Volgens Wikipedia:"Een bulk-insert is een proces of methode die wordt geleverd door een databasebeheersysteem om meerdere rijen gegevens in een databasetabel te laden." Als we deze uitleg aanpassen in overeenstemming met de BULK INSERT-instructie, maakt bulk insert het mogelijk om externe gegevensbestanden in SQL Server te importeren. Stel dat onze organisatie een CSV-bestand van 1.500.000 rijen heeft en we willen dit bestand importeren naar een bepaalde tabel in SQL Server, zodat we gemakkelijk de BULK INSERT-instructie in SQL Server kunnen gebruiken. We kunnen zeker verschillende importmethodologieën vinden om dit CSV-bestandimportproces af te handelen, b.v. we kunnen bcp gebruiken (b ulk c opy p rogram), SQL Server Import en Export Wizard of SQL Server Integration Service-pakket. De instructie BULK INSERT is echter veel sneller en robuuster dan het gebruik van andere methoden. Een ander voordeel van het bulk insert statement is dat het verschillende parameters biedt die helpen bij het bepalen van de instellingen van het bulk insert proces.
Eerst beginnen we met een heel eenvoudig voorbeeld en dan zullen we verschillende geavanceerde scenario's doorlopen.
Voorbereiding
Voordat we met de voorbeelden beginnen, hebben we een voorbeeld-CSV-bestand nodig. Daarom zullen we een voorbeeld-CSV-bestand downloaden van de E for Excel-website, waar u verschillende voorbeeld-CSV-bestanden met een ander rijnummer kunt vinden. De link vind je aan het einde van het artikel. In onze scenario's gebruiken we 1.500.000 verkooprecords. Download een zip-bestand, pak het CSV-bestand uit en plaats het op uw lokale schijf.

CSV-bestand importeren in SQL Server-tabel
Scenario-1:Bestemming en CSV-bestand hebben een gelijk aantal kolommen
In dit eerste scenario importeren we het CSV-bestand in de eenvoudigste vorm in de doeltabel. Ik heb mijn voorbeeld-CSV-bestand op de C:-schijf geplaatst en nu gaan we een tabel maken waarin we gegevens uit het CSV-bestand zullen importeren.
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
De volgende instructie BULK INSERT importeert het CSV-bestand naar de tabel Verkoop.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
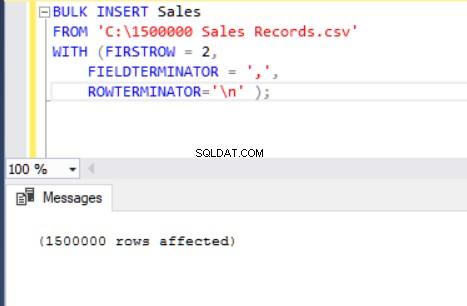
Nu zullen we de parameters van de bovenstaande bulk insert-instructie uitleggen.
De parameter FIRSTROW specificeert het startpunt van de insert-instructie. In het onderstaande voorbeeld willen we kolomkoppen overslaan, dus stellen we deze parameter in op 2.

FIELDTERMINATOR definieert het teken dat velden van elkaar scheidt. SQL Server detecteert elk veld op zo'n manier. ROWTERMINATOR verschilt niet veel van FIELDTERMINATOR. Het definieert het scheidingskarakter van rijen. In het voorbeeld-CSV-bestand is fieldterminator heel duidelijk en is het een komma (,). Maar hoe kunnen we een fieldterminator detecteren? Open het CSV-bestand in Notepad++ en navigeer vervolgens naar Beeld->Symbool weergeven->Toon alle charters en ontdek de CRLF-tekens aan het einde van elk veld.
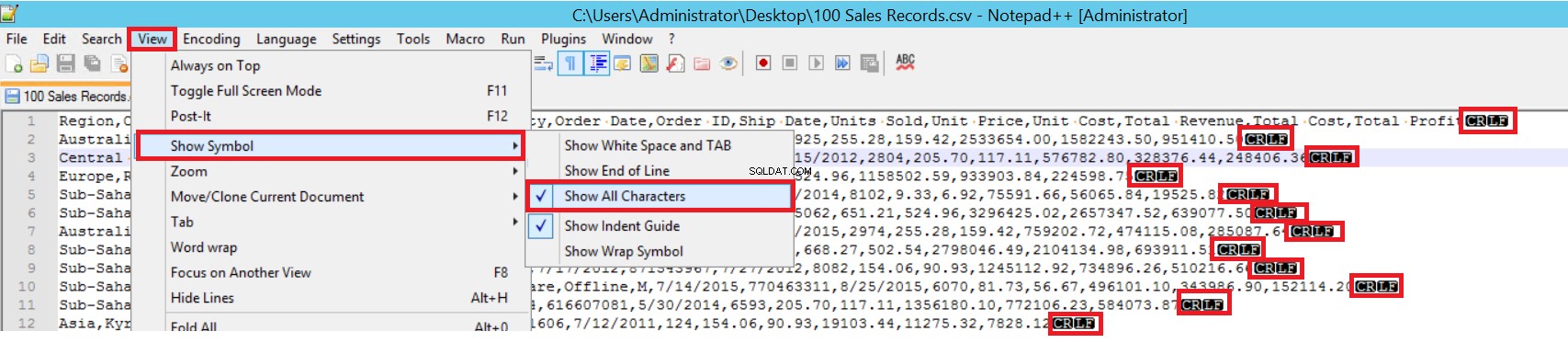
CR =Carriage Return en LF =Line Feed. Ze worden gebruikt om een regeleinde in een tekstbestand te markeren en dit wordt aangegeven door het "\n"-teken in de bulkinsert-instructie.
Een andere methode om een CSV-bestand naar een tabel te importeren met behulp van bulkinsert is het gebruik van de FORMAT-parameter. Houd er rekening mee dat de parameter FORMAT alleen beschikbaar is in SQL Server 2017 en latere versies.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
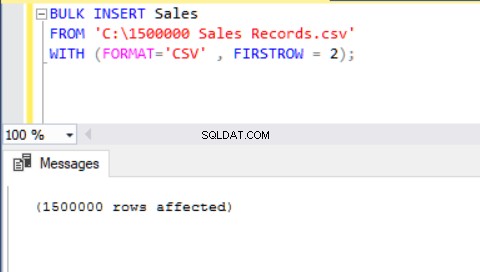
Nu gaan we een ander scenario analyseren.
Scenario-2:Bestemmingstabel heeft meer kolommen dan CSV-bestand
In dit scenario voegen we een primaire sleutel toe aan de tabel Sales en in dit geval worden de gelijkheidskolomtoewijzingen verbroken. Nu gaan we de Sales-tabel maken met een primaire sleutel, proberen het CSV-bestand te importeren via de opdracht bulk insert, en dan krijgen we een foutmelding.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
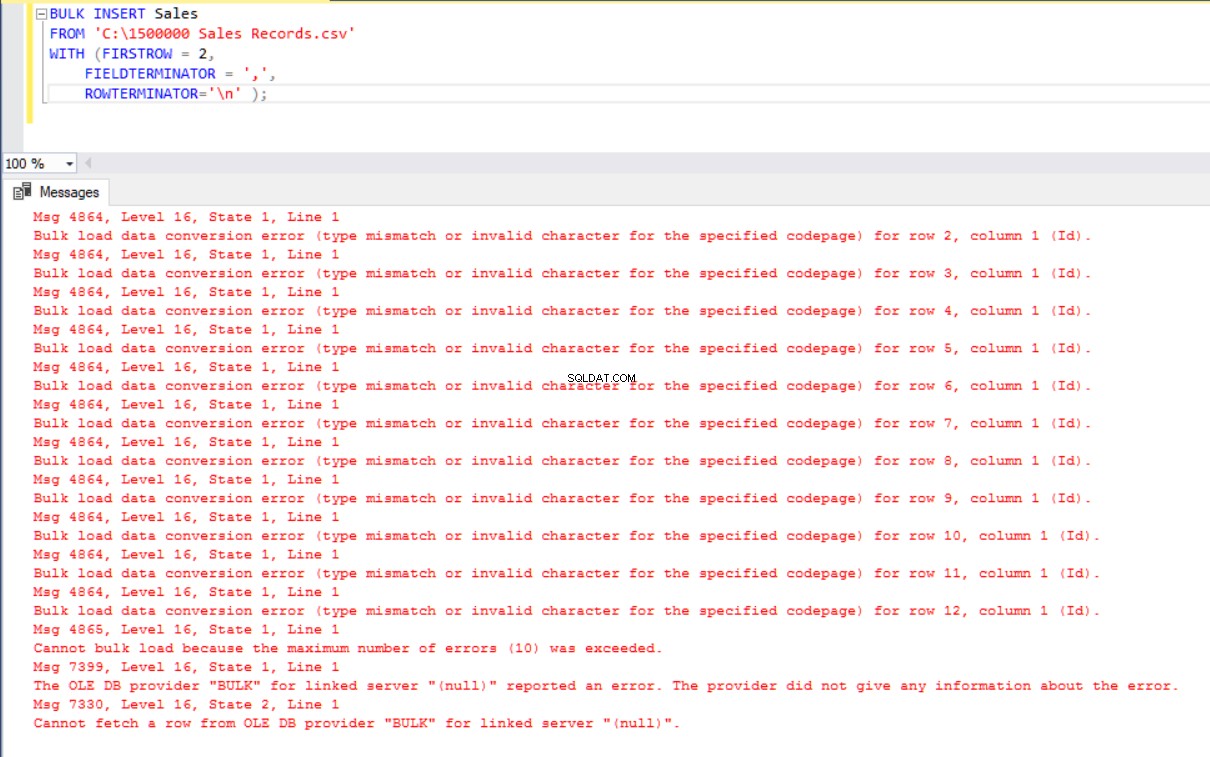
Om deze fout te verhelpen, maken we een weergave van de tabel Verkoop met toewijzingskolommen aan het CSV-bestand en importeren we de CSV-gegevens over deze weergave naar de tabel Verkoop.
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Scenario-3:hoe CSV-bestanden scheiden en in kleine batches laden?
SQL Server verkrijgt een vergrendeling naar de doeltabel tijdens de bulk-invoegbewerking. Als u de parameter BATCHSIZE niet instelt, opent SQL Server standaard een transactie en voegt de volledige CSV-gegevens in deze transactie in. Als u echter de parameter BATCHSIZE instelt, verdeelt SQL Server de CSV-gegevens volgens deze parameterwaarde. In het volgende voorbeeld verdelen we de volledige CSV-gegevens in verschillende sets van elk 300.000 rijen. De gegevens worden dus 5 keer geïmporteerd.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 );
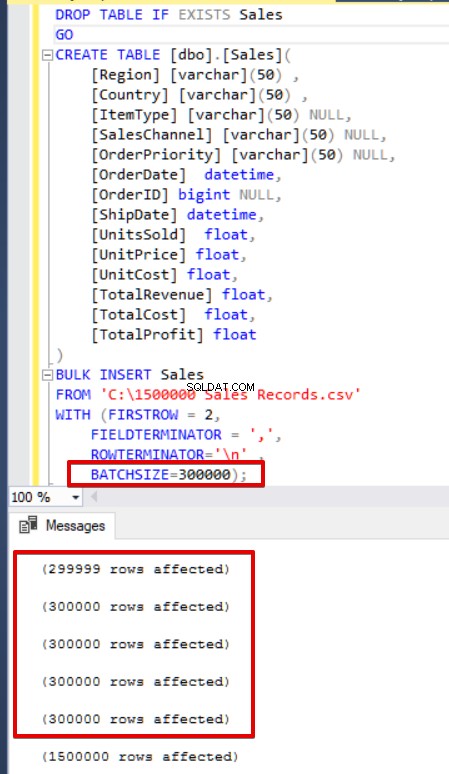
Als uw bulkinvoeginstructie de parameter batchgrootte (BATCHSIZE) niet bevat, treedt er een fout op en zal SQL Server het hele bulkinvoegproces terugdraaien. Aan de andere kant, als u de batchgrootte-parameter instelt op bulk insert-instructie, zal SQL Server alleen dit verdeelde deel terugdraaien waar de fout is opgetreden. Er is geen optimale of beste waarde voor deze parameter omdat deze parameterwaarde kan worden gewijzigd op basis van uw databasesysteemvereisten.
Scenario-4:Hoe de . te annuleren importproces bij foutmelding?
In sommige scenario's voor bulkkopie, als er een fout optreedt, willen we misschien het bulkkopieproces annuleren of het proces laten doorgaan. Met de parameter MAXERRORS kunnen we het maximale aantal fouten specificeren. Als het bulk-invoegproces deze maximale foutwaarde bereikt, wordt de bulkimportbewerking geannuleerd en teruggedraaid. De standaardwaarde voor deze parameter is 10.
In het volgende voorbeeld zullen we het gegevenstype in 3 rijen van het CSV-bestand opzettelijk corrumperen en de parameter MAXERRORS op 2 zetten. Als gevolg hiervan wordt de hele bulk-invoegbewerking geannuleerd omdat het foutnummer de parameter max error overschrijdt.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2);
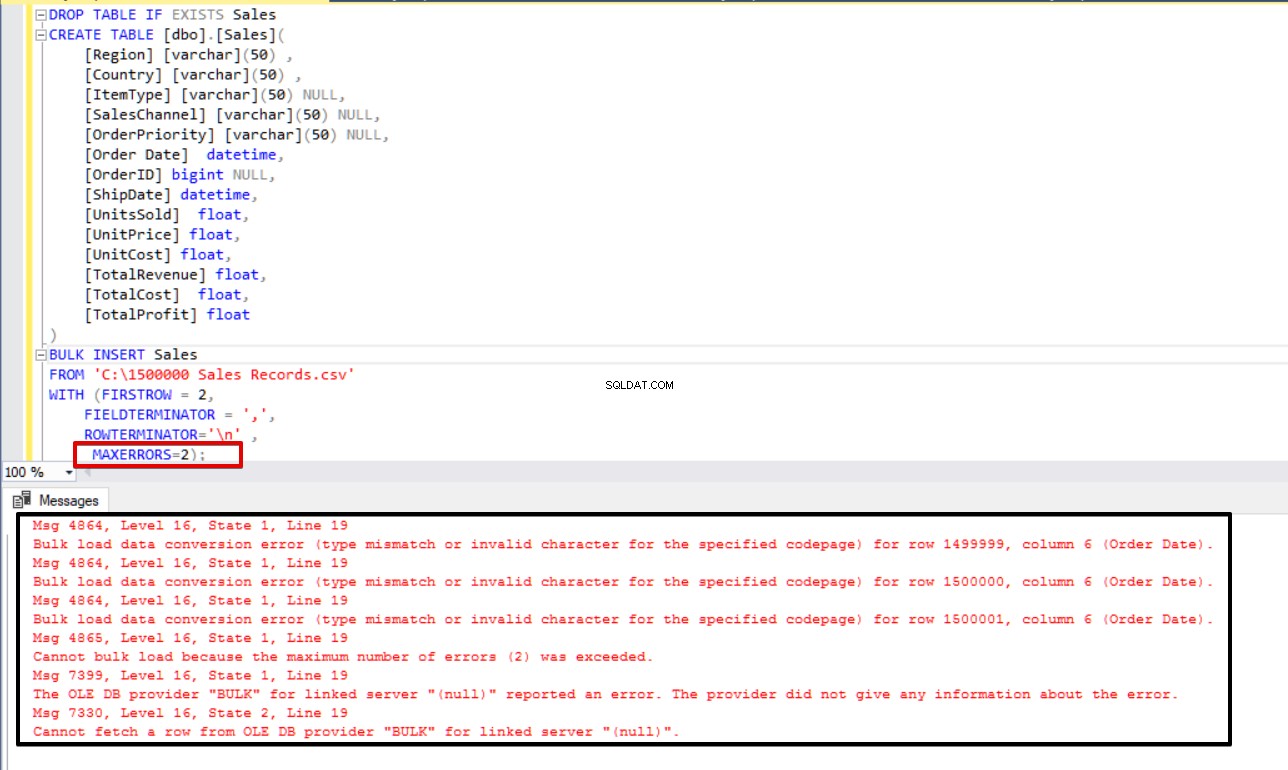
Nu zullen we de max error-parameter wijzigen in 4. Als resultaat zal de bulk insert-instructie deze rijen overslaan en de juiste gestructureerde gegevensrijen invoegen, en het bulk-invoegproces voltooien.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
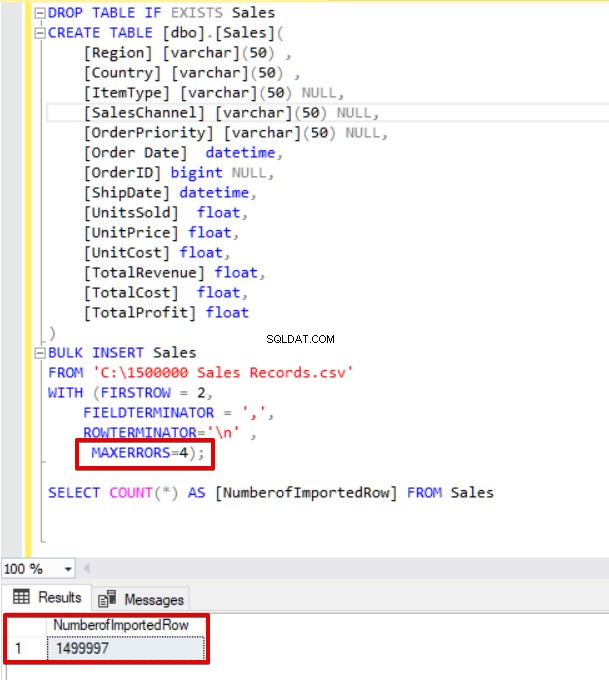
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
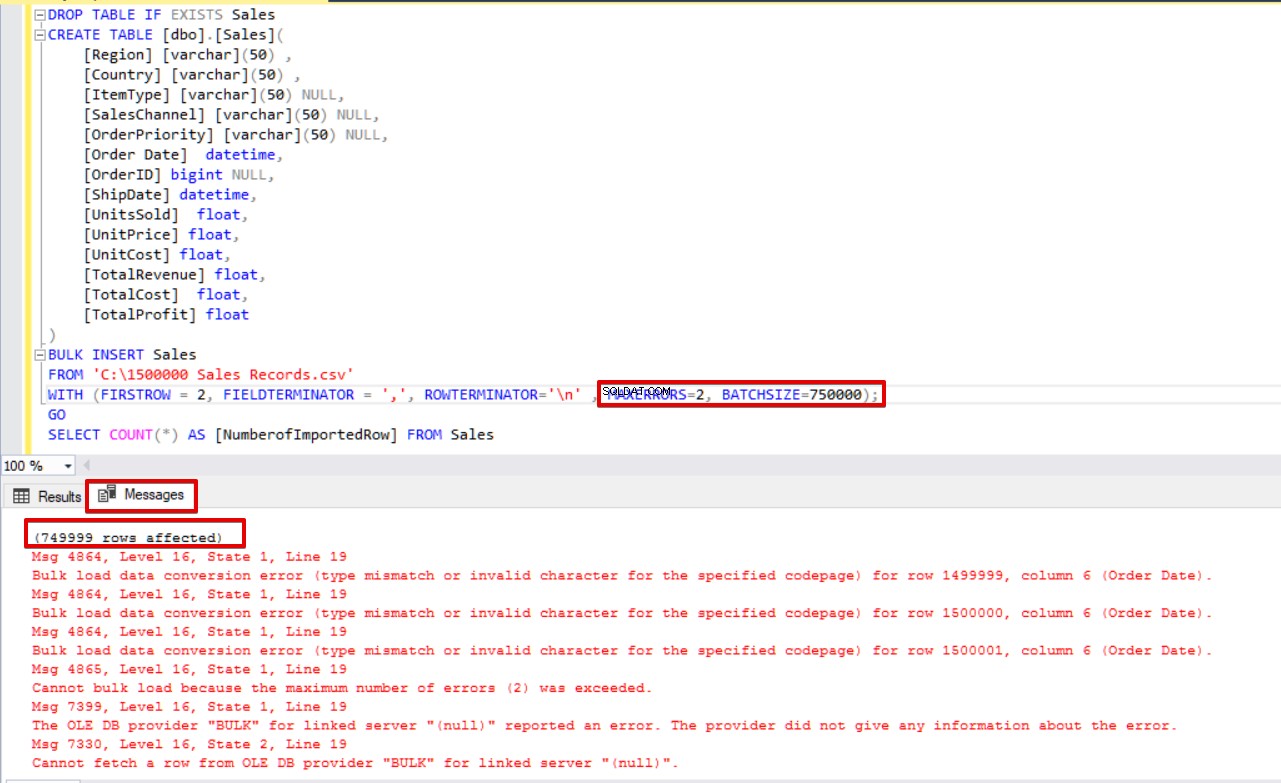
Als we bovendien beide, de batchgrootte en de maximale foutparameters tegelijkertijd gebruiken, zal het bulkkopieproces niet de hele invoegbewerking annuleren, maar alleen het verdeelde deel.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
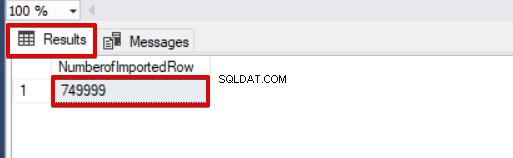
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
In dit eerste deel van deze serie artikelen hebben we de basisprincipes besproken van het gebruik van de bulk-invoegbewerking in SQL Server en hebben we verschillende scenario's geanalyseerd die dicht bij de echte problemen liggen.
SQL Server Bulk Insert – Deel 2
Nuttige links:
Bulkinsert
E voor Excel – Voorbeeld CSV-bestanden / datasets voor testen (tot 1,5 miljoen records)
Kladblok++ downloaden
Handig hulpmiddel:
dbForge Data Pump – een SSMS-invoegtoepassing voor het vullen van SQL-databases met externe brongegevens en het migreren van gegevens tussen systemen.