In dit artikel worden enkele minder bekende functies en beperkingen van query-optimalisatie besproken, en worden de redenen voor extreem slechte prestaties van hash-joins in een specifiek geval uitgelegd.
Voorbeeldgegevens
Het volgende script voor het maken van voorbeeldgegevens is gebaseerd op een bestaande tabel met getallen. Als je er nog geen hebt, kan het onderstaande script worden gebruikt om er een efficiënt te maken. De resulterende tabel zal een enkele integerkolom bevatten met getallen van één tot één miljoen:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); De voorbeeldgegevens zelf bestaan uit twee tabellen, T1 en T2. Beide hebben een sequentiële kolom voor de primaire sleutel met een geheel getal, genaamd pk, en een tweede kolom met nulwaarden met de naam c1. Tabel T1 heeft 600.000 rijen waarbij de even genummerde rijen dezelfde waarde hebben voor c1 als de pk-kolom, en de oneven genummerde rijen zijn null. Tabel c2 heeft 32.000 rijen waarbij kolom c1 in elke rij NULL is. Het volgende script maakt en vult deze tabellen:
CREATE TABLE dbo.T1
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T1
PRIMARY KEY CLUSTERED (pk)
);
CREATE TABLE dbo.T2
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T2
PRIMARY KEY CLUSTERED (pk)
);
INSERT dbo.T1 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
CASE
WHEN N.n % 2 = 1 THEN NULL
ELSE N.n
END
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 600000;
INSERT dbo.T2 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
NULL
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 32000;
UPDATE STATISTICS dbo.T1 WITH FULLSCAN;
UPDATE STATISTICS dbo.T2 WITH FULLSCAN; De eerste tien rijen met voorbeeldgegevens in elke tabel zien er als volgt uit:
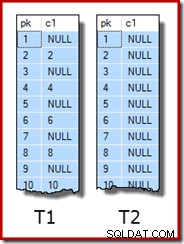
De twee tafels samenvoegen
Deze eerste test omvat het samenvoegen van de twee tabellen in kolom c1 (niet de pk-kolom) en het retourneren van de pk-waarde uit tabel T1 voor rijen die samenkomen:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1;
De query retourneert feitelijk geen rijen omdat kolom c1 NULL is in alle rijen van tabel T2, dus geen rijen kunnen overeenkomen met het gelijkheidsjoinpredikaat. Dit klinkt misschien vreemd om te doen, maar ik ben er zeker van dat het gebaseerd is op een echte productiequery (sterk vereenvoudigd voor een gemakkelijke discussie).
Merk op dat dit lege resultaat niet afhankelijk is van de instelling van ANSI_NULLS, omdat dat alleen bepaalt hoe vergelijkingen met een null-letterlijk of variabele worden afgehandeld. Voor kolomvergelijkingen wijst een gelijkheidspredikaat altijd nulls af.
Het uitvoeringsplan voor deze eenvoudige join-query heeft enkele interessante functies. We zullen eerst kijken naar het pre-uitvoeringsplan ('geschat') in SQL Sentry Plan Explorer:
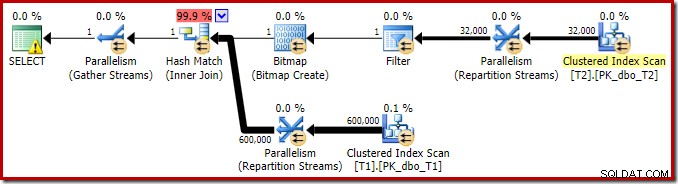
De waarschuwing op het SELECT-pictogram klaagt alleen over een ontbrekende index op tabel T1 voor kolom c1 (met pk als een opgenomen kolom). De indexsuggestie is hier niet relevant.
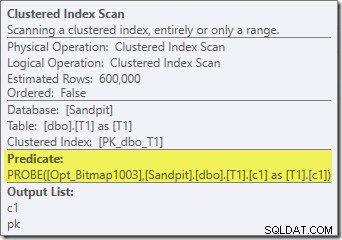
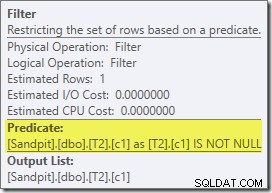
Het eerste echte item dat in dit plan van belang is, is het filter:
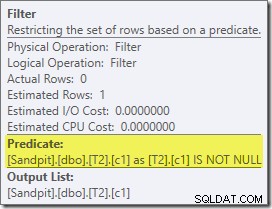
Dit IS NOT NULL predikaat verschijnt niet in de bronquery, hoewel het impliciet is in het join-predikaat zoals eerder vermeld. Het is interessant dat het is uitgebroken als een expliciete extra operator en vóór de samenvoegbewerking is geplaatst. Merk op dat zelfs zonder het filter de query nog steeds correcte resultaten zou opleveren - de join zelf zou nog steeds de nulls afwijzen.
Het Filter is ook om andere redenen nieuwsgierig. Het heeft een geschatte kostprijs van precies nul (ook al wordt verwacht dat het op 32.000 rijen zal werken), en het is niet als resterend predikaat in de Clustered Index Scan geduwd. De optimizer is normaal gesproken vrij enthousiast om dit te doen.
Beide dingen worden verklaard door het feit dat dit filter is geïntroduceerd in een herschrijving na optimalisatie. Nadat de query-optimizer de op kosten gebaseerde verwerking heeft voltooid, is er een relatief klein aantal herschrijvingen van vaste plannen die worden overwogen. Een van deze is verantwoordelijk voor de introductie van het filter.
We kunnen de uitvoer zien van op kosten gebaseerde planselectie (vóór het herschrijven) met behulp van ongedocumenteerde traceervlaggen 8607 en de bekende 3604 om tekstuele uitvoer naar de console te sturen (tabblad berichten in SSMS):
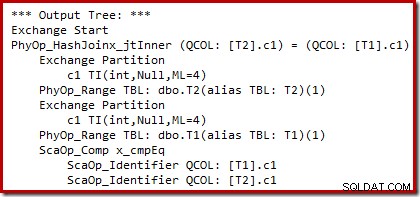
De uitvoerstructuur toont een hash-join, twee scans en enkele parallellisme (uitwisseling) operators. Er is geen nulafwijzend filter in de c1-kolom van tabel T2.
De specifieke herschrijving na optimalisatie kijkt uitsluitend naar de build-invoer van een hash-join. Afhankelijk van zijn beoordeling van de situatie, kan het een expliciet filter toevoegen om rijen te weigeren die null zijn in de join-sleutel. Het effect van het filter op het geschatte aantal rijen wordt ook in het uitvoeringsplan geschreven, maar omdat de op kosten gebaseerde optimalisatie al is voltooid, worden er geen kosten voor het filter berekend. Voor het geval het niet duidelijk is, zijn computerkosten een verspilling van moeite als alle op kosten gebaseerde beslissingen al zijn genomen.
Het filter blijft direct op de build-invoer in plaats van naar beneden te worden geduwd in de geclusterde indexscan omdat de belangrijkste optimalisatieactiviteit is voltooid. De herschrijvingen na de optimalisatie zijn in feite last-minute aanpassingen aan een voltooid uitvoeringsplan.
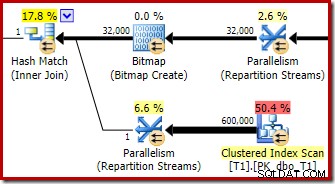
Een tweede, en vrij aparte, herschrijving na optimalisatie is verantwoordelijk voor de Bitmap-operator in het definitieve plan (je hebt misschien gemerkt dat het ook ontbrak in de 8607-uitvoer):
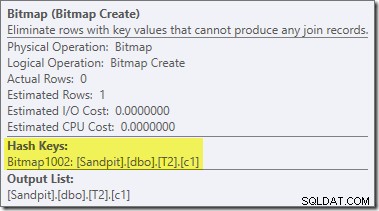
Deze operator heeft ook geen geschatte kosten voor zowel I/O als CPU. Het andere dat het identificeert als een operator die is geïntroduceerd door een late tweak (in plaats van tijdens op kosten gebaseerde optimalisatie) is dat de naam Bitmap is gevolgd door een nummer. Er zijn andere soorten bitmaps geïntroduceerd tijdens op kosten gebaseerde optimalisatie, zoals we later zullen zien.
Voor nu is het belangrijkste van deze bitmap dat het c1-waarden registreert die te zien zijn tijdens de bouwfase van de hash-join. De voltooide bitmap wordt naar de probe-kant van de join geduwd wanneer de hash overgaat van de build-fase naar de probe-fase. De bitmap wordt gebruikt om vroege semi-join-reductie uit te voeren, waarbij rijen aan de sondezijde worden geëlimineerd die onmogelijk kunnen worden samengevoegd. als je hier meer informatie over nodig hebt, raadpleeg dan mijn vorige artikel over dit onderwerp.
Het tweede effect van de bitmap is te zien op de geclusterde indexscan aan de sondezijde:
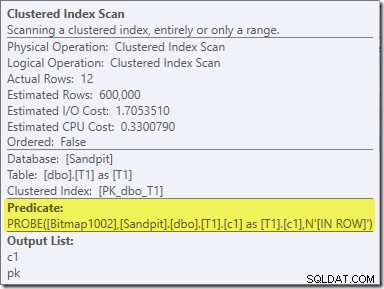
De bovenstaande schermafbeelding toont de voltooide bitmap die wordt gecontroleerd als onderdeel van de Clustered Index Scan op tabel T1. Aangezien de bronkolom een geheel getal is (een bigint zou ook werken), wordt de bitmapcontrole helemaal in de opslagengine geduwd (zoals aangegeven door de 'INROW'-kwalificatie) in plaats van te worden gecontroleerd door de queryprocessor. Meer in het algemeen kan de bitmap worden toegepast op elke operator aan de sondezijde, vanaf de uitwisseling. Hoe ver de queryprocessor de bitmap kan duwen, hangt af van het type kolom en de versie van SQL Server.
Om de analyse van de belangrijkste kenmerken van dit uitvoeringsplan te voltooien, moeten we kijken naar het ('werkelijke') plan na de uitvoering:
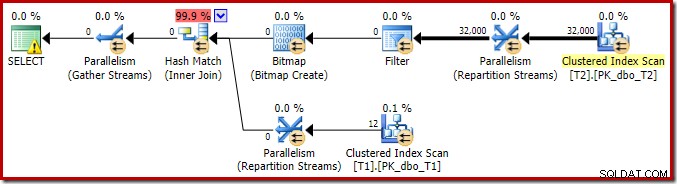
Het eerste dat opvalt, is de verdeling van rijen over threads tussen de T2-scan en de Repartition Streams-uitwisseling er direct boven. Tijdens een testrun zag ik de volgende distributie op een systeem met vier logische processors:
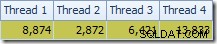
De verdeling is niet bijzonder gelijkmatig, zoals vaak het geval is voor een parallelle scan op een relatief klein aantal rijen, maar in ieder geval hebben alle threads wat werk gekregen. De threaddistributie tussen dezelfde Repartition Streams-uitwisseling en het filter is heel anders:
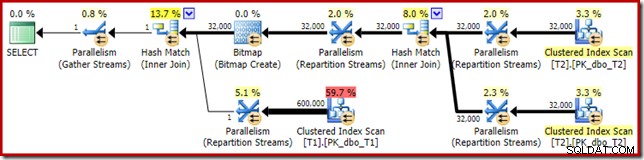
Hieruit blijkt dat alle 32.000 rijen uit tabel T2 door een enkele thread zijn verwerkt. Om te zien waarom, moeten we naar de ruileigenschappen kijken:

Deze uitwisseling, zoals die aan de probe-kant van de hash-join, moet ervoor zorgen dat rijen met dezelfde join-sleutelwaarden op dezelfde instantie van de hash-join terechtkomen. Bij DOP 4 zijn er vier hash-joins, elk met een eigen hash-tabel. Voor correcte resultaten moeten rijen aan de buildzijde en rijen aan de probezijde met dezelfde join-sleutels bij dezelfde hash-join aankomen; anders kunnen we een rij aan de probe-zijde vergelijken met de verkeerde hashtabel.
In een parallel plan in rijmodus bereikt SQL Server dit door beide ingangen opnieuw te partitioneren met dezelfde hashfunctie op de join-kolommen. In het huidige geval bevindt de join zich in kolom c1, dus de invoer wordt verdeeld over threads door een hash-functie (partitioneringstype:hash) toe te passen op de join-sleutelkolom (c1). Het probleem hier is dat kolom c1 slechts één enkele waarde bevat - null - in tabel T2, dus alle 32.000 rijen krijgen dezelfde hash-waarde, zodat ze allemaal op dezelfde thread terechtkomen.
Het goede nieuws is dat dit allemaal niet echt van belang is voor deze zoekopdracht. Het herschrijffilter na optimalisatie elimineert alle rijen voordat er veel werk is verzet. Op mijn laptop wordt de bovenstaande query uitgevoerd (geen resultaten, zoals verwacht) in ongeveer 70 ms .
Deelnemen aan drie tafels
Voor de tweede test voegen we een extra join toe van tabel T2 aan zichzelf op zijn primaire sleutel:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 -- New! ON T3.pk = T2.pk;
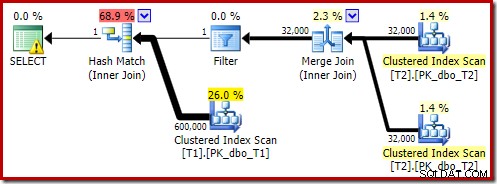
Dit verandert niets aan de logische resultaten van de query, maar wel aan het uitvoeringsplan:
Zoals verwacht heeft de self-join van tabel T2 op zijn primaire sleutel geen effect op het aantal rijen dat in aanmerking komt uit die tabel:
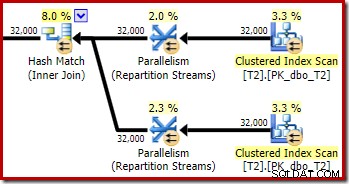
De verdeling van rijen over threads is ook goed in deze plansectie. Voor de scans is het vergelijkbaar met voorheen omdat de parallelle scan rijen op aanvraag distribueert naar threads. De uitwisselingen herpartitionering op basis van een hash van de join-sleutel, die deze keer de pk-kolom is. Gezien het bereik van verschillende pk-waarden, is de resulterende threaddistributie ook erg gelijkmatig:
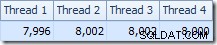
Wat betreft het interessantere gedeelte van het geschatte plan, zijn er enkele verschillen met de test met twee tabellen:

Nogmaals, de build-side exchange leidt uiteindelijk alle rijen naar dezelfde thread omdat c1 de join-sleutel is, en dus de partitioneringskolom voor de Repartition Streams-uitwisselingen (onthoud dat c1 null is voor alle rijen in tabel T2).
Er zijn nog twee andere belangrijke verschillen in dit deel van het plan in vergelijking met de vorige test. Ten eerste is er geen filter om null-c1-rijen van de build-kant van de hash-join te verwijderen. De verklaring daarvoor houdt verband met het tweede verschil:de bitmap is veranderd, hoewel dit niet duidelijk is uit de bovenstaande afbeelding:
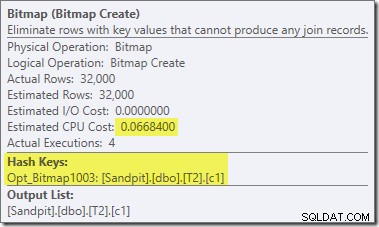
Dit is een Opt_Bitmap, geen Bitmap. Het verschil is dat deze bitmap is geïntroduceerd tijdens op kosten gebaseerde optimalisatie, niet door een last-minute herschrijving. Het mechanisme dat geoptimaliseerde bitmaps in overweging neemt, wordt geassocieerd met het verwerken van star-join-query's. De star-join-logica vereist ten minste drie samengevoegde tabellen, dus dit verklaart waarom een geoptimaliseerde bitmap is niet meegenomen in het voorbeeld van de samenvoeging van twee tabellen.
Deze geoptimaliseerde bitmap heeft geschatte CPU-kosten die niet nul zijn en heeft rechtstreeks invloed op het algemene plan dat door de optimizer is gekozen. Het effect op de schatting van de kardinaliteit aan de sondezijde is te zien bij de operator Repartition Streams:
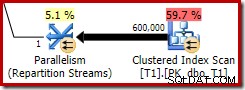
Merk op dat het kardinaliteitseffect wordt gezien bij de uitwisseling, ook al wordt de bitmap uiteindelijk helemaal naar beneden in de opslagengine ('INROW') geduwd, net zoals we in de eerste test zagen (maar let nu op de Opt_Bitmap-referentie):
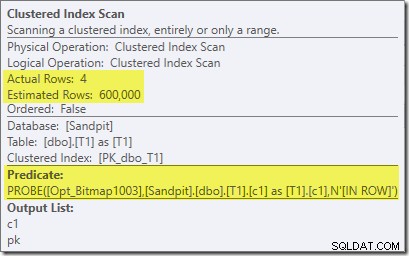
Het plan voor de uitvoering ('werkelijke') is als volgt:
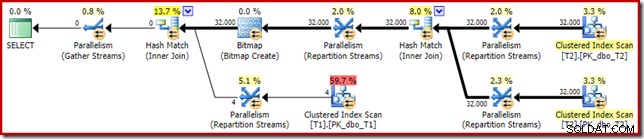
De voorspelde effectiviteit van de geoptimaliseerde bitmap betekent dat de afzonderlijke herschrijving na optimalisatie voor het nulfilter niet wordt toegepast. Persoonlijk vind ik dit jammer, omdat het vroegtijdig elimineren van de nulls met een filter de noodzaak zou tenietdoen om de bitmap te bouwen, de hashtabellen te vullen en de bitmap-verbeterde scan van tabel T1 uit te voeren. Desalniettemin beslist de optimizer anders en er is in dit geval gewoon geen discussie over.
Ondanks de extra self-join van tabel T2 en het extra werk dat gepaard gaat met het ontbrekende filter, levert dit uitvoeringsplan toch snel het verwachte resultaat (geen rijen) op. Een typische uitvoering op mijn laptop duurt ongeveer 200ms .
Het gegevenstype wijzigen
Voor deze derde test zullen we het gegevenstype van kolom c1 in beide tabellen wijzigen van geheel getal naar decimaal. Er is niets bijzonders aan deze keuze; hetzelfde effect is te zien bij elk numeriek type dat geen geheel getal of bigint is.
ALTER TABLE dbo.T1 ALTER COLUMN c1 decimal(9,0) NULL; ALTER TABLE dbo.T2 ALTER COLUMN c1 decimal(9,0) NULL; ALTER INDEX PK_dbo_T1 ON dbo.T1 REBUILD WITH (MAXDOP = 1); ALTER INDEX PK_dbo_T2 ON dbo.T2 REBUILD WITH (MAXDOP = 1); UPDATE STATISTICS dbo.T1 WITH FULLSCAN; UPDATE STATISTICS dbo.T2 WITH FULLSCAN;
De join-query met drie joins opnieuw gebruiken:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk;
Het geschatte uitvoeringsplan ziet er heel bekend uit:
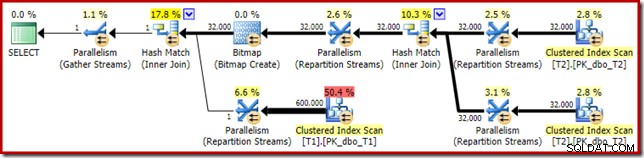
Afgezien van het feit dat de geoptimaliseerde bitmap niet langer 'INROW' kan worden toegepast door de storage engine vanwege de verandering van datatype, is het uitvoeringsplan in wezen identiek. De onderstaande opname toont de verandering in scaneigenschappen:
Helaas worden de prestaties nogal dramatisch beïnvloed. Deze query wordt niet uitgevoerd in 70 ms of 200 ms, maar in ongeveer 20 minuten . In de test die het volgende post-uitvoeringsplan opleverde, was de runtime eigenlijk 22 minuten en 29 seconden:

Het meest voor de hand liggende verschil is dat de geclusterde indexscan op tabel T1 300.000 rijen retourneert, zelfs nadat het geoptimaliseerde bitmapfilter is toegepast. Dit is logisch, aangezien de bitmap is gebouwd op rijen die alleen nulls bevatten in de c1-kolom. De bitmap verwijdert niet-null-rijen uit de T1-scan, waardoor alleen de 300.000 rijen met null-waarden voor c1 overblijven. Onthoud dat de helft van de rijen in T1 null is.
Toch lijkt het vreemd dat het samenvoegen van 32.000 rijen met 300.000 rijen meer dan 20 minuten zou duren. Voor het geval je het je afvroeg, één CPU-kern was vastgepend op 100% voor de hele uitvoering. De verklaring voor deze slechte prestatie en het extreme gebruik van hulpbronnen bouwt voort op enkele ideeën die we eerder hebben onderzocht:
We weten bijvoorbeeld al dat ondanks de parallelle uitvoeringspictogrammen alle rijen van T2 op dezelfde thread terechtkomen. Ter herinnering:de parallelle hash-join in rijmodus moet opnieuw worden gepartitioneerd op de join-kolommen (c1). Alle rijen uit T2 hebben dezelfde waarde – null – in kolom c1, dus alle rijen komen op dezelfde thread terecht. Evenzo hebben alle rijen van T1 die het bitmapfilter passeren, ook null in kolom c1, dus ze worden ook opnieuw gepartitioneerd naar dezelfde thread. Dit verklaart waarom een enkele kern al het werk doet.
Het lijkt misschien nog steeds onredelijk dat hash het samenvoegen van 32.000 rijen met 300.000 rijen 20 minuten zou moeten duren, vooral omdat de kolommen voor het samenvoegen aan beide zijden nul zijn en hoe dan ook niet worden samengevoegd. Om dit te begrijpen, moeten we nadenken over hoe deze hash-join werkt.
De build-invoer (de 32.000 rijen) maakt een hash-tabel met behulp van de join-kolom, c1. Aangezien elke rij aan de buildzijde dezelfde waarde (null) bevat voor join-kolom c1, betekent dit dat alle 32.000 rijen in dezelfde hash-bucket terechtkomen. Wanneer de hash-join overschakelt naar zoeken naar overeenkomsten, wordt elke rij aan de sondezijde met een null-c1-kolom ook hashes naar dezelfde bucket. De hash-join moet dan alle 32.000 items in die bucket controleren op een overeenkomst.
Het controleren van de 300.000 sonderijen resulteert in 32.000 vergelijkingen die 300.000 keer worden gemaakt. Dit is het slechtste geval voor een hash-join:alle build-rijen aan de zijkant hashen naar dezelfde bucket, wat resulteert in wat in wezen een Cartesiaans product is. Dit verklaart de lange uitvoeringstijd en constant 100% processorgebruik, aangezien de hash de lange hash-bucketketen volgt.
Deze slechte prestatie helpt verklaren waarom het herschrijven na optimalisatie om nulls op de build-invoer naar een hash-join te elimineren bestaat. Het is jammer dat het filter in dit geval niet is toegepast.
Oplossingen
Het optimalisatieprogramma kiest deze planvorm omdat het onjuist schat dat de geoptimaliseerde bitmap alle rijen uit tabel T1 zal filteren. Hoewel deze schatting bij de Repartition Streams wordt getoond in plaats van bij de Clustered Index Scan, is dit toch de basis van de beslissing. Ter herinnering, hier is nogmaals het relevante gedeelte van het pre-uitvoeringsplan:
Als dit een juiste schatting zou zijn, zou het geen tijd kosten om de hash-join te verwerken. Het is jammer dat de schatting van de selectiviteit voor de geoptimaliseerde bitmap zo verkeerd is als het gegevenstype geen eenvoudig geheel getal of bigint is. Het lijkt erop dat een bitmap die is gebouwd op een integer- of bigint-sleutel ook in staat is om null-rijen uit te filteren die niet kunnen worden samengevoegd. Als dit inderdaad het geval is, is dit een belangrijke reden om de voorkeur te geven aan integer- of bigint-joinkolommen.
De tijdelijke oplossingen die volgen, zijn grotendeels gebaseerd op het idee om de problematische geoptimaliseerde bitmaps te elimineren.
Seriële uitvoering
Een manier om te voorkomen dat geoptimaliseerde bitmaps worden overwogen, is door een niet-parallel plan te vereisen. Rijmodus Bitmap-operators (al dan niet geoptimaliseerd) worden alleen gezien in parallelle plannen:
SELECT T1.pk
FROM
(
dbo.T2 AS T2
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
)
JOIN dbo.T1 AS T1
ON T1.c1 = T2.c1
OPTION (MAXDOP 1, FORCE ORDER); Die query wordt uitgedrukt met een iets andere syntaxis met een FORCE ORDER-hint om een planvorm te genereren die gemakkelijker vergelijkbaar is met de vorige parallelle plannen. De essentiële functie is de MAXDOP 1-hint.
Dat geschatte plan laat zien dat het herschrijffilter na optimalisatie wordt hersteld:
De post-uitvoeringsversie van het plan laat zien dat het alle rijen uit de build-invoer filtert, wat betekent dat de scan aan de zijkant van de sonde helemaal kan worden overgeslagen:
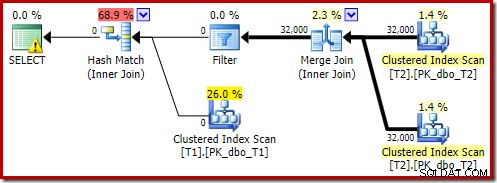
Zoals je zou verwachten, wordt deze versie van de query erg snel uitgevoerd - gemiddeld ongeveer 20 ms voor mij. We kunnen een soortgelijk effect bereiken zonder de FORCE ORDER hint en het herschrijven van de query:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (MAXDOP 1);
De optimizer kiest in dit geval een andere planvorm, waarbij het filter direct boven de scan van T2 wordt geplaatst:
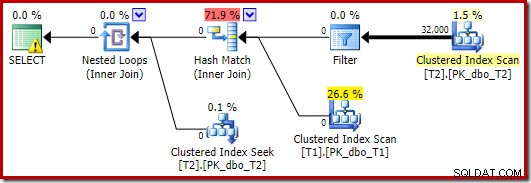
Dit wordt nog sneller uitgevoerd - in ongeveer 10 ms - zoals je zou verwachten. Dit zou natuurlijk geen goede keuze zijn als het aantal aanwezige (en koppelbare) rijen veel groter zou zijn.
Geoptimaliseerde bitmaps uitschakelen
Er is geen vraaghint om geoptimaliseerde bitmaps uit te schakelen, maar we kunnen hetzelfde effect bereiken door een aantal ongedocumenteerde traceervlaggen te gebruiken. Zoals altijd is dit alleen voor rentewaarde; je zou deze nooit in een echt systeem of applicatie willen gebruiken:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYTRACEON 7497, QUERYTRACEON 7498);
Het resulterende uitvoeringsplan is:
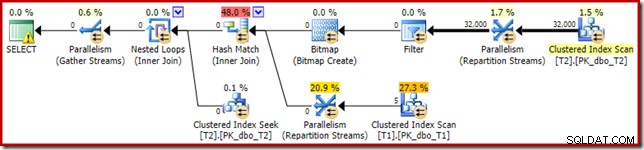
De Bitmap daar is een herschrijfbitmap na optimalisatie, geen geoptimaliseerde bitmap:
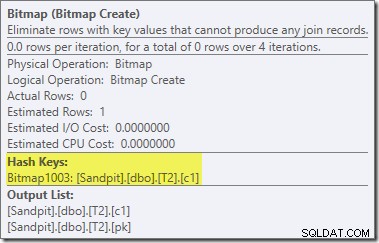
Let op de nulkostenramingen en de bitmapnaam (in plaats van Opt_Bitmap). zonder een geoptimaliseerde bitmap om de kostenramingen scheef te trekken, wordt het herschrijven na optimalisatie met een null-rejecting Filter geactiveerd. Dit uitvoeringsplan duurt ongeveer 70ms .
Hetzelfde uitvoeringsplan (met filter en niet-geoptimaliseerde bitmap) kan ook worden geproduceerd door de optimalisatieregel uit te schakelen die verantwoordelijk is voor het genereren van star-join bitmapplannen (wederom, strikt ongedocumenteerd en niet voor gebruik in de echte wereld):
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYRULEOFF StarJoinToHashJoinsWithBitmap);
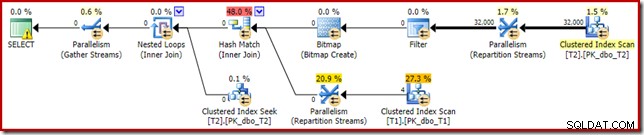
Inclusief een expliciet filter
Dit is de eenvoudigste optie, maar je zou er alleen aan denken om het te doen als je je bewust bent van de problemen die tot nu toe zijn besproken. Nu we weten dat we nulls uit T2.c1 moeten verwijderen, kunnen we dit direct aan de query toevoegen:
SELECT T1.pk
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.c1 = T1.c1
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
WHERE
T2.c1 IS NOT NULL; -- New! Het resulterende geschatte uitvoeringsplan is misschien niet helemaal wat u zou verwachten:
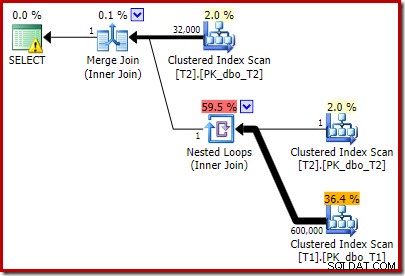
Het extra predikaat dat we hebben toegevoegd, is in de middelste geclusterde indexscan van T2 geplaatst:
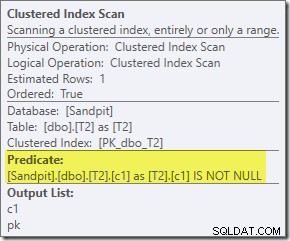
Het post-uitvoeringsplan is:
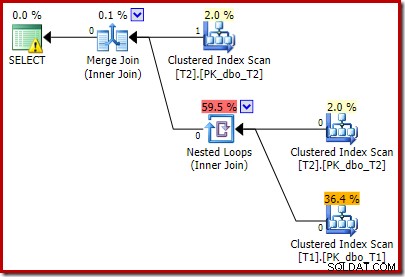
Merk op dat de Merge Join wordt afgesloten na het lezen van één rij van de bovenste invoer en vervolgens geen rij kan vinden op de onderste invoer, vanwege het effect van het predikaat dat we hebben toegevoegd. De Clustered Index Scan van tabel T1 wordt helemaal nooit uitgevoerd, omdat de Nested Loops-join nooit een rij krijgt op zijn stuurinvoer. Dit laatste vraagformulier wordt in één of twee milliseconden uitgevoerd.
Laatste gedachten
Dit artikel heeft een behoorlijke hoeveelheid grond behandeld om een aantal minder bekende query-optimalisatiegedragingen te onderzoeken en de redenen voor extreem slechte hash-joinprestaties in een specifiek geval uit te leggen.
Het is misschien verleidelijk om je af te vragen waarom de optimizer niet routinematig nulafwijzende filters toevoegt voorafgaand aan gelijkheidsjoins. Men kan alleen maar veronderstellen dat dit in voldoende veel voorkomende gevallen niet voordelig zou zijn. De meeste joins zullen naar verwachting niet veel null =null-afwijzingen tegenkomen, en het routinematig toevoegen van predikaten kan snel contraproductief worden, vooral als er veel join-kolommen aanwezig zijn. Voor de meeste joins is het afwijzen van nulls binnen de join-operator waarschijnlijk een betere optie (vanuit een kostenmodelperspectief) dan het introduceren van een expliciet filter.
Het lijkt erop dat er een poging wordt gedaan om te voorkomen dat de allerergste gevallen zich manifesteren door de herschrijving na de optimalisatie die is ontworpen om null-joinrijen te weigeren voordat ze de build-invoer van een hash-join bereiken. Het lijkt erop dat er een ongelukkige interactie bestaat tussen het effect van geoptimaliseerde bitmapfilters en de toepassing van deze herschrijving. Het is ook jammer dat wanneer dit prestatieprobleem zich voordoet, het erg moeilijk is om een diagnose te stellen vanuit het uitvoeringsplan alleen.
Voor nu lijkt de beste optie zich bewust te zijn van dit potentiële prestatieprobleem met hash-joins op nullable-kolommen, en om expliciete null-afwijzende predikaten toe te voegen (met een opmerking!) om ervoor te zorgen dat een efficiënt uitvoeringsplan wordt geproduceerd, indien nodig. Het gebruik van een MAXDOP 1-hint kan ook een alternatief plan onthullen met het verklikkerfilter aanwezig.
Als algemene regel geldt dat query's die samenkomen op kolommen van het type integer en op zoek gaan naar bestaande gegevens, eerder beter passen bij het optimalisatiemodel en de uitvoeringsengine dan bij de alternatieven.
Erkenningen
Ik wil SQL_Sasquatch (@sqL_handLe) bedanken voor zijn toestemming om op zijn originele artikel te reageren met een technische analyse. De voorbeeldgegevens die hier worden gebruikt, zijn sterk gebaseerd op dat artikel.
Ik wil ook Rob Farley (blog | twitter) bedanken voor onze technische discussies door de jaren heen, en vooral één in januari 2015 waar we de implicaties bespraken van extra null-afwijzende predikaten voor equi-joins. Rob heeft verschillende keren over gerelateerde onderwerpen geschreven, ook in Inverse Predikaten – kijk beide kanten op voordat je oversteekt.