Achtergrond
Een van de eerste dingen waar ik naar kijk als ik een prestatieprobleem oplos, zijn wachtstatistieken via de sys.dm_os_wait_stats DMV. Om te zien waar SQL Server op wacht, gebruik ik de query uit Glenn Berry's huidige set SQL Server Diagnostic Queries. Afhankelijk van de output ga ik me verdiepen in specifieke gebieden binnen SQL Server.
Als ik bijvoorbeeld hoge CXPACKET-wachttijden zie, controleer ik het aantal kernen op de server, het aantal NUMA-knooppunten en de waarden voor maximale mate van parallellisme en kostendrempel voor parallellisme. Dit is achtergrondinformatie die ik gebruik om de configuratie te begrijpen. Voordat ik zelfs maar overweeg om wijzigingen aan te brengen, verzamel ik meer kwantitatieve gegevens, aangezien een systeem met CXPACKET-wachttijden niet noodzakelijk een onjuiste instelling heeft voor maximale mate van parallellisme.
Evenzo heeft een systeem met hoge wachttijden voor I/O-gerelateerde wachttypen zoals PAGEIOLATCH_XX, WRITELOG en IO_COMPLETION niet noodzakelijk een inferieur opslagsubsysteem. Als ik I/O-gerelateerde wait-types zie als de top waits, wil ik meteen meer weten over de onderliggende storage. Is het direct-attached storage of een SAN? Wat is het RAID-niveau, hoeveel schijven zijn er in de array en wat is de snelheid van de schijven? Ik wil ook weten of andere bestanden of databases de opslag delen. En hoewel het belangrijk is om de configuratie te begrijpen, is een logische volgende stap om naar virtuele bestandsstatistieken te kijken via de sys.dm_io_virtual_file_stats DMV.
Deze DMV, geïntroduceerd in SQL Server 2005, is een vervanging voor de functie fn_virtualfilestats die degenen onder u die op SQL Server 2000 en eerder draaiden, waarschijnlijk kennen en waarderen. De DMV bevat cumulatieve I/O-informatie voor elk databasebestand, maar de gegevens worden gereset bij het opnieuw opstarten van een instantie, wanneer een database wordt gesloten, offline wordt gehaald, losgekoppeld en opnieuw wordt gekoppeld, enz. Het is van cruciaal belang om te begrijpen dat de gegevens van virtuele bestandsstatistieken niet representatief zijn voor de huidige prestaties - het is een momentopname die een aggregatie is van I / O-gegevens sinds de laatste opruiming door een van de bovengenoemde gebeurtenissen. Ook al zijn de gegevens niet van een bepaald tijdstip, ze kunnen toch nuttig zijn. Als de hoogste wachttijden voor een instantie I/O-gerelateerd zijn, maar de gemiddelde wachttijd minder dan 10 ms is, is opslag waarschijnlijk geen probleem - maar het correleren van de uitvoer met wat u ziet in sys.dm_io_virtual_stats is nog steeds de moeite waard om te bevestigen dat laag is latenties. Verder, zelfs als je hoge latenties ziet in sys.dm_io_virtual_stats, heb je nog steeds niet bewezen dat opslag een probleem is.
De installatie
Om naar virtuele bestandsstatistieken te kijken, heb ik twee exemplaren van de AdventureWorks2012-database gemaakt, die u kunt downloaden van Codeplex. Voor het eerste exemplaar, hierna bekend als EX_AdventureWorks2012, heb ik het script van Jonathan Kehayias uitgevoerd om de tabellen Sales.SalesOrderHeader en Sales.SalesOrderDetail uit te breiden tot respectievelijk 1,2 miljoen en 4,9 miljoen rijen. Voor de tweede database, BIG_AdventureWorks2012, heb ik het script uit mijn vorige partitioneringsbericht gebruikt om een kopie te maken van de tabel Sales.SalesOrderHeader met 123 miljoen rijen. Beide databases zijn opgeslagen op een externe USB-drive (Seagate Slim 500GB), met tempdb op mijn lokale schijf (SSD).
Voordat ik ging testen, heb ik vier aangepaste opgeslagen procedures in elke database gemaakt (Create_Custom_SPs.zip), die als mijn "normale" werklast zouden dienen. Mijn testproces was als volgt voor elke database:
- Start de instantie opnieuw.
- Statistieken van virtuele bestanden vastleggen.
- Voer de "normale" werkbelasting twee minuten uit (procedures worden herhaaldelijk aangeroepen via een PowerShell-script).
- Statistieken van virtuele bestanden vastleggen.
- Herstel alle indexen voor de juiste SalesOrder-tabel(len).
- Statistieken van virtuele bestanden vastleggen.
De gegevens
Om virtuele bestandsstatistieken vast te leggen, heb ik een tabel gemaakt met historische informatie en vervolgens een variatie op de zoekopdracht van Jimmy May uit zijn DMV All-Stars-script gebruikt voor de momentopname:
USE [msdb];
GO
CREATE TABLE [dbo].[SQLskills_FileLatency]
(
[RowID] [INT] IDENTITY(1,1) NOT NULL,
[CaptureID] [INT] NOT NULL,
[CaptureDate] [DATETIME2](7) NULL,
[ReadLatency] [BIGINT] NULL,
[WriteLatency] [BIGINT] NULL,
[Latency] [BIGINT] NULL,
[AvgBPerRead] [BIGINT] NULL,
[AvgBPerWrite] [BIGINT] NULL,
[AvgBPerTransfer] [BIGINT] NULL,
[Drive] [NVARCHAR](2) NULL,
[DB] [NVARCHAR](128) NULL,
[database_id] [SMALLINT] NOT NULL,
[file_id] [SMALLINT] NOT NULL,
[sample_ms] [INT] NOT NULL,
[num_of_reads] [BIGINT] NOT NULL,
[num_of_bytes_read] [BIGINT] NOT NULL,
[io_stall_read_ms] [BIGINT] NOT NULL,
[num_of_writes] [BIGINT] NOT NULL,
[num_of_bytes_written] [BIGINT] NOT NULL,
[io_stall_write_ms] [BIGINT] NOT NULL,
[io_stall] [BIGINT] NOT NULL,
[size_on_disk_MB] [NUMERIC](25, 6) NULL,
[file_handle] [VARBINARY](8) NOT NULL,
[physical_name] [NVARCHAR](260) NOT NULL
) ON [PRIMARY];
GO
CREATE CLUSTERED INDEX CI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureDate], [RowID]);
CREATE NONCLUSTERED INDEX NCI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureID]);
DECLARE @CaptureID INT;
SELECT @CaptureID = MAX(CaptureID) FROM [msdb].[dbo].[SQLskills_FileLatency];
PRINT (@CaptureID);
IF @CaptureID IS NULL
BEGIN
SET @CaptureID = 1;
END
ELSE
BEGIN
SET @CaptureID = @CaptureID + 1;
END
INSERT INTO [msdb].[dbo].[SQLskills_FileLatency]
(
[CaptureID],
[CaptureDate],
[ReadLatency],
[WriteLatency],
[Latency],
[AvgBPerRead],
[AvgBPerWrite],
[AvgBPerTransfer],
[Drive],
[DB],
[database_id],
[file_id],
[sample_ms],
[num_of_reads],
[num_of_bytes_read],
[io_stall_read_ms],
[num_of_writes],
[num_of_bytes_written],
[io_stall_write_ms],
[io_stall],
[size_on_disk_MB],
[file_handle],
[physical_name]
)
SELECT
--virtual file latency
@CaptureID,
GETDATE(),
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([io_stall_read_ms]/[num_of_reads])
END [ReadLatency],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([io_stall_write_ms]/[num_of_writes])
END [WriteLatency],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE ([io_stall]/([num_of_reads] + [num_of_writes]))
END [Latency],
--avg bytes per IOP
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([num_of_bytes_read]/[num_of_reads])
END [AvgBPerRead],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([num_of_bytes_written]/[num_of_writes])
END [AvgBPerWrite],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE (([num_of_bytes_read] + [num_of_bytes_written])/([num_of_reads] + [num_of_writes]))
END [AvgBPerTransfer],
LEFT([mf].[physical_name],2) [Drive],
DB_NAME([vfs].[database_id]) [DB],
[vfs].[database_id],
[vfs].[file_id],
[vfs].[sample_ms],
[vfs].[num_of_reads],
[vfs].[num_of_bytes_read],
[vfs].[io_stall_read_ms],
[vfs].[num_of_writes],
[vfs].[num_of_bytes_written],
[vfs].[io_stall_write_ms],
[vfs].[io_stall],
[vfs].[size_on_disk_bytes]/1024/1024. [size_on_disk_MB],
[vfs].[file_handle],
[mf].[physical_name]
FROM [sys].[dm_io_virtual_file_stats](NULL,NULL) AS vfs
JOIN [sys].[master_files] [mf]
ON [vfs].[database_id] = [mf].[database_id]
AND [vfs].[file_id] = [mf].[file_id]
ORDER BY [Latency] DESC; Ik herstartte de instantie en legde vervolgens onmiddellijk de bestandsstatistieken vast. Toen ik de uitvoer filterde om alleen de EX_AdventureWorks2012- en tempdb-databasebestanden te bekijken, werden alleen tempdb-gegevens vastgelegd omdat er geen gegevens waren opgevraagd uit de EX_AdventureWorks2012-database:

Uitvoer van de eerste opname van sys.dm_os_virtual_file_stats
Ik heb toen de "normale" werkbelasting twee minuten uitgevoerd (het aantal uitvoeringen van elke opgeslagen procedure varieerde enigszins), en nadat het de vastgelegde bestandsstatistieken opnieuw had voltooid:

Uitvoer van sys.dm_os_virtual_file_stats na normale werkbelasting
We zien een latentie van 57 ms voor het EX_AdventureWorks2012-gegevensbestand. Niet ideaal, maar na verloop van tijd met mijn normale werklast zou dit waarschijnlijk gelijk worden. Er is een minimale latentie voor tempdb, wat wordt verwacht omdat de werklast die ik heb uitgevoerd niet veel tempdb-activiteit genereert. Vervolgens heb ik alle indexen opnieuw opgebouwd voor de tabellen Sales.SalesOrderHeaderEnlarged en Sales.SalesOrderDetailEnlarged:
USE [EX_AdventureWorks2012]; GO ALTER INDEX ALL ON Sales.SalesOrderHeaderEnlarged REBUILD; ALTER INDEX ALL ON Sales.SalesOrderDetailEnlarged REBUILD;
Het opnieuw opbouwen duurde minder dan een minuut, en let op de piek in leeslatentie voor het EX_AdventureWorks2012-gegevensbestand en de pieken in de schrijflatentie voor de EX_AdventureWorks2012-gegevens en logbestanden:

Uitvoer van sys.dm_os_virtual_file_stats na opnieuw opbouwen index
Volgens die momentopname van bestandsstatistieken is de latentie verschrikkelijk; meer dan 600 ms voor schrijven! Als ik deze waarde voor een productiesysteem zou zien, zou het gemakkelijk zijn om onmiddellijk problemen met opslag te vermoeden. Het is echter ook de moeite waard om op te merken dat AvgBPerWrite ook is toegenomen en dat het schrijven van grotere blokken langer duurt. De toename van AvgBPerWrite wordt verwacht voor de taak voor het opnieuw opbouwen van de index.
Begrijp dat als je naar deze gegevens kijkt, je geen volledig beeld krijgt. Een betere manier om naar latenties te kijken met behulp van virtuele bestandsstatistieken, is door snapshots te maken en vervolgens de latentie voor de verstreken tijdsperiode te berekenen. Het onderstaande script gebruikt bijvoorbeeld twee snapshots (huidige en vorige) en berekent vervolgens het aantal lees- en schrijfbewerkingen in die periode, het verschil in io_stall_read_ms en io_stall_write_ms waarden, en deelt vervolgens io_stall_read_ms delta door het aantal leesbewerkingen, en io_stall_write_ms delta door aantal schrijft. Met deze methode berekenen we de hoeveelheid tijd die SQL Server wachtte op I/O voor lees- of schrijfbewerkingen, en deel deze vervolgens door het aantal lees- of schrijfbewerkingen om de latentie te bepalen.
DECLARE @CurrentID INT, @PreviousID INT; SET @CurrentID = 3; SET @PreviousID = @CurrentID - 1; WITH [p] AS ( SELECT [CaptureDate], [database_id], [file_id], [ReadLatency], [WriteLatency], [num_of_reads], [io_stall_read_ms], [num_of_writes], [io_stall_write_ms] FROM [msdb].[dbo].[SQLskills_FileLatency] WHERE [CaptureID] = @PreviousID ) SELECT [c].[CaptureDate] [CurrentCaptureDate], [p].[CaptureDate] [PreviousCaptureDate], DATEDIFF(MINUTE, [p].[CaptureDate], [c].[CaptureDate]) [MinBetweenCaptures], [c].[DB], [c].[physical_name], [c].[ReadLatency] [CurrentReadLatency], [p].[ReadLatency] [PreviousReadLatency], [c].[WriteLatency] [CurrentWriteLatency], [p].[WriteLatency] [PreviousWriteLatency], [c].[io_stall_read_ms]- [p].[io_stall_read_ms] [delta_io_stall_read], [c].[num_of_reads] - [p].[num_of_reads] [delta_num_of_reads], [c].[io_stall_write_ms] - [p].[io_stall_write_ms] [delta_io_stall_write], [c].[num_of_writes] - [p].[num_of_writes] [delta_num_of_writes], CASE WHEN ([c].[num_of_reads] - [p].[num_of_reads]) = 0 THEN NULL ELSE ([c].[io_stall_read_ms] - [p].[io_stall_read_ms])/([c].[num_of_reads] - [p].[num_of_reads]) END [IntervalReadLatency], CASE WHEN ([c].[num_of_writes] - [p].[num_of_writes]) = 0 THEN NULL ELSE ([c].[io_stall_write_ms] - [p].[io_stall_write_ms])/([c].[num_of_writes] - [p].[num_of_writes]) END [IntervalWriteLatency] FROM [msdb].[dbo].[SQLskills_FileLatency] [c] JOIN [p] ON [c].[database_id] = [p].[database_id] AND [c].[file_id] = [p].[file_id] WHERE [c].[CaptureID] = @CurrentID AND [c].[database_id] IN (2, 11);
Wanneer we dit uitvoeren om de latentie tijdens het opnieuw opbouwen van de index te berekenen, krijgen we het volgende:

Latentie berekend op basis van sys.dm_io_virtual_file_stats tijdens het opnieuw opbouwen van de index voor EX_AdventureWorks2012
Nu kunnen we zien dat de werkelijke latentie gedurende die tijd hoog was - wat we zouden verwachten. En als we dan terug zouden gaan naar onze normale werklast en deze een paar uur zouden laten draaien, zouden de gemiddelde waarden berekend op basis van virtuele bestandsstatistieken in de loop van de tijd afnemen. Als we kijken naar PerfMon-gegevens die tijdens de test zijn vastgelegd (en vervolgens zijn verwerkt via PAL), zien we significante pieken in Avg. Schijf sec/Lezen en Gem. Disk sec/Write die overeenkomt met de tijd dat het opnieuw opbouwen van de index werd uitgevoerd. Maar op andere momenten liggen de latentiewaarden ver onder de aanvaardbare waarden:
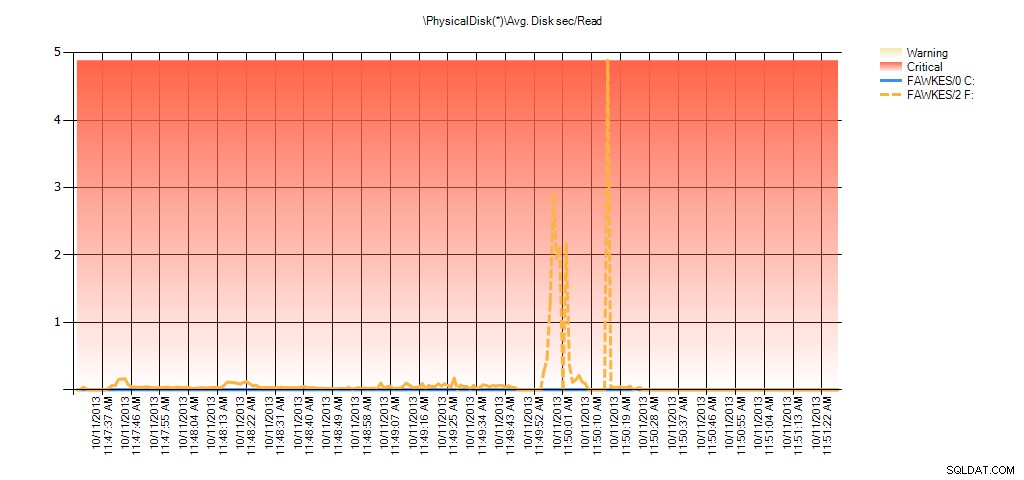
Samenvatting van Avg Disk Sec/Read van PAL voor EX_AdventureWorks2012 tijdens testen
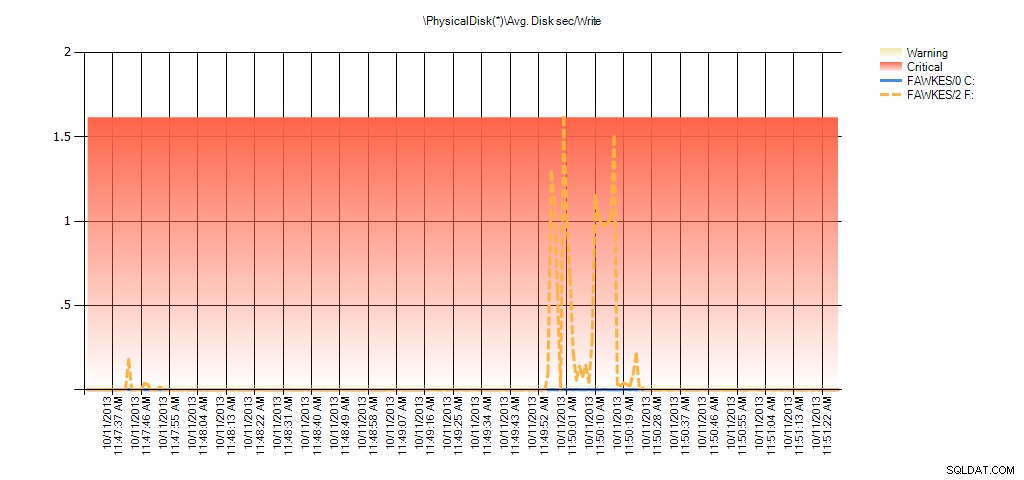
Samenvatting van Avg Disk Sec/Write from PAL voor EX_AdventureWorks2012 tijdens het testen
U kunt hetzelfde gedrag zien voor de BIG_AdventureWorks 2012-database. Hier is de latentie-informatie gebaseerd op de momentopname van de virtuele bestandsstatistieken vóór en na het opnieuw opbouwen van de index:

Latentie berekend op basis van sys.dm_io_virtual_file_stats tijdens het opnieuw opbouwen van de index voor BIG_AdventureWorks2012
En de prestatiemetergegevens laten dezelfde pieken zien tijdens het opnieuw opbouwen:
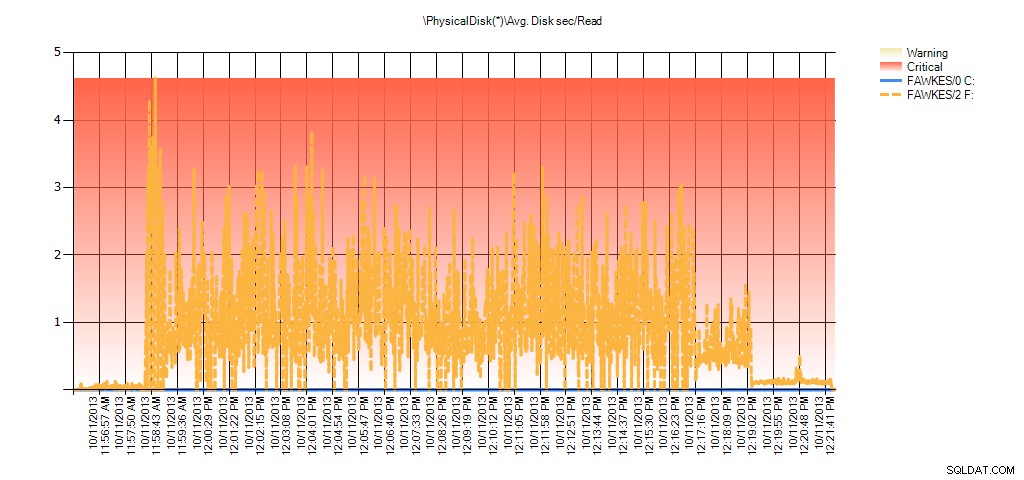
Samenvatting van Avg Disk Sec/Read van PAL voor BIG_AdventureWorks2012 tijdens testen
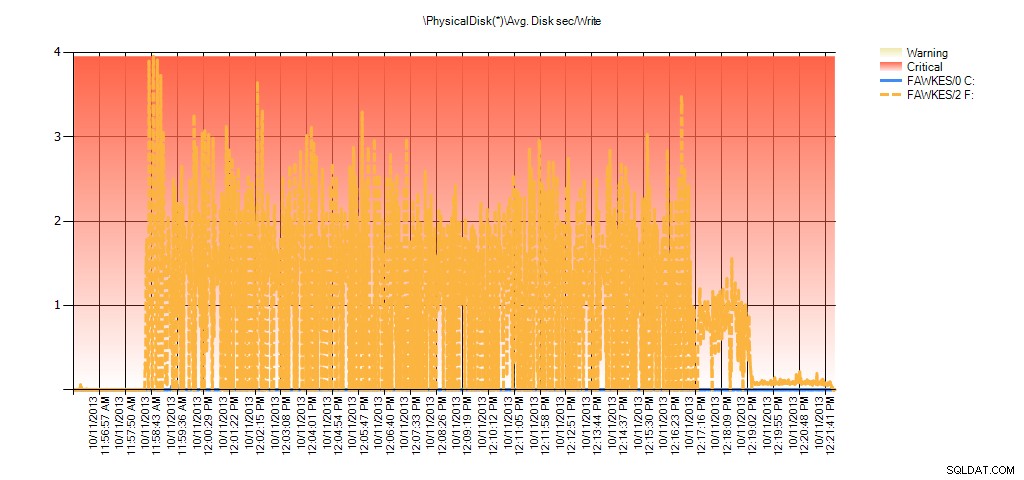
Samenvatting van Avg Disk Sec/Write from PAL voor BIG_AdventureWorks2012 tijdens het testen
Conclusie
Statistieken van virtuele bestanden zijn een goed startpunt wanneer u de I/O-prestaties voor een SQL Server-instantie wilt begrijpen. Als u I/O-gerelateerde wachttijden ziet wanneer u naar wachtstatistieken kijkt, is het kijken naar sys.dm_io_virtual_file_stats een logische volgende stap. Houd er echter rekening mee dat de gegevens die u bekijkt een aggregaat zijn sinds de statistieken voor het laatst zijn gewist door een van de bijbehorende gebeurtenissen (bijvoorbeeld opnieuw opstarten, offline van database, enz.). Als u lage latenties ziet, houdt het I/O-subsysteem de prestatiebelasting bij. Als u echter hoge latenties ziet, is het geen uitgemaakte zaak dat opslag een probleem is. Om echt te weten wat er aan de hand is, kunt u beginnen met het maken van snapshots van bestandsstatistieken, zoals hier wordt weergegeven, of u kunt gewoon Performance Monitor gebruiken om de latentie in realtime te bekijken. Het is heel eenvoudig om een gegevensverzamelaarset in PerfMon te maken die de fysieke schijftellers Avg vastlegt. Schijf sec./lezen en Gem. Disk Sec/Read voor alle schijven die databasebestanden hosten. Plan de Data Collector om regelmatig te starten en te stoppen, en bemonster elke n seconden (bijv. 15), en zodra u PerfMon-gegevens voor een geschikte tijd heeft vastgelegd, voert u deze door PAL om de latentie in de loop van de tijd te onderzoeken.
Als u merkt dat I/O-latentie optreedt tijdens uw normale werkbelasting, en niet alleen tijdens onderhoudstaken die I/O aansturen, nog steeds kan opslag niet als het onderliggende probleem aanwijzen. Opslaglatentie kan verschillende redenen hebben, zoals:
- SQL Server moet te veel gegevens lezen als gevolg van inefficiënte queryplannen of ontbrekende indexen
- Er is te weinig geheugen toegewezen aan de instantie en dezelfde gegevens worden steeds opnieuw van de schijf gelezen omdat deze niet in het geheugen kunnen blijven
- Impliciete conversies veroorzaken index- of tabelscans
- Query's voeren SELECT * uit wanneer niet alle kolommen vereist zijn
- Doorgestuurde recordproblemen veroorzaken extra I/O
- Lage paginadichtheden door indexfragmentatie, paginasplitsingen of onjuiste instellingen voor de vulfactor veroorzaken extra I/O
Wat de hoofdoorzaak ook is, wat essentieel is om te begrijpen over prestaties, vooral als het gaat om I/O, is dat er zelden één gegevenspunt is dat u kunt gebruiken om het probleem te lokaliseren. Om het echte probleem te vinden, zijn meerdere feiten nodig die, wanneer ze bij elkaar passen, u helpen het probleem te ontdekken.
Houd er ten slotte rekening mee dat in sommige gevallen de opslaglatentie volledig acceptabel kan zijn. Voordat u snellere opslag of wijzigingen in code eist, moet u de werkbelastingpatronen en Service Level Agreement (SLA) voor de database bekijken. In het geval van een datawarehouse dat rapporten aan gebruikers levert, is de SLA voor query's waarschijnlijk niet dezelfde waarden van minder dan een seconde die u zou verwachten voor een OLTP-systeem met groot volume. In de DW-oplossing kunnen I/O-latenties van meer dan één seconde perfect acceptabel en verwacht zijn. Begrijp de verwachtingen van het bedrijf en zijn gebruikers en bepaal vervolgens welke actie eventueel moet worden ondernomen. En als er wijzigingen nodig zijn, verzamel dan de kwantitatieve gegevens die u nodig hebt om uw argument te ondersteunen, namelijk wachtstatistieken, virtuele bestandsstatistieken en latenties uit Performance Monitor.