Onlangs maakte mijn vriend Erland Sommarskog kennis met een nieuwe eilandenuitdaging. Het is gebaseerd op een vraag van een openbaar databaseforum. De uitdaging zelf is niet ingewikkeld om aan te pakken bij het gebruik van bekende technieken, die voornamelijk vensterfuncties gebruiken. Deze technieken vereisen echter expliciete sortering ondanks de aanwezigheid van een ondersteunende index. Dit heeft gevolgen voor de schaalbaarheid en responstijd van de oplossingen. Ik hield van uitdagingen en ging op zoek naar een oplossing om het aantal expliciete Sort-operators in het plan tot een minimum te beperken, of beter nog, de noodzaak daarvan helemaal te elimineren. En ik heb zo'n oplossing gevonden.
Ik zal beginnen met het presenteren van een algemene vorm van de uitdaging. Ik laat dan twee oplossingen zien op basis van bekende technieken, gevolgd door de nieuwe oplossing. Ten slotte vergelijk ik de prestaties van de verschillende oplossingen.
Ik raad je aan een oplossing te zoeken voordat je de mijne implementeert.
De uitdaging
Ik zal een algemene vorm van de oorspronkelijke eilandenuitdaging van Erland presenteren.
Gebruik de volgende code om een tabel met de naam T1 te maken en deze te vullen met een kleine set voorbeeldgegevens:
SET NOCOUNT ON;
USE tempdb;
DROP TABLE IF EXISTS dbo.T1
CREATE TABLE dbo.T1
(
grp VARCHAR(10) NOT NULL,
ord INT NOT NULL,
val VARCHAR(10) NOT NULL,
CONSTRAINT PK_T1 PRIMARY KEY(grp, ord)
);
GO
INSERT INTO dbo.T1(grp, ord, val) VALUES
('Group A', 1002, 'Y'),
('Group A', 1003, 'Y'),
('Group A', 1005, 'Y'),
('Group A', 1007, 'N'),
('Group A', 1011, 'N'),
('Group A', 1013, 'N'),
('Group A', 1017, 'Y'),
('Group A', 1019, 'Y'),
('Group A', 1023, 'N'),
('Group A', 1029, 'N'),
('Group B', 1001, 'X'),
('Group B', 1002, 'X'),
('Group B', 1003, 'Z'),
('Group B', 1005, 'Z'),
('Group B', 1008, 'Z'),
('Group B', 1013, 'Z'),
('Group B', 1021, 'Y'),
('Group B', 1034, 'Y'); De uitdaging is als volgt:
Uitgaande van partitionering op basis van de kolom-grp en volgorde op basis van de kolomvolgorde, berekent u opeenvolgende rijnummers beginnend met 1 binnen elke opeenvolgende groep rijen met dezelfde waarde in de val-kolom. Hieronder volgt het gewenste resultaat voor de gegeven kleine set voorbeeldgegevens:
grp ord val seqno -------- ----- ---- ------ Group A 1002 Y 1 Group A 1003 Y 2 Group A 1005 Y 3 Group A 1007 N 1 Group A 1011 N 2 Group A 1013 N 3 Group A 1017 Y 1 Group A 1019 Y 2 Group A 1023 N 1 Group A 1029 N 2 Group B 1001 X 1 Group B 1002 X 2 Group B 1003 Z 1 Group B 1005 Z 2 Group B 1008 Z 3 Group B 1013 Z 4 Group B 1021 Y 1 Group B 1034 Y 2
Let op de definitie van de primaire sleutelbeperking op basis van de samengestelde sleutel (grp, ord), wat resulteert in een geclusterde index op basis van dezelfde sleutel. Deze index kan mogelijk vensterfuncties ondersteunen, gepartitioneerd op grp en geordend op bestelling.
Om de prestaties van uw oplossing te testen, moet u de tabel vullen met grotere hoeveelheden voorbeeldgegevens. Gebruik de volgende code om de helperfunctie GetNums te maken:
CREATE FUNCTION dbo.GetNums(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Gebruik de volgende code om T1 in te vullen, nadat u de parameters die het aantal groepen, het aantal rijen per groep en het aantal verschillende waarden vertegenwoordigen naar wens hebt gewijzigd:
DECLARE
@numgroups AS INT = 1000,
@rowspergroup AS INT = 10000, -- test with 1000 to 10000 here
@uniquevalues AS INT = 5;
ALTER TABLE dbo.T1 DROP CONSTRAINT PK_T1;
TRUNCATE TABLE dbo.T1;
INSERT INTO dbo.T1 WITH(TABLOCK) (grp, ord, val)
SELECT
CAST(G.n AS VARCHAR(10)) AS grp,
CAST(R.n AS INT) AS ord,
CAST(ABS(CHECKSUM(NEWID())) % @uniquevalues + 1 AS VARCHAR(10)) AS val
FROM dbo.GetNums(1, @numgroups) AS G
CROSS JOIN dbo.GetNums(1, @rowspergroup) AS R;
ALTER TABLE dbo.T1 ADD CONSTRAINT PK_T1 PRIMARY KEY CLUSTERED(grp, ord);
In mijn prestatietests vulde ik de tabel met 1.000 groepen, tussen 1.000 en 10.000 rijen per groep (dus 1 miljoen tot 10 miljoen rijen) en 5 verschillende waarden. Ik gebruikte een SELECT INTO statement om het resultaat in een tijdelijke tabel te schrijven.
Mijn testmachine heeft vier logische CPU's, waarop SQL Server 2019 Enterprise draait.
Ik neem aan dat je een omgeving gebruikt die is ontworpen om de batchmodus in rijopslag te ondersteunen, hetzij direct, bijvoorbeeld door SQL Server 2019 Enterprise-editie zoals de mijne te gebruiken, of indirect, door een dummy columnstore-index op de tabel te maken.
Denk aan extra punten als het je lukt om een efficiënte oplossing te bedenken zonder expliciete sortering in het plan. Veel succes!
Is een sorteeroperator nodig bij de optimalisatie van vensterfuncties?
Voordat ik oplossingen bespreek, een beetje achtergrond over optimalisatie, dus wat u later in de queryplannen ziet, is logischer.
De meest gebruikelijke technieken voor het oplossen van eilandtaken zoals die van ons, zijn het gebruik van een combinatie van aggregatie- en/of rangschikkingsvensterfuncties. SQL Server kan dergelijke vensterfuncties verwerken met behulp van een reeks oudere operatoren voor rijmodus (Segment, Sequence Project, Segment, Window Spool, Stream Aggregate) of de nieuwere en meestal efficiëntere Window Aggregate-operator in batchmodus.
In beide gevallen moeten de operators die de berekening van de vensterfunctie uitvoeren, de gegevens opnemen die zijn besteld door de elementen voor het partitioneren en bestellen van vensters. Als u geen ondersteunende index heeft, moet SQL Server natuurlijk een sorteeroperator in het plan opnemen. Als u bijvoorbeeld meerdere vensterfuncties in uw oplossing heeft met meer dan één unieke combinatie van partitionering en volgorde, zult u ongetwijfeld expliciete sortering in het plan hebben. Maar wat als je maar één unieke combinatie hebt van partitioneren en ordenen en een ondersteunende index?
De oudere rijmodusmethode kan vertrouwen op vooraf geordende gegevens die zijn opgenomen uit een index zonder de noodzaak van een expliciete sorteeroperator in zowel seriële als parallelle modi. De nieuwere batchmodusoperator elimineert veel van de inefficiënties van de oudere rijmodusoptimalisatie en heeft de inherente voordelen van batchmodusverwerking. De huidige parallelle implementatie vereist echter een intermediaire batchmodus parallelle sorteeroperator, zelfs wanneer een ondersteunende index aanwezig is. Alleen de seriële implementatie ervan kan vertrouwen op indexvolgorde zonder een sorteeroperator. Dit wil allemaal zeggen dat wanneer de optimizer een strategie moet kiezen om uw vensterfunctie af te handelen, ervan uitgaande dat u een ondersteunende index heeft, dit over het algemeen een van de volgende vier opties zal zijn:
- Rijmodus, serieel, geen sortering
- Rijmodus, parallel, geen sortering
- Batchmodus, serieel, geen sortering
- Batchmodus, parallel, sorteren
Welke optie ook resulteert in de laagste plankosten, zal worden gekozen, ervan uitgaande dat natuurlijk aan de voorwaarden voor parallellisme en batchmodus wordt voldaan bij het overwegen hiervan. Normaal gesproken, als de optimizer een parallel plan wil rechtvaardigen, moeten de voordelen van parallellisme opwegen tegen het extra werk, zoals threadsynchronisatie. Bij optie 4 hierboven moeten de voordelen van parallellisme opwegen tegen het gebruikelijke extra werk dat gepaard gaat met parallellisme, plus de extra sortering.
Tijdens het experimenteren met verschillende oplossingen voor onze uitdaging, had ik gevallen waarin de optimizer optie 2 hierboven koos. Het koos ervoor ondanks het feit dat de rijmodusmethode enkele inefficiënties met zich meebrengt, omdat de voordelen van parallellisme en geen sortering resulteerden in een plan met lagere kosten dan de alternatieven. In sommige van die gevallen resulteerde het forceren van een serieel plan met een hint in optie 3 hierboven en in betere prestaties.
Laten we met deze achtergrond in gedachten naar oplossingen kijken. Ik zal beginnen met twee oplossingen die gebaseerd zijn op bekende technieken voor eilandtaken die niet kunnen ontsnappen aan expliciete sortering in het plan.
Oplossing gebaseerd op bekende techniek 1
Hieronder volgt de eerste oplossing voor onze uitdaging, die gebaseerd is op een techniek die al een tijdje bekend is:
WITH C AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY ord) -
ROW_NUMBER() OVER(PARTITION BY grp, val ORDER BY ord) AS island
FROM dbo.T1
)
SELECT grp, ord, val,
ROW_NUMBER() OVER(PARTITION BY grp, val, island ORDER BY ord) AS seqno
FROM C; Ik noem het bekende oplossing 1.
De CTE met de naam C is gebaseerd op een query die twee rijnummers berekent. De eerste (ik noem het rn1) is gepartitioneerd op grp en geordend op bestelling. De tweede (ik noem het rn2) is gepartitioneerd door grp en val en geordend op bestelling. Aangezien rn1 hiaten heeft tussen verschillende groepen van dezelfde val en rn2 niet, is het verschil tussen rn1 en rn2 (kolom genaamd eiland) een unieke constante waarde voor alle rijen met dezelfde grp- en val-waarden. Hieronder volgt het resultaat van de innerlijke query, inclusief de resultaten van de berekeningen met twee rijen getallen, die niet als afzonderlijke kolommen worden geretourneerd:
grp ord val rn1 rn2 island -------- ----- ---- ---- ---- ------- Group A 1002 Y 1 1 0 Group A 1003 Y 2 2 0 Group A 1005 Y 3 3 0 Group A 1007 N 4 1 3 Group A 1011 N 5 2 3 Group A 1013 N 6 3 3 Group A 1017 Y 7 4 3 Group A 1019 Y 8 5 3 Group A 1023 N 9 4 5 Group A 1029 N 10 5 5 Group B 1001 X 1 1 0 Group B 1002 X 2 2 0 Group B 1003 Z 3 1 2 Group B 1005 Z 4 2 2 Group B 1008 Z 5 3 2 Group B 1013 Z 6 4 2 Group B 1021 Y 7 1 6 Group B 1034 Y 8 2 6
Wat de buitenste query nog moet doen, is het berekenen van de resultaatkolom seqno met behulp van de ROW_NUMBER-functie, gepartitioneerd op grp, val en eiland, en geordend op volgorde, om het gewenste resultaat te genereren.
Merk op dat u dezelfde eilandwaarde kunt krijgen voor verschillende valwaarden binnen dezelfde partitie, zoals in de bovenstaande uitvoer. Daarom is het belangrijk om grp, val en eiland als raamscheidingselementen te gebruiken en niet alleen grp en eiland.
Evenzo, als u te maken hebt met een eilandtaak waarbij u de gegevens moet groeperen op het eiland en groepsaggregaten moet berekenen, zou u de rijen groeperen op grp, val en eiland. Maar dit is niet het geval met onze uitdaging. Hier kreeg je de taak om voor elk eiland afzonderlijk rijnummers te berekenen.
Afbeelding 1 heeft het standaardplan dat ik voor deze oplossing op mijn computer heb gekregen nadat ik de tabel met 10 miljoen rijen had gevuld.
 Figuur 1:Parallel plan voor bekende oplossing 1
Figuur 1:Parallel plan voor bekende oplossing 1
De berekening van rn1 kan vertrouwen op indexvolgorde. Dus koos de optimizer de strategie zonder sorteren + parallelle rijmodus voor deze (eerste Segment- en Sequence Project-operators in het plan). Aangezien de berekeningen van zowel rn2 als seqno hun eigen unieke combinaties van partitionerings- en ordeningselementen gebruiken, is expliciet sorteren onvermijdelijk voor die, ongeacht de gebruikte strategie. Dus de optimizer koos voor beide de strategie voor sorteren + parallelle batchmodus. Bij dit plan zijn twee expliciete Sort-operators betrokken.
In mijn prestatietest kostte het deze oplossing 3,68 seconden om te voltooien tegen 1 miljoen rijen en 43,1 seconden tegen 10 miljoen rijen.
Zoals vermeld, heb ik alle oplossingen ook getest door een serieel plan te forceren (met een MAXDOP 1-hint). Het seriële plan voor deze oplossing wordt getoond in figuur 1.
 Figuur 2:Serieel plan voor bekende oplossing 1
Figuur 2:Serieel plan voor bekende oplossing 1
Zoals verwacht, gebruikt ook de berekening van rn1 deze keer de batchmodusstrategie zonder een voorafgaande Sort-operator, maar het plan heeft nog steeds twee Sort-operatoren voor de daaropvolgende rijnummerberekeningen. Het seriële plan presteerde slechter dan het parallelle plan op mijn machine met alle invoerformaten die ik heb getest, het duurde 4,54 seconden om te voltooien met 1M rijen en 61,5 seconden met 10M rijen.
Oplossing gebaseerd op bekende techniek 2
De tweede oplossing die ik zal presenteren, is gebaseerd op een briljante techniek voor eilanddetectie die ik een paar jaar geleden van Paul White heb geleerd. Hieronder volgt de volledige oplossingscode op basis van deze techniek:
WITH C1 AS
(
SELECT *,
CASE
WHEN val = LAG(val) OVER(PARTITION BY grp ORDER BY ord) THEN 0
ELSE 1
END AS isstart
FROM dbo.T1
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY grp ORDER BY ord ROWS UNBOUNDED PRECEDING) AS island
FROM C1
)
SELECT grp, ord, val,
ROW_NUMBER() OVER(PARTITION BY grp, island ORDER BY ord) AS seqno
FROM C2; Ik noem deze oplossing Bekende oplossing 2.
De query die de CTE C1-berekeningen definieert, gebruikt een CASE-expressie en de LAG-vensterfunctie (gepartitioneerd op grp en geordend op volgorde) om een resultaatkolom met de naam isstart te berekenen. Deze kolom heeft de waarde 0 wanneer de huidige waarde gelijk is aan de vorige en anders 1. Met andere woorden, het is 1 wanneer de rij de eerste is op een eiland en 0 anders.
Hieronder volgt de uitvoer van de query die C1 definieert:
grp ord val isstart -------- ----- ---- -------- Group A 1002 Y 1 Group A 1003 Y 0 Group A 1005 Y 0 Group A 1007 N 1 Group A 1011 N 0 Group A 1013 N 0 Group A 1017 Y 1 Group A 1019 Y 0 Group A 1023 N 1 Group A 1029 N 0 Group B 1001 X 1 Group B 1002 X 0 Group B 1003 Z 1 Group B 1005 Z 0 Group B 1008 Z 0 Group B 1013 Z 0 Group B 1021 Y 1 Group B 1034 Y 0
De magie wat betreft eilanddetectie gebeurt in de CTE C2. De query die het definieert, berekent een eiland-ID met behulp van de SUM-vensterfunctie (ook gepartitioneerd op grp en geordend op volgorde) toegepast op de isstart-kolom. De resultaatkolom met de eilandidentificatie wordt eiland genoemd. Binnen elke partitie krijg je 1 voor het eerste eiland, 2 voor het tweede eiland, enzovoort. De combinatie van kolommen grp en eiland is dus een eiland-ID, die u kunt gebruiken in eilandtaken waarbij, indien relevant, gegroepeerd moet worden op eiland.
Hieronder volgt de uitvoer van de query die C2 definieert:
grp ord val isstart island -------- ----- ---- -------- ------- Group A 1002 Y 1 1 Group A 1003 Y 0 1 Group A 1005 Y 0 1 Group A 1007 N 1 2 Group A 1011 N 0 2 Group A 1013 N 0 2 Group A 1017 Y 1 3 Group A 1019 Y 0 3 Group A 1023 N 1 4 Group A 1029 N 0 4 Group B 1001 X 1 1 Group B 1002 X 0 1 Group B 1003 Z 1 2 Group B 1005 Z 0 2 Group B 1008 Z 0 2 Group B 1013 Z 0 2 Group B 1021 Y 1 3 Group B 1034 Y 0 3
Ten slotte berekent de buitenste query de gewenste resultaatkolom seqno met een ROW_NUMBER-functie, gepartitioneerd op grp en eiland, en geordend op ord. Merk op dat deze combinatie van elementen voor partitioneren en ordenen verschilt van de combinatie die werd gebruikt door de vorige vensterfuncties. Terwijl de berekening van de eerste twee vensterfuncties mogelijk op indexvolgorde kan vertrouwen, kan de laatste dat niet.
Afbeelding 3 heeft het standaardplan dat ik voor deze oplossing heb gekregen.
 Figuur 3:Parallel plan voor bekende oplossing 2
Figuur 3:Parallel plan voor bekende oplossing 2
Zoals u in het plan kunt zien, gebruikt de berekening van de eerste twee vensterfuncties de strategie zonder sorteren + parallelle rijmodus, en de berekening van de laatste gebruikt de strategie voor sorteren + parallelle batchmodus.
De looptijden die ik voor deze oplossing kreeg, varieerden van 2,57 seconden voor rijen van 1 miljoen tot 46,2 seconden voor rijen van 10 miljoen.
Bij het forceren van seriële verwerking kreeg ik het plan weergegeven in figuur 4.
 Figuur 4:Serieel plan voor bekende oplossing 2
Figuur 4:Serieel plan voor bekende oplossing 2
Zoals verwacht, zijn deze keer alle vensterfunctieberekeningen afhankelijk van de batchmodusstrategie. De eerste twee zonder voorafgaande sortering, en de laatste met. Zowel het parallelle plan als het seriële plan omvatte één expliciete sorteeroperator. Het seriële plan presteerde beter dan het parallelle plan op mijn machine met de invoerformaten die ik heb getest. De looptijden die ik kreeg voor het geforceerde seriële plan varieerden van 1,75 seconden tegen 1 miljoen rijen tot 21,7 seconden tegen 10 miljoen rijen.
Oplossing op basis van nieuwe techniek
Toen Erland deze uitdaging op een besloten forum introduceerde, waren mensen sceptisch over de mogelijkheid om het op te lossen met een vraag die was geoptimaliseerd met een plan zonder expliciete sortering. Dat is alles wat ik moest horen om me te motiveren. Dus dit is wat ik bedacht:
WITH C1 AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY ord) AS rn,
LAG(val) OVER(PARTITION BY grp ORDER BY ord) AS prev
FROM dbo.T1
),
C2 AS
(
SELECT *,
MAX(CASE WHEN val = prev THEN NULL ELSE rn END)
OVER(PARTITION BY grp ORDER BY ord ROWS UNBOUNDED PRECEDING) AS firstrn
FROM C1
)
SELECT grp, ord, val, rn - firstrn + 1 AS seqno
FROM C2; De oplossing gebruikt drie vensterfuncties:LAG, ROW_NUMBER en MAX. Het belangrijkste hier is dat ze alle drie zijn gebaseerd op grp-partitionering en volgordevolgorde, die is uitgelijnd met de ondersteunende indexsleutelvolgorde.
De query die de CTE C1 definieert, gebruikt de ROW_NUMBER-functie om rijnummers (rn-kolom) te berekenen en de LAG-functie om de vorige valwaarde te retourneren (vorige kolom).
Dit is de uitvoer van de query die C1 definieert:
grp ord val rn prev -------- ----- ---- --- ----- Group A 1002 Y 1 NULL Group A 1003 Y 2 Y Group A 1005 Y 3 Y Group A 1007 N 4 Y Group A 1011 N 5 N Group A 1013 N 6 N Group A 1017 Y 7 N Group A 1019 Y 8 Y Group A 1023 N 9 Y Group A 1029 N 10 N Group B 1001 X 1 NULL Group B 1002 X 2 X Group B 1003 Z 3 X Group B 1005 Z 4 Z Group B 1008 Z 5 Z Group B 1013 Z 6 Z Group B 1021 Y 7 Z Group B 1034 Y 8 Y
Merk op dat wanneer val en prev hetzelfde zijn, het niet de eerste rij op het eiland is, anders is het dat wel.
Op basis van deze logica gebruikt de query die de CTE C2 definieert een CASE-expressie die rn retourneert wanneer de rij de eerste in een eiland is en anders NULL. De code past vervolgens de MAX-vensterfunctie toe op het resultaat van de CASE-expressie, waarbij de eerste rn van het eiland wordt geretourneerd (eerste kolom).
Dit is de uitvoer van de query die C2 definieert, inclusief de uitvoer van de CASE-expressie:
grp ord val rn prev CASE firstrn -------- ----- ---- --- ----- ----- -------- Group A 1002 Y 1 NULL 1 1 Group A 1003 Y 2 Y NULL 1 Group A 1005 Y 3 Y NULL 1 Group A 1007 N 4 Y 4 4 Group A 1011 N 5 N NULL 4 Group A 1013 N 6 N NULL 4 Group A 1017 Y 7 N 7 7 Group A 1019 Y 8 Y NULL 7 Group A 1023 N 9 Y 9 9 Group A 1029 N 10 N NULL 9 Group B 1001 X 1 NULL 1 1 Group B 1002 X 2 X NULL 1 Group B 1003 Z 3 X 3 3 Group B 1005 Z 4 Z NULL 3 Group B 1008 Z 5 Z NULL 3 Group B 1013 Z 6 Z NULL 3 Group B 1021 Y 7 Z 7 7 Group B 1034 Y 8 Y NULL 7
Wat overblijft voor de buitenste query is om de gewenste resultaatkolom seqno te berekenen als rn minus firstrn plus 1.
Afbeelding 5 heeft het standaard parallelle plan dat ik voor deze oplossing heb gekregen toen ik het testte met behulp van een SELECT INTO-instructie, waarbij het resultaat in een tijdelijke tabel werd geschreven.
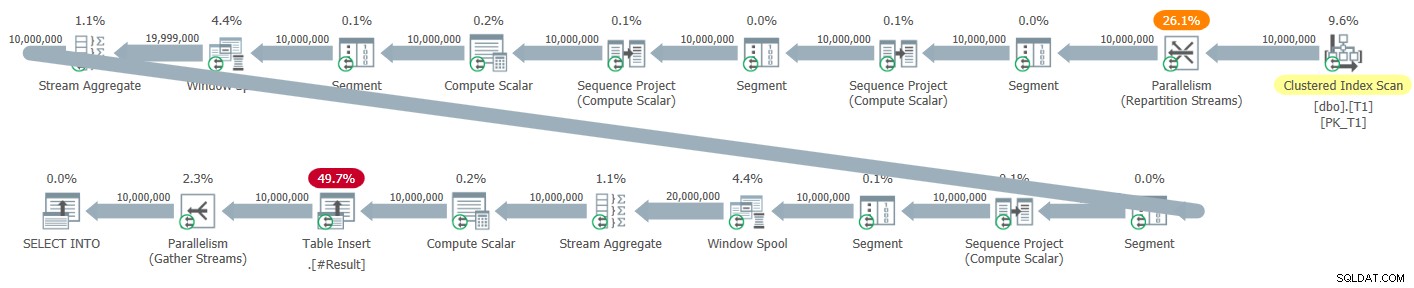 Figuur 5:Parallel plan voor een nieuwe oplossing
Figuur 5:Parallel plan voor een nieuwe oplossing
Er zijn geen expliciete sorteeroperatoren in dit plan. Alle drie de vensterfuncties worden echter berekend met behulp van de strategie zonder sorteren + parallelle rijmodus, dus we missen de voordelen van batchverwerking. De looptijden die ik kreeg voor deze oplossing met het parallelle plan varieerden van 2,47 seconden tegen 1M rijen en 41,4 tegen 10M rijen.
Hier is de kans groot dat een serieel plan met batchverwerking het aanzienlijk beter doet, vooral wanneer de machine niet veel CPU's heeft. Bedenk dat ik mijn oplossingen test tegen een machine met 4 logische CPU's. Afbeelding 6 heeft het plan dat ik voor deze oplossing heb gekregen bij het forceren van seriële verwerking.
 Figuur 6:Serieel plan voor een nieuwe oplossing
Figuur 6:Serieel plan voor een nieuwe oplossing
Alle drie de vensterfuncties gebruiken de strategie zonder sorteren + seriële batchmodus. En de resultaten zijn behoorlijk indrukwekkend. De looptijden van deze oplossing varieerden van 0,5 seconden voor rijen van 1 miljoen en 5,49 seconden voor rijen van 10 miljoen. Wat ook merkwaardig is aan deze oplossing, is dat SQL Server bij het testen als een normale SELECT-instructie (waarbij de resultaten worden weggegooid) in tegenstelling tot een SELECT INTO-instructie, standaard het seriële plan heeft gekozen. Met de andere twee oplossingen kreeg ik standaard een parallel plan, zowel met SELECT als met SELECT INTO.
Zie het volgende gedeelte voor de volledige prestatietestresultaten.
Prestatievergelijking
Hier is de code die ik heb gebruikt om de drie oplossingen te testen, natuurlijk zonder commentaar op de MAXDOP 1-hint om de seriële plannen te testen:
-- Test Known Solution 1
DROP TABLE IF EXISTS #Result;
WITH C AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY ord) -
ROW_NUMBER() OVER(PARTITION BY grp, val ORDER BY ord) AS island
FROM dbo.T1
)
SELECT grp, ord, val,
ROW_NUMBER() OVER(PARTITION BY grp, val, island ORDER BY ord) AS seqno
INTO #Result
FROM C
/* OPTION(MAXDOP 1) */; -- uncomment for serial test
GO
-- Test Known Solution 2
DROP TABLE IF EXISTS #Result;
WITH C1 AS
(
SELECT *,
CASE
WHEN val = LAG(val) OVER(PARTITION BY grp ORDER BY ord) THEN 0
ELSE 1
END AS isstart
FROM dbo.T1
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY grp ORDER BY ord ROWS UNBOUNDED PRECEDING) AS island
FROM C1
)
SELECT grp, ord, val,
ROW_NUMBER() OVER(PARTITION BY grp, island ORDER BY ord) AS seqno
INTO #Result
FROM C2
/* OPTION(MAXDOP 1) */;
GO
-- Test New Solution
DROP TABLE IF EXISTS #Result;
WITH C1 AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY ord) AS rn,
LAG(val) OVER(PARTITION BY grp ORDER BY ord) AS prev
FROM dbo.T1
),
C2 AS
(
SELECT *,
MAX(CASE WHEN val = prev THEN NULL ELSE rn END)
OVER(PARTITION BY grp ORDER BY ord ROWS UNBOUNDED PRECEDING) AS firstrn
FROM C1
)
SELECT grp, ord, val, rn - firstrn + 1 AS seqno
INTO #Result
FROM C2
/* OPTION(MAXDOP 1) */; Afbeelding 7 toont de looptijden van zowel de parallelle als de seriële plannen voor alle oplossingen tegen verschillende invoergroottes.
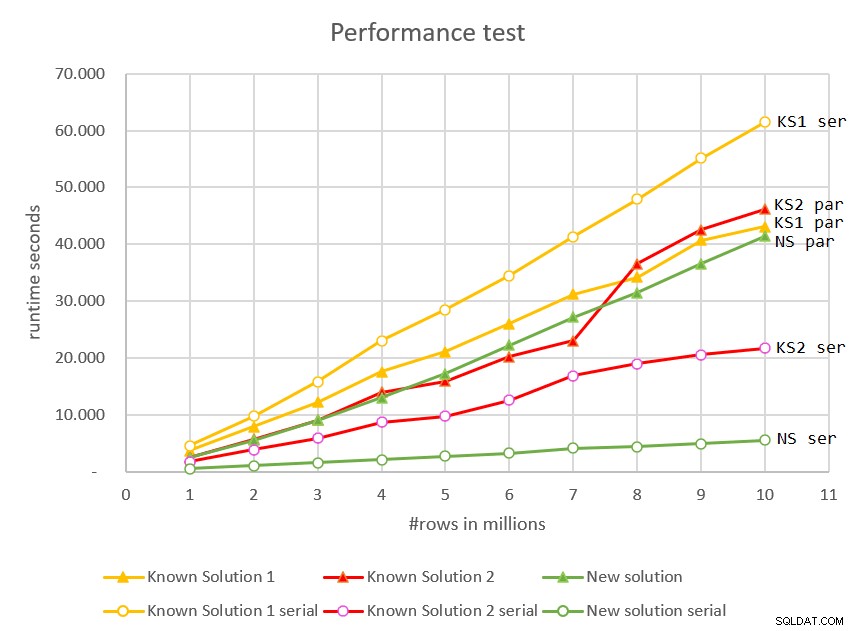 Figuur 7:Prestatievergelijking
Figuur 7:Prestatievergelijking
De nieuwe oplossing, die gebruikmaakt van de seriële modus, is de duidelijke winnaar. Het heeft geweldige prestaties, lineaire schaalbaarheid en onmiddellijke responstijd.
Conclusie
Eilandtaken komen in het echte leven vrij vaak voor. Veel van hen omvatten zowel het identificeren van eilanden als het groeperen van de gegevens per eiland. De uitdaging van de eilandengroep van Erland, waar dit artikel zich op richtte, is een beetje unieker omdat het niet gaat om groeperen, maar om het rangschikken van de rijen van elk eiland met rijnummers.
Ik presenteerde twee oplossingen op basis van bekende technieken voor het identificeren van eilanden. Het probleem met beide is dat ze resulteren in plannen met expliciete sortering, wat een negatief effect heeft op de prestaties, schaalbaarheid en responstijd van de oplossingen. Ik presenteerde ook een nieuwe techniek die resulteerde in een plan zonder sorteren. Het seriële plan voor deze oplossing, die een strategie zonder sortering + seriële batchmodus gebruikt, biedt uitstekende prestaties, lineaire schaalbaarheid en onmiddellijke responstijd. Het is jammer, althans voorlopig, we kunnen geen strategie hebben zonder sort + parallelle batchmodus voor het afhandelen van vensterfuncties.