Al mijn berichten van dit jaar gingen over reflexmatige reacties op wachtstatistieken, maar in dit bericht wijk ik af van dat thema om te praten over een bepaalde bugbeer van mij:de prestatieteller van de paginalevensverwachting (die ik PLE noem ).
Wat betekent PLE?
Er zijn allerlei onjuiste uitspraken over de levensverwachting van pagina's op internet, en de meest flagrante zijn die waarin wordt aangegeven dat de waarde 300 de drempel is waarvoor u zich zorgen moet maken.
Om te begrijpen waarom deze verklaring zo misleidend is, moet u begrijpen wat PLE eigenlijk is.
De definitie van PLE is de verwachte tijd, in seconden, dat een gegevensbestandspagina die in de bufferpool wordt gelezen (de in-memory cache van gegevensbestandspagina's) in het geheugen blijft voordat deze uit het geheugen wordt gepusht om ruimte te maken voor andere gegevens bestandspagina. Een andere manier om aan PLE te denken is een onmiddellijke meting van de druk op de bufferpool om vrije ruimte te maken voor pagina's die van schijf worden gelezen. Voor beide definities is een hoger getal beter.
Wat is een goede PLE-drempel?
Een PLE van 300 betekent dat uw volledige bufferpool effectief wordt gespoeld en elke vijf minuten opnieuw wordt gelezen. Toen de drempelwaarde voor PLE van 300 voor het eerst werd gegeven door Microsoft, rond 2005/2006, was dat aantal misschien logischer omdat de gemiddelde hoeveelheid geheugen op een server veel lager was.
Tegenwoordig, waar servers routinematig 64 GB, 128 GB en grotere hoeveelheden geheugen hebben, zou het waarschijnlijk de oorzaak zijn van een verlammend prestatieprobleem wanneer ongeveer elke vijf minuten ongeveer zoveel gegevens van de schijf worden gelezen.
In werkelijkheid, tegen de tijd dat PLE op of onder de 300 zweeft, is uw server al in zwaar weer. Je zou je al zorgen gaan maken, lang voordat de PLE zo laag is.
Dus wat is de drempel die je moet gebruiken als je je zorgen zou moeten maken?
Nou, dat is precies het punt. Ik kan je geen drempel geven, want dat aantal zal voor iedereen verschillen. Als je echt heel graag een getal wilt gebruiken, heeft mijn collega Jonathan Kehayias een formule bedacht:
( Bufferpoolgeheugen in GB / 4 ) x 300Zelfs dat aantal is enigszins willekeurig en uw kilometerstand zal variëren.
Ik hou er niet van om cijfers aan te bevelen. Mijn advies is om je PLE te meten wanneer de prestaties op het gewenste niveau zijn - dat is de drempel die u gebruikt.
Begint u zich dus zorgen te maken zodra PLE onder die drempel zakt? Nee. Je begint je zorgen te maken wanneer PLE onder die drempel zakt en onder die drempel blijft, of als het plotseling daalt en je weet niet waarom.
Dit komt omdat er enkele bewerkingen zijn die een PLE-drop veroorzaken (bijvoorbeeld het uitvoeren van DBCC CHECKDB of index-reconstructies kunnen het soms doen) en zijn geen reden tot bezorgdheid. Maar als u een grote PLE-daling ziet en u weet niet wat de oorzaak is, dan moet u zich zorgen maken.
Je vraagt je misschien af hoe DBCC CHECKDB kan een PLE-daling veroorzaken wanneer het ongunstig is en hard probeert te voorkomen dat de bufferpool wordt leeggemaakt met de gegevens die het gebruikt (zie deze blogpost voor een uitleg). Het is omdat de geheugentoekenning voor het uitvoeren van de query voor DBCC CHECKDB wordt verkeerd berekend door de Query Optimizer en kan een grote vermindering van de bufferpool veroorzaken (het geheugen voor de toekenning wordt gestolen uit de bufferpool) en een daaruit voortvloeiende daling van PLE.
Hoe controleer je PLE?
Dit is het lastige. De meeste mensen gaan direct naar de Buffer Manager prestatieobject in PerfMon en controleer de Page life expectancy balie. Is dit de juiste aanpak? Waarschijnlijk niet.
Ik zou zeggen dat een grote meerderheid van de servers die er tegenwoordig zijn, NUMA-architectuur gebruikt, en dit heeft een diepgaand effect op hoe je PLE bewaakt.
Bij NUMA wordt de bufferpool opgesplitst in buffernodes, met één buffernode per NUMA-node die SQL Server kan ‘zien’. Elk bufferknooppunt volgt PLE afzonderlijk en de Buffer Manager:Page life expectancy teller is het gemiddelde van de bufferknooppunt PLE's. Als u alleen de algehele bufferpool PLE bewaakt, kan de druk op een van de bufferknooppunten worden gemaskeerd door het gemiddelde (ik bespreek dit in een blogpost hier).
Dus als uw server NUMA gebruikt, moet u de individuele Buffer Node:Page life expectancy controleren tellers (er is één prestatieobject voor bufferknooppunten voor elk NUMA-knooppunt), anders houdt u de Buffer Manager:Page life expectancy goed in de gaten teller.
Nog beter is om een monitoringtool zoals SQL Sentry Performance Advisor te gebruiken, die deze teller als onderdeel van het dashboard toont, rekening houdend met de NUMA-knooppunten op de server, en waarmee u eenvoudig waarschuwingen kunt configureren.
Voorbeelden van het gebruik van Performance Advisor
Hieronder ziet u een voorbeeldgedeelte van een schermopname van Performance Advisor voor een systeem met één NUMA-knooppunt:
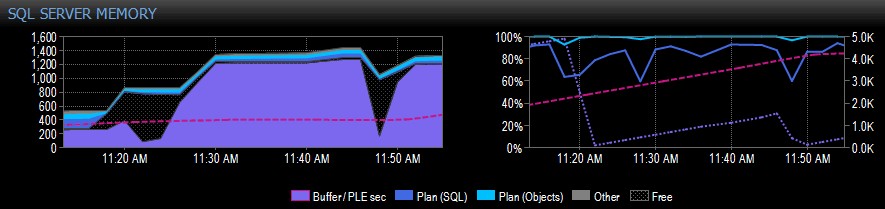
Aan de rechterkant van de vangst is de roze stippellijn de PLE tussen 10.30 uur en ongeveer 11.20 uur - het stijgt gestaag tot 5.000 of zo, een heel gezond aantal. Even voor 11.20 uur is er een enorme daling, en dan begint het weer te stijgen tot 11.45 uur, waar het weer daalt.
Dit is typisch wat u zou zien als de bufferpool vol is, met alle pagina's die worden gebruikt, en dan wordt een query uitgevoerd die ervoor zorgt dat een enorme hoeveelheid verschillende gegevens van de schijf worden gelezen, waardoor veel van wat zich al in het geheugen bevindt, wordt verplaatst en een steile daling in PLE. Als je niet wist wat zoiets veroorzaakte, zou je het willen onderzoeken, zoals ik verderop beschrijf.
Als tweede voorbeeld is de onderstaande schermopname van een van onze Remote DBA-clients waar de server twee NUMA-knooppunten heeft (u kunt zien dat er twee paarse PLE-lijnen zijn), en waar we Performance Advisor uitgebreid gebruiken:

Op de server van deze client wordt elke ochtend rond 5 uur 's ochtends een taak voor indexonderhoud en consistentiecontrole gestart die ervoor zorgt dat de PLE in beide bufferknooppunten valt. Dit is verwacht gedrag, dus het is niet nodig om het te onderzoeken zolang de PLE gedurende de dag weer stijgt.
Wat kunt u doen aan het laten vallen van PLE?
Als de oorzaak van de PLE-daling niet bekend is, kunt u een aantal dingen doen:
- Als het probleem zich nu voordoet, onderzoek dan welke query's leesacties veroorzaken met behulp van de
sys.dm_os_waiting_tasksDMV om te zien welke threads wachten op pagina's die van schijf worden gelezen (d.w.z. threads die wachten opPAGEIOLATCH_SH), en repareer vervolgens die zoekopdrachten. - Als het probleem zich in het verleden heeft voorgedaan, kijkt u in de DMV sys.dm_exec_query_stats voor query's met een hoog aantal fysieke leesbewerkingen, of gebruikt u een controletool die u die informatie kan geven (bijvoorbeeld de Top SQL-weergave in Performance Advisor), en repareer vervolgens die vragen.
- Correleer de PLE-drop met geplande agenttaken die databaseonderhoud uitvoeren.
- Zoek naar query's met zeer grote geheugentoekenningen voor het uitvoeren van query's met behulp van de
sys.dm_exec_query_memory_grantsDMV, en repareer vervolgens die vragen.
Mijn vorige post hier legt meer uit over #1 en #2, en een script om wachttijden op een server te onderzoeken en een link naar hun queryplannen is hier te vinden.
De "repareer die vragen" valt buiten het bestek van dit bericht, dus ik laat dat voor een andere keer of als een oefening voor de lezer ☺
Samenvatting
Trap niet in de val van het geloven van een aanbevolen PLE-drempel die u online zou kunnen lezen. De beste manier om te reageren op PLE-wijzigingen is wanneer PLE onder wat dan ook daalt uw comfortniveau is en blijft daar - dat is de indicatie van een prestatieprobleem dat u moet onderzoeken.
In het volgende artikel in de serie bespreek ik een andere veelvoorkomende oorzaak van het automatisch afstemmen van prestaties. Tot dan, veel plezier met het oplossen van problemen!