
Ik werd onlangs uitgescholden omdat ik suggereerde dat, in sommige gevallen, een niet-geclusterde index beter zal presteren voor een bepaalde zoekopdracht dan de geclusterde index. Deze persoon verklaarde dat de geclusterde index altijd het beste is omdat deze per definitie altijd dekt, en dat elke niet-geclusterde index met enkele of alle dezelfde sleutelkolommen altijd overbodig was.
Ik ben het er graag mee eens dat de geclusterde index altijd dekkend is (en om hier enige dubbelzinnigheid te voorkomen, houden we het bij schijfgebaseerde tabellen met traditionele B-tree-indexen).
 Ik ben het er echter niet mee eens dat een geclusterde index altijd is sneller dan een niet-geclusterde index. Ik ben het er ook niet mee eens dat het altijd overbodig is om een niet-geclusterde index of unieke beperking te maken die bestaat uit dezelfde (of enkele van dezelfde) kolommen in de clustersleutel.
Ik ben het er echter niet mee eens dat een geclusterde index altijd is sneller dan een niet-geclusterde index. Ik ben het er ook niet mee eens dat het altijd overbodig is om een niet-geclusterde index of unieke beperking te maken die bestaat uit dezelfde (of enkele van dezelfde) kolommen in de clustersleutel.
Laten we dit voorbeeld nemen, Warehouse.StockItemTransactions , van WideWorldImporters. De geclusterde index wordt geïmplementeerd via een primaire sleutel op alleen de StockItemTransactionID kolom (vrij typisch wanneer je een soort surrogaat-ID hebt gegenereerd door een IDENTITEIT of een SEQUENTIE).
Het is vrij gebruikelijk om een telling van de hele tafel te eisen (hoewel er in veel gevallen betere manieren zijn). Dit kan zijn voor incidentele inspectie of als onderdeel van een pagineringsprocedure. De meeste mensen zullen het op deze manier doen:
SELECT COUNT(*) FROM Warehouse.StockItemTransactions;
Met het huidige schema zal dit een niet-geclusterde index gebruiken:
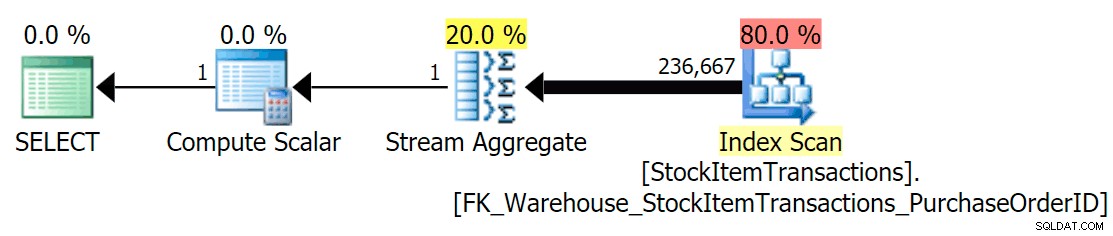
We weten dat de niet-geclusterde index niet alle kolommen in de geclusterde index bevat. De telbewerking hoeft er alleen voor te zorgen dat alle rijen zijn opgenomen, zonder zich zorgen te maken over welke kolommen aanwezig zijn, dus SQL Server kiest meestal de index met het kleinste aantal pagina's (in dit geval heeft de gekozen index ~ 414 pagina's).
Laten we de query nu opnieuw uitvoeren, deze keer vergeleken met een hint-query die het gebruik van de geclusterde index afdwingt.
SELECT COUNT(*) FROM Warehouse.StockItemTransactions; SELECT COUNT(*) /* with hint */ FROM Warehouse.StockItemTransactions WITH (INDEX(1));
We krijgen een bijna identieke planvorm, maar we zien een enorm verschil in uitlezingen (414 voor de gekozen index versus 1.982 voor de geclusterde index):
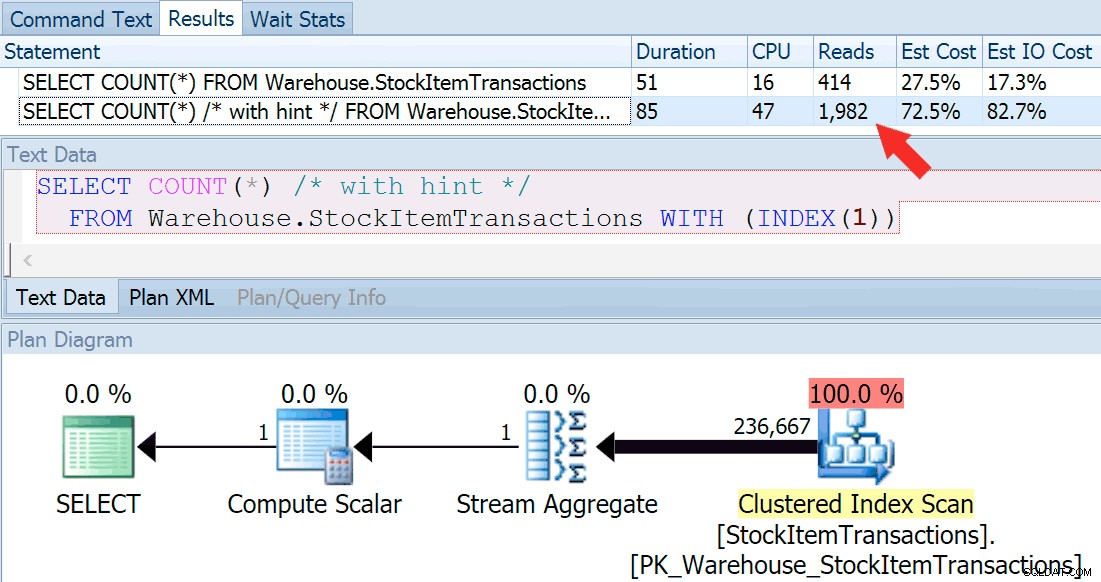
De duur is iets hoger voor de geclusterde index, maar het verschil is verwaarloosbaar als we te maken hebben met een kleine hoeveelheid gegevens in de cache op een snelle schijf. Die discrepantie zou veel groter zijn met meer gegevens, op een trage schijf of op een systeem met geheugendruk.
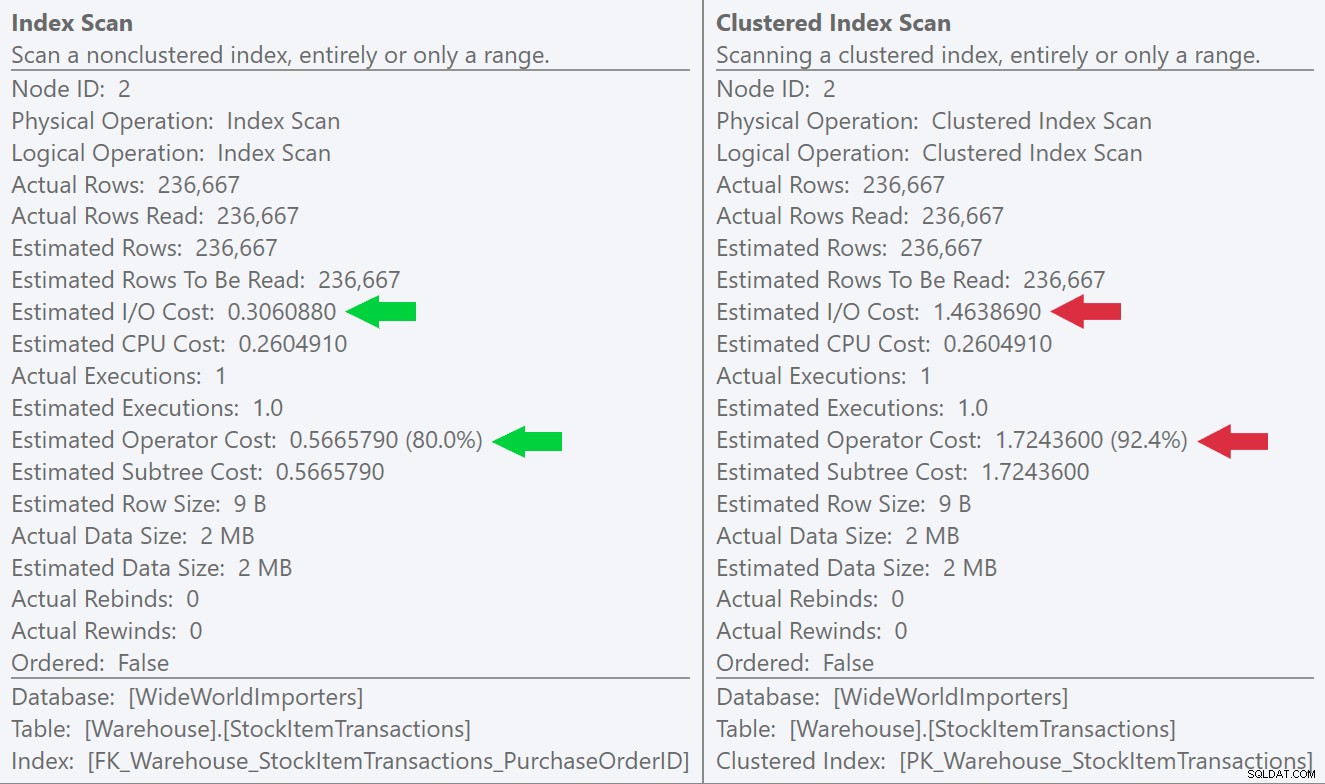
Als we kijken naar de tooltips voor de scanbewerkingen, kunnen we zien dat hoewel het aantal rijen en de geschatte CPU-kosten identiek zijn, het grote verschil afkomstig is van de geschatte I/O-kosten (omdat SQL Server weet dat er meer pagina's in de geclusterde index dan de niet-geclusterde index):
We kunnen dit verschil nog duidelijker zien als we een nieuwe, unieke index maken op alleen de ID-kolom (waardoor het "redundant" wordt met de geclusterde index, toch?):
CREATE UNIQUE INDEX NewUniqueNCIIndex ON Warehouse.StockItemTransactions(StockItemTransactionID);
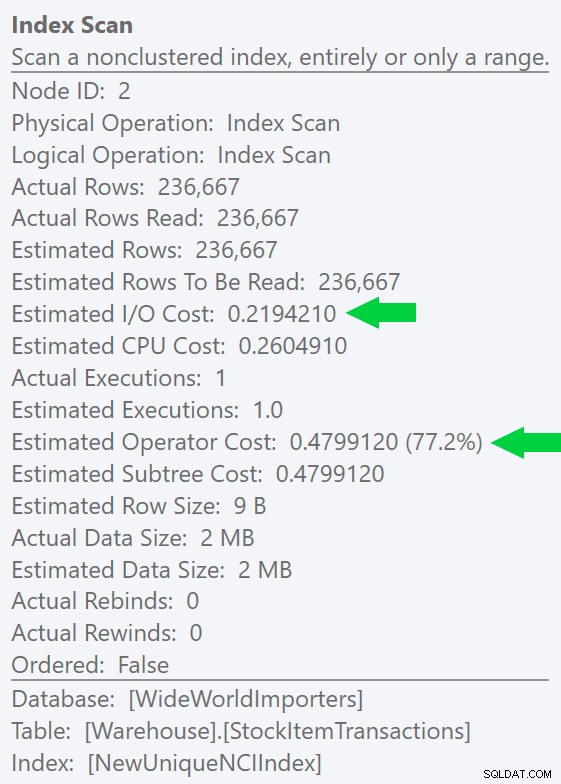 Het uitvoeren van een vergelijkbare query met een expliciete indexhint levert dezelfde planvorm op, maar een nog lagere geschatte I/O kosten (en zelfs lagere looptijden) – zie afbeelding rechts. En als u de oorspronkelijke query uitvoert zonder de hint, ziet u dat SQL Server nu ook deze index kiest.
Het uitvoeren van een vergelijkbare query met een expliciete indexhint levert dezelfde planvorm op, maar een nog lagere geschatte I/O kosten (en zelfs lagere looptijden) – zie afbeelding rechts. En als u de oorspronkelijke query uitvoert zonder de hint, ziet u dat SQL Server nu ook deze index kiest.
Het lijkt misschien voor de hand liggend, maar veel mensen zouden geloven dat de geclusterde index hier de beste keuze is. SQL Server zal bijna altijd de voorkeur geven aan welke methode dan ook die de goedkoopste manier biedt om alle I/O uit te voeren, en in het geval van een volledige scan, zal dat de "magere" index zijn. Dit kan ook gebeuren met beide soorten zoekacties (singleton- en range-scans), tenminste wanneer de index dekt.
Nu, zoals altijd, doet dat niet op welke manier dan ook betekent dat u extra indexen moet gaan maken op al uw tabellen om te voldoen aan telquery's. Dat is niet alleen een inefficiënte manier om de tabelgrootte te controleren (zie nogmaals dit artikel), maar een index die dat ondersteunt, zou moeten betekenen dat u die query vaker uitvoert dan dat u de gegevens bijwerkt. Onthoud dat elke index ruimte op schijf nodig heeft, ruimte in het geheugen, en alle schrijfacties tegen de tabel moeten ook elke index raken (gefilterde indexen daargelaten).
Samenvatting
Ik zou nog veel andere voorbeelden kunnen bedenken die aantonen wanneer een niet-geclusterd bestand nuttig kan zijn en de onderhoudskosten waard kan zijn, zelfs bij het dupliceren van de sleutelkolom(men) van de geclusterde index. Niet-geclusterde indexen kunnen worden gemaakt met dezelfde sleutelkolommen maar in een andere sleutelvolgorde, of met verschillende ASC/DESC op de kolommen zelf om een alternatieve presentatievolgorde beter te ondersteunen. U kunt ook niet-geclusterde indexen hebben die slechts een kleine subset van de rijen bevatten door het gebruik van een filter. Ten slotte, als u uw meest voorkomende vragen kunt beantwoorden met dunnere, niet-geclusterde indexen, is dat ook beter voor het geheugenverbruik.
Maar mijn punt van deze serie is eigenlijk alleen maar om een tegenvoorbeeld te laten zien dat de dwaasheid illustreert van het maken van algemene uitspraken zoals deze. Ik zal u een uitleg geven van Paul White die in een DBA.SE-antwoord uitlegt waarom een dergelijke niet-geclusterde index in feite veel beter kan presteren dan een geclusterde index. Dit geldt zelfs als beide beide typen zoeken gebruiken:
- Verschil tussen zoeken naar geclusterde index en zoeken naar niet-geclusterde index