Inleiding
Tegenwoordig is hoge beschikbaarheid een vereiste voor veel systemen, ongeacht welke technologie je gebruikt. Dit is vooral belangrijk voor databases, omdat ze gegevens opslaan waarop kritieke applicaties en systemen vertrouwen. De meest gebruikelijke strategie voor het bereiken van hoge beschikbaarheid is replicatie. Er zijn verschillende manieren om gegevens over meerdere servers en failover-verkeer te repliceren wanneer bijvoorbeeld een primaire server niet meer reageert.
Architectuur met hoge beschikbaarheid voor PostgreSQL
Er zijn verschillende architecturen voor het implementeren van hoge beschikbaarheid in PostgreSQL, maar de basis zijn Primary-Standby en Primary-Primary architecturen.
Primaire-stand-by-architecturen
Primary-Standby is misschien wel de meest elementaire HA-architectuur die je kunt opzetten en vaak ook het gemakkelijkst te implementeren en te onderhouden. Het is gebaseerd op één primaire database met een of meer standby-servers. Deze standby-databases blijven gesynchroniseerd (of bijna gesynchroniseerd) met het primaire knooppunt, afhankelijk van of de replicatie synchroon of asynchroon is. Als de primaire server uitvalt, bevat de standby-server bijna alle gegevens van de primaire server en kan deze snel worden omgezet in de nieuwe primaire databaseserver.
U kunt twee typen Standby-databases implementeren, afhankelijk van de aard van de replicatie:
- Logische stand-by:de replicatie tussen primair en stand-by gebeurt via SQL-instructies.
- Fysieke stand-by:de replicatie tussen primair en stand-by vindt plaats via de interne wijzigingen in de gegevensstructuur.
In het geval van PostgreSQL wordt een stroom van write-ahead log (WAL)-records gebruikt om de Standby-databases gesynchroniseerd te houden. Dit kan synchroon of asynchroon zijn en de hele databaseserver wordt gerepliceerd.
Vanaf versie 10 bevat PostgreSQL een ingebouwde optie om logische replicatie in te stellen, die een stroom van logische gegevenswijzigingen opbouwt op basis van de informatie in het vooruitschrijflogboek. Met deze replicatiemethode kunnen de gegevenswijzigingen van afzonderlijke tabellen worden gerepliceerd zonder dat een primaire server hoeft te worden aangewezen. Het zorgt er ook voor dat gegevens in meerdere richtingen kunnen stromen.
Helaas is een Primary-Standby setup niet voldoende om effectief hoge beschikbaarheid te garanderen, aangezien je ook storingen moet afhandelen. Om storingen aan te pakken, moet u ze kunnen detecteren. Zodra u weet dat er een storing is, bijvoorbeeld fouten op het primaire knooppunt of het knooppunt dat niet reageert, kunt u een stand-byknooppunt selecteren om het defecte knooppunt met zo min mogelijk vertraging te vervangen. Dit proces moet zo efficiënt mogelijk zijn om de volledige functionaliteit van de applicaties te herstellen. PostgreSQL zelf bevat geen automatisch failover-mechanisme, dus dit vereist een aangepast script of tools van derden voor deze automatisering.
Nadat er een failover heeft plaatsgevonden, moet uw toepassing hiervan op de hoogte worden gesteld om de nieuwe Primary te gaan gebruiken. U moet ook de status van uw architectuur na een failover evalueren, omdat u een situatie kunt tegenkomen waarin alleen de nieuwe primaire wordt uitgevoerd (u had bijvoorbeeld een primair knooppunt en slechts één stand-by vóór het probleem). In dat geval moet u een Standby-knooppunt toevoegen om de Primary-Standby-configuratie opnieuw te maken die u oorspronkelijk had voor hoge beschikbaarheid.
Primair-Primaire architecturen
Primair-Primaire architectuur biedt een manier om de impact van een fout op een van de nodes te minimaliseren, aangezien de andere node(s) voor al het verkeer kunnen zorgen en de prestaties mogelijk slechts in geringe mate beïnvloeden maar nooit functionaliteit verliezen. Primair-primaire architectuur wordt vaak gebruikt met het dubbele doel om een omgeving met hoge beschikbaarheid te creëren en horizontaal te schalen (in vergelijking met het concept van verticale schaalbaarheid waarbij u meer bronnen aan een server toevoegt).
PostgreSQL ondersteunt deze architectuur nog niet "native", dus je zult moeten verwijzen naar tools en implementaties van derden. Houd er bij het kiezen van een oplossing rekening mee dat er veel projecten/tools zijn, maar sommige worden niet meer ondersteund, terwijl andere nieuw zijn en mogelijk niet in productie zijn getest.
Load Balancing
Load balancers zijn tools die kunnen worden gebruikt om het verkeer van uw applicatie te beheren om het meeste uit uw database-architectuur te halen.
Deze hulpprogramma's zijn niet alleen nuttig bij het balanceren van de belasting van uw databases, maar ze helpen ook toepassingen om te leiden naar de beschikbare/gezonde knooppunten en zelfs om poorten met verschillende rollen te specificeren.
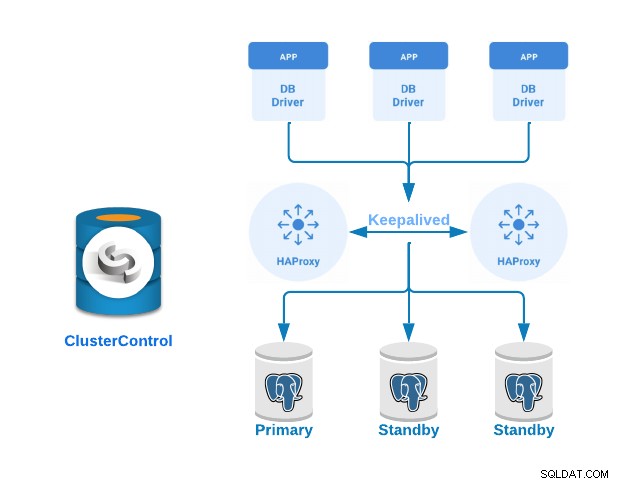
HAProxy is een load balancer die verkeer van de ene herkomst naar een of meer bestemmingen verdeelt en specifieke regels en/of protocollen voor deze taak kan definiëren. Als een van de bestemmingen niet meer reageert, worden ze gemarkeerd als offline en wordt het verkeer naar de rest van de beschikbare bestemmingen gestuurd.
Keepalived is een service waarmee je een virtueel IP-adres kunt configureren binnen een actieve/passieve groep servers. Dit virtuele IP-adres wordt toegewezen aan een actieve server. Als deze server uitvalt, wordt het IP-adres automatisch gemigreerd naar de "Secundaire" passieve server, waardoor deze op een transparante manier voor de systemen met hetzelfde IP-adres kan blijven werken.
Laten we eens kijken hoe we een Primary-Standby PostgreSQL-cluster kunnen implementeren met load balancer-servers en daartussen geconfigureerde keepalives. We zullen dit demonstreren met behulp van de gebruiksvriendelijke interface van ClusterControl.
Voor dit voorbeeld maken we:
- 3 PostgreSQL-servers (één primaire en twee standby-servers).
- 2 HAProxy Load Balancers.
- Keepalived geconfigureerd tussen de load balancer-servers.
Database-implementatie
Als u een database wilt implementeren met ClusterControl, selecteert u gewoon de optie "Deploy" en volgt u de instructies die verschijnen.
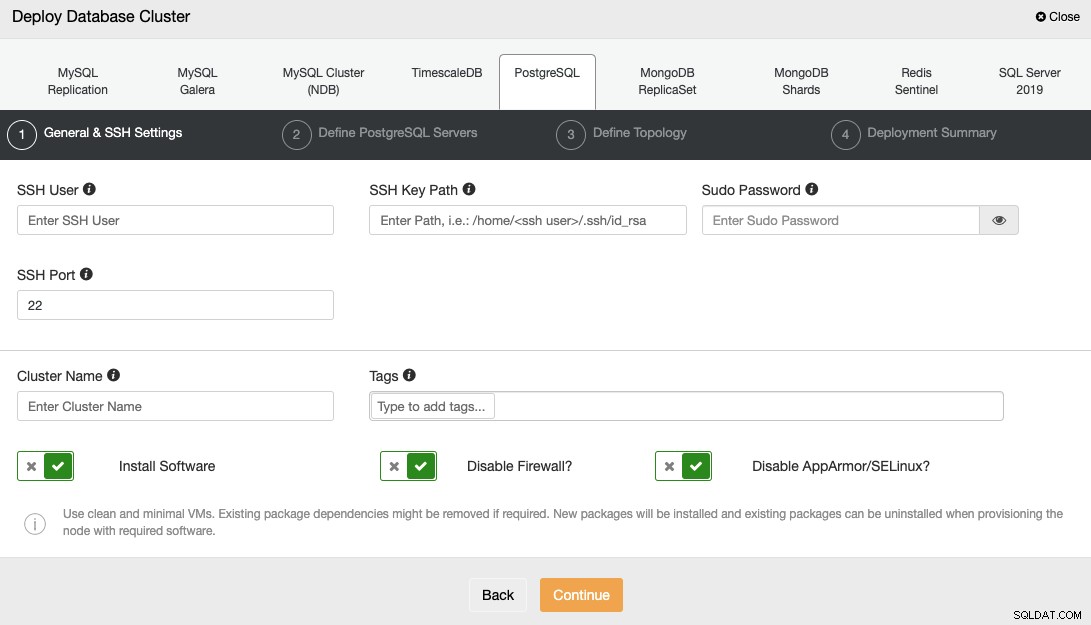
Als u PostgreSQL selecteert, moet u de gebruiker, de sleutel of het wachtwoord opgeven en Poort om via SSH verbinding te maken met uw servers. U heeft ook de naam van uw nieuwe cluster nodig en kiest of u wilt dat ClusterControl de bijbehorende software en configuraties voor u installeert.
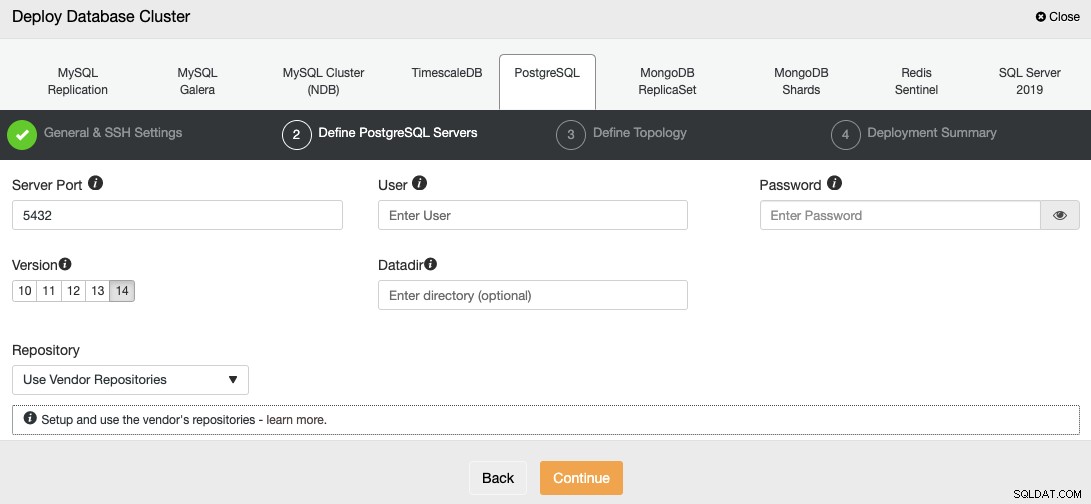
Na het instellen van de SSH-toegangsinformatie, moet u de databasegebruiker definiëren, versie en datadir (optioneel). U kunt ook aangeven welke repository u wilt gebruiken; de officiële repository van de leverancier wordt standaard gebruikt.
In de volgende stap moet u uw servers toevoegen aan het cluster dat u gaat maken.
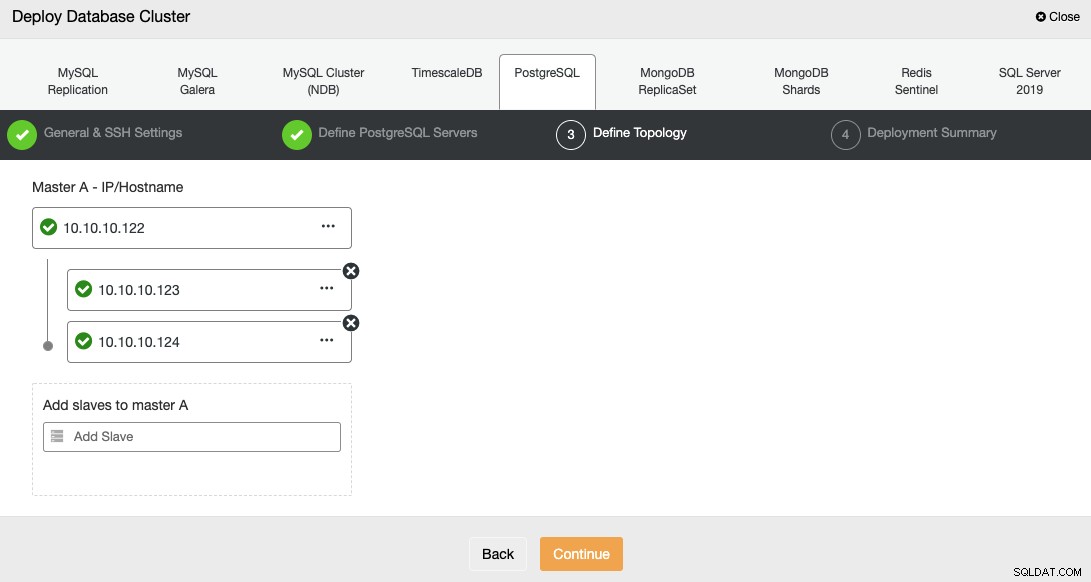
Bij het toevoegen van uw servers kunt u IP of hostnaam invoeren.
In de laatste stap kunt u kiezen of uw replicatie synchroon of asynchroon zal zijn.
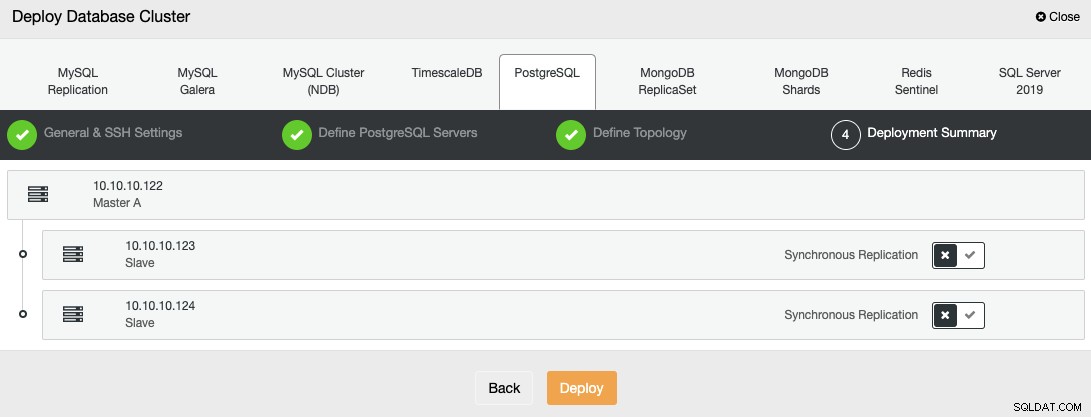
U kunt de status van het maken van uw nieuwe cluster volgen via ClusterControl activiteitenmonitor.
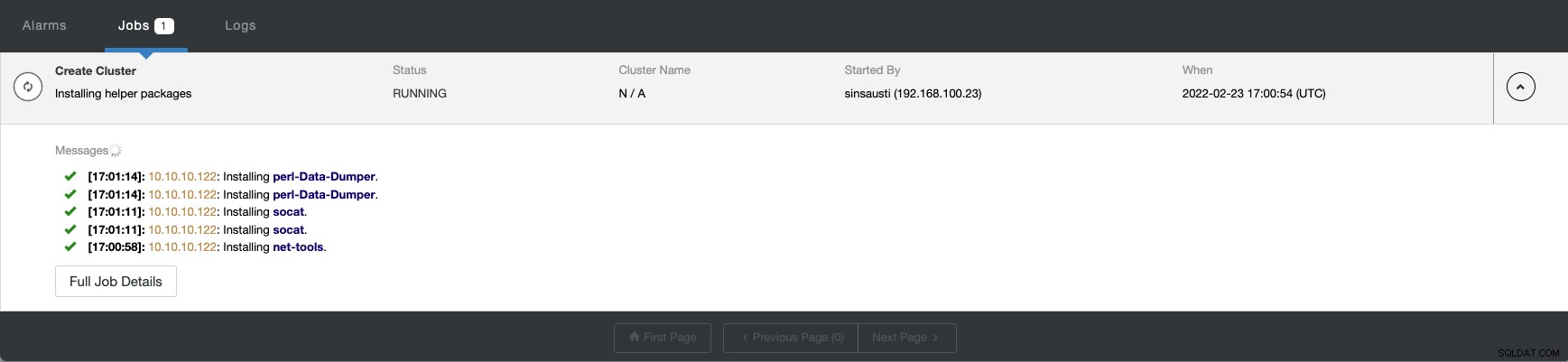
Zodra de taak is voltooid, kunt u uw cluster zien in de hoofd ClusterControl scherm.
Zodra uw cluster is gemaakt, kunt u verschillende taken uitvoeren, zoals het toevoegen van een load balancer (HAProxy) of een nieuwe replica.
Load Balancer-implementatie
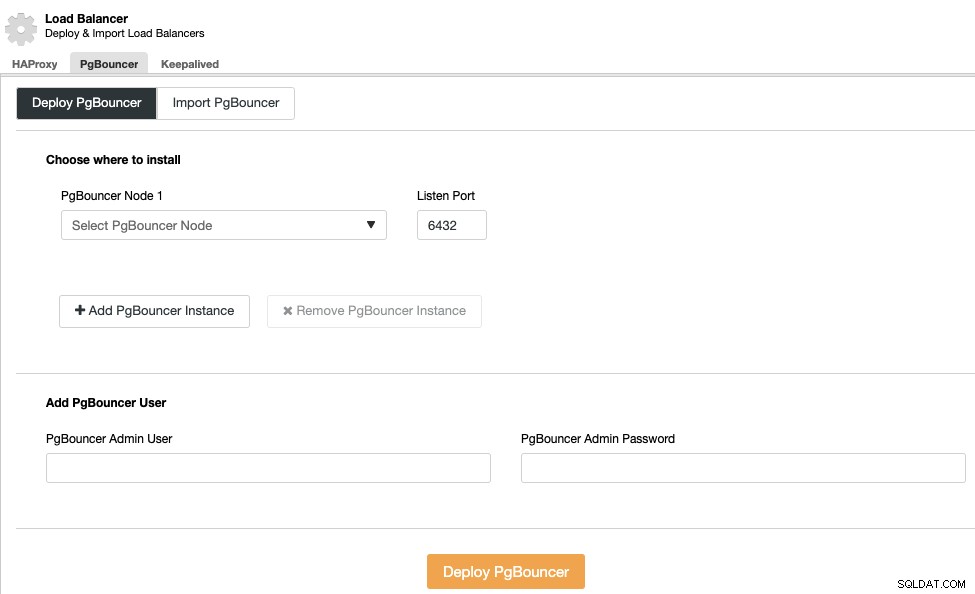
Als u een load balancer-implementatie wilt uitvoeren, selecteert u de optie "Load Balancer toevoegen" in de clusteracties en vult u de gevraagde informatie in.
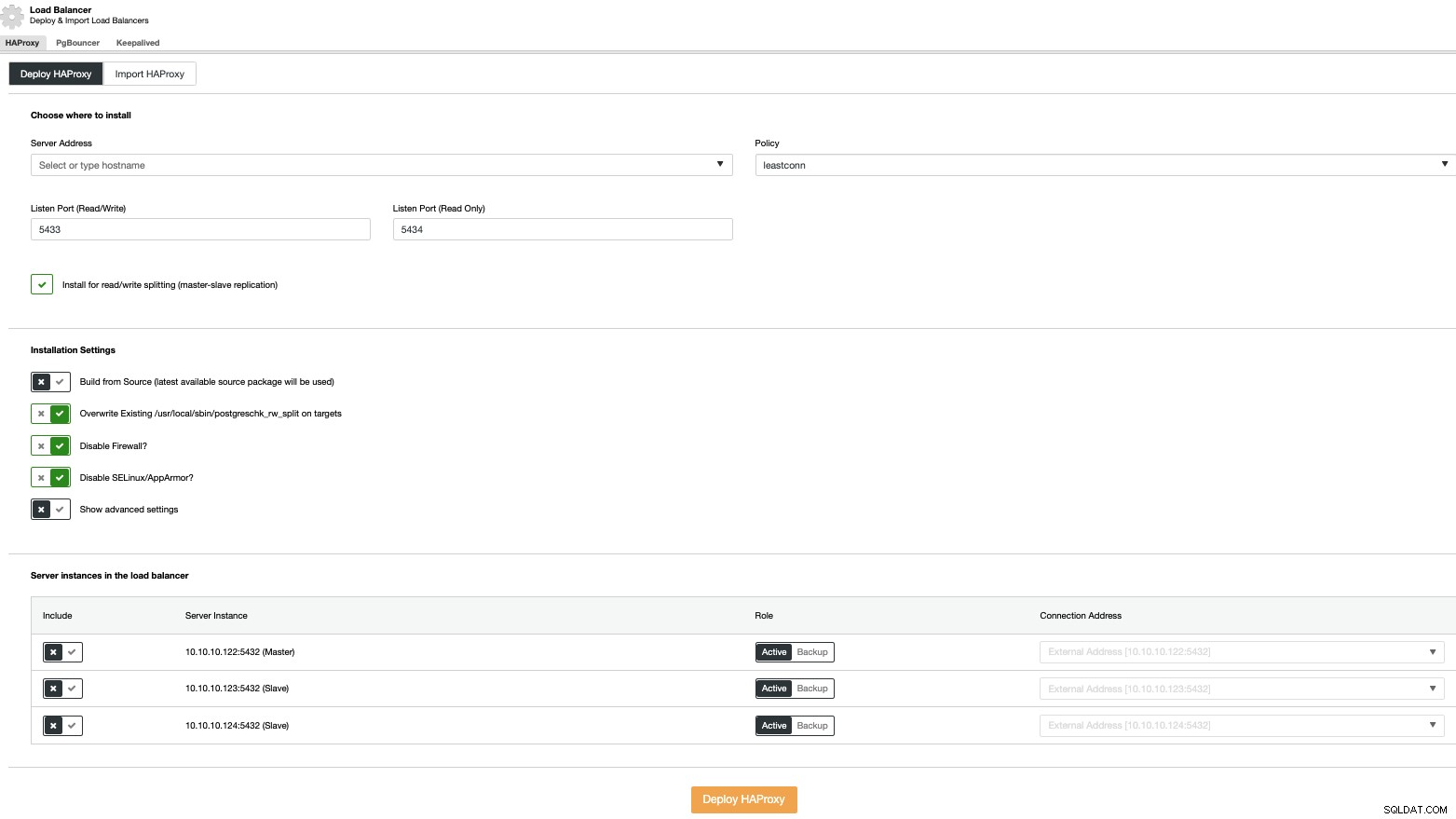
U hoeft alleen het IP-adres of de hostnaam, poort, beleid, en de knooppunten die u in uw load balancers gaat configureren.
Behoud implementatie
Als u een keepalive-implementatie wilt uitvoeren, selecteert u het cluster, gaat u naar het menu 'Beheren' en de sectie 'Load Balancer' en selecteert u vervolgens de optie 'Keepalived'.
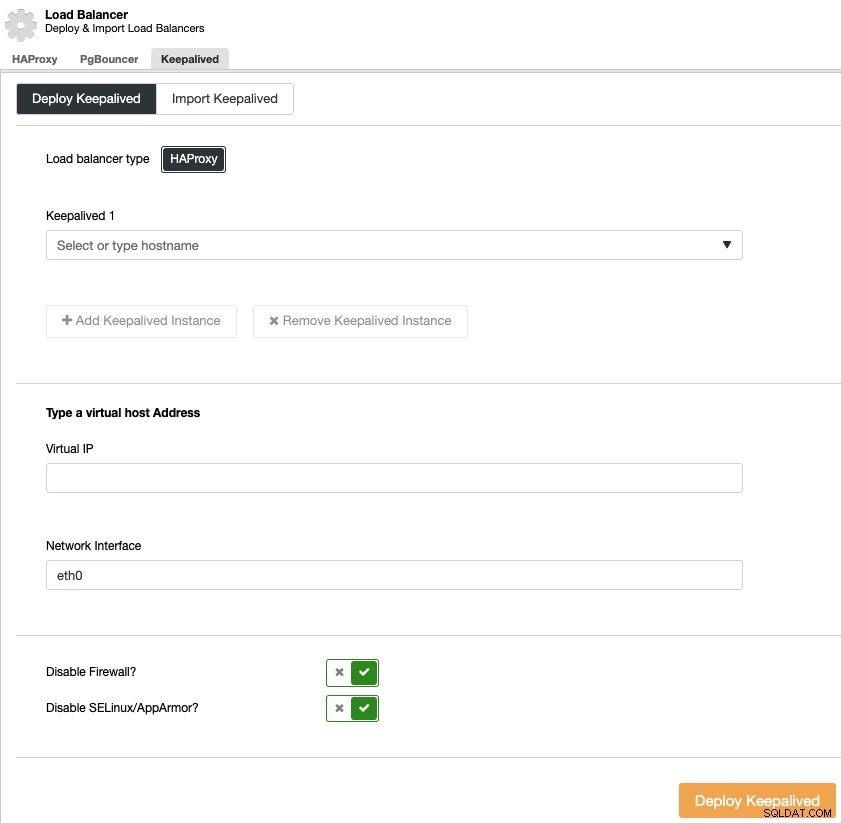
U moet de load balancer-servers en het virtuele IP-adres voor uw hoge beschikbaarheidsomgeving.
Keepalived gebruikt het virtuele IP-adres en migreert het van de ene load balancer naar de andere in geval van storing, zodat uw systemen normaal kunnen blijven functioneren.
Als je de vorige stappen hebt gevolgd, zou je de volgende topologie moeten hebben:
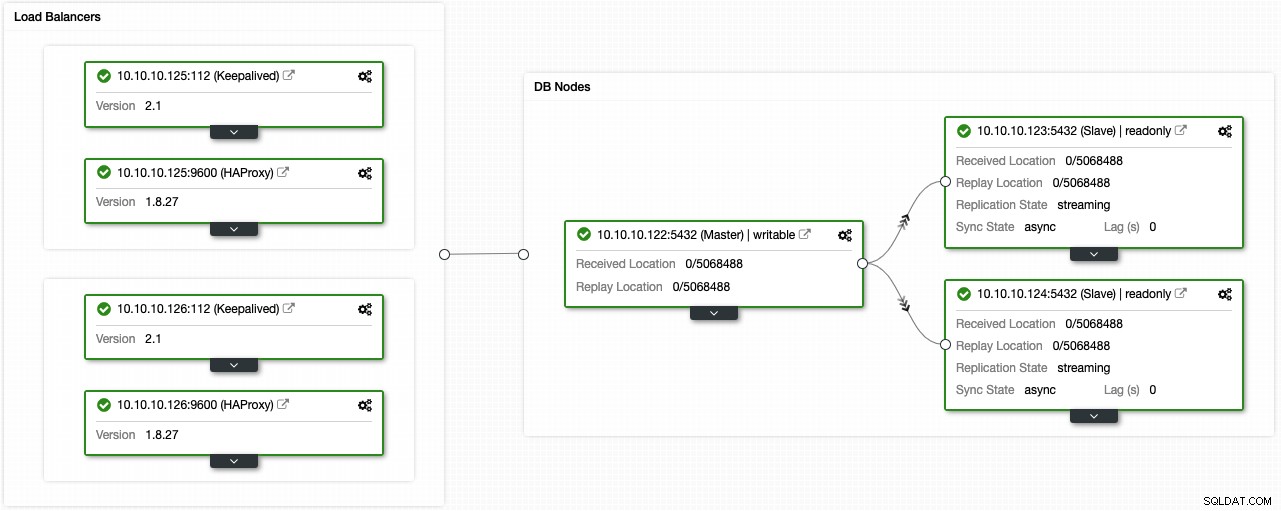
U kunt deze omgeving met hoge beschikbaarheid verbeteren door een verbindingspooler zoals PgBouncer toe te voegen. Het is geen must, maar kan nuttig zijn om de prestaties te verbeteren en actieve verbindingen af te handelen in geval van storing, en het beste is dat u het ook kunt implementeren met ClusterControl.
ClusterControl-failover
Stel dat de optie "Autorecovery" is ingeschakeld op uw ClusterControl-server. In het geval van een primaire storing, zal ClusterControl de meest geavanceerde Standby (als deze niet op de zwarte lijst staat) promoveren naar Primair en u op de hoogte stellen van het probleem. Het zal ook een failover uitvoeren voor de rest van de Standby-knooppunten om te repliceren vanuit de nieuwe Primary.
HAProxy is standaard geconfigureerd met twee verschillende poorten; read-write en read-only poorten.
In uw lees-schrijfpoort heeft u uw primaire server als online en de rest van uw knooppunten als offline, en in de alleen-lezenpoort heeft u zowel de primaire als de stand-by-server online.
Als HAProxy detecteert dat een van uw nodes, ofwel Primair ofwel Stand-by, niet toegankelijk is, wordt deze automatisch gemarkeerd als offline. Het houdt er geen rekening mee om er verkeer naar toe te sturen. Detectie wordt uitgevoerd door scripts voor statuscontrole die ClusterControl configureert op het moment van implementatie. Deze controleren of de instanties actief zijn, of ze worden hersteld of alleen-lezen zijn.
Als ClusterControl een stand-by naar primair promoot, markeert uw HAProxy de oude primaire als offline voor beide poorten en plaatst het gepromote knooppunt online in de lees-schrijfpoort.
Als uw actieve HAProxy, die het virtuele IP-adres heeft toegewezen waarmee uw systemen verbinding maken, faalt, migreert Keepalive dit IP-adres automatisch naar uw passieve HAProxy. Dit betekent dat uw systemen dan normaal kunnen blijven functioneren.
Op deze manier blijven uw systemen werken zoals verwacht en zonder uw handmatige tussenkomst.
Overwegingen
Als het je lukt om je oude mislukte primaire node te herstellen, wordt deze standaard NIET automatisch opnieuw in het cluster geïntroduceerd. Je moet het handmatig doen. Een reden hiervoor is dat als uw replica op het moment van de storing vertraging heeft opgelopen en ClusterControl de oude Primary aan het cluster toevoegt, dit verlies van informatie of inconsistentie van gegevens tussen de knooppunten zou betekenen. Misschien wilt u het probleem ook in detail analyseren. Als ClusterControl het defecte knooppunt opnieuw in het cluster zou introduceren, zou u mogelijk diagnostische informatie verliezen.
Als de failover mislukt, worden er ook geen verdere pogingen ondernomen. Handmatig ingrijpen is vereist om het probleem te analyseren en de bijbehorende acties uit te voeren. Dit om te voorkomen dat ClusterControl, als high availability manager, de volgende Standby en de volgende probeert te promoten. Er is mogelijk een probleem en u moet dit controleren.
Beveiliging
Een belangrijk ding dat u niet mag vergeten voordat u in productie gaat met uw omgeving met hoge beschikbaarheid, is het waarborgen van de beveiliging ervan.
Verschillende beveiligingsaspecten waarmee u rekening moet houden, zijn onder meer versleuteling, rolbeheer en toegangsbeperking per IP-adres, die we in een vorige blog uitgebreid hebben besproken.
In uw PostgreSQL-database heeft u het bestand pg_hba.conf, dat de clientverificatie afhandelt. U kunt het type verbinding, het bron-IP-adres of netwerk beperken, met welke database u verbinding kunt maken en met welke gebruikers. Daarom is dit bestand een cruciaal onderdeel voor PostgreSQL-beveiliging.
U kunt uw PostgreSQL-database configureren vanuit het postgresql.conf-bestand, zodat het alleen luistert op een specifieke netwerkinterface en een andere poort dan de standaardpoort (5432), waardoor elementaire verbindingspogingen van ongewenste bronnen worden vermeden .
Goed gebruikersbeheer, ofwel door veilige wachtwoorden te gebruiken of toegang en privileges te beperken, is een ander essentieel onderdeel van uw beveiligingsinstellingen. Het wordt aanbevolen dat u zo min mogelijk rechten toewijst aan alle gebruikers en, indien mogelijk, de bron van de verbinding specificeert.
U kunt ook gegevensversleuteling inschakelen, zowel in transit als in rust, om toegang tot informatie voor onbevoegde personen te vermijden.
Een controlelogboek is handig om te begrijpen wat er in uw database gebeurt of is gebeurd. Met PostgreSQL kunt u verschillende parameters configureren voor logboekregistratie of zelfs de pgAudit-extensie voor deze taak gebruiken.
Last but not least, het wordt aanbevolen om je database en servers up-to-date te houden met de nieuwste patches om veiligheidsrisico's te voorkomen. Hiervoor kunt u met ClusterControl operationele rapporten genereren om te controleren of u over updates beschikt en zelfs om uw databaseservers bij te werken.
Conclusie
Installaties met hoge beschikbaarheid kunnen moeilijk te realiseren lijken, vooral als het gaat om het begrijpen van de verschillende architecturen en benodigde componenten om ze correct te configureren.
Als u HA handmatig beheert, moet u zeker eens kijken naar Replicatietopologiewijzigingen uitvoeren voor PostgreSQL. Velen zullen op zoek gaan naar tools zoals ClusterControl om de implementatie, load balancers, failover, beveiliging en meer te helpen beheren voor een complete omgeving met hoge beschikbaarheid. U kunt ClusterControl 30 dagen gratis downloaden om te zien hoe het de last van het beheer van een database-infrastructuur met hoge beschikbaarheid kan verlichten.
Hoe u uw PostgreSQL-databases met hoge beschikbaarheid ook wilt beheren, zorg ervoor dat u ons volgt op Twitter of LinkedIn, of abonneer u op onze nieuwsbrief voor de laatste updates en best practices voor het beheren van uw database-instellingen.