Post van Dan Holmes, die blogt op sql.dnhlms.com.
SQL Server Books Online (BOL), whitepapers en vele andere bronnen laten u zien hoe en waarom u statistieken over een tabel of index wilt bijwerken. U krijgt echter maar één manier om die waarden vorm te geven. Ik zal je laten zien hoe je de statistieken precies kunt maken zoals je wilt binnen de grenzen van de 200 beschikbare stappen.
Disclaimer :Dit werkt voor mij omdat ik mijn applicatie, mijn database en de normale werkstroom- en applicatiegebruikspatronen van mijn gebruiker ken. Het gebruikt echter niet-gedocumenteerde opdrachten en kan, als het verkeerd wordt gebruikt, ervoor zorgen dat uw toepassing aanzienlijk slechter presteert.In onze applicatie leest en schrijft de Scheduling-gebruiker regelmatig gegevens die gebeurtenissen voor morgen en de komende dagen vertegenwoordigen. Gegevens voor vandaag en eerder worden niet gebruikt door de Scheduler. Als eerste in de ochtend begint de dataset voor morgen bij een paar honderd rijen en tegen de middag kan het 1400 en hoger zijn. Het volgende diagram illustreert het aantal rijen. Deze gegevens zijn verzameld op woensdagochtend 18 november 2015. Historisch gezien kunt u zien dat het normale aantal rijen ongeveer 1.400 is, behalve voor weekenddagen en de volgende dag.
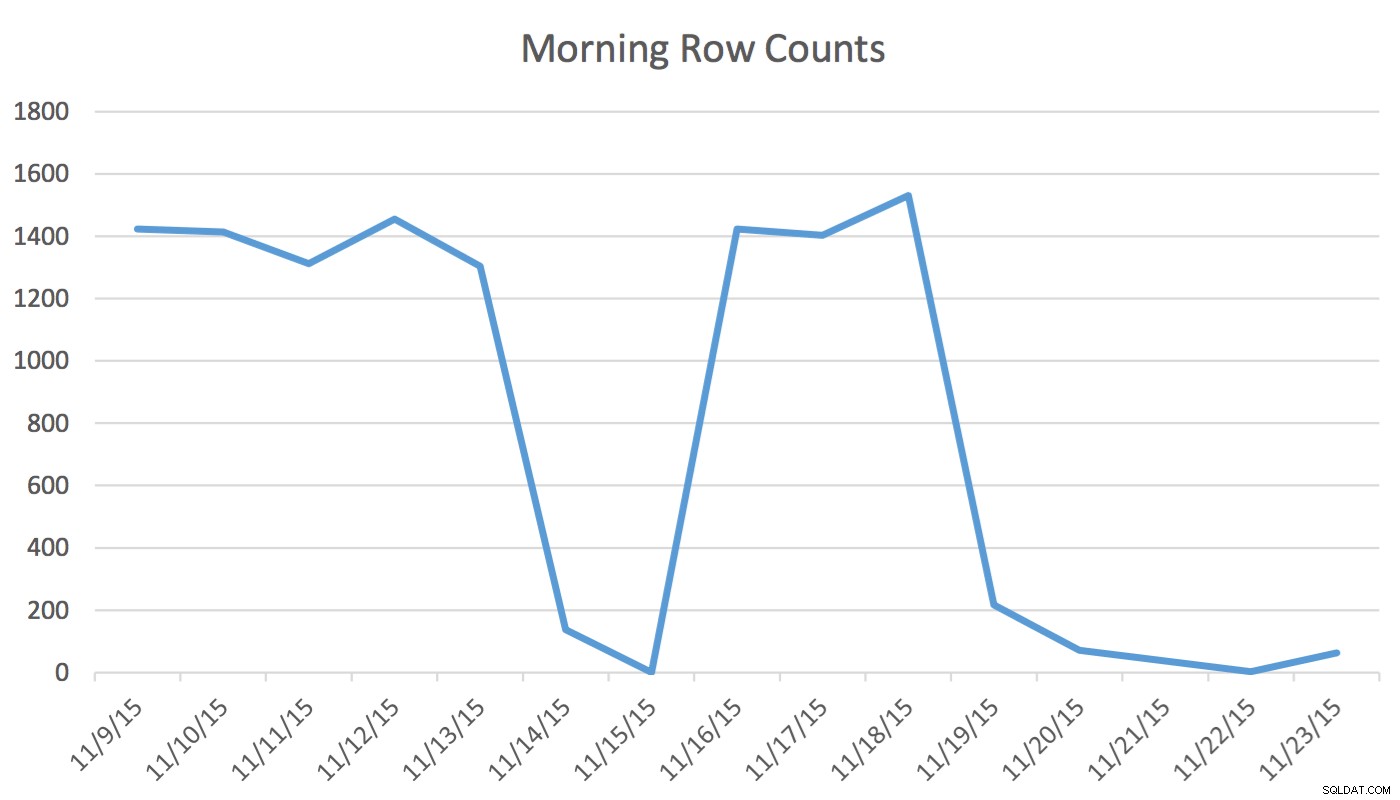
Voor de Scheduler zijn de enige relevante gegevens de komende dagen. Wat er vandaag gebeurt en gisteren is gebeurd, is niet relevant voor zijn activiteit. Dus hoe veroorzaakt dit een probleem? Deze tabel heeft 2.259.205 rijen, wat betekent dat de wijziging in het aantal rijen van 's ochtends tot 's middags niet voldoende is om een door SQL Server geïnitieerde statistische update te activeren. Verder een handmatig geplande taak die statistieken maakt met behulp van UPDATE STATISTICS vult het histogram met een steekproef van alle gegevens in de tabel, maar bevat mogelijk niet de relevante informatie. Deze delta van het aantal rijen is voldoende om het plan te wijzigen. Zonder een statistische update en een nauwkeurig histogram zal het plan echter niet ten goede veranderen naarmate de gegevens veranderen.
Een relevante selectie van het histogram voor deze tabel uit een back-up gedateerd op 4-11-2015 kan er als volgt uitzien:
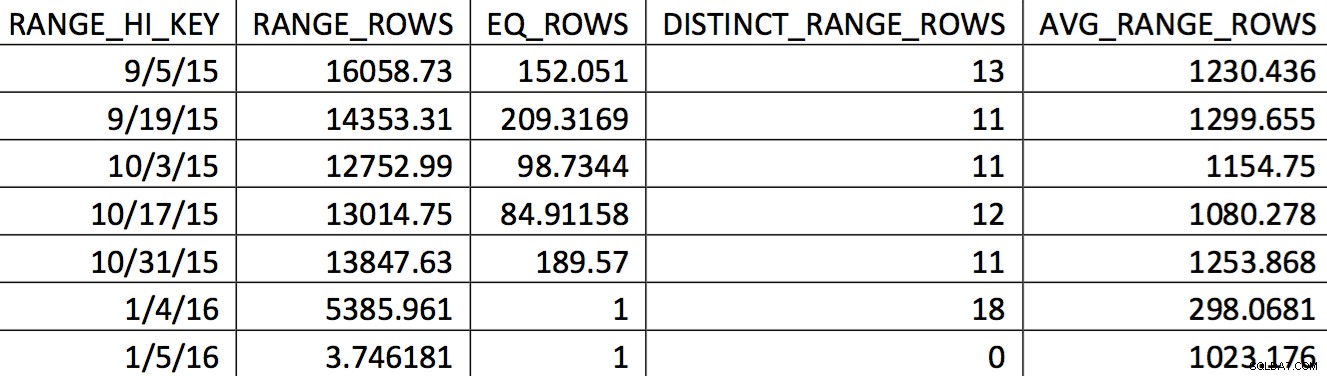
De waarden van belang worden niet nauwkeurig weergegeven in het histogram. Wat zou worden gebruikt voor de datum van 5-11-2015 zou de hoge waarde 1/4/2016 zijn. Op basis van de grafiek is dit histogram duidelijk geen goede informatiebron voor de optimizer voor de datum van interesse. Het forceren van de gebruikswaarden in het histogram is niet betrouwbaar, dus hoe doe je dat? Mijn eerste poging was om herhaaldelijk de WITH SAMPLE . te gebruiken optie van UPDATE STATISTICS en vraag het histogram totdat de waarden die ik nodig had in het histogram stonden (een inspanning die hier wordt beschreven). Uiteindelijk bleek die aanpak onbetrouwbaar.
Dit histogram kan leiden tot een plan met dit soort gedrag. De onderschatting van rijen levert een Nested Loop-join en een index-zoekopdracht op. De uitlezingen zijn vervolgens hoger dan ze zouden moeten zijn vanwege deze plankeuze. Dit heeft ook effect op de duur van de verklaring.
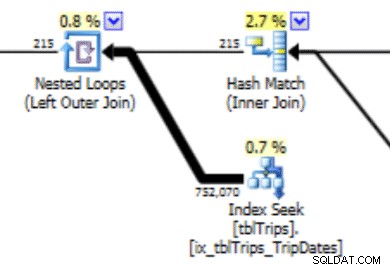
Wat veel beter zou werken, is om de gegevens precies zo te maken als u wilt, en hier leest u hoe u dat doet.
Er is een niet-ondersteunde optie van UPDATE STATISTICS :STATS_STREAM . Dit wordt gebruikt door Microsoft Customer Support om statistieken te exporteren en importeren, zodat ze een optimizer opnieuw kunnen maken zonder alle gegevens in de tabel te hebben. Die functie kunnen we gebruiken. Het idee is om een tabel te maken die de DDL nabootst van de statistiek die we willen aanpassen. De relevante gegevens worden aan de tabel toegevoegd. De statistieken worden geëxporteerd en geïmporteerd in de originele tabel.
In dit geval is het een tabel met 200 rijen niet-NULL-datums en 1 rij die de NULL-waarden bevat. Bovendien is er een index in die tabel die overeenkomt met de index met de slechte histogramwaarden.
De naam van de tabel is tblTripsScheduled . Het heeft een niet-geclusterde index op (id, TheTripDate) en een geclusterde index op TheTripDate . Er zijn een handvol andere kolommen, maar alleen de kolommen die bij de index betrokken zijn, zijn belangrijk.
Maak een tabel (tijdelijke tabel als je wilt) die de tabel en index nabootst. De tabel en index zien er als volgt uit:
CREATE TABLE #tbltripsscheduled_cix_tripsscheduled(
id INT NOT NULL
, tripdate DATETIME NOT NULL
, PRIMARY KEY NONCLUSTERED(id, tripdate)
);
CREATE CLUSTERED INDEX thetripdate ON #tbltripsscheduled_cix_tripsscheduled(tripdate);
Vervolgens moet de tabel worden gevuld met 200 rijen gegevens waarop de statistieken moeten worden gebaseerd. Voor mijn situatie is het de dag van tot en met de komende zestig dagen. De afgelopen 60 dagen en daarna wordt gevuld met een "willekeurige" selectie van elke 10 dagen. (De cnt waarde in de CTE is een foutopsporingswaarde. Het speelt geen rol in de uiteindelijke resultaten.) De aflopende volgorde voor de rn kolom zorgt ervoor dat de 60 dagen worden opgenomen, en dan zoveel mogelijk van het verleden.
DECLARE @date DATETIME = '20151104';
WITH tripdates
AS
(
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE NOT thetripdate BETWEEN @date AND @date
AND thetripdate < DATEADD(DAY, 60, @date) --only look 60 days out GROUP BY thetripdate
HAVING DATEDIFF(DAY, 0, thetripdate) % 10 = 0
UNION ALL
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE thetripdate BETWEEN @date AND DATEADD(DAY, 60, @date)
GROUP BY thetripdate
),
tripdate_top_200
AS
(
SELECT *
FROM
(
SELECT *, ROW_NUMBER() OVER(ORDER BY thetripdate DESC) rn
FROM tripdates
) td
WHERE rn <= 200
)
INSERT #tbltripsscheduled_cix_tripsscheduled (id, tripdate)
SELECT t.tripid, t.thetripdate
FROM tripdate_top_200 tp
INNER JOIN dbo.tbltripsscheduled t ON t.thetripdate = tp.thetripdate;
Onze tabel is nu gevuld met elke rij die waardevol is voor de gebruiker van vandaag en een selectie van historische rijen. Als de kolom TheTripdate nullable was, zou de insert ook het volgende bevatten:
UNION ALL SELECT id, thetripdate FROM dbo.tbltripsscheduled WHERE thetripdate IS NULL;
Vervolgens werken we de statistieken bij van de index van onze tijdelijke tabel.
UPDATE STATISTICS #tbltrips_IX_tbltrips_tripdates (tripdates) WITH FULLSCAN;
Exporteer die statistieken nu naar een tijdelijke tabel. Die tafel ziet er zo uit. Het komt overeen met de uitvoer van DBCC SHOW_STATISTICS WITH HISTOGRAM .
CREATE TABLE #stats_with_stream
(
stream VARBINARY(MAX) NOT NULL
, rows INT NOT NULL
, pages INT NOT NULL
);
DBCC SHOW_STATISTICS heeft een optie om de statistieken als een stream te exporteren. Het is die stroom die we willen. Die stream is ook dezelfde stream die de UPDATE STATISTICS stream-optie gebruikt. Om dat te doen:
INSERT INTO #stats_with_stream --SELECT * FROM #stats_with_stream
EXEC ('DBCC SHOW_STATISTICS (N''tempdb..#tbltripsscheduled_cix_tripsscheduled'', thetripdate)
WITH STATS_STREAM,NO_INFOMSGS'); De laatste stap is om de SQL te maken die de statistieken van onze doeltabel bijwerkt, en deze vervolgens uit te voeren.
DECLARE @sql NVARCHAR(MAX);
SET @sql = (SELECT 'UPDATE STATISTICS tbltripsscheduled(cix_tbltripsscheduled) WITH
STATS_STREAM = 0x' + CAST('' AS XML).value('xs:hexBinary(sql:column("stream"))',
'NVARCHAR(MAX)') FROM #stats_with_stream );
EXEC (@sql); Op dit moment hebben we het histogram vervangen door ons op maat gemaakte histogram. U kunt dit verifiëren door het histogram te controleren:
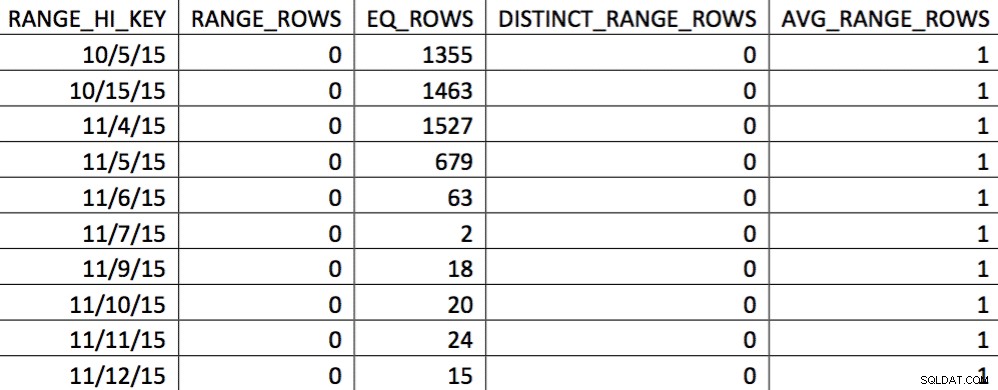
In deze selectie van de gegevens op 11/4 zijn alle dagen vanaf 11/4 vertegenwoordigd, en zijn de historische gegevens vertegenwoordigd en nauwkeurig. Als u het eerder getoonde deel van het queryplan opnieuw bekijkt, kunt u zien dat de optimizer een betere keuze heeft gemaakt op basis van de gecorrigeerde statistieken:
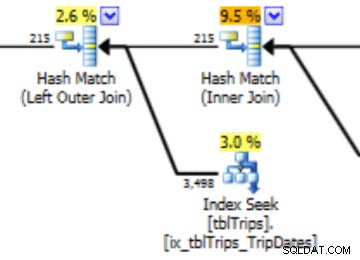
Er is een prestatievoordeel voor geïmporteerde statistieken. De kosten om de statistieken te berekenen staan in een "offline" tabel. De enige uitvaltijd voor de productietafel is de duur van het importeren van de stream.
Dit proces maakt gebruik van ongedocumenteerde functies en het lijkt erop dat het gevaarlijk kan zijn, maar onthoud dat er een gemakkelijke ongedaanmaking is:de update-statistiekenverklaring. Als er iets misgaat, kunnen de statistieken altijd worden bijgewerkt met behulp van standaard T-SQL.
Het plannen van deze code om regelmatig te worden uitgevoerd, kan de optimizer enorm helpen om betere plannen te maken, gezien een dataset die over het omslagpunt verandert, maar niet genoeg om een statistische update te activeren.
Toen ik de eerste versie van dit artikel af had, veranderde het aantal rijen in de tabel in de eerste grafiek van 217 in 717. Dat is een verandering van 300%. Dat is genoeg om het gedrag van de optimizer te veranderen, maar niet genoeg om een statistische update te activeren. Deze gegevenswijziging zou een slecht plan hebben achtergelaten. Met het hier beschreven proces is dit probleem opgelost.
Referenties:
- UPDATE STATISTIEKEN (boeken online)
- SQL 2008 Statistieken Whitepaper
- Zoeken naar kantelpunt