Dit is het laatste deel van een vijfdelige serie die een diepe duik neemt in de manier waarop parallelle plannen in de rijmodus van SQL Server worden uitgevoerd. In deel 1 werd uitvoeringscontext nul geïnitialiseerd voor de bovenliggende taak en in deel 2 werd de query-scanstructuur gemaakt. Deel 3 startte de query-scan, voerde een vroege fase uit verwerking, en startte de eerste aanvullende parallelle taken in tak C. Deel 4 beschreef uitwisselingssynchronisatie, en het opstarten van parallelle plantakken C &D.
Branch B Parallelle taken starten
Een herinnering aan de takken in dit parallelle plan (klik om te vergroten):
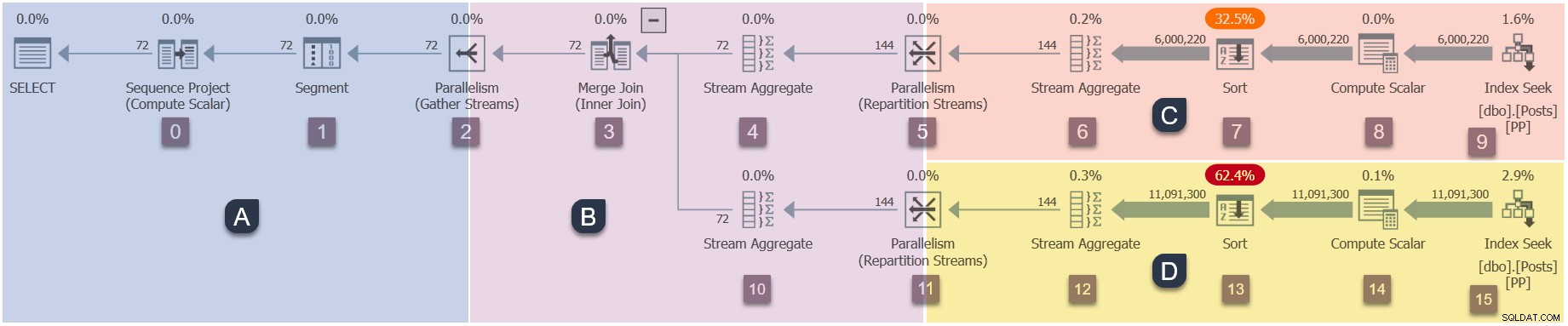
Dit is de vierde fase in de uitvoeringsvolgorde:
- Tak A (bovenliggende taak).
- Branch C (extra parallelle taken).
- Branch D (extra parallelle taken).
- Branch B (extra parallelle taken).
De enige thread die momenteel actief is (niet opgeschort op CXPACKET ) is de bovenliggende taak , die zich aan de consumentenkant van de uitwisseling van herverdelingsstromen bevindt op knooppunt 11 in filiaal B:
De bovenliggende taak keert nu terug uit geneste vroege fasen oproepen, verstreken tijd en CPU-tijden in profilers instellen zoals het gaat. Eerste en laatste actieve tijden zijn niet bijgewerkt tijdens de verwerking in de vroege fase. Onthoud dat deze nummers worden geregistreerd tegen uitvoeringscontext nul - de parallelle taken van Branch B bestaan nog niet.
De oudertaak stijgt de boom van knooppunt 11, via het stroomaggregaat op knooppunt 10 en de samenvoegverbinding op knooppunt 3, terug naar de verzamelstromenuitwisseling op knooppunt 2.
De verwerking in de vroege fase is nu voltooid .
Met de originele EarlyPhases bel bij het knooppunt 2 verzamel streams ruil eindelijk voltooid, keert de bovenliggende taak terug naar het openen van die centrale (je herinnert je die oproep misschien nog wel aan het begin van deze serie). De open methode op knooppunt 2 roept nu CQScanExchangeNew::StartAllProducers aan om de parallelle taken te maken voor filiaal B.
De oudertaak nu wacht op CXPACKET bij de consument kant van het knooppunt 2 stromen verzamelen aandelenbeurs. Dit wachten gaat door totdat de nieuw gemaakte Branch B-taken hun geneste Open . hebben voltooid belt en keerde terug om de producentenkant van de collect streams-uitwisseling te voltooien.
Parallelle taken van tak B open
De twee nieuwe parallelle taken in Branch B beginnen bij de producent kant van het knooppunt 2 stromen verzamelen aandelenbeurs. Volgens het gebruikelijke iteratieve uitvoeringsmodel in rijmodus noemen ze:
CQScanXProducerNew::Open(knooppunt 2 producentzijde open).CQScanProfileNew::Open(profiler voor knooppunt 3).CQScanMergeJoinNew::Open(knooppunt 3 merge join).CQScanProfileNew::Open(profiler voor knooppunt 4).CQScanStreamAggregateNew::Open(knooppunt 4 stroomaggregaat).CQScanProfileNew::Open(profiler voor knooppunt 5).CQScanExchangeNew::Open(repartitie streams uitwisseling).
De parallelle taken volgen beide de buitenste (bovenste) invoer naar de merge join, net als de verwerking in de vroege fase.
De uitwisseling voltooien
Wanneer de Tak B-taken bij de consument aankomen kant van de herverdelingsstromen wisselen op knooppunt 5, elke taak:
- Registreert met de uitwisselingspoort (
CXPort). - Maakt de pijpen (
CXPipe) die deze taak koppelen aan een of meer producentenkanttaken (afhankelijk van het type uitwisseling). De huidige uitwisseling is een herverdeling van stromen, dus elke consumententaak heeft twee leidingen (bij DOP 2). Elke consument kan rijen ontvangen van een van de twee producenten. - Voegt een
CXPipeMergetoe samenvoegen rijen van meerdere leidingen (aangezien dit een uitwisseling is die de bestelling bewaart). - Maakt rijpakketten (verwarrend genaamd
CXPacket) gebruikt voor stroomregeling en om rijen over de wisselleidingen te bufferen. Deze worden toegewezen vanuit het eerder toegekende zoekgeheugen.
Zodra beide parallelle taken aan de consumentenzijde dat werk hebben voltooid, is de uitwisseling van knooppunt 5 klaar voor gebruik. De twee consumenten (in filiaal B) en de twee producenten (in filiaal C) hebben allemaal de uitwisselingspoort geopend, dus het knooppunt 5 CXPACKET wacht op einde .
Checkpoint
Zoals de zaken er nu voor staan:
- De bovenliggende taak in Tak A is wacht op
CXPACKETaan de consumentenzijde van het knooppunt 2 uitwisseling van verzamelstromen. Dit wachten gaat door totdat beide knooppunt 2-producenten terugkeren en de uitwisseling openen. - De twee parallelle taken in Branch B zijn uitvoerbaar . Ze hebben zojuist de consumentenkant van de uitwisseling van herverdelingsstromen op knooppunt 5 geopend.
- De twee parallelle taken in Branch C zijn zojuist vrijgelaten uit hun
CXPACKETwacht, en zijn nu uitvoerbaar . De twee stroomaggregaten op knooppunt 6 (één per parallelle taak) kunnen beginnen met het aggregeren van rijen van de twee soorten op knooppunt 7. Bedenk dat de index zoekt op knooppunt 9 enige tijd geleden is gesloten, toen de soorten hun invoerfase voltooiden. - De twee parallelle taken in Branch D zijn wachten op
CXPACKETaan de producentenkant van de herverdelingsstroomuitwisseling op knooppunt 11. Ze wachten tot de consumentenkant van knooppunt 11 wordt geopend door de twee parallelle taken in tak B. De indexzoekopdrachten zijn gesloten en de soorten zijn klaar om over te gaan naar hun uitvoerfase.
Meerdere actieve branches
Dit is de eerste keer dat we meerdere vestigingen (B en C) tegelijkertijd actief hebben, wat een uitdaging kan zijn om te bespreken. Gelukkig is het ontwerp van de demo-query zodanig dat de stroomaggregaten in Branch C slechts een paar rijen zullen produceren. Het kleine aantal smalle uitvoerrijen past gemakkelijk in het rijpakket buffers op het knooppunt 5 uitwisseling van herverdelingsstromen. De taken van Branch C kunnen daarom doorgaan met hun werk (en uiteindelijk sluiten) zonder te wachten tot de consumentenkant van de node 5 repartition streams om rijen op te halen.
Handig is dat dit betekent dat we de twee parallelle taken van Branch C op de achtergrond kunnen laten draaien zonder dat we ons er zorgen over hoeven te maken. We hoeven ons alleen maar bezig te houden met wat de twee parallelle taken van Branch B doen.
Tak B-opening voltooid
Een herinnering aan Branch B:
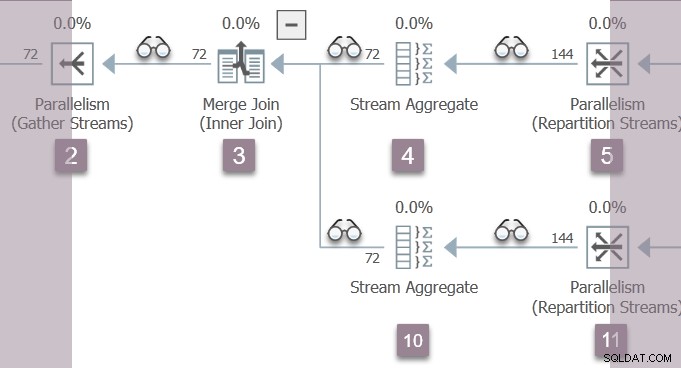
De twee parallelle werkers in Branch B komen terug van hun Open oproepen op het knooppunt 5 repartitie streams uitwisselen. Dit brengt ze terug door het stroomaggregaat op knooppunt 4, naar de samenvoegverbinding op knooppunt 3.
Omdat we stijgen de boom in de Open methode, de profilers boven knooppunt 5 en knooppunt 4 registreren laatst actief tijd, evenals het optellen van verstreken en CPU-tijden (per taak). We voeren nu geen vroege fasen van de bovenliggende taak uit, dus de nummers die zijn vastgelegd voor uitvoeringscontext nul worden niet beïnvloed.
Bij de merge join beginnen de twee Branch B parallelle taken aflopend de binnenste (lagere) invoer, die ze door het stroomaggregaat op knooppunt 10 (en een paar profilers) naar de consumentenkant van de herverdelingsstroomuitwisseling op knooppunt 11 leidt.
Branch D hervat uitvoering
Een herhaling van de Branch C-gebeurtenissen bij knooppunt 5 vindt nu plaats bij de herpartitiestromen van knooppunt 11. De consumentenzijde van de uitwisseling van knooppunt 11 is voltooid en geopend. De twee producenten in Branch D beëindigen hun CXPACKET wacht, wordt uitvoerbaar nog een keer. We laten de Tak D-taken op de achtergrond draaien en plaatsen hun resultaten in uitwisselingsbuffers.
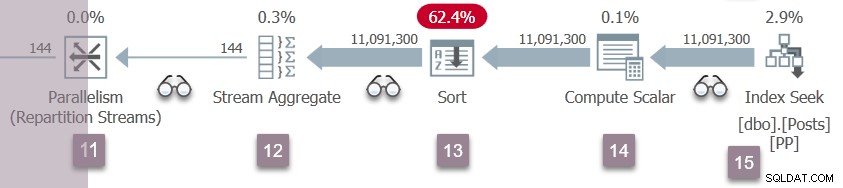
Er zijn nu zes parallelle taken (elk twee in filialen B, C en D) samen tijd delen op de twee planners die zijn toegewezen aan aanvullende parallelle taken in deze query.
Tak A-opening is voltooid
De twee parallelle taken in Branch B komen terug van hun Open oproepen bij het knooppunt 11 herpartitioneer streams uitwisseling, voorbij het knooppunt 10 stroomaggregaat, via de samenvoegverbinding bij knooppunt 3, en terug naar de producentkant van de verzamel streams op knooppunt 2. Profiler laatst actief en geaccumuleerde verstreken &CPU-tijden worden bijgewerkt als we de boom opklimmen in geneste Open methoden.
Bij de producent kant van de uitwisseling van verzamelstromen, synchroniseren de twee parallelle taken van Branch B het openen van de uitwisselingspoort, en wacht dan op CXPACKET voor de consumentenkant om te openen.
De oudertaak wachten aan de consumentenkant van de verzamelstreams is nu uitgebracht van zijn CXPACKET wacht, waardoor het de uitwisselingspoort aan de kant van de consument kan voltooien. Dit verlost op zijn beurt de producenten van hun (korte) CXPACKET wacht. De node 2 verzamelstreams zijn nu geopend door alle eigenaren.
De queryscan voltooien
De oudertaak stijgt nu de query-scanboom op vanuit de verzamelstreams-uitwisseling en keert terug van de Open oproepen bij de centrale, segment , en volgproject operators in filiaal A.
Dit voltooit de opening de query-scanboom, die een tijdje geleden is gestart door de aanroep van CQueryScan::StartupQuery . Alle takken van het parallelle plan zijn nu gestart met de uitvoering.
Returning rijen
Het uitvoeringsplan is klaar om rijen te retourneren als reactie op GetRow roept op bij de root van de query-scanstructuur, gestart door een aanroep van CQueryScan::GetRow . Ik ga niet in detail treden, aangezien het strikt buiten het bestek valt van een artikel over hoe parallelle plannen opstarten .
Toch is de korte reeks:
- De bovenliggende taak roept
GetRow. aan op het sequentieproject, datGetRow. aanroept op het segment, datGetRow. aanroept op de consument kant van de uitwisseling van verzamelstromen. - Als er nog geen rijen beschikbaar zijn op de uitwisseling, wacht de bovenliggende taak wacht op
CXCONSUMER. - Ondertussen hebben de onafhankelijk draaiende parallelle taken van Branch B recursief
GetRowaangeroepen beginnend bij de producent kant van de uitwisseling van verzamelstromen. - Rijen worden aan filiaal B geleverd door de consumentenzijden van de uitwisselingen van repartitiestromen op knooppunten 5 en 12.
- Takken C en D verwerken nog steeds rijen van hun soort via hun respectievelijke stroomaggregaten. Taak B-taken moeten mogelijk wachten op
CXCONSUMERbij herverdeling streams knooppunten 5 en 12 zodat een compleet pakket rijen beschikbaar komt. - Rijen die tevoorschijn komen uit de geneste
GetRowoproepen in Branch B worden samengevoegd tot rijpakketten bij de producent kant van de uitwisseling van verzamelstromen. - De
CXCONSUMER. van de bovenliggende taak wacht aan de consumentenkant van de verzamelstreams eindigt wanneer een pakket beschikbaar komt. - Vervolgens wordt rij voor rij verwerkt via de bovenliggende operators in filiaal A, en uiteindelijk naar de client.
- Uiteindelijk raken de rijen op, en een geneste
Closeoproep rimpelt door de boom, over de uitwisselingen, en parallelle uitvoering komt tot een einde.
Samenvatting en slotopmerkingen
Eerst een samenvatting van de uitvoeringsvolgorde van dit specifieke parallelle uitvoeringsplan:
- De oudertaak opent tak A . Vroege fase verwerking begint bij de uitwisseling van verzamelstromen.
- Aanroepen in de vroege fase van de bovenliggende taak dalen de scanboom af naar de index, zoeken bij knooppunt 9, en stijgen dan terug naar de herpartitioneringsuitwisseling bij knooppunt 5.
- De bovenliggende taak start parallelle taken voor Branch C , wacht dan terwijl ze alle beschikbare rijen inlezen in de blokkerende sorteeroperatoren op knooppunt 7.
- Vroege fase-oproepen stijgen op naar de merge join en dalen dan de binnenste input af naar de centrale op knooppunt 11.
- Taken voor Bak D worden net als voor Branch C gestart, terwijl de bovenliggende taak op knooppunt 11 wacht.
- Aanroepen uit de vroege fase keren terug van knooppunt 11 tot aan de verzamelstromen. De vroege fase eindigt hier.
- De bovenliggende taak creëert parallelle taken voor Branch B , en wacht tot de opening van tak B is voltooid.
- Taak B-taken bereiken de herpartitiestreams van knooppunt 5, synchroniseren, voltooien de uitwisseling en geven Taak C-taken vrij om rijen van de sorteringen samen te voegen.
- Wanneer Tak B-taken de herpartitiestreams van knooppunt 12 bereiken, synchroniseren ze, voltooien ze de uitwisseling en geven ze Tak D-taken vrij om te beginnen met het aggregeren van rijen vanaf de sortering.
- Taak B-taken keren terug naar de uitwisseling van verzamelstromen en synchroniseren, waardoor de bovenliggende taak wordt bevrijd van het wachten. De bovenliggende taak is nu klaar om het proces van het retourneren van rijen naar de client te starten.
Misschien wilt u de uitvoering van dit plan bekijken in Sentry One Plan Explorer. Zorg ervoor dat u de optie "Met Live Query Profile" van de verzameling van het werkelijke abonnement inschakelt. Het leuke van het rechtstreeks uitvoeren van de query in Plan Explorer is dat je in je eigen tempo door meerdere opnames kunt gaan en zelfs terug kunt spoelen. Het toont ook een grafisch overzicht van I/O, CPU en wachttijden, gesynchroniseerd met de live-queryprofileringsgegevens.
Aanvullende opmerkingen
Het opklimmen van de query-scanstructuur tijdens verwerking in de vroege fase stelt de eerste en laatste actieve tijden in bij elke profileringiterator voor de bovenliggende taak, maar verzamelt geen verstreken of CPU-tijd. Oplopend in de boom tijdens Open en GetRow roept een parallelle taak aan, stelt de laatste actieve tijd in en verzamelt de verstreken tijd en CPU-tijd bij elke profileringiterator per taak.
De verwerking in de vroege fase is specifiek voor parallelle plannen in rijmodus. Het is noodzakelijk om ervoor te zorgen dat uitwisselingen in de juiste volgorde worden geïnitialiseerd en dat alle parallelle machines correct werken.
De bovenliggende taak voert niet altijd de volledige verwerking in de vroege fase uit. Vroege fasen beginnen bij een root-uitwisseling, maar hoe die oproepen door de boom navigeren, hangt af van de tegengekomen iterators. Ik heb voor deze demo een merge-join gekozen omdat het toevallig een vroege fase-verwerking vereist voor beide invoer.
Vroege fasen bij (bijvoorbeeld) een parallelle hash-join verspreiden zich alleen langs de build-invoer. Wanneer de hash-join overgaat naar de testfase, opent iterators op die input, inclusief eventuele uitwisselingen. Een nieuwe ronde van verwerking in de vroege fase wordt gestart, afgehandeld door (precies) een van de parallelle taken, die de rol van de bovenliggende taak spelen.
Wanneer verwerking in de vroege fase een parallelle vertakking tegenkomt die een blokkerende iterator bevat, start het de extra parallelle taken voor die vertakking en wacht tot die producenten hun openingsfase voltooien. Die vertakking kan ook onderliggende vertakkingen hebben, die op dezelfde manier recursief worden behandeld.
Sommige vertakkingen in een parallel plan in rijmodus moeten mogelijk op een enkele thread worden uitgevoerd (bijvoorbeeld vanwege een globaal aggregaat of top). Deze 'seriële zones' draaien ook op een extra 'parallelle' taak, het enige verschil is dat er maar één taak, uitvoeringscontext en werker voor die tak is. De verwerking in de vroege fase werkt hetzelfde, ongeacht het aantal taken dat aan een filiaal is toegewezen. Een 'seriële zone' rapporteert bijvoorbeeld timings voor de bovenliggende taak (of een parallelle taak die die rol speelt) evenals de enkele extra taak. Dit manifesteert zich in showplan als gegevens voor "thread 0" (vroege fasen) en "thread 1" (de aanvullende taak).
Afsluitende gedachten
Dit alles vertegenwoordigt zeker een extra laag complexiteit. Het rendement van die investering is het gebruik van runtime-resources (voornamelijk threads en geheugen), verminderde synchronisatiewachten, verhoogde doorvoer, mogelijk nauwkeurige prestatiestatistieken en een minimale kans op parallelle impasses binnen de query.
Hoewel het parallellisme in de rijmodus grotendeels is overschaduwd door de modernere batch-modus parallelle uitvoeringsengine, heeft het ontwerp van de rijmodus nog steeds een zekere schoonheid. De meeste iterators kunnen doen alsof ze nog steeds in een serieel plan werken, waarbij bijna alle synchronisatie, stroomregeling en planning door de uitwisselingen wordt afgehandeld. Dankzij de zorg en aandacht die duidelijk is in implementatiedetails, zoals verwerking in de vroege fase, kunnen zelfs de grootste parallelle plannen met succes worden uitgevoerd zonder dat de queryontwerper te veel nadenkt over de praktische problemen.