Volgens Wikipedia is de bulk-insert een proces of methode die wordt aangeboden door een databasebeheersysteem om meerdere rijen gegevens in een databasetabel te laden. Als we deze uitleg aanpassen aan de BULK INSERT-instructie, maakt de bulk-insert het mogelijk om externe gegevensbestanden in SQL Server te importeren.
Stel dat onze organisatie een CSV-bestand van 1.500.000 rijen heeft en we willen dit importeren in een bepaalde tabel in SQL Server om de BULK INSERT-instructie in SQL Server te gebruiken. We kunnen verschillende methoden vinden om deze taak uit te voeren. Het kan BCP gebruiken (b ulk c opy p rogram), SQL Server Import en Export Wizard of SQL Server Integration Service-pakket. De instructie BULK INSERT is echter veel sneller en krachtiger. Een ander voordeel is dat het verschillende parameters biedt die helpen bij het bepalen van de instellingen voor het bulkinvoegproces.
Laten we beginnen met een basisvoorbeeld. Daarna zullen we meer geavanceerde scenario's doornemen.
Voorbereiding
Allereerst hebben we een voorbeeld-CSV-bestand nodig. We downloaden een voorbeeld-CSV-bestand van de E for Excel-website (een verzameling voorbeeld-CSV-bestanden met een ander rijnummer). Hier gaan we 1.500.000 verkooprecords gebruiken.
Download een zipbestand, pak het uit om een CSV-bestand te krijgen en plaats het op uw lokale schijf.
CSV-bestand importeren naar SQL Server-tabel
We importeren ons CSV-bestand in de eenvoudigste vorm in de bestemmingstabel. Ik heb mijn voorbeeld-CSV-bestand op de C:-schijf geplaatst. Nu maken we een tabel om de CSV-bestandsgegevens erin te importeren:
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
De volgende instructie BULK INSERT importeert het CSV-bestand naar de tabel Verkoop:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); U hebt waarschijnlijk de specifieke parameters van de bovenstaande bulkinvoeginstructie opgemerkt. Laten we ze verduidelijken:
- FIRSTROW specificeert het startpunt van de insert-instructie. In het onderstaande voorbeeld willen we kolomkoppen overslaan, dus stellen we deze parameter in op 2.

- FIELDTERMINATOR definieert het teken dat velden van elkaar scheidt. SQL Server detecteert elk veld op deze manier.
- ROWTERMINATOR verschilt niet veel van FIELDTERMINATOR. Het definieert het scheidingsteken van rijen.
In het voorbeeld-CSV-bestand is FIELDTERMINATOR heel duidelijk en is het een komma (,). Om deze parameter te detecteren, opent u het CSV-bestand in Notepad++ en navigeert u naar Beeld -> Symbool weergeven -> Alle charters tonen. De CRLF-tekens staan aan het einde van elk veld.
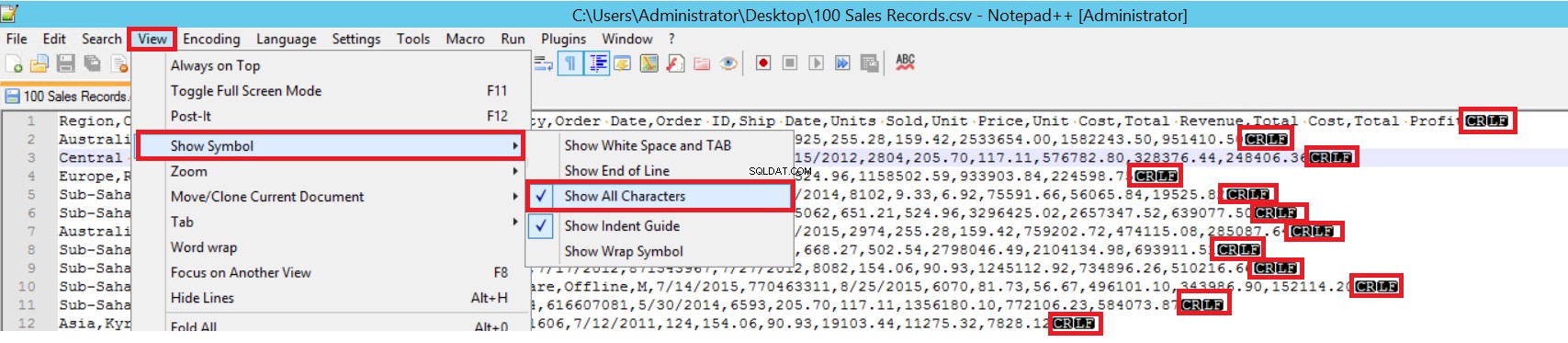
CR =Carriage Return en LF =Line Feed. Ze worden gebruikt om een regeleinde in een tekstbestand te markeren. De indicator is "\n" in de bulk insert-instructie.
Een andere manier om een CSV-bestand naar een tabel met bulkinsert te importeren, is door de parameter FORMAT te gebruiken. Merk op dat deze parameter alleen beschikbaar is in SQL Server 2017 en latere versies.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
Dat was het eenvoudigste scenario waarbij de doeltabel en het CSV-bestand een gelijk aantal kolommen hebben. Als de doeltabel echter meer kolommen heeft, is het CSV-bestand typisch. Laten we er eens over nadenken.
We voegen een primaire sleutel toe aan de tabel Sales om de gelijkheidskolomtoewijzingen te doorbreken. We maken de Sales-tabel met een primaire sleutel en importeren het CSV-bestand via het bulk-insert-commando.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
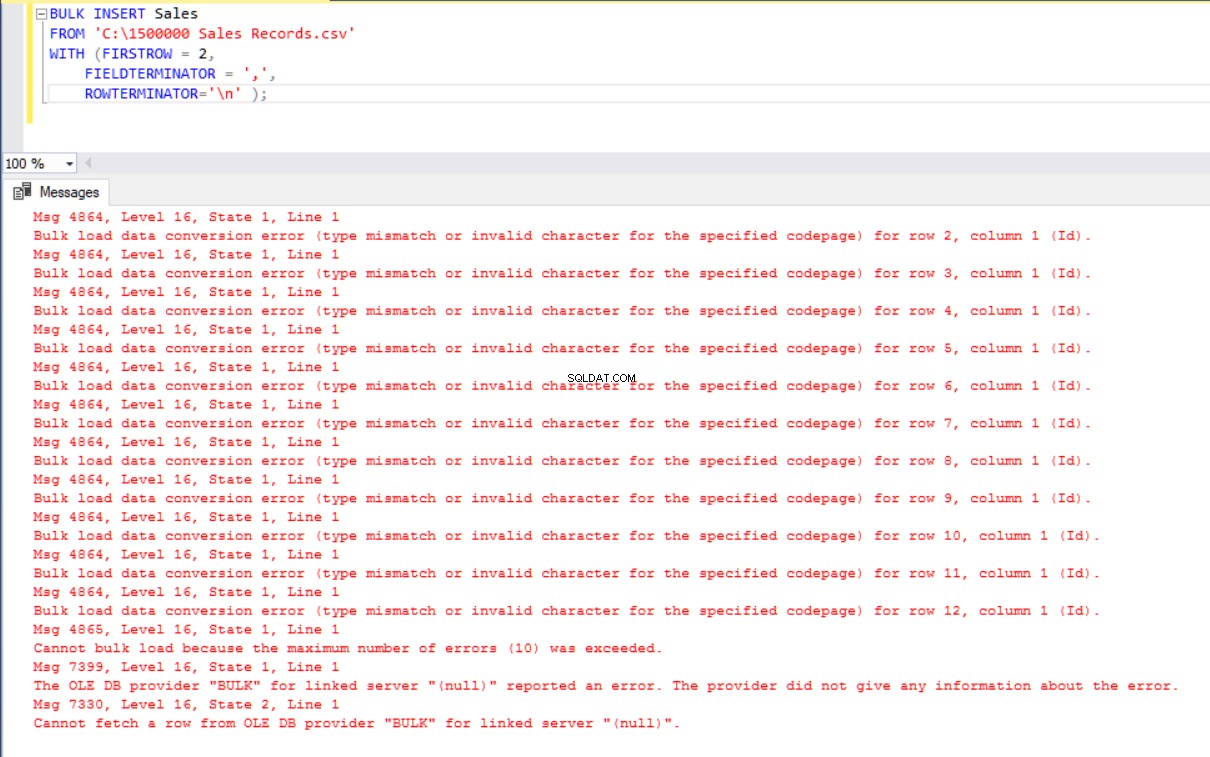
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Maar het geeft een fout:
Om de fout te verhelpen, maken we een weergave van de tabel Verkoop met toewijzingskolommen aan het CSV-bestand. Vervolgens importeren we de CSV-gegevens over deze weergave naar de tabel Verkoop:
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Scheid en laad een groot CSV-bestand in een kleine batchgrootte
SQL Server verkrijgt een vergrendeling naar de doeltabel tijdens de bulk-invoegbewerking. Als u de parameter BATCHSIZE niet instelt, opent SQL Server standaard een transactie en voegt de volledige CSV-gegevens erin in. Met deze parameter verdeelt SQL Server de CSV-gegevens volgens de parameterwaarde.
Laten we de hele CSV-gegevens opdelen in verschillende sets van elk 300.000 rijen.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 ); De gegevens worden in delen vijf keer geïmporteerd.
- Als uw bulk insert-instructie de BATCHSIZE-parameter niet bevat, zal er een fout optreden en zal de SQL Server het hele bulk insert-proces terugdraaien.
- Met deze parameter ingesteld op bulk insert-instructie, draait SQL Server alleen het deel terug waar de fout is opgetreden.
Er is geen optimale of beste waarde voor deze parameter omdat de waarde ervan kan veranderen afhankelijk van de vereisten van uw databasesysteem.
Stel het gedrag in bij fouten
Als er een fout optreedt in sommige scenario's voor bulkkopie, kunnen we het bulkkopieproces annuleren of doorgaan. Met de parameter MAXERRORS kunnen we het maximale aantal fouten specificeren. Als het bulk-invoegproces deze maximale foutwaarde bereikt, annuleert het de bulkimportbewerking en wordt het teruggedraaid. De standaardwaarde voor deze parameter is 10.
We hebben bijvoorbeeld beschadigde gegevenstypen in 3 rijen van het CSV-bestand. De MAXERRORS-parameter is ingesteld op 2.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2); De hele bulk-invoegbewerking wordt geannuleerd omdat er meer fouten zijn dan de MAXERRORS-parameterwaarde.
Als we de parameter MAXERRORS wijzigen in 4, zal de bulkinsert-instructie deze rijen met fouten overslaan en correcte gestructureerde rijen met gegevens invoegen. Het bulk-invoegproces is voltooid.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Als we zowel BATCHSIZE als MAXERRORS tegelijkertijd gebruiken, zal het bulkkopieproces de hele invoegbewerking niet annuleren. Het zal alleen het gesplitste gedeelte annuleren.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
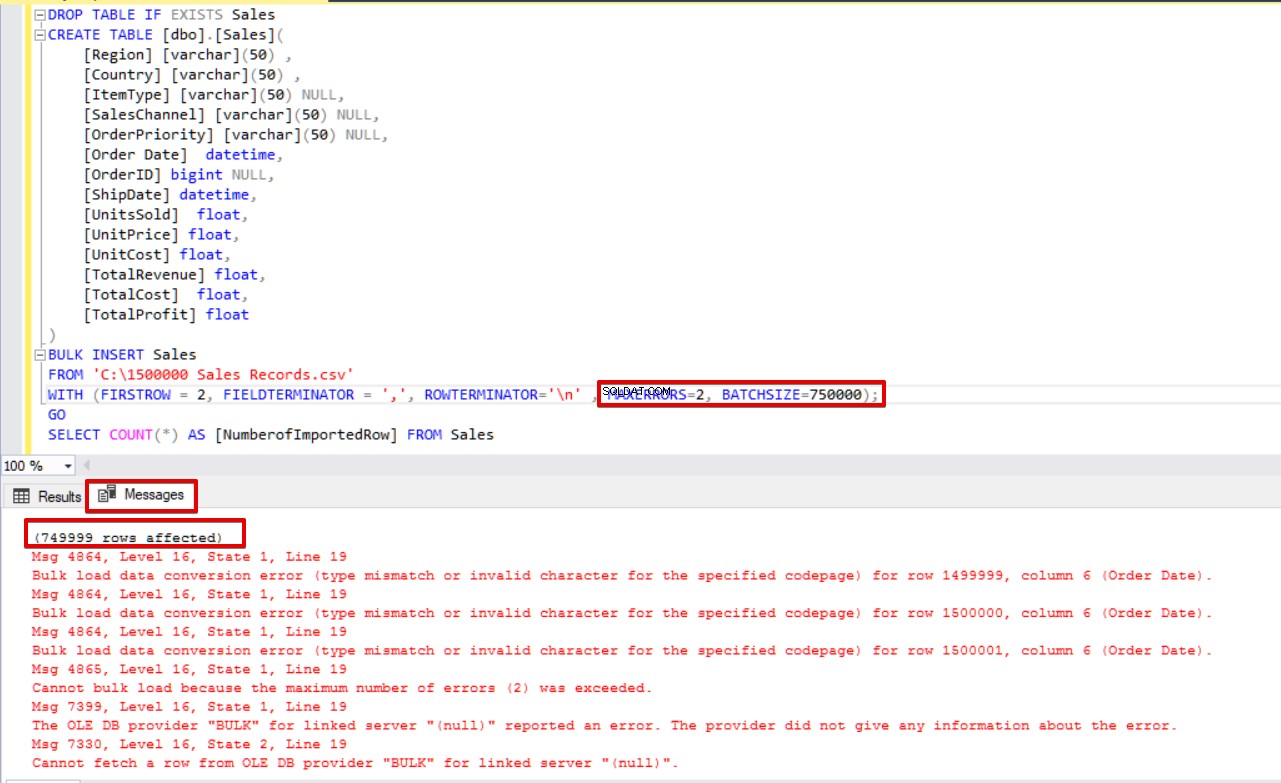
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
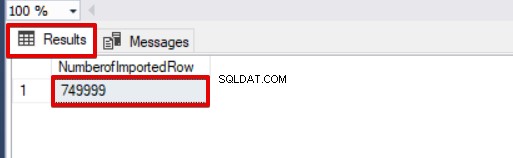
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Bekijk de onderstaande afbeelding die het resultaat van de uitvoering van het script laat zien:
Andere opties van het bulk-invoegproces
FIRE_TRIGGERS – activeer triggers in de bestemmingstabel tijdens de bulk-invoegbewerking
Tijdens het bulk-invoegproces worden standaard de invoegtriggers die zijn opgegeven in de doeltabel niet geactiveerd. Toch willen we ze in sommige situaties mogelijk inschakelen.
De oplossing is het gebruik van de FIRE_TRIGGERS-optie in bulkinvoeginstructies. Houd er echter rekening mee dat dit de prestaties van de bulk-insertbewerking kan beïnvloeden en verminderen. Het is omdat trigger/triggers afzonderlijke bewerkingen in de database kunnen uitvoeren.
In eerste instantie stellen we de FIRE_TRIGGERS-parameter niet in en het bulk-invoegproces zal de invoegtrigger niet activeren. Zie het onderstaande T-SQL-script:
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLogWanneer dit script wordt uitgevoerd, wordt de invoegtrigger niet geactiveerd omdat de optie FIRE_TRIGGERS niet is ingesteld.
Laten we nu de optie FIRE_TRIGGERS toevoegen aan de bulk insert-instructie:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n',
FIRE_TRIGGERS);
GO
SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog 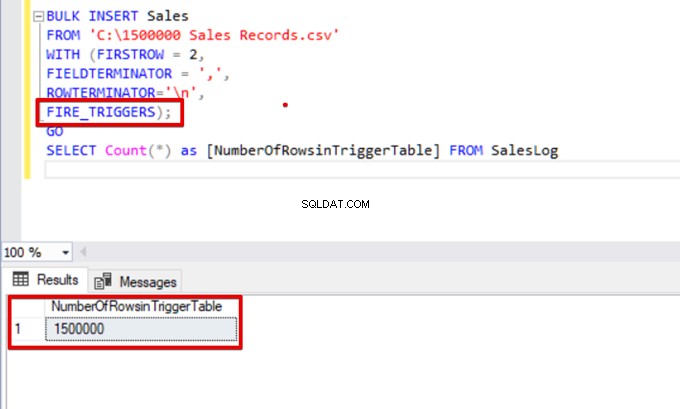
CHECK_CONSTRAINTS – schakel een controlebeperking in tijdens de bulkinvoegbewerking
Met controlebeperkingen kunnen we de gegevensintegriteit in SQL Server-tabellen afdwingen. Het doel van de beperking is om ingevoegde, bijgewerkte of verwijderde waarden te controleren op basis van hun syntaxisregelgeving. De beperking NOT NULL zorgt er bijvoorbeeld voor dat de NULL-waarde een opgegeven kolom niet kan wijzigen.
Hier concentreren we ons op beperkingen en interacties met bulk-inserts. Tijdens het bulk-invoegproces worden standaard beperkingen voor controle en externe sleutels genegeerd. Maar er zijn enkele uitzonderingen.
Volgens Microsoft worden “UNIEKE en PRIMARY KEY-beperkingen altijd afgedwongen. Bij het importeren in een tekenkolom waarvoor de beperking NOT NULL is gedefinieerd, voegt BULK INSERT een lege tekenreeks in als er geen waarde in het tekstbestand staat.'
In het volgende T-SQL-script voegen we een controlebeperking toe aan de kolom OrderDate, die de besteldatum bepaalt die groter is dan 01.01.2016.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'Als gevolg hiervan slaat het bulk-invoegproces de controlebeperking over. SQL Server geeft echter de controlebeperking aan als niet-vertrouwd:
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'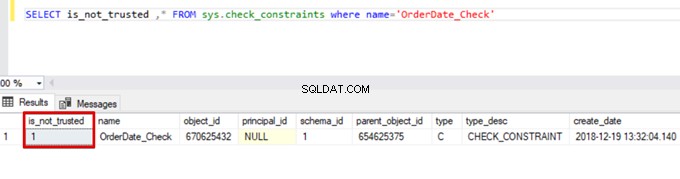
Deze waarde geeft aan dat iemand gegevens in deze kolom heeft ingevoegd of bijgewerkt door de controlebeperking over te slaan. Tegelijkertijd kan deze kolom inconsistente gegevens bevatten over die beperking.
Probeer de bulk insert-instructie uit te voeren met de optie CHECK_CONSTRAINTS. Het resultaat is eenvoudig:controlebeperking retourneert een fout vanwege onjuiste gegevens.
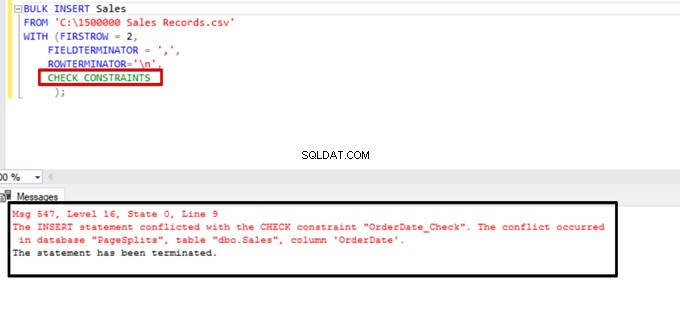
TABLOCK – verhoog de prestaties bij meerdere bulkinvoegingen in één bestemmingstabel
Het primaire doel van het vergrendelingsmechanisme in SQL Server is het beschermen en waarborgen van de gegevensintegriteit. In het hoofdconcept van het artikel over SQL Server-vergrendeling vindt u details over het vergrendelingsmechanisme.
We zullen ons concentreren op de details van het bulksgewijs invoegen van processen.
Als u de bulk insert-instructie uitvoert zonder de TABLELOCK-optie, verkrijgt deze de vergrendeling van rijen of tabellen volgens de vergrendelingshiërarchie. Maar in sommige gevallen willen we misschien meerdere bulk-invoegprocessen uitvoeren op één bestemmingstabel en zo de bewerkingstijd verkorten.
Eerst voeren we twee bulk-insert-statements tegelijk uit en analyseren we het gedrag van het vergrendelingsmechanisme. Open twee queryvensters in SQL Server Management Studio en voer de volgende bulkinvoeginstructies tegelijkertijd uit.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
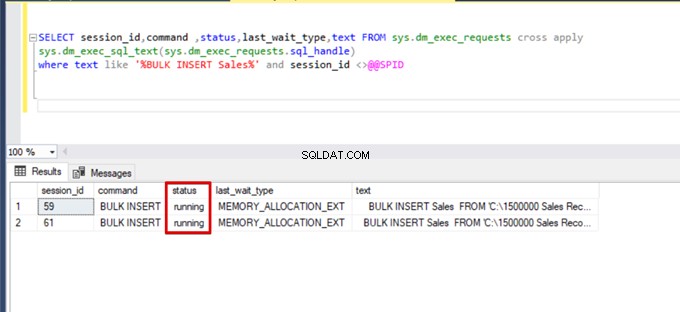
);Voer de volgende DMV-query (Dynamic Management View) uit – het helpt om de status van het bulkinvoegproces te bewaken:
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply
sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle)
where text like '%BULK INSERT Sales%' and session_id <>@@SPID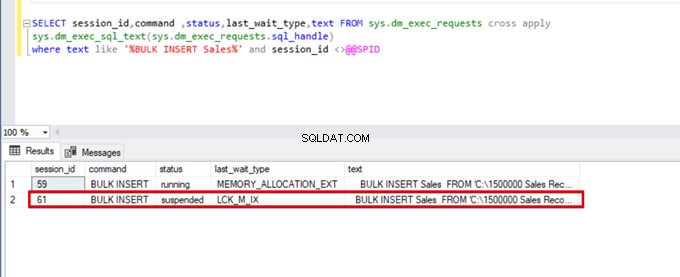
Zoals u kunt zien in de bovenstaande afbeelding, sessie 61, is de status van het bulk-invoegproces opgeschort vanwege vergrendeling. Als we het probleem verifiëren, vergrendelt sessie 59 de bestemmingstabel voor bulkinserts. Vervolgens wacht sessie 61 op het vrijgeven van deze vergrendeling om het bulk-invoegproces voort te zetten.
Nu voegen we de TABLOCK-optie toe aan de bulkinvoeginstructies en voeren we de query's uit.
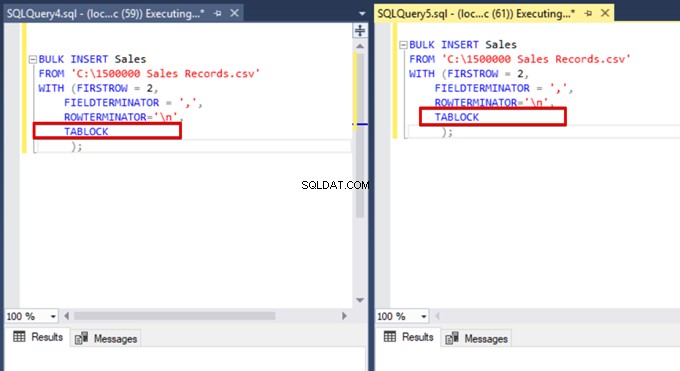
Wanneer we de DMV-bewakingsquery opnieuw uitvoeren, kunnen we geen onderbroken bulkinvoegproces zien omdat SQL Server een bepaald vergrendelingstype gebruikt dat bulkupdatevergrendeling (BU) wordt genoemd. Met dit slottype kunnen meerdere bulkinvoegbewerkingen tegelijkertijd tegen dezelfde tafel worden verwerkt. Deze optie verkort ook de totale tijd van het bulkinvoegproces.
Wanneer we de volgende query uitvoeren tijdens het bulk-invoegproces, kunnen we de vergrendelingsdetails en slottypes controleren:
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()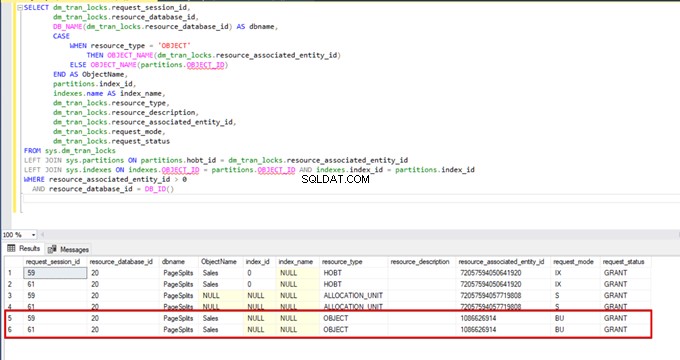
Conclusie
In het huidige artikel zijn alle details van de bulk-invoegbewerking in SQL Server onderzocht. We noemden met name de opdracht BULK INSERT en de instellingen en opties. We hebben ook verschillende scenario's geanalyseerd die dicht bij echte problemen liggen.
Handig hulpmiddel:
dbForge Data Pump – een SSMS-invoegtoepassing voor het vullen van SQL-databases met externe brongegevens en het migreren van gegevens tussen systemen.