Het zoeken naar tekenreeksgegevens voor een willekeurige subtekenreeksovereenkomst kan een dure bewerking zijn in SQL Server. Query's van het formulier Column LIKE '%match%' kan de zoekmogelijkheden van een b-tree-index niet gebruiken, dus de queryprocessor moet het predikaat op elke rij afzonderlijk toepassen. Bovendien moet elke test de volledige set gecompliceerde sorteerregels correct toepassen. Door al deze factoren te combineren, is het geen verrassing dat dit soort zoekopdrachten veel middelen en traag kunnen zijn.
Full-Text Search is een krachtig hulpmiddel voor taalkundige matching, en de nieuwere Statistical Semantic Search is geweldig voor het vinden van documenten met vergelijkbare betekenissen. Maar soms moet je echt gewoon strings vinden die een bepaalde substring bevatten - een substring die misschien niet eens een woord is, in welke taal dan ook.
Als de gezochte gegevens niet groot zijn of als de responstijdvereisten niet essentieel zijn, gebruikt u LIKE '%match%' zou wel eens een passende oplossing kunnen zijn. Maar in het geval dat de behoefte aan supersnel zoeken alle andere overwegingen overtreft (inclusief opslagruimte), kunt u een aangepaste oplossing overwegen met n-grammen. De specifieke variatie die in dit artikel wordt onderzocht, is een trigram van drie tekens.
Wildcard zoeken met trigrammen
Het basisidee van een trigram-zoekopdracht is vrij eenvoudig:
- Behoud substrings van drie tekens (trigrammen) van de doelgegevens.
- Verdeel de zoekterm(en) in trigrammen.
- Vergelijk zoektrigrammen met de opgeslagen trigrammen (gelijkheid zoeken)
- Snijd de gekwalificeerde rijen om strings te vinden die overeenkomen met alle trigrammen
- Pas het originele zoekfilter toe op het veel kleinere kruispunt
We zullen een voorbeeld doornemen om precies te zien hoe dit allemaal werkt en wat de compromissen zijn.
Voorbeeldtabel en gegevens
Het onderstaande script maakt een voorbeeldtabel en vult deze met een miljoen rijen tekenreeksgegevens. Elke tekenreeks is 20 tekens lang, waarbij de eerste 10 tekens numeriek zijn. De overige 10 tekens zijn een combinatie van cijfers en letters van A tot F, gegenereerd met NEWID() . Er is niets bijzonders aan deze voorbeeldgegevens; de trigramtechniek is vrij algemeen.
-- The test table
CREATE TABLE dbo.Example
(
id integer IDENTITY NOT NULL,
string char(20) NOT NULL,
CONSTRAINT [PK dbo.Example (id)]
PRIMARY KEY CLUSTERED (id)
);
GO
-- 1 million rows
INSERT dbo.Example WITH (TABLOCKX)
(string)
SELECT TOP (1 * 1000 * 1000)
-- 10 numeric characters
REPLACE(STR(RAND(CHECKSUM(NEWID())) * 1e10, 10), SPACE(1), '0') +
-- plus 10 mixed numeric + [A-F] characters
RIGHT(NEWID(), 10)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
OPTION (MAXDOP 1); Het duurt ongeveer 3 seconden om de gegevens op mijn bescheiden laptop te maken en te vullen. De gegevens zijn pseudo-willekeurig, maar als indicatie ziet het er ongeveer zo uit:
Gegevensvoorbeeld
Trigrammen genereren
De volgende inline-functie genereert verschillende alfanumerieke trigrammen van een gegeven invoerreeks:
--- Generate trigrams from a string
CREATE FUNCTION dbo.GenerateTrigrams (@string varchar(255))
RETURNS table
WITH SCHEMABINDING
AS RETURN
WITH
N16 AS
(
SELECT V.v
FROM
(
VALUES
(0),(0),(0),(0),(0),(0),(0),(0),
(0),(0),(0),(0),(0),(0),(0),(0)
) AS V (v)),
-- Numbers table (256)
Nums AS
(
SELECT n = ROW_NUMBER() OVER (ORDER BY A.v)
FROM N16 AS A
CROSS JOIN N16 AS B
),
Trigrams AS
(
-- Every 3-character substring
SELECT TOP (CASE WHEN LEN(@string) > 2 THEN LEN(@string) - 2 ELSE 0 END)
trigram = SUBSTRING(@string, N.n, 3)
FROM Nums AS N
ORDER BY N.n
)
-- Remove duplicates and ensure all three characters are alphanumeric
SELECT DISTINCT
T.trigram
FROM Trigrams AS T
WHERE
-- Binary collation comparison so ranges work as expected
T.trigram COLLATE Latin1_General_BIN2 NOT LIKE '%[^A-Z0-9a-z]%'; Als voorbeeld van het gebruik, de volgende oproep:
SELECT
GT.trigram
FROM dbo.GenerateTrigrams('SQLperformance.com') AS GT; Produceert de volgende trigrammen:

SQLperformance.com trigrammen
Het uitvoeringsplan is in dit geval een vrij directe vertaling van de T-SQL:
- Rijen genereren (kruisverbinding van Constant Scans)
- Rijnummering (segment- en reeksproject)
- Het aantal benodigde getallen beperken op basis van de lengte van de string (Top)
- Verwijder trigrammen met niet-alfanumerieke tekens (Filter)
- Duplicaten verwijderen (afzonderlijke sortering)

Plan voor het genereren van trigrammen
De trigrammen laden
De volgende stap is om trigrammen voor de voorbeeldgegevens te behouden. De trigrammen worden bewaard in een nieuwe tabel, gevuld met de inline-functie die we zojuist hebben gemaakt:
-- Trigrams for Example table
CREATE TABLE dbo.ExampleTrigrams
(
id integer NOT NULL,
trigram char(3) NOT NULL
);
GO
-- Generate trigrams
INSERT dbo.ExampleTrigrams WITH (TABLOCKX)
(id, trigram)
SELECT
E.id,
GT.trigram
FROM dbo.Example AS E
CROSS APPLY dbo.GenerateTrigrams(E.string) AS GT; Dat duurt ongeveer 20 seconden om uit te voeren op mijn SQL Server 2016-laptopinstantie. Deze specifieke run produceerde 17.937.972 rijen van trigrammen voor de 1 miljoen rijen testgegevens van 20 tekens. Het uitvoeringsplan toont in wezen het functieplan dat wordt geëvalueerd voor elke rij van de voorbeeldtabel:
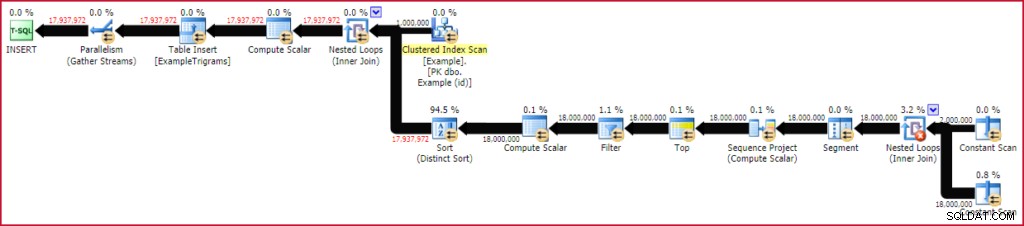
De trigramtabel vullen
Aangezien deze test is uitgevoerd op SQL Server 2016 (laden van een heap-tabel, onder databasecompatibiliteitsniveau 130, en met een TABLOCK hint), profiteert het plan van parallel invoegen. Rijen worden verdeeld tussen threads door de parallelle scan van de voorbeeldtabel en blijven daarna op dezelfde thread (geen uitwisselingen van herpartitionering).
De sorteeroperator ziet er misschien een beetje indrukwekkend uit, maar de cijfers tonen het totale aantal rijen dat is gesorteerd, over alle iteraties van de geneste lusverbinding. In feite zijn er een miljoen verschillende soorten, van elk 18 rijen. Bij een mate van parallellisme van vier (twee cores hyperthreaded in mijn geval), zijn er maximaal vier kleine sorteringen tegelijk aan de gang, en elke sorteerinstantie kan geheugen hergebruiken. Dit verklaart waarom het maximale geheugengebruik van dit uitvoeringsplan slechts 136 KB is (hoewel er 2.152 KB werd toegekend).
De trigrammentabel bevat één rij voor elk afzonderlijk trigram in elke brontabelrij (geïdentificeerd door id ):
Trigram-tabelvoorbeeld
We maken nu een geclusterde b-tree-index om het zoeken naar trigram-overeenkomsten te ondersteunen:
-- Trigram search index
CREATE UNIQUE CLUSTERED INDEX
[CUQ dbo.ExampleTrigrams (trigram, id)]
ON dbo.ExampleTrigrams (trigram, id)
WITH (DATA_COMPRESSION = ROW); Dit duurt ongeveer 45 seconden , hoewel een deel daarvan te wijten is aan het soort morsen (mijn exemplaar is beperkt tot 4 GB geheugen). Een instantie met meer geheugen beschikbaar zou die minimaal gelogde parallelle index waarschijnlijk een stuk sneller kunnen voltooien.
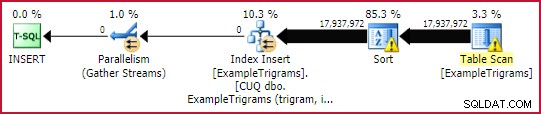
Index bouwplan
Merk op dat de index als uniek is gespecificeerd (met behulp van beide kolommen in de sleutel). We hadden alleen op het trigram een niet-unieke geclusterde index kunnen maken, maar SQL Server zou hoe dan ook 4-byte uniquifiers hebben toegevoegd aan bijna alle rijen. Zodra we er rekening mee houden dat uniquifiers worden opgeslagen in het gedeelte met variabele lengte van de rij (met de bijbehorende overhead), is het gewoon logischer om id op te nemen. in de sleutel en klaar ermee.
Rijcompressie is gespecificeerd omdat het de grootte van de trigramtabel op nuttige wijze verkleint van 277 MB tot 190 MB (ter vergelijking, de voorbeeldtabel is 32 MB). Als u niet op zijn minst SQL Server 2016 SP1 gebruikt (waar datacompressie voor alle edities beschikbaar kwam), kunt u de compressieclausule indien nodig weglaten.
Als laatste optimalisatie zullen we ook een geïndexeerde weergave van de trigrammentabel maken om snel en gemakkelijk te kunnen vinden welke trigrammen het meest en het minst vaak voorkomen in de gegevens. Deze stap kan worden overgeslagen, maar wordt aanbevolen voor prestaties.
-- Selectivity of each trigram (performance optimization)
CREATE VIEW dbo.ExampleTrigramCounts
WITH SCHEMABINDING
AS
SELECT ET.trigram, cnt = COUNT_BIG(*)
FROM dbo.ExampleTrigrams AS ET
GROUP BY ET.trigram;
GO
-- Materialize the view
CREATE UNIQUE CLUSTERED INDEX
[CUQ dbo.ExampleTrigramCounts (trigram)]
ON dbo.ExampleTrigramCounts (trigram); 
Geïndexeerde weergave bouwplan
Dit duurt slechts een paar seconden om te voltooien. De grootte van de gematerialiseerde weergave is klein, slechts 104KB .
Trigram zoeken
Gegeven een zoekreeks (bijv. '%find%this%' ), zal onze benadering zijn om:
- Genereer de complete set trigrammen voor de zoekreeks
- Gebruik de geïndexeerde weergave om de drie meest selectieve trigrammen te vinden
- Vind de id's die overeenkomen met alle beschikbare trigrammen
- Haal de strings op met id
- Het volledige filter toepassen op de trigram-gekwalificeerde rijen
Selectieve trigrammen zoeken
De eerste twee stappen zijn vrij eenvoudig. We hebben al een functie om trigrammen te genereren voor een willekeurige string. Het vinden van de meest selectieve van die trigrammen kan worden bereikt door deel te nemen aan de geïndexeerde weergave. De volgende code verpakt de implementatie voor onze voorbeeldtabel in een andere inline-functie. Het draait de drie meest selectieve trigrammen in een enkele rij voor gebruiksgemak later:
-- Most selective trigrams for a search string
-- Always returns a row (NULLs if no trigrams found)
CREATE FUNCTION dbo.Example_GetBestTrigrams (@string varchar(255))
RETURNS table
WITH SCHEMABINDING AS
RETURN
SELECT
-- Pivot
trigram1 = MAX(CASE WHEN BT.rn = 1 THEN BT.trigram END),
trigram2 = MAX(CASE WHEN BT.rn = 2 THEN BT.trigram END),
trigram3 = MAX(CASE WHEN BT.rn = 3 THEN BT.trigram END)
FROM
(
-- Generate trigrams for the search string
-- and choose the most selective three
SELECT TOP (3)
rn = ROW_NUMBER() OVER (
ORDER BY ETC.cnt ASC),
GT.trigram
FROM dbo.GenerateTrigrams(@string) AS GT
JOIN dbo.ExampleTrigramCounts AS ETC
WITH (NOEXPAND)
ON ETC.trigram = GT.trigram
ORDER BY
ETC.cnt ASC
) AS BT; Als voorbeeld:
SELECT
EGBT.trigram1,
EGBT.trigram2,
EGBT.trigram3
FROM dbo.Example_GetBestTrigrams('%1234%5678%') AS EGBT; retourneert (voor mijn voorbeeldgegevens):
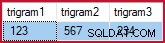
Geselecteerde trigrammen
Het uitvoeringsplan is:
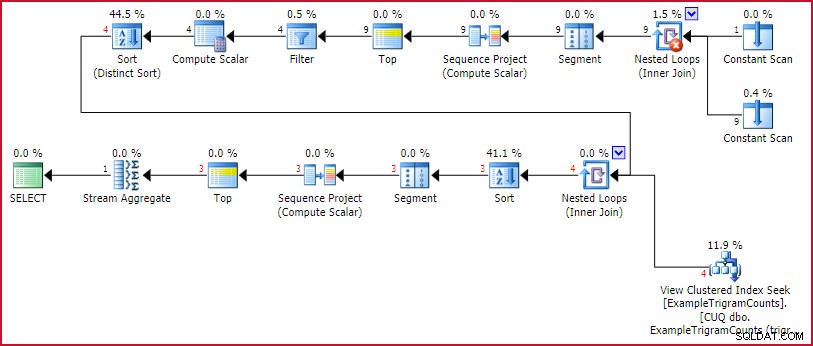
GetBestTrigrams uitvoeringsplan
Dit is het bekende trigramgenererende plan van vroeger, gevolgd door een opzoeking in de geïndexeerde weergave voor elk trigram, sorteren op het aantal overeenkomsten, de rijen nummeren (Sequence Project), de set beperken tot drie rijen (Top), dan draaien het resultaat (Stream Aggregate).
ID's zoeken die overeenkomen met alle trigrammen
De volgende stap is om rij-id's van voorbeeldtabel te vinden die overeenkomen met alle niet-null-trigrammen die door de vorige fase zijn opgehaald. De rimpel hier is dat we nul, één, twee of drie trigrammen beschikbaar hebben. De volgende implementatie verpakt de nodige logica in een functie met meerdere instructies en retourneert de kwalificerende id's in een tabelvariabele:
-- Returns Example ids matching all provided (non-null) trigrams
CREATE FUNCTION dbo.Example_GetTrigramMatchIDs
(
@Trigram1 char(3),
@Trigram2 char(3),
@Trigram3 char(3)
)
RETURNS @IDs table (id integer PRIMARY KEY)
WITH SCHEMABINDING AS
BEGIN
IF @Trigram1 IS NOT NULL
BEGIN
IF @Trigram2 IS NOT NULL
BEGIN
IF @Trigram3 IS NOT NULL
BEGIN
-- 3 trigrams available
INSERT @IDs (id)
SELECT ET1.id
FROM dbo.ExampleTrigrams AS ET1
WHERE ET1.trigram = @Trigram1
INTERSECT
SELECT ET2.id
FROM dbo.ExampleTrigrams AS ET2
WHERE ET2.trigram = @Trigram2
INTERSECT
SELECT ET3.id
FROM dbo.ExampleTrigrams AS ET3
WHERE ET3.trigram = @Trigram3
OPTION (MERGE JOIN);
END;
ELSE
BEGIN
-- 2 trigrams available
INSERT @IDs (id)
SELECT ET1.id
FROM dbo.ExampleTrigrams AS ET1
WHERE ET1.trigram = @Trigram1
INTERSECT
SELECT ET2.id
FROM dbo.ExampleTrigrams AS ET2
WHERE ET2.trigram = @Trigram2
OPTION (MERGE JOIN);
END;
END;
ELSE
BEGIN
-- 1 trigram available
INSERT @IDs (id)
SELECT ET1.id
FROM dbo.ExampleTrigrams AS ET1
WHERE ET1.trigram = @Trigram1;
END;
END;
RETURN;
END; Het geschatte uitvoeringsplan voor deze functie toont de strategie:
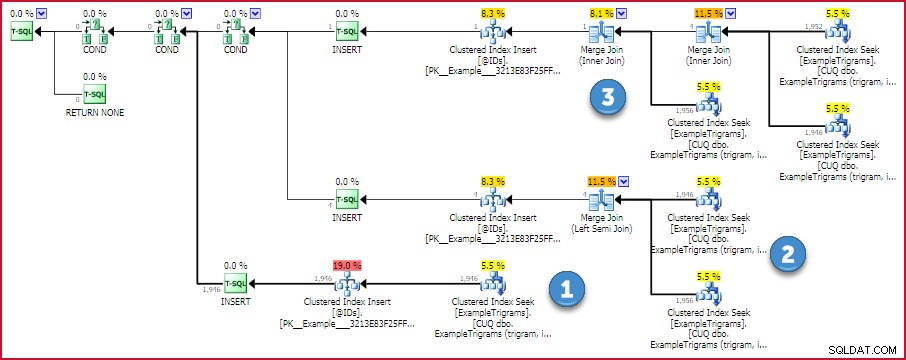
Trigram Match ID-abonnement
Als er één trigram beschikbaar is, wordt er één keer in de trigramtabel gezocht. Anders worden twee of drie zoekopdrachten uitgevoerd en wordt de kruising van id's gevonden met behulp van een efficiënte één-op-veel-samenvoeging(en). Er zijn geen geheugenverslindende operators in dit plan, dus geen kans op een hash- of sorteerfout.
Als we doorgaan met het zoeken naar voorbeelden, kunnen we id's vinden die overeenkomen met de beschikbare trigrammen door de nieuwe functie toe te passen:
SELECT EGTMID.id
FROM dbo.Example_GetBestTrigrams('%1234%5678%') AS EGBT
CROSS APPLY dbo.Example_GetTrigramMatchIDs
(EGBT.trigram1, EGBT.trigram2, EGBT.trigram3) AS EGTMID; Dit geeft een set als volgt terug:

Overeenkomende ID's
Het daadwerkelijke (na uitvoering) plan voor de nieuwe functie toont de vorm van het plan met drie trigram-ingangen die worden gebruikt:
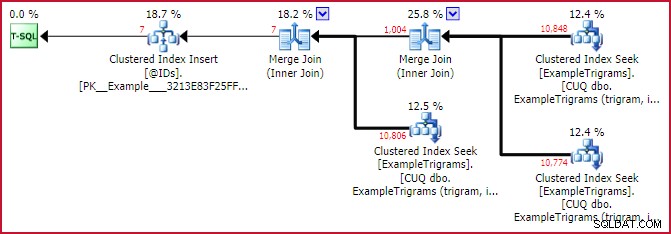
Eigenlijk ID-overeenkomstplan
Dit laat de kracht van trigram-matching vrij goed zien. Hoewel alle drie de trigrammen elk ongeveer 11.000 rijen in de voorbeeldtabel identificeren, reduceert het eerste snijpunt deze set tot 1.004 rijen, en het tweede snijpunt reduceert het tot slechts 7 .
Volledige implementatie van trigram-zoekopdracht
Nu we de id's hebben die overeenkomen met de trigrammen, kunnen we de overeenkomende rijen opzoeken in de voorbeeldtabel. We moeten nog steeds de oorspronkelijke zoekvoorwaarde toepassen als laatste controle, omdat trigrammen valse positieven kunnen genereren (maar geen valse negatieven). Het laatste probleem dat moet worden aangepakt, is dat de vorige fasen mogelijk geen trigrammen hebben gevonden. Dit kan bijvoorbeeld zijn omdat de zoekstring te weinig informatie bevat. Een zoekreeks van '%FF%' kan geen trigram zoeken gebruiken omdat twee karakters niet genoeg zijn om zelfs maar een enkel trigram te genereren. Om dit scenario gracieus af te handelen, zal onze zoekopdracht deze voorwaarde detecteren en terugvallen op een niet-trigram zoekopdracht.
De volgende laatste inline-functie implementeert de vereiste logica:
-- Search implementation
CREATE FUNCTION dbo.Example_TrigramSearch
(
@Search varchar(255)
)
RETURNS table
WITH SCHEMABINDING
AS
RETURN
SELECT
Result.string
FROM dbo.Example_GetBestTrigrams(@Search) AS GBT
CROSS APPLY
(
-- Trigram search
SELECT
E.id,
E.string
FROM dbo.Example_GetTrigramMatchIDs
(GBT.trigram1, GBT.trigram2, GBT.trigram3) AS MID
JOIN dbo.Example AS E
ON E.id = MID.id
WHERE
-- At least one trigram found
GBT.trigram1 IS NOT NULL
AND E.string LIKE @Search
UNION ALL
-- Non-trigram search
SELECT
E.id,
E.string
FROM dbo.Example AS E
WHERE
-- No trigram found
GBT.trigram1 IS NULL
AND E.string LIKE @Search
) AS Result;
Het belangrijkste kenmerk is de buitenste verwijzing naar GBT.trigram1 aan beide zijden van de UNION ALL . Deze vertalen zich naar Filters met opstartexpressies in het uitvoeringsplan. Een opstartfilter voert zijn substructuur alleen uit als de voorwaarde waar is. Het netto-effect is dat slechts één deel van de unie wordt uitgevoerd, afhankelijk van of we een trigram hebben gevonden of niet. Het relevante deel van het uitvoeringsplan is:
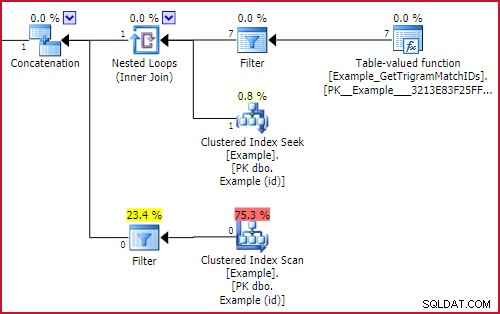
Opstartfiltereffect
Ofwel de Example_GetTrigramMatchIDs functie wordt uitgevoerd (en de resultaten worden opgezocht in Voorbeeld met behulp van een zoekactie op id), of de Clustered Index Scan van Voorbeeld met een resterend LIKE predikaat wordt uitgevoerd, maar niet beide.
Prestaties
De volgende code test de prestaties van het zoeken op trigrammen met de equivalente LIKE :
SET STATISTICS XML OFF
DECLARE @S datetime2 = SYSUTCDATETIME();
SELECT F2.string
FROM dbo.Example AS F2
WHERE
F2.string LIKE '%1234%5678%'
OPTION (MAXDOP 1);
SELECT ElapsedMS = DATEDIFF(MILLISECOND, @S, SYSUTCDATETIME());
GO
SET STATISTICS XML OFF
DECLARE @S datetime2 = SYSUTCDATETIME();
SELECT ETS.string
FROM dbo.Example_TrigramSearch('%1234%5678%') AS ETS;
SELECT ElapsedMS = DATEDIFF(MILLISECOND, @S, SYSUTCDATETIME());
Deze produceren beide dezelfde resultaatrij(en), maar de LIKE zoekopdracht duurt 2100ms , terwijl het zoeken naar trigrammen 15 ms . duurt .
Nog betere prestaties zijn mogelijk. Over het algemeen verbeteren de prestaties naarmate de trigrammen selectiever worden en minder in aantal (onder het maximum van drie in deze implementatie). Bijvoorbeeld:
SET STATISTICS XML OFF
DECLARE @S datetime2 = SYSUTCDATETIME();
SELECT ETS.string
FROM dbo.Example_TrigramSearch('%BEEF%') AS ETS;
SELECT ElapsedMS = DATEDIFF(MILLISECOND, @S, SYSUTCDATETIME());
Die zoekopdracht leverde 111 rijen op in het SSMS-raster in 4ms . De LIKE equivalent liep gedurende 1950ms .
De trigrammen onderhouden
Als de doeltabel statisch is, is het natuurlijk geen probleem om de basistabel en de bijbehorende trigramtabel gesynchroniseerd te houden. Evenzo, als de zoekresultaten niet altijd volledig up-to-date hoeven te zijn, kan een geplande vernieuwing van de trigramtabel(len) goed werken.
Anders kunnen we enkele vrij eenvoudige triggers gebruiken om de trigram-zoekgegevens gesynchroniseerd te houden met de onderliggende strings. Het algemene idee is om trigrammen te genereren voor verwijderde en ingevoegde rijen en deze vervolgens toe te voegen of te verwijderen in de trigramtabel, indien van toepassing. De triggers voor invoegen, bijwerken en verwijderen hieronder laten dit idee in de praktijk zien:
-- Maintain trigrams after Example inserts
CREATE TRIGGER MaintainTrigrams_AI
ON dbo.Example
AFTER INSERT
AS
BEGIN
IF @@ROWCOUNT = 0 RETURN;
IF TRIGGER_NESTLEVEL(@@PROCID, 'AFTER', 'DML') > 1 RETURN;
SET NOCOUNT ON;
SET ROWCOUNT 0;
-- Insert related trigrams
INSERT dbo.ExampleTrigrams
(id, trigram)
SELECT
INS.id, GT.trigram
FROM Inserted AS INS
CROSS APPLY dbo.GenerateTrigrams(INS.string) AS GT;
END; -- Maintain trigrams after Example deletes
CREATE TRIGGER MaintainTrigrams_AD
ON dbo.Example
AFTER DELETE
AS
BEGIN
IF @@ROWCOUNT = 0 RETURN;
IF TRIGGER_NESTLEVEL(@@PROCID, 'AFTER', 'DML') > 1 RETURN;
SET NOCOUNT ON;
SET ROWCOUNT 0;
-- Deleted related trigrams
DELETE ET
WITH (SERIALIZABLE)
FROM Deleted AS DEL
CROSS APPLY dbo.GenerateTrigrams(DEL.string) AS GT
JOIN dbo.ExampleTrigrams AS ET
ON ET.trigram = GT.trigram
AND ET.id = DEL.id;
END; -- Maintain trigrams after Example updates
CREATE TRIGGER MaintainTrigrams_AU
ON dbo.Example
AFTER UPDATE
AS
BEGIN
IF @@ROWCOUNT = 0 RETURN;
IF TRIGGER_NESTLEVEL(@@PROCID, 'AFTER', 'DML') > 1 RETURN;
SET NOCOUNT ON;
SET ROWCOUNT 0;
-- Deleted related trigrams
DELETE ET
WITH (SERIALIZABLE)
FROM Deleted AS DEL
CROSS APPLY dbo.GenerateTrigrams(DEL.string) AS GT
JOIN dbo.ExampleTrigrams AS ET
ON ET.trigram = GT.trigram
AND ET.id = DEL.id;
-- Insert related trigrams
INSERT dbo.ExampleTrigrams
(id, trigram)
SELECT
INS.id, GT.trigram
FROM Inserted AS INS
CROSS APPLY dbo.GenerateTrigrams(INS.string) AS GT;
END;
De triggers zijn behoorlijk efficiënt en verwerken zowel wijzigingen in één rij als in meerdere rijen (inclusief de meerdere acties die beschikbaar zijn bij het gebruik van een MERGE uitspraak). De geïndexeerde weergave van de trigrams-tabel wordt automatisch onderhouden door SQL Server zonder dat we triggercode hoeven te schrijven.
Triggerbewerking
Voer bijvoorbeeld een instructie uit om een willekeurige rij uit de voorbeeldtabel te verwijderen:
-- Single row delete DELETE TOP (1) dbo.Example;
Het (werkelijke) uitvoeringsplan na de uitvoering bevat een vermelding voor de trigger na het verwijderen:
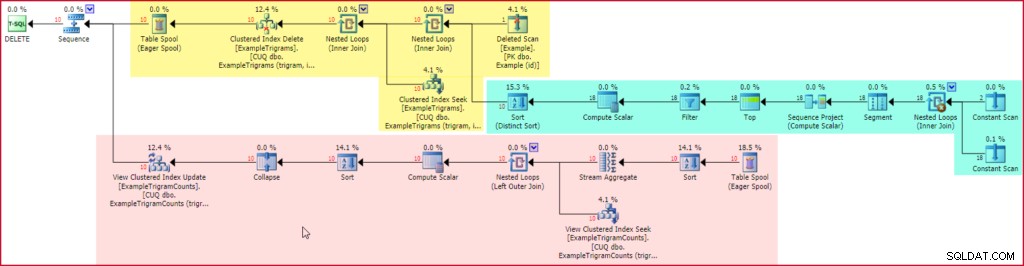
Triggeruitvoeringsplan verwijderen
Het gele gedeelte van het plan leest rijen van de verwijderde pesudo-tabel, genereert trigrammen voor elke verwijderde voorbeeldreeks (met behulp van het bekende plan dat in groen is gemarkeerd), lokaliseert en verwijdert vervolgens de bijbehorende trigramtabelitems. Het laatste deel van het plan, in rood weergegeven, wordt automatisch toegevoegd door SQL Server om de geïndexeerde weergave up-to-date te houden.
Het plan voor de invoegtrigger is zeer vergelijkbaar. Updates worden afgehandeld door het uitvoeren van een verwijdering gevolgd door een invoeging. Voer het volgende script uit om deze plannen te zien en bevestig dat nieuwe en bijgewerkte rijen kunnen worden gevonden met behulp van de trigram-zoekfunctie:
-- Single row insert
INSERT dbo.Example (string)
VALUES ('SQLPerformance.com');
-- Find the new row
SELECT ETS.string
FROM dbo.Example_TrigramSearch('%perf%') AS ETS;
-- Single row update
UPDATE TOP (1) dbo.Example
SET string = '12345678901234567890';
-- Multi-row insert
INSERT dbo.Example WITH (TABLOCKX)
(string)
SELECT TOP (1000)
REPLACE(STR(RAND(CHECKSUM(NEWID())) * 1e10, 10), SPACE(1), '0') +
RIGHT(NEWID(), 10)
FROM master.dbo.spt_values AS SV1;
-- Multi-row update
UPDATE TOP (1000) dbo.Example
SET string = '12345678901234567890';
-- Search for the updated rows
SELECT ETS.string
FROM dbo.Example_TrigramSearch('12345678901234567890') AS ETS; Voorbeeld samenvoegen
Het volgende script toont een MERGE instructie die wordt gebruikt om de voorbeeldtabel in één keer in te voegen, te verwijderen en bij te werken:
-- MERGE demo
DECLARE @MergeData table
(
id integer UNIQUE CLUSTERED NULL,
operation char(3) NOT NULL,
string char(20) NULL
);
INSERT @MergeData
(id, operation, string)
VALUES
(NULL, 'INS', '11223344556677889900'), -- Insert
(1001, 'DEL', NULL), -- Delete
(2002, 'UPD', '00000000000000000000'); -- Update
DECLARE @Actions table
(
action$ nvarchar(10) NOT NULL,
old_id integer NULL,
old_string char(20) NULL,
new_id integer NULL,
new_string char(20) NULL
);
MERGE dbo.Example AS E
USING @MergeData AS MD
ON MD.id = E.id
WHEN MATCHED AND MD.operation = 'DEL'
THEN DELETE
WHEN MATCHED AND MD.operation = 'UPD'
THEN UPDATE SET E.string = MD.string
WHEN NOT MATCHED AND MD.operation = 'INS'
THEN INSERT (string) VALUES (MD.string)
OUTPUT $action, Deleted.id, Deleted.string, Inserted.id, Inserted.string
INTO @Actions (action$, old_id, old_string, new_id, new_string);
SELECT * FROM @Actions AS A; De uitvoer zal iets laten zien als:

Actie-output
Laatste gedachten
Er is misschien enige ruimte om grote verwijderings- en updatebewerkingen te versnellen door rechtstreeks naar id's te verwijzen in plaats van trigrammen te genereren. Dit is hier niet geïmplementeerd omdat het een nieuwe niet-geclusterde index op de trigrams-tabel zou vereisen, waardoor de (reeds aanzienlijke) gebruikte opslagruimte zou worden verdubbeld. De trigrammentabel bevat een enkel geheel getal en een char(3) per rij; een niet-geclusterde index op de integer-kolom zou de char(3) . krijgen kolom op alle niveaus (met dank aan de geclusterde index en de noodzaak dat indexsleutels op elk niveau uniek zijn). Er is ook geheugenruimte om rekening mee te houden, aangezien trigram-zoekopdrachten het beste werken als alle leesbewerkingen uit de cache komen.
De extra index zou trapsgewijze referentiële integriteit een optie maken, maar dat is vaak meer moeite dan het waard is.
Trigram zoeken is geen wondermiddel. De extra opslagvereisten, de complexiteit van de implementatie en de impact op de updateprestaties wegen er allemaal zwaar tegen. De techniek is ook nutteloos voor zoekopdrachten die geen trigrammen genereren (minimaal 3 tekens). Hoewel de hier getoonde basisimplementatie vele soorten zoekopdrachten aankan (begint met, bevat, eindigt met meerdere jokertekens), dekt deze niet elke mogelijke zoekexpressie die kan worden gebruikt om te werken met LIKE . Het werkt goed voor zoekreeksen die trigrammen van het EN-type genereren; er is meer werk nodig om zoekreeksen af te handelen die een OR-type behandeling vereisen, of meer geavanceerde opties zoals reguliere expressies.
Dat gezegd hebbende, als uw aanvraag echt moet hebben snelle zoekopdrachten met jokertekens, n-grammen zijn iets om serieus over na te denken.
Gerelateerde inhoud:Een manier om een index te krijgen, zoek naar een leidende %wildcard door Aaron Bertrand.