Wanneer u een databasecluster in verschillende servers implementeert, heeft u het replicatievoordeel bereikt dat de beschikbaarheid van gegevens wordt verbeterd. Het is echter nodig om processen bij te houden en te zien of ze actief zijn of niet. Een van de programma's die in dit proces worden gebruikt, is Heartbeat, dat de mogelijkheid heeft om de aanwezigheid van bronnen op een of meer systemen in een bepaald cluster te controleren en te verifiëren. Naast de PostgreSQL en de bestandssystemen waarvoor PostgreSQL-gegevens worden opgeslagen, is de DRBD een van de bronnen die we in dit artikel gaan bespreken over hoe het Heartbeat-programma kan worden gebruikt.
HA Hartslag
Zoals eerder besproken in de DRBD-blog, wordt een hoge beschikbaarheid van gegevens bereikt door verschillende instanties van de server uit te voeren, maar dezelfde gegevens te bedienen. Deze actieve serverinstanties kunnen worden gedefinieerd als een cluster in relatie tot een Heartbeat. In principe is elk van de serverinstanties fysiek in staat om dezelfde service te bieden als de andere binnen dat cluster. Er kan echter slechts één instantie tegelijk actief service verlenen om een hoge beschikbaarheid van gegevens te garanderen. De overige instanties kunnen we dus als ‘hot-spares’ definiëren die bij uitval van de master in gebruik kunnen worden genomen. Het Heartbeat-pakket kan worden gedownload via deze link. Nadat u dit pakket hebt geïnstalleerd, kunt u het configureren om met uw systeem te werken met de onderstaande procedure. Een eenvoudige structuur van de Heartbeat-configuratie is:
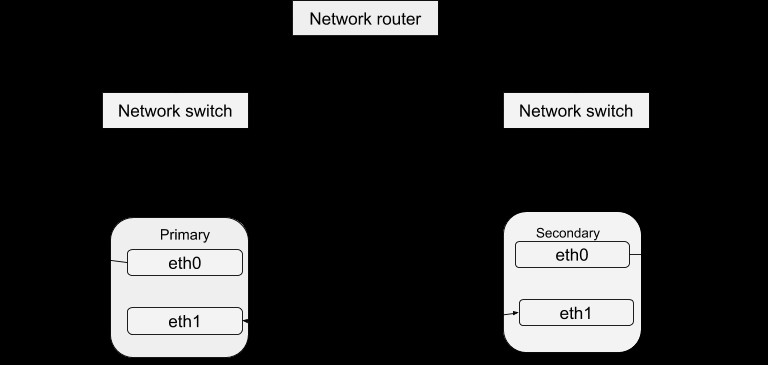
Configuratie van hartslag
Als u in deze map /etc/ha.d kijkt, vindt u enkele bestanden die worden gebruikt in het configuratieproces. Het ha.cf-bestand vormt de belangrijkste hartslagconfiguratie. Het bevat de lijst met alle knooppunten en tijden voor het identificeren van fouten, naast het sturen van de hartslag op welk type mediapaden moet worden gebruikt en hoe deze moeten worden geconfigureerd. Beveiligingsinformatie voor het cluster wordt vastgelegd in het authkeys-bestand. Opgenomen informatie in deze bestanden moet identiek zijn voor alle hosts in het cluster en dit kan eenvoudig worden bereikt door synchronisatie tussen alle hosts. Dit wil zeggen dat elke wijziging van informatie in de ene host naar alle andere moet worden gekopieerd.
Ha.cf-bestand
De basisstructuur van het ha.cf-bestand is
logfacility local0
keepalive 3
Deadtime 7
warntime 3
initdead 30
mcast eth0 225.0.0.1 694 2 0
mcast eth1 225.0.0.2 694 1 0
auto_failback off
node drbd1
node drbd2
node drbd3-
Logfacility:deze wordt gebruikt om de Heartbeat te sturen op welke syslog-logging-faciliteit het moet gebruiken voor het opnemen van berichten. De meest gebruikte waarden zijn auth, authpriv, user, local0, syslog en daemon. U kunt ook besluiten om geen logs te hebben, zodat u de waarde kunt instellen op geen .i.e.
logfacility none - Keepalive:dit is de tijd tussen hartslagen, dat wil zeggen de frequentie waarmee het hartslagsignaal naar de andere hosts wordt gestuurd. In de voorbeeldcode hierboven is deze ingesteld op 3 seconden.
- Deadtime:dit is de vertraging in seconden waarna een node als mislukt wordt verklaard.
- Waarschuwingstijd:is de vertraging in seconden waarna een waarschuwing wordt vastgelegd in een logboek dat aangeeft dat er geen contact meer met een knooppunt kan worden gemaakt.
- Initdead:dit is de tijd in seconden die nodig is om te wachten tijdens het opstarten van het systeem voordat de andere host als down wordt beschouwd.
- Mcast:het is een gedefinieerde methodeprocedure voor het verzenden van een hartslagsignaal. Voor de bovenstaande voorbeeldcode wordt het multicast-netwerkadres gebruikt via een begrensd netwerkapparaat. Voor een meervoudig cluster moet het multicast-adres uniek zijn voor elk cluster. Je kunt ook een seriële verbinding kiezen over de multicast of als je het zo instelt dat er meerdere netwerkinterfaces zijn, gebruik dan beide voor de hartslagverbinding zoals in het voorbeeld. Het voordeel van beide is om de kans op een tijdelijke storing te overwinnen, die bijgevolg een ongeldige storingsgebeurtenis kan veroorzaken.
- Auto_failback:dit maakt opnieuw verbinding met een server die een mislukte back-up had gemaakt met het cluster als deze beschikbaar komt. Het kan echter voor verwarring zorgen als de server aan staat en dan op een ander tijdstip online komt. Met betrekking tot de DRBD, als deze niet goed is geconfigureerd, kunt u eindigen met meer dan één gegevensset op dezelfde server. Daarom is het raadzaam om het altijd uit te zetten.
- Knooppunt:geeft een overzicht van het knooppunt binnen de Heartbeat-clustergroep. Je zou voor elk minimaal 1 node moeten hebben.
Extra configuraties
U kunt ook aanvullende configuratie-informatie instellen, zoals:
ping 10.0.0.1
respawn hacluster /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=haclient uid=hacluster
deadping 5- Ping:dit is belangrijk om ervoor te zorgen dat u verbinding hebt op de openbare interface voor de servers en verbinding met een andere host. Het is belangrijk om het IP-adres te overwegen in plaats van de hostnaam voor de bestemmingsmachine.
- Respawn:dit is het commando dat moet worden uitgevoerd als er een storing optreedt.
- Apiauth:is de autoriteit voor de mislukking. U moet de gebruikers- en groeps-ID configureren waarmee de opdracht wordt uitgevoerd. Het authkeys-bestand bevat de autorisatie-informatie voor het Heartbeat-cluster en deze sleutel is zeer uniek voor het verifiëren van machines binnen een bepaald Heartbeat-cluster.
- Deadping:definieert de time-out voordat een non-respons een fout veroorzaakt.
Integratie van hartslag met Postgres en DRBD
Zoals eerder vermeld, zal wanneer een masterserver uitvalt, een andere server met een bepaald cluster in actie komen om dezelfde service te leveren. Heartbeat helpt bij het configureren van bronnen die de selectie van een server in geval van storing verbeteren. Het definieert bijvoorbeeld welke individuele servers moeten worden opgestart of weggegooid in het geval van een storing. Als we inchecken bij het haresources-bestand in de map /etc/ha.d, krijgen we een overzicht van de bronnen die kunnen worden beheerd. Het bronbestandspad is /etc/ha.d/resource.d en de brondefinitie staat op één regel, namelijk:
drbd1 drbddisk Filesystem::/dev/drbd0::/drbd::ext3 postgres 10.0.0.1(let op de spaties).
- Drbd1:verwijst naar de naam van de voorkeurshost om meer secans te zijn dan de server die normaal wordt gebruikt als de standaardmaster voor het afhandelen van de service. Zoals vermeld in de DRBD-blog, hebben we bronnen nodig voor onze server en deze worden in de regel gedefinieerd als de drbddisk, het bestandssysteem en postgres. Het laatste veld is een virtueel IP-adres dat moet worden gebruikt om de service te delen, d.w.z. verbinding maken met de Postgres-server. Standaard wordt deze toegewezen aan de server die actief is wanneer de Heartbeat begint. Wanneer er een storing optreedt, worden deze resources in volgorde van opstelling op de back-upserver gestart wanneer het corresponderende script wordt aangeroepen. In de instelling schakelt het script de DRBD-schijf op de secundaire host in de primaire modus, waardoor het apparaat kan lezen/schrijven.
- Bestandssysteem:dit beheert de bronnen van het bestandssysteem en in dit geval is de DRBD geselecteerd zodat deze wordt aangekoppeld tijdens het aanroepen van het bronnenscript.
- Postgres:hiermee wordt de Postgres-server gestart of beheerd
Soms wilt u meldingen per e-mail ontvangen. Voeg hiervoor deze regel toe aan het bronnenbestand met uw e-mail voor het ontvangen van de waarschuwingsteksten:
MailTo:: example@sqldat.com::DRBDFailureOm de hartslag te starten, kun je het commando
. uitvoeren/etc/ha.d/heartbeat startof start zowel de primaire als de secundaire server opnieuw op. Als u nu de opdracht
. uitvoert$ /usr/lib64/heartbeat/hb_standbyHet huidige knooppunt wordt getriggerd om zijn bronnen netjes af te staan aan het andere knooppunt.
Download de whitepaper vandaag PostgreSQL-beheer en -automatisering met ClusterControlLees wat u moet weten om PostgreSQL te implementeren, bewaken, beheren en schalenDownload de whitepaperOmgaan met fouten op systeemniveau
Soms is de serverkernel mogelijk beschadigd, wat wijst op een mogelijk probleem met uw server. U moet de server configureren om zichzelf uit het cluster te verwijderen in het geval van een probleem. Dit probleem wordt vaak kernel panic genoemd en veroorzaakt bijgevolg een harde herstart op uw machine. Je kunt een herstart forceren door de kernel.panic en kernel.panic_on_oop van het kernelcontrolebestand /etc/sysctl.conf in te stellen. Dwz
kernel.panic_on_oops = 1
kernel.panic = 1Een andere optie is om het vanaf de opdrachtregel te doen met het sysctl-commando, d.w.z.:
$ sysctl -w kernel.panic=1U kunt ook het bestand sysctl.conf bewerken en de configuratie-informatie opnieuw laden met deze opdracht.
sysctl -pDe waarde geeft het aantal seconden aan dat moet worden gewacht voordat opnieuw wordt opgestart. De tweede heartbeat-node zou dan moeten detecteren dat de server niet beschikbaar is en vervolgens de failover-host omschakelen.
Conclusie
Heartbeat is een subsysteem waarmee een secundaire server kan worden geselecteerd in een primair systeem en een back-upsysteem wanneer een actieve server uitvalt. Het bepaalt ook of alle andere servers in leven zijn. Het zorgt ook voor overdracht van bronnen naar het nieuwe primaire knooppunt