Dit artikel is het zevende deel van een serie over benoemde tabeluitdrukkingen. In Deel 5 en Deel 6 heb ik de conceptuele aspecten van gemeenschappelijke tabeluitdrukkingen (CTE's) behandeld. Deze en volgende maand richt mijn aandacht zich op optimalisatieoverwegingen van CTE's.
Ik zal beginnen met het snel opnieuw bekijken van het ont-nestingsconcept van benoemde tabeluitdrukkingen en de toepasbaarheid ervan op CTE's demonstreren. Ik zal dan mijn aandacht richten op overwegingen van volharding. Ik zal het hebben over persistentieaspecten van recursieve en niet-recursieve CTE's. Ik zal uitleggen wanneer het zinvol is om vast te houden aan CTE's dan wanneer het eigenlijk zinvoller is om met tijdelijke tabellen te werken.
In mijn voorbeelden blijf ik de voorbeelddatabases TSQLV5 en PerformanceV5 gebruiken. U kunt het script dat TSQLV5 maakt en vult hier vinden en het ER-diagram hier. Je kunt het script dat PerformanceV5 maakt en vult hier vinden.
Vervanging/ontnesting
In deel 4 van de serie, die gericht was op de optimalisatie van afgeleide tabellen, beschreef ik een proces van het verwijderen/vervangen van tabeluitdrukkingen. Ik heb uitgelegd dat wanneer SQL Server een query met afgeleide tabellen optimaliseert, het transformatieregels toepast op de initiële boom van logische operatoren die door de parser worden geproduceerd, waardoor dingen mogelijk worden verplaatst over wat oorspronkelijk de grenzen van tabelexpressies waren. Dit gebeurt in een mate dat wanneer je een plan voor een query vergelijkt met afgeleide tabellen met een plan voor een query die rechtstreeks ingaat tegen de onderliggende basistabellen waar je de unnesting-logica zelf hebt toegepast, ze er hetzelfde uitzien. Ik heb ook een techniek beschreven om unnesting te voorkomen met behulp van het TOP-filter met een zeer groot aantal rijen als invoer. Ik heb een aantal gevallen gedemonstreerd waarin deze techniek best handig was:een waarbij het doel was om fouten te voorkomen en een andere om optimalisatieredenen.
De TL;DR-versie van substitutie/unnesting van CTE's is dat het proces hetzelfde is als bij afgeleide tabellen. Als u tevreden bent met deze verklaring, kunt u deze sectie overslaan en meteen naar de volgende sectie over Persistentie gaan. Je mist niets belangrijks dat je nog niet eerder hebt gelezen. Als je echter net als ik bent, wil je waarschijnlijk het bewijs dat dat inderdaad het geval is. Daarna wilt u waarschijnlijk doorgaan met het lezen van dit gedeelte en de code testen die ik gebruik, terwijl ik de sleutel-unnesting-voorbeelden die ik eerder heb gedemonstreerd met afgeleide tabellen opnieuw bekijk en deze converteer om CTE's te gebruiken.
In deel 4 heb ik de volgende query gedemonstreerd (we noemen het Query 1):
GEBRUIK TSQLV5; SELECT orderid, orderdate FROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180301' ) AS D3 WHERE besteldatum>='20180401';
De query omvat drie nestingniveaus van afgeleide tabellen, plus een buitenste query. Elk niveau filtert een ander bereik van besteldatums. Het plan voor Query 1 wordt getoond in figuur 1.
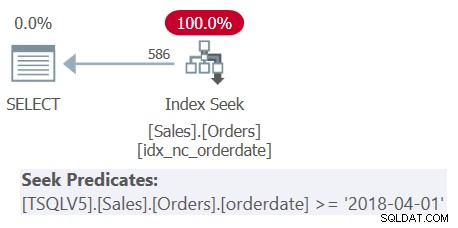 Figuur 1:Uitvoeringsplan voor Query 1
Figuur 1:Uitvoeringsplan voor Query 1
Het plan in figuur 1 laat duidelijk zien dat het uit elkaar halen van de afgeleide tabellen heeft plaatsgevonden, aangezien alle filterpredikaten zijn samengevoegd tot één alomvattend filterpredikaat.
Ik heb uitgelegd dat je het unnesting-proces kunt voorkomen door een betekenisvol TOP-filter te gebruiken (in tegenstelling tot TOP 100 PERCENT) met een zeer groot aantal rijen als invoer, zoals de volgende query laat zien (we noemen het Query 2):
SELECT orderid, orderdate FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>=' 20180201' ) AS D2 WAAR besteldatum>='20180301' ) AS D3 WAAR besteldatum>='20180401';
Het plan voor Query 2 wordt getoond in figuur 2.
 Figuur 2:Uitvoeringsplan voor Query 2
Figuur 2:Uitvoeringsplan voor Query 2
Het plan laat duidelijk zien dat er niet is verwijderd, aangezien u de afgeleide tabelgrenzen effectief kunt zien.
Laten we dezelfde voorbeelden proberen met CTE's. Hier is Query 1 geconverteerd om CTE's te gebruiken:
MET C1 AS ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ), C2 AS ( SELECT * FROM C1 WHERE orderdate>='20180201' ), C3 AS ( SELECT * FROM C2 WHERE orderdate>=' 20180301' ) SELECTEER bestel-ID, besteldatum VANAF C3 WAAR besteldatum>='20180401';
U krijgt exact hetzelfde plan als eerder in figuur 1 getoond, waar u kunt zien dat de nesting plaatsvond.
Hier is Query 2 geconverteerd om CTE's te gebruiken:
MET C1 AS ( SELECTEER TOP (9223372036854775807) * VANUIT Sales.Orders WHERE orderdate>='20180101' ), C2 AS ( SELECT TOP (9223372036854775807) * VANAF C1 WHERE orderdate>='20180201' ), C3 AS ( SELECTEER TOP (9223372036854775807) * VANAF C2 WAAR besteldatum>='20180301' ) SELECTEER bestel-ID, besteldatum VANAF C3 WAAR besteldatum>='20180401';
Je krijgt hetzelfde plan als eerder getoond in figuur 2, waar je kunt zien dat het verwijderen niet heeft plaatsgevonden.
Laten we vervolgens de twee voorbeelden opnieuw bekijken die ik heb gebruikt om de bruikbaarheid van de techniek te demonstreren om unnesting te voorkomen - alleen deze keer met behulp van CTE's.
Laten we beginnen met de foutieve zoekopdracht. De volgende zoekopdracht probeert orderregels te retourneren met een korting die groter is dan de minimumkorting en waarbij het omgekeerde van de korting groter is dan 10:
SELECT orderid, productid, korting FROM Sales.OrderDetails WHERE korting> (SELECT MIN(korting) FROM Sales.OrderDetails) EN 1.0 / korting> 10.0;
De minimale korting kan niet negatief zijn, maar is nul of hoger. U denkt dus waarschijnlijk dat als een rij een korting van nul heeft, het eerste predikaat moet worden geëvalueerd als onwaar, en dat een kortsluiting de poging om het tweede predikaat te evalueren moet voorkomen, waardoor een fout wordt vermeden. Wanneer u deze code echter uitvoert, krijgt u een fout door delen door nul:
Msg 8134, Level 16, State 1, Line 99 Delen door nul opgetreden fout.
Het probleem is dat hoewel SQL Server een kortsluitingsconcept op fysiek verwerkingsniveau ondersteunt, er geen garantie is dat het de filterpredikaten in schriftelijke volgorde van links naar rechts zal evalueren. Een veelvoorkomende poging om dergelijke fouten te vermijden, is door een benoemde tabelexpressie te gebruiken die het deel van de filterlogica afhandelt dat u als eerste wilt evalueren, en om de buitenste query de filterlogica te laten afhandelen die u als tweede wilt laten evalueren. Hier is de geprobeerde oplossing met behulp van een CTE:
MET C AS ( SELECT * FROM Sales.OrderDetails WHERE korting> (SELECT MIN(korting) FROM Sales.OrderDetails) ) SELECT orderid, productid, korting VAN C WHERE 1.0 / korting> 10.0;
Helaas resulteert het ongedaan maken van de tabeluitdrukking in een logisch equivalent van de oorspronkelijke oplossingsquery, en wanneer u deze code probeert uit te voeren, krijgt u opnieuw een fout bij delen door nul:
Msg 8134, Level 16, State 1, Line 108 Delen door nul opgetreden fout.
Door onze truc te gebruiken met het TOP-filter in de innerlijke query, voorkom je het ongedaan maken van de tabeluitdrukking, zoals:
MET C AS ( SELECTEER TOP (9223372036854775807) * UIT Sales.OrderDetails WHERE korting> (SELECT MIN(korting) FROM Sales.OrderDetails) SELECT orderid, productid, korting VAN C WHERE 1.0 / korting> 10.0;
Deze keer wordt de code succesvol uitgevoerd zonder fouten.
Laten we verder gaan met het voorbeeld waarin u de techniek gebruikt om unnesting om optimalisatieredenen te voorkomen. De volgende code retourneert alleen verzenders met een maximale besteldatum die op of na 1 januari 2018 valt:
GEBRUIK PerformanceV5; MET C AS (SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod VAN dbo.Shippers AS S) SELECT shipperid, maxod VAN C WHERE maxod> ='20180101';
Als je je afvraagt waarom je niet een veel eenvoudigere oplossing gebruikt met een gegroepeerde zoekopdracht en een HAVING-filter, heeft dit te maken met de dichtheid van de shipperid-kolom. De tabel Bestellingen bevat 1.000.000 bestellingen en de verzendingen van die bestellingen werden afgehandeld door vijf verzenders, wat betekent dat elke verzender gemiddeld 20% van de bestellingen afhandelde. Het plan voor een gegroepeerde query die de maximale besteldatum per verzender berekent, zou alle 1.000.000 rijen scannen, wat resulteert in duizenden pagina's die worden gelezen. Inderdaad, als u alleen de interne zoekopdracht van de CTE markeert (we noemen het vraag 3) en de maximale besteldatum per verzender berekent en het uitvoeringsplan controleert, krijgt u het plan weergegeven in figuur 3.
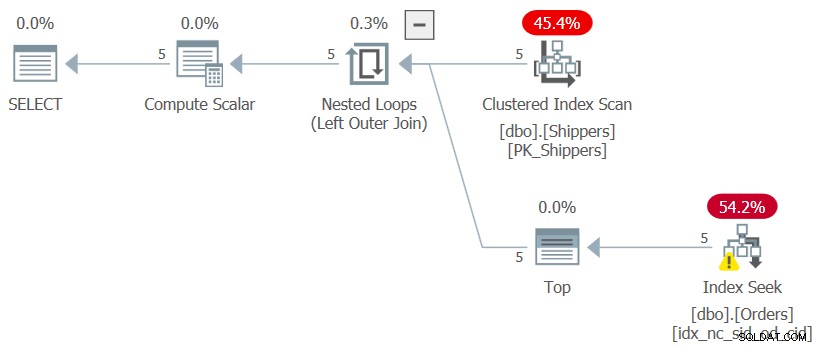 Figuur 3:Uitvoeringsplan voor Query 3
Figuur 3:Uitvoeringsplan voor Query 3
Het plan scant vijf rijen in de geclusterde index op Shippers. Per verzender past het plan een zoek-tegen-een-dekkingsindex toe op Bestellingen, waarbij (verzendperiode, besteldatum) de leidende sleutels van de index zijn, die rechtstreeks naar de laatste rij in elke verladersectie op bladniveau gaan om de maximale besteldatum voor de huidige afzender. Aangezien we slechts vijf verladers hebben, zijn er slechts vijf indexzoekoperaties, wat resulteert in een zeer efficiënt plan. Dit zijn de prestatiemetingen die ik kreeg toen ik de innerlijke query van de CTE uitvoerde:
duur:0 ms, CPU:0 ms, leest:15
Wanneer u echter de volledige oplossing uitvoert (we noemen het Query 4), krijgt u een heel ander plan, zoals weergegeven in afbeelding 4.
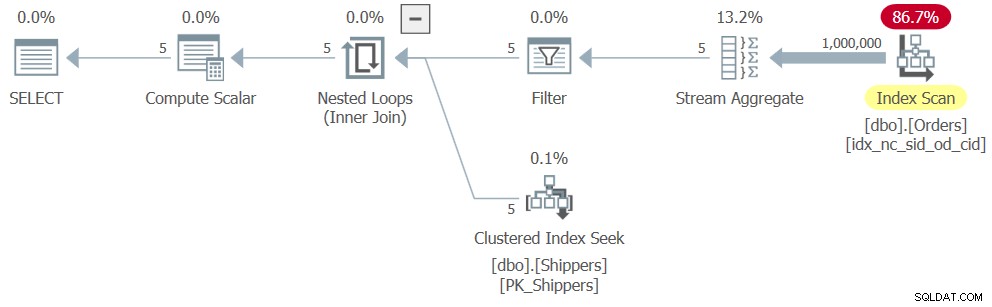 Figuur 4:Uitvoeringsplan voor Query 4
Figuur 4:Uitvoeringsplan voor Query 4
Wat er is gebeurd, is dat SQL Server de tabelexpressie heeft verwijderd, waardoor de oplossing werd omgezet in een logisch equivalent van een gegroepeerde query, wat resulteerde in een volledige scan van de index op Orders. Dit zijn de prestatiecijfers die ik voor deze oplossing heb gekregen:
duur:316 ms, CPU:281 ms, leest:3854
Wat we hier nodig hebben, is om te voorkomen dat de tabelexpressie ongedaan wordt gemaakt, zodat de innerlijke query wordt geoptimaliseerd met zoekacties tegen de index op Orders, en dat de buitenste query alleen maar resulteert in een toevoeging van een filteroperator in de plan. Je bereikt dit met onze truc door een TOP-filter toe te voegen aan de inner query, zoals (we noemen deze oplossing Query 5):
MET C AS ( SELECT TOP (9223372036854775807) S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S) SELECT shipperid , maxod VAN C WAAR maxod>='20180101';
Het plan voor deze oplossing wordt getoond in figuur 5.
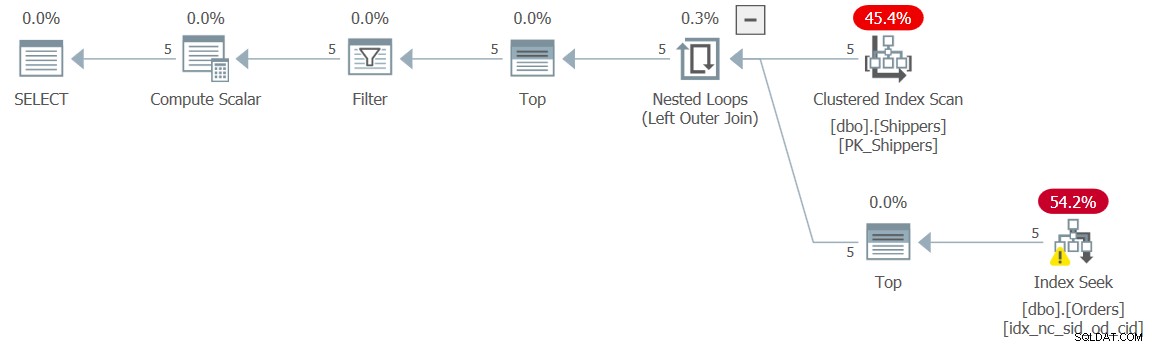 Figuur 5:Uitvoeringsplan voor Query 5
Figuur 5:Uitvoeringsplan voor Query 5
Uit het plan blijkt dat het gewenste effect is bereikt en de prestatiecijfers bevestigen dit dan ook:
duur:0 ms, CPU:0 ms, leest:15
Onze tests bevestigen dus dat SQL Server substitutie/unnesting van CTE's afhandelt, net zoals bij afgeleide tabellen. Dit betekent dat u de ene boven de andere niet moet verkiezen vanwege optimalisatieredenen, maar vanwege conceptuele verschillen die voor u van belang zijn, zoals besproken in deel 5.
Persistentie
Een veel voorkomende misvatting over CTE's en benoemde tabeluitdrukkingen in het algemeen is dat ze dienen als een soort persistentiemiddel. Sommigen denken dat SQL Server de resultatenset van de innerlijke query naar een werktabel voortzet en dat de buitenste query daadwerkelijk interageert met die werktabel. In de praktijk worden reguliere niet-recursieve CTE's en afgeleide tabellen niet volgehouden. Ik beschreef de unnesting-logica die SQL Server toepast bij het optimaliseren van een query met tabelexpressies, resulterend in een plan dat rechtstreeks samenwerkt met de onderliggende basistabellen. Merk op dat de optimizer ervoor kan kiezen om werktabellen te gebruiken om sets met tussenliggende resultaten te behouden als het zinvol is om dit te doen om prestatieredenen of om andere redenen, zoals Halloween-bescherming. Wanneer dit het geval is, ziet u Spool- of Index Spool-operators in het plan. Dergelijke keuzes zijn echter niet gerelateerd aan het gebruik van tabeluitdrukkingen in de query.
Recursieve CTE's
Er zijn een aantal uitzonderingen waarin SQL Server de gegevens van de tabelexpressie behoudt. Een daarvan is het gebruik van geïndexeerde weergaven. Als u een geclusterde index voor een weergave maakt, behoudt SQL Server de resultaatset van de innerlijke query in de geclusterde index van de weergave en houdt deze gesynchroniseerd met eventuele wijzigingen in de onderliggende basistabellen. De andere uitzondering is wanneer u recursieve query's gebruikt. SQL Server moet de tussenliggende resultaatsets van de anker- en recursieve query's in een spool bewaren, zodat het toegang heeft tot de resultatenset van de laatste ronde die wordt vertegenwoordigd door de recursieve verwijzing naar de CTE-naam telkens wanneer het recursieve lid wordt uitgevoerd.
Om dit te demonstreren gebruik ik een van de recursieve queries uit deel 6 in de serie.
Gebruik de volgende code om de tabel Werknemers in de tempdb-database te maken, vul deze met voorbeeldgegevens en maak een ondersteunende index:
STEL NOCOUNT IN; GEBRUIK tempdb; DROP TABEL INDIEN BESTAAT dbo.Medewerkers; GO MAAK TABEL dbo.Werknemers ( empid INT NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, mgrid INT NULL CONSTRAINT FK_Employees_Employees REFERENTIES dbo.Employees, empname VARCHAR(25) NOT NULL, salaris MONEY NOT NULL, CHECKrid) (werknemer MONEY NOT NULL, CHECKrid) INSERT INTO dbo.Werknemers(empid, mgrid, empname, salaris) VALUES(1, NULL, 'David', $10000,00), (2, 1, 'Eitan', $7000,00), (3, 1, 'Ina', $7500,00) , (4, 2, 'Seraph' , $5000.00), (5, 2, 'Jiru' , $5500.00), (6, 2, 'Steve' , $4500.00), (7, 3, 'Aaron' , $5000.00), ( 8, 5, 'Lilach', $ 3500,00), (9, 7, 'Rita', $ 3000,00), (10, 5, 'Sean', $ 3000,00), (11, 7, 'Gabriel', $ 3000,00), (12, 9, 'Emilia', $2000,00), (13, 9, 'Michael', $2000,00), (14, 9, 'Didi', $ 1500,00); MAAK UNIEKE INDEX idx_unc_mgrid_empid OP dbo.Employees(mgrid, empid) INCLUDE(empname, salaris); GO
Ik heb de volgende recursieve CTE gebruikt om alle ondergeschikten van een invoersubboom rootmanager te retourneren, waarbij ik werknemer 3 als invoermanager in dit voorbeeld heb gebruikt:
DECLARE @root AS INT =3; MET C AS ( SELECTEER empid, mgrid, empname VAN dbo.Employees WHERE empid =@root UNION ALLES SELECTEER S.empid, S.mgrid, S.empname UIT C AS M INNER WORDT LID dbo.Employees AS S ON S.mgrid =M .empid ) SELECTEER empid, mgrid, empname FROM C;
Het plan voor deze query (we noemen het Query 6) wordt weergegeven in Afbeelding 6.
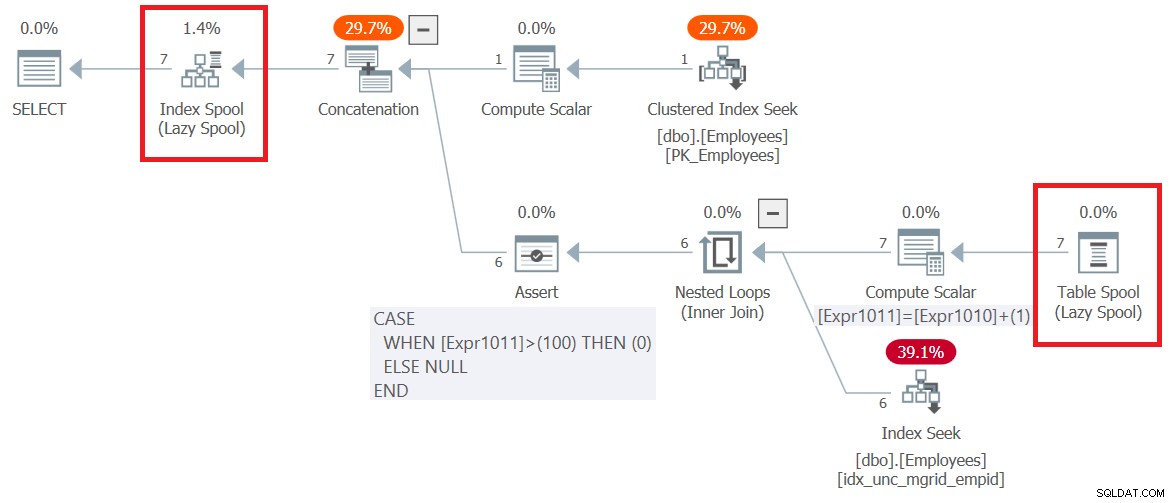 Figuur 6:Uitvoeringsplan voor Query 6
Figuur 6:Uitvoeringsplan voor Query 6
Merk op dat het allereerste dat in het plan gebeurt, rechts van het root-SELECT-knooppunt, het maken van een op B-tree gebaseerde werktabel is, vertegenwoordigd door de Index Spool-operator. Het bovenste deel van het plan behandelt de logica van het ankerlid. Het haalt de ingevoerde rijen van werknemers uit de geclusterde index op Werknemers en schrijft deze naar de spool. Het onderste deel van het plan vertegenwoordigt de logica van het recursieve lid. Het wordt herhaaldelijk uitgevoerd totdat het een lege resultaatset retourneert. De buitenste invoer naar de operator Nested Loops verkrijgt de managers van de vorige ronde van de spool (Table Spool-operator). De innerlijke invoer gebruikt een Index Seek-operator tegen een niet-geclusterde index die is gemaakt op Werknemers (mgrid, empid) om de directe ondergeschikten van de managers uit de vorige ronde te verkrijgen. De resultatenset van elke uitvoering van het onderste deel van het plan wordt ook naar de indexspoel geschreven. Merk op dat er in totaal 7 rijen naar de spoel zijn geschreven. Eén geretourneerd door het ankerlid en nog 6 geretourneerd door alle uitvoeringen van het recursieve lid.
Even terzijde, het is interessant om op te merken hoe het plan omgaat met de standaard maxrecursielimiet, die 100 is. Merk op dat de onderste Compute Scalar-operator een interne teller genaamd Expr1011 met 1 blijft verhogen bij elke uitvoering van het recursieve lid. Vervolgens stelt de Assert-operator een vlag in op nul als deze teller de 100 overschrijdt. Als dit gebeurt, stopt SQL Server de uitvoering van de query en genereert een fout.
Wanneer niet volhouden
Terug naar niet-recursieve CTE's, die normaal gesproken niet worden volgehouden, het is aan jou om vanuit een optimalisatieperspectief uit te zoeken wanneer het een goede zaak is om ze te gebruiken in plaats van daadwerkelijke persistentietools zoals tijdelijke tabellen en tabelvariabelen. Ik zal een paar voorbeelden doornemen om te laten zien wanneer elke benadering meer optimaal is.
Laten we beginnen met een voorbeeld waarin CTE's het beter doen dan tijdelijke tabellen. Dat is vaak het geval wanneer u niet meerdere evaluaties van dezelfde CTE heeft, maar misschien gewoon een modulaire oplossing waarbij elke CTE slechts één keer wordt geëvalueerd. De volgende code (we noemen het Query 7) doorzoekt de tabel Orders in de Performance-database, die 1.000.000 rijen heeft, om orderjaren terug te geven waarin meer dan 70 verschillende klanten bestellingen hebben geplaatst:
GEBRUIK PerformanceV5; MET C1 AS ( SELECTEER JAAR (besteldatum) ALS besteljaar, custid VAN dbo.Orders ), C2 AS ( SELECT besteljaar, COUNT (DISTINCT custid) ALS aantal UIT C1 GROEP BY besteljaar ) SELECTEER besteljaar, aantal UIT C2 WHERE aantal> 70; /pre>Deze query genereert de volgende uitvoer:
besteljaar aantal ----------- ----------- 2015 992 2017 20000 2018 20000 2019 20000 2016 20000Ik heb deze code uitgevoerd met SQL Server 2019 Developer Edition en kreeg het plan weergegeven in afbeelding 7.
Figuur 7:Uitvoeringsplan voor Query 7
Merk op dat het uit elkaar halen van de CTE resulteerde in een plan dat de gegevens uit een index op de Orders-tabel haalt, en dat er geen spooling van de interne queryresultatenset van de CTE nodig is. Ik kreeg de volgende prestatiecijfers bij het uitvoeren van deze query op mijn computer:
duur:265 ms, CPU:828 ms, leest:3970, schrijft:0Laten we nu een oplossing proberen die tijdelijke tabellen gebruikt in plaats van CTE's (we noemen het Oplossing 8), zoals:
SELECTEER JAAR(besteldatum) ALS besteljaar, custid INTO #T1 VANUIT dbo.Orders; SELECTEER orderjaar, COUNT(DISTINCT custid) AS numcusts INTO #T2 VAN #T1 GROUP BY orderyear; SELECT besteljaar, aantal UIT #T2 WAAR aantal> 70; DROP TABEL #T1, #T2;De plannen voor deze oplossing zijn weergegeven in figuur 8.
Figuur 8:Plannen voor oplossing 8
Let op de Table Insert-operators die de resultaatsets naar de tijdelijke tabellen #T1 en #T2 schrijven. De eerste is vooral duur omdat hij 1.000.000 rijen naar #T1 schrijft. Dit zijn de prestatienummers die ik voor deze uitvoering heb gekregen:
duur:454 ms, CPU:1517 ms, leest:14359, schrijft:359Zoals je kunt zien, is de oplossing met de CTE's veel optimaler.
Wanneer volharden
Is het dus zo dat een modulaire oplossing waarbij slechts één evaluatie van elke CTE nodig is, altijd de voorkeur verdient boven het gebruik van tijdelijke tabellen? Niet noodzakelijk. In op CTE gebaseerde oplossingen die veel stappen omvatten en resulteren in uitgebreide plannen waarbij de optimizer veel kardinaliteitsschattingen moet toepassen op veel verschillende punten in het plan, zou je kunnen eindigen met opgehoopte onnauwkeurigheden die resulteren in suboptimale keuzes. Een van de technieken om dergelijke gevallen aan te pakken, is door enkele sets met tussentijdse resultaten zelf in tijdelijke tabellen te bewaren en er indien nodig zelfs indexen op te maken, waardoor de optimizer een nieuwe start krijgt met nieuwe statistieken, waardoor de kans op kardinaliteitsschattingen van betere kwaliteit wordt vergroot. hopelijk leiden tot meer optimale keuzes. Of dit beter is dan een oplossing die geen tijdelijke tabellen gebruikt, is iets dat je moet testen. Soms is het de moeite waard om extra kosten in te ruilen voor het aanhouden van sets met tussentijdse resultaten om kardinaliteitsschattingen van betere kwaliteit te krijgen.
Een ander typisch geval waarbij het gebruik van tijdelijke tabellen de voorkeur heeft, is wanneer de op CTE gebaseerde oplossing meerdere evaluaties van dezelfde CTE heeft en de interne query van de CTE vrij duur is. Overweeg de volgende op CTE gebaseerde oplossing (we noemen het Query 9), die overeenkomt met elk besteljaar en -maand een ander besteljaar en -maand met het dichtste aantal bestellingen:
MET OrderCount AS ( SELECTEER JAAR(orderdatum) AS orderjaar, MAAND(orderdatum) AS ordermaand, COUNT(*) AS aantallen VAN dbo.Orders GROEP PER JAAR(orderdatum), MAAND(orderdatum) ) SELECTEER O1.orderjaar, O1 .ordermaand, O1.aantalbestellingen, O2.besteljaar AS besteljaar2, O2.bestellingsmaand AS bestelmaand2, O2.aantalbestellingen AS aantal2 UIT OrdCount AS O1 CROSS APPLY ( SELECTEER TOP (1) O2.besteljaar, O2.bestelmaand, O2.aantal bestellingen VANUIT OrdCount AS O2 WHERE O2.besteljaar <> O1.besteljaar OF O2.bestelmaand <> O1.bestelmaand BESTELLEN DOOR ABS(O1.aantal bestellingen - O2.aantal bestellingen), O2.besteljaar, O2.bestelmaand ) AS O2;Deze query genereert de volgende uitvoer:
orderjaar ordermaand nummers orderjaar2 ordermaand2 nummers2 ----------- ----------- ----------- -------- --- ----------- ----------- 2016 1 21262 2017 3 21267 2019 1 21227 2016 5 21229 2019 2 19145 2018 2 19125 2018 4 20561 2016 9 20554 2018 5 21209 2019 5 21210 2018 6 20515 2016 11 20513 2018 7 21194 2018 10 21197 2017 9 20542 2017 11 20539 2017 10 21234 2019 3 21235 2017 11 20539 2019 4 20537 2017 12 21183 2016 8 21185 2018 1 21241 2019 7 21238 2016 2 19844 2019 12 20184 2018 3 21222 2016 10 21222 2016 4 20526 2019 9 20527 2019 4 20537 2017 11 20539 2017 5 21203 2017 8 21199 2019 6 20531 2019 9 20527 2017 7 21217 2016 7 21218 2018 8 21283 2017 3 21267 2018 10 21197 2017 8 21199 2016 11 20513 2018 6 20515 2019 11 20494 2017 4 20498 2018 2 19125 2019 2 19145 2016 3 21211 2016 12 21212 2019 3 21235 2017 10 21234 2016 5 21229 2019 1 21227 2019 5 21210 201 6 3 21211 2017 6 20551 2016 9 20554 2017 8 21199 2018 10 21197 2018 9 20487 2019 11 20494 2016 10 21222 2018 3 21222 2018 11 20575 2016 6 20571 2016 12 21212 2016 3 21211 2019 12 20184 2018 9 20487 2017 1 21223 2016 10 21222 2017 2 19174 2019 2 19145 2017 3 21267 2016 1 21262 2017 4 20498 2019 11 20494 2016 6 20571 2018 11 20575 2016 7 21218 2017 7 21217 2019 7 21238 2018 1 21241 2016 8 21185 2017 12 21183 2019 8 21189 2016 8 21185 2016 9 20554 2017 6 20551 2019 9 20527 2016 4 20526 2019 10 21254 2016 1 21262 2015 12 1018 2018 2 19125 2018 12 21225 2017 1 21223 (49 rijen aangetast)Het plan voor Query 9 wordt getoond in figuur 9.
Figuur 9:Uitvoeringsplan voor Query 9
Het bovenste deel van het plan komt overeen met de instantie van de OrdCount CTE die een alias heeft als O1. Deze referentie resulteert in één evaluatie van de CTE OrdCount. Dit deel van het plan haalt de rijen uit een index in de tabel Orders, groepeert ze op jaar en maand en verzamelt het aantal orders per groep, wat resulteert in 49 rijen. Het onderste deel van het plan komt overeen met de gecorreleerde afgeleide tabel O2, die per rij uit O1 wordt toegepast, en wordt dus 49 keer uitgevoerd. Elke uitvoering bevraagt de OrdCount CTE en resulteert daarom in een afzonderlijke evaluatie van de innerlijke query van de CTE. U kunt zien dat het onderste deel van het plan alle rijen uit de index op Orders, groepen scant en deze samenvoegt. U krijgt in feite in totaal 50 evaluaties van de CTE, wat resulteert in 50 keer het scannen van de 1.000.000 rijen van Orders, het groeperen en aggregeren ervan. Het klinkt niet als een erg efficiënte oplossing. Dit zijn de prestatiemetingen die ik kreeg bij het uitvoeren van deze oplossing op mijn computer:
duur:16 seconden, CPU:56 seconden, leest:130404, schrijft:0Aangezien er slechts enkele tientallen maanden mee gemoeid zijn, zou het veel efficiënter zijn om een tijdelijke tabel te gebruiken om het resultaat van een enkele activiteit op te slaan die de rijen van Orders groepeert en aggregeert, en dan zowel de uiterlijke als de innerlijke invoer van de APPLY-operator werkt samen met de tijdelijke tabel. Hier is de oplossing (we noemen het Oplossing 10) met een tijdelijke tabel in plaats van de CTE:
SELECTEER JAAR (besteldatum) AS besteljaar, MAAND (besteldatum) AS bestelmaand, COUNT(*) AS aantallen INTO #OrdCount VAN dbo.Orders GROEP OP JAAR (besteldatum), MAAND (besteldatum); SELECTEER O1.besteljaar, O1.bestellingsmaand, O1.aantalbestellingen, O2.besteljaar AS besteljaar2, O2.bestelmaand AS bestelmaand2, O2.aantalbestellingen AS aantal2 VAN #OrdCount AS O1 CROSS APPLY ( SELECTEER TOP (1) O2.besteljaar, O2.bestelmaand , O2.aantalorders VAN #OrdCount AS O2 WHERE O2.orderjaar <> O1.orderjaar OF O2.ordermaand <> O1.ordermaand BESTELLEN DOOR ABS(O1.aantalorders - O2.aantalorders), O2.orderjaar, O2.ordermaand ) AS O2; DROP TABEL #OrdCount;Hier heeft het niet veel zin om de tijdelijke tabel te indexeren, aangezien het TOP-filter is gebaseerd op een berekening in de bestelspecificatie en daarom is sorteren onvermijdelijk. Het kan echter heel goed zijn dat het in andere gevallen, met andere oplossingen, ook relevant voor u is om te overwegen uw tijdelijke tabellen te indexeren. In ieder geval is het plan voor deze oplossing weergegeven in figuur 10.
Figuur 10:uitvoeringsplannen voor oplossing 10
Bekijk in het topplan hoe het zware werk, waarbij 1.000.000 rijen worden gescand, gegroepeerd en samengevoegd, slechts één keer gebeurt. 49 rijen worden naar de tijdelijke tabel #OrdCount geschreven en vervolgens werkt het onderste plan samen met de tijdelijke tabel voor zowel de buitenste als de binnenste invoer van de operator Nested Loops, die de logica van de operator APPLY afhandelt.
Dit zijn de prestatiecijfers die ik heb gekregen voor de uitvoering van deze oplossing:
duur:0,392 seconden, CPU:0,5 seconden, leest:3636, schrijft:3Het is in ordes van grootte sneller dan de op CTE gebaseerde oplossing.
Wat nu?
In dit artikel ben ik begonnen met het bespreken van optimalisatieoverwegingen met betrekking tot CTE's. Ik heb laten zien dat het proces van ontnesting/substitutie dat plaatsvindt met afgeleide tabellen op dezelfde manier werkt met CTE's. Ik besprak ook het feit dat niet-recursieve CTE's niet worden volgehouden en legde uit dat wanneer persistentie een belangrijke factor is voor de prestaties van uw oplossing, u dit zelf moet doen door tools zoals tijdelijke tabellen en tabelvariabelen te gebruiken. Volgende maand zal ik de discussie voortzetten door aanvullende aspecten van CTE-optimalisatie te bespreken.