Dit artikel is het tweede in een reeks over optimalisatiedrempels voor het groeperen en aggregeren van gegevens. In deel 1 heb ik de reverse-engineered formule gegeven voor de kosten van de Stream Aggregate-operator. Ik heb uitgelegd dat deze operator de rijen moet gebruiken die zijn geordend door de groeperingsset (elke volgorde van zijn leden), en dat wanneer de gegevens vooraf worden besteld uit een index, u lineaire schaling krijgt met betrekking tot het aantal rijen en het aantal groepen. Ook is er in een dergelijk geval geen geheugentoelage nodig.
In dit artikel concentreer ik me op de kostenberekening en schaling van een op stroom aggregatie gebaseerde bewerking wanneer de gegevens niet vooraf worden verkregen uit een index, maar eerst moeten worden gesorteerd.
In mijn voorbeelden gebruik ik de PerformanceV3-voorbeelddatabase, zoals in deel 1. Je kunt het script downloaden dat deze database maakt en vult vanaf hier. Voordat u de voorbeelden uit dit artikel uitvoert, moet u ervoor zorgen dat u eerst de volgende code uitvoert om een aantal onnodige indexen te verwijderen:
DROP INDEX idx_nc_sid_od_cid OP dbo.Orders;DROP INDEX idx_unc_od_oid_i_cid_eid OP dbo.Orders;
De enige twee indexen die in deze tabel moeten worden achtergelaten, zijn idx_cl_od (geclusterd met orderdate als de sleutel) en PK_Orders (niet geclusterd met orderid als de sleutel).
Sorteren + Samenvoegen streamen
De focus van dit artikel is om te proberen te achterhalen hoe een stroomaggregatiebewerking wordt geschaald wanneer de gegevens niet vooraf zijn besteld door de groeperingsset. Aangezien de Stream Aggregate-operator de geordende rijen moet verwerken, moet het plan een expliciete Sort-operator bevatten als ze niet vooraf zijn besteld in een index. Dus de kosten van de geaggregeerde operatie waarmee u rekening moet houden, zijn de som van de kosten van de Sort + Stream Aggregate-operators.
Ik gebruik de volgende query (we noemen het Query 1) om een plan met een dergelijke optimalisatie te demonstreren:
SELECTEER verzendperiode, MAX(besteldatum) AS maxod VAN (SELECTEER TOP (100) * VANAF dbo.Orders) AS D GROEP DOOR verzendperiode;
Het plan voor deze zoekopdracht wordt getoond in figuur 1.

Figuur 1:Plan voor Query 1
De reden dat ik een tabeluitdrukking met een TOP-filter gebruik, is om het exacte aantal (geschatte) rijen te bepalen die betrokken zijn bij de groepering en aggregatie. Door gecontroleerde wijzigingen toe te passen, wordt het gemakkelijker om te proberen de kostprijsformules te reverse-engineeren.
Als je je afvraagt waarom zo'n klein aantal rijen in dit voorbeeld wordt gefilterd, heeft dit te maken met de optimalisatiedrempels die deze strategie de voorkeur geven boven het Hash Aggregate-algoritme. In deel 3 beschrijf ik de kostprijsberekening en schaalvergroting van het hash-alternatief. In gevallen waarin de optimizer niet zelf een stroomaggregatiebewerking kiest, bijvoorbeeld wanneer het om grote aantallen rijen gaat, kunt u deze altijd forceren met de hint OPTIE(ORDERGROEP) tijdens het onderzoeksproces. Als je je concentreert op de kosten van seriële abonnementen, kun je natuurlijk een MAXDOP 1-hint toevoegen om parallellisme te elimineren.
Zoals eerder vermeld, moet u, om de kosten en schaal van een niet-vooraf besteld stroomaggregatiealgoritme te evalueren, rekening houden met de som van de Sort + Stream Aggregate-operators. U kent de kostenformule voor de Stream Aggregate-operator al uit deel 1:
@numrows * 0.0000006 + @numgroups * 0.0000005In onze zoekopdracht hebben we 100 geschatte invoerrijen en 5 geschatte uitvoergroepen (5 verschillende verzender-ID's geschat op basis van dichtheidsinformatie). Dus de kosten van de Stream Aggregate-operator in ons plan zijn:
100 * 0,0000006 + 5 * 0,0000005 =0,00000625Laten we proberen de kostprijsformule voor de sorteeroperator te achterhalen. Onthoud dat onze focus ligt op de geschatte kosten en schaalvergroting, omdat ons uiteindelijke doel is om optimalisatiedrempels te vinden waarbij de optimizer zijn keuzes van de ene strategie naar de andere verandert.
De schatting van de I/O-kosten lijkt vast te staan:0,0112613. Ik krijg dezelfde I/O-kosten, ongeacht factoren zoals het aantal rijen, het aantal sorteerkolommen, het gegevenstype, enzovoort. Dit is waarschijnlijk de verklaring voor wat verwacht I/O-werk.
Wat betreft de CPU-kosten, helaas, Microsoft maakt de exacte algoritmen die ze gebruiken voor het sorteren niet publiekelijk bekend. Onder de algemene algoritmen die worden gebruikt voor het sorteren door database-engines in het algemeen, zijn er echter verschillende implementaties van merge sort en quicksort. Dankzij de inspanningen van Paul White, die dol is op het bekijken van Windows debugger-stacktraces (we hebben hier niet allemaal het lef voor), hebben we wat meer inzicht in het onderwerp, gepubliceerd in zijn serie "Internals of the Seven SQL Server Sorteert.” Volgens de bevindingen van Paul gebruikt de algemene sorteerklasse (gebruikt in het bovenstaande plan) merge sort (eerst intern, dan overgaand naar extern). Gemiddeld vereist dit algoritme n log n vergelijkingen om n items te sorteren. Met dit in gedachten is het waarschijnlijk een veilige gok als uitgangspunt om aan te nemen dat het CPU-gedeelte van de kosten van de operator gebaseerd is op een formule zoals:
CPU-kosten operator =Dit kan natuurlijk een te grote vereenvoudiging zijn van de werkelijke kostenformule die Microsoft gebruikt, maar bij gebrek aan documentatie hierover is dit een eerste schatting.
Vervolgens kunt u de CPU-kosten voor sorteren verkrijgen uit twee queryplannen die zijn gemaakt voor het sorteren van verschillende aantallen rijen, bijvoorbeeld 1000 en 2000, en op basis van deze en de bovenstaande formule de vergelijkingskosten en opstartkosten reverse-engineeren. Voor dit doel hoeft u geen gegroepeerde zoekopdracht te gebruiken; het is voldoende om gewoon een eenvoudige ORDER BY te doen. Ik gebruik de volgende twee queries (we noemen ze Query 2 en Query 3):
SELECTEER orderid % 1000000000 als mijnorderid VAN (SELECTEER TOP (1000) * VANUIT dbo.Orders) AS D ORDER BY myorderid; SELECTEER orderid % 1000000000 als mijnorderid VAN (SELECTEER TOP (2000) * VAN dbo.Orders) AS D ORDER DOOR mijnorderid;
Het punt bij het ordenen op het resultaat van een berekening is om een Sort-operator te forceren om in het plan te worden gebruikt.
Figuur 2 toont de relevante delen van de twee plannen:
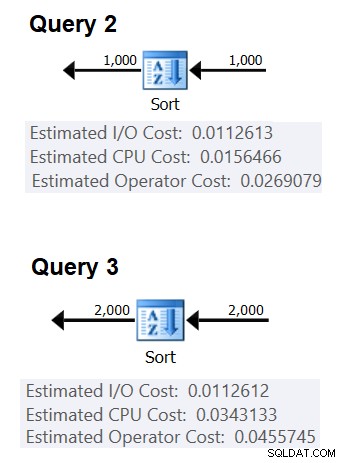
Figuur 2:Plannen voor Query 2 en Query 3
Om te proberen de kosten van één vergelijking af te leiden, gebruikt u de volgende formule:
vergelijkingskosten =
((
/ (
(0.0343133 – 0.0156466) / (2000*LOG(2000) – 1000*LOG(1000)) =2.25061348918698E-06
Wat de opstartkosten betreft, kunt u deze afleiden op basis van beide plannen, bijvoorbeeld op basis van het plan dat 2000 rijen sorteert:
opstartkosten =0,0343133 – 2000*LOG(2000) * 2.25061348918698E-06 =9.99127891201865E-05
En zo wordt onze formule voor het sorteren van CPU-kosten:
Sorteer CPU-kosten operator =9.99127891201865E-05 + @numrows * LOG(@numrows) * 2.25061348918698E-06Als u vergelijkbare technieken gebruikt, zult u merken dat factoren zoals de gemiddelde rijgrootte, het aantal bestelkolommen en hun gegevenstypes geen invloed hebben op de geschatte CPU-kosten voor sorteren. De enige factor die relevant lijkt, is het geschatte aantal rijen. Merk op dat de sortering een geheugentoekenning nodig heeft, en de toekenning is evenredig met het aantal rijen (geen groepen) en de gemiddelde rijgrootte. Maar onze focus ligt momenteel op de geschatte operatorkosten, en het lijkt erop dat deze schatting alleen wordt beïnvloed door het geschatte aantal rijen.
Deze formule lijkt de CPU-kosten goed te voorspellen tot een drempel van ongeveer 5.000 rijen. Probeer het met de volgende nummers:100, 200, 300, 400, 500, 1000, 2000, 3000, 4000, 5000:
SELECT aantalrijen, 9.99127891201865E-05 + aantalrijen * LOG(aantalrijen) * 2.25061348918698E-06 AS predicatedcost FROM (VALUES(100), (200), (300), (400), (500), (1000) , (2000), (3000), (4000), (5000)) AS D(aantal rijen);
Vergelijk wat de formule voorspelt en de geschatte CPU-kosten die de plannen laten zien voor de volgende vragen:
SELECTEER orderid % 1000000000 als mijnorderid VAN (SELECTEER TOP (100) * VANUIT dbo.Orders) AS D ORDER DOOR mijnorderid; SELECTEER orderid % 1000000000 als myorderid FROM (SELECT TOP (200) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECTEER orderid % 1000000000 als mijnorderid VAN (SELECTEER TOP (300) * VANAF dbo.Orders) ALS D ORDER DOOR myorderid; SELECTEER orderid % 1000000000 als myorderid FROM (SELECT TOP (400) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECTEER orderid % 1000000000 als myorderid FROM (SELECT TOP (500) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECTEER orderid % 1000000000 als mijnorderid VAN (SELECTEER TOP (1000) * VANUIT dbo.Orders) ALS D ORDER DOOR myorderid; SELECTEER orderid % 1000000000 als myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECTEER orderid % 1000000000 als myorderid FROM (SELECT TOP (3000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECTEER orderid % 1000000000 als myorderid FROM (SELECT TOP (4000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECTEER orderid % 1000000000 als mijnorderid VAN (SELECTEER TOP (5000) * VAN dbo.Orders) AS D ORDER DOOR mijnorderid;
Ik kreeg de volgende resultaten:
aantal predicatedcost geschatte kosten ratio ----------- --------------- -------------- --- ---- 100 0,0011363 0,0011365 1.00018 200 0,0024848 0,0024849 1.00004 300 0,0039510 0,0039511 1.00003 400 0,0054937 0,0054938 1.00002 500 0,0070933 0,0070933 1,00000 1000 0,0156466 0,0156466 1,00000 2000 0,0343133 0,0343133 1,00000 3000 0,0541576 0,0741576 5000 0,00074 400065De kolom voorspelde kosten toont de voorspelling op basis van onze reverse-engineering formule, de kolom geschatte kosten toont de geschatte kosten die in het plan worden weergegeven en de kolomverhouding toont de verhouding tussen de laatste en de eerste.
De voorspelling lijkt behoorlijk nauwkeurig tot 5.000 rijen. Bij aantallen groter dan 5.000 werkt onze reverse-engineered formule echter niet meer goed. De volgende zoekopdracht geeft u de voorspellingen voor rijen van 6K, 7K, 10K, 20K, 100K en 200K:
SELECT aantalrijen, 9.99127891201865E-05 + aantalrijen * LOG(aantalrijen) * 2.25061348918698E-06 AS predicatedcost FROM (VALUES(6000), (7000), (10000), (20000), (100000), (200000) ) AS D(aantal rijen);Gebruik de volgende query's om de geschatte CPU-kosten uit de plannen te halen (let op de hint om een serieel plan te forceren, want met grotere aantallen rijen is de kans groter dat u een parallel plan krijgt waarbij de kostenformules zijn aangepast voor parallellisme):
SELECTEER orderid % 1000000000 als myorderid VAN (SELECTEER TOP (6000) * VAN dbo.Orders) ALS D ORDER DOOR myorderid OPTIE (MAXDOP 1); SELECTEER orderid % 1000000000 als myorderid FROM (SELECT TOP (7000) * FROM dbo.Orders) AS D ORDER DOOR myorderid OPTIE (MAXDOP 1); SELECTEER orderid % 1000000000 als myorderid FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D ORDER DOOR myorderid OPTIE (MAXDOP 1); SELECTEER orderid % 1000000000 als myorderid FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D ORDER DOOR myorderid OPTIE (MAXDOP 1); SELECTEER orderid % 1000000000 als mijnorderid VAN (SELECTEER TOP (100000) * VAN dbo.Orders) ALS DORDER DOOR myorderid OPTIE (MAXDOP 1); SELECTEER orderid % 1000000000 als mijnorderid VAN (SELECTEER TOP (200000) * VAN dbo.Orders) ALS D ORDER DOOR myorderid OPTIE (MAXDOP 1);Ik kreeg de volgende resultaten:
aantal predicatedcost geschatte kosten ratio ----------- --------------- -------------- --- --- 6000 0.117575 0.160970 1.3691 7000 0.139583 0.244848 1.7541 10.000 0.207389 0.603420 2.9096 20.000 0.445878 1.311710 2.9419 100000 2.591210 7.623920 2.9422 200000 5.494330 16.165700 2.9423Zoals u kunt zien, wordt onze formule na 5.000 rijen steeds minder nauwkeurig, maar merkwaardig genoeg stabiliseert de nauwkeurigheidsratio zich op ongeveer 2,94 bij ongeveer 20.000 rijen. Dit houdt in dat bij grote aantallen onze formule nog steeds van toepassing is, alleen met een hogere vergelijkingskost, en dat ruwweg tussen de 5.000 en 20.000 rijen, het geleidelijk overgaat van de lagere vergelijkingskost naar de hogere. Maar wat zou het verschil tussen de kleine schaal en de grote schaal kunnen verklaren? Het goede nieuws is dat het antwoord niet zo ingewikkeld is als het verzoenen van kwantummechanica en algemene relativiteitstheorie met snaartheorie. Op de kleinere schaal wilde Microsoft alleen rekening houden met het feit dat de CPU-cache waarschijnlijk zal worden gebruikt, en voor kostendoeleinden gaan ze uit van een vaste cachegrootte.
Dus om de vergelijkingskosten op grote schaal te berekenen, wilt u de soort CPU-kosten van twee plannen gebruiken voor getallen boven de 20.000. Ik gebruik 100.000 en 200.000 rijen (laatste twee rijen in bovenstaande tabel). Hier is de formule om de vergelijkingskosten af te leiden:
vergelijkingskosten =
(16.1657 – 7.62392) / (200000*LOG(200000) – 100000*LOG(100000)) =6.62193536908588E-06Vervolgens volgt hier de formule om de opstartkosten af te leiden op basis van het plan voor 200.000 rijen:
opstartkosten =
16.1657 – 200000*LOG(200000) * 6.62193536908588E-06 =1.35166186417734E-04Het kan heel goed zijn dat de opstartkosten voor de kleine en grote schaal hetzelfde zijn, en dat het verschil dat we hebben te wijten is aan afrondingsfouten. Hoe dan ook, met grote aantallen rijen worden de opstartkosten verwaarloosbaar in vergelijking met de kosten van de vergelijkingen.
Samengevat, hier is de formule voor de CPU-kosten van de sorteeroperator voor grote aantallen (>=20000):
CPU-kosten operator =1,35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06Laten we de nauwkeurigheid van de formule testen met rijen van 500K, 1M en 10M. De volgende code geeft u de voorspellingen van onze formule:
SELECT aantalrijen, 1.35166186417734E-04 + aantalrijen * LOG(aantalrijen) * 6.62193536908588E-06 AS predicatedcost FROM (VALUES(500000), (1000000), (10000000)) AS D(numrows);Gebruik de volgende zoekopdrachten om de geschatte CPU-kosten te krijgen:
SELECTEER orderid % 1000000000 als myorderid FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTIE (MAXDOP 1); SELECTEER orderid % 1000000000 als myorderid FROM (SELECT TOP (1000000) * FROM dbo.Orders) AS D ORDER DOOR myorderid OPTIE (MAXDOP 1); SELECTEER CHECKSUM(NEWID()) als myorderid VAN (SELECTEER TOP (10000000) O1.orderid VAN dbo.Orders AS O1 CROSS JOIN dbo.Orders AS O2) AS D ORDER BY myorderid OPTIE (MAXDOP 1);Ik kreeg de volgende resultaten:
aantal predicatedcost geschatte kosten ratio ----------- --------------- -------------- --- --- 500000 43.4479 43.448 1.0000 1000000 91.4856 91.486 1.0000 10000000 1067.3300 1067.340 1.0000Het lijkt erop dat onze formule voor grote getallen het redelijk goed doet.
Alles bij elkaar
De totale kosten van het toepassen van een stroomaggregaat met expliciete sortering voor kleine aantallen rijen (<=5.000 rijen) bedragen:
+ + =
0,0112613
+ 9.99127891201865E-05 + @numrows * LOG(@ numrows) * 2.25061348918698E-06
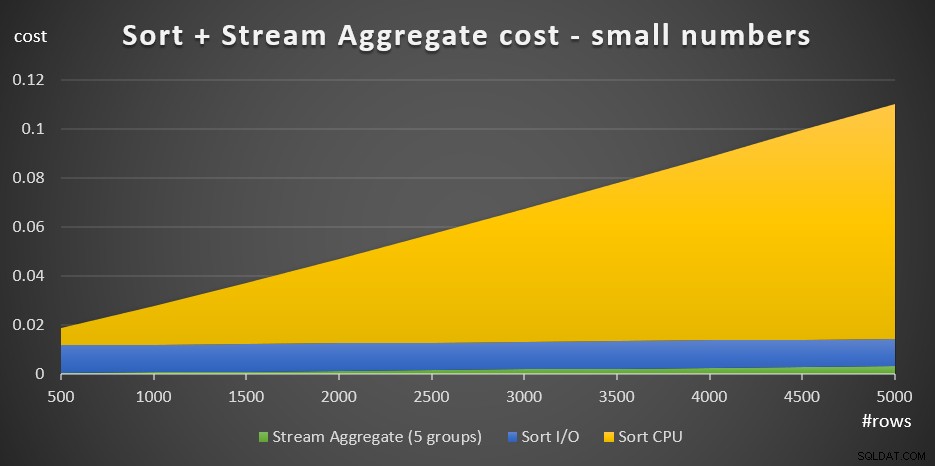
+ @numrows * 0.0000006 + @numgroups * 0.0000005Afbeelding 3 heeft een vlakdiagram dat laat zien hoe deze kosten worden geschaald.
Figuur 3:Sorteringskosten + Stroomaggregaat voor kleine aantallen rijenDe soort CPU-kosten vormen het meest substantiële deel van de totale totale Sort + Stream-kosten. Toch zijn bij kleine aantallen rijen de stroomaggregaatkosten en het sorteer-I/O-gedeelte van de kosten niet geheel verwaarloosbaar. In visuele termen kun je alle drie de delen in de grafiek duidelijk zien.
Wat betreft grote aantallen rijen (>=20.000), is de calculatieformule:
0.0112613
+ 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06
+ @numrows * 0.0000006 + @numgroups * 0.0000005Ik zag niet veel waarde in het nastreven van de exacte manier waarop de vergelijkingskosten overgaan van de kleine naar de grote schaal.
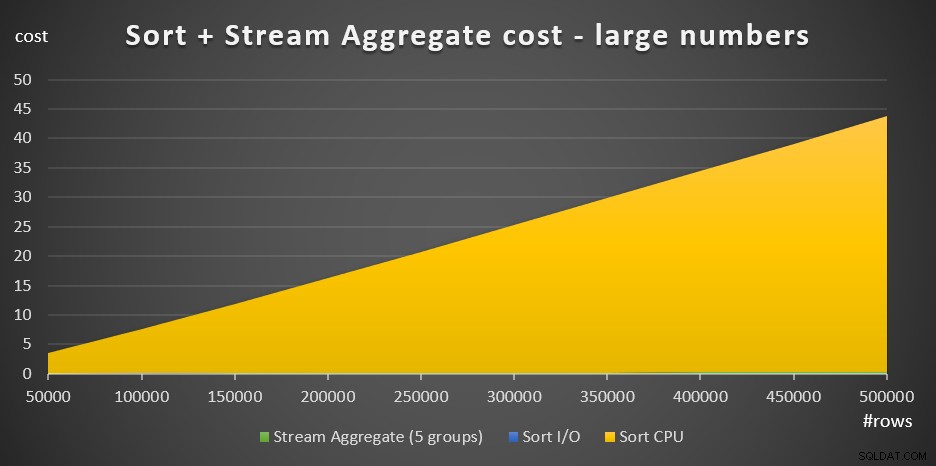
Afbeelding 4 heeft een vlakdiagram dat laat zien hoe de kosten voor grote aantallen worden geschaald.
Figuur 4:Sorteringskosten + Stroomaggregaat voor grote aantallen rijenBij grote aantallen rijen zijn de Stream Aggregate-kosten en Sort I/O-kosten zo verwaarloosbaar in vergelijking met de Sort CPU-kosten dat ze niet eens met het blote oog zichtbaar zijn in de grafiek. Bovendien is het deel van de Sort CPU-kosten dat wordt toegeschreven aan het opstartwerk ook verwaarloosbaar. Daarom is het enige deel van de kostenberekening dat echt zinvol is, de totale vergelijkingskosten:
@numrows * LOG(@numrows) *Dit betekent dat wanneer u de schaal van de Sort + Stream Aggregate-strategie moet evalueren, u deze kunt vereenvoudigen tot alleen dit dominante deel. Als u bijvoorbeeld moet evalueren hoe de kosten zouden schalen van 100.000 rijen naar 100.000.000 rijen, kunt u de formule gebruiken (merk op dat de vergelijkingskosten niet relevant zijn):
(100000000 * LOG(100000000)*) / (100000 * LOG(100000)*) =1600Dit vertelt u dat wanneer het aantal rijen toeneemt van 100.000 met een factor 1.000 tot 100.000.000, de geschatte kosten met een factor 1.600 toenemen.
Het schalen van 1.000.000 tot 1.000.000.000 rijen wordt als volgt berekend:
(1000000000 * LOG(1000000000)) / (1000000 * LOG (1000000)) =1500Dat wil zeggen, wanneer het aantal rijen toeneemt van 1.000.000 met een factor 1.000, nemen de geschatte kosten toe met een factor 1.500.
Dit zijn interessante observaties over de manier waarop de Sort + Stream Aggregate-strategie schaalt. Vanwege de zeer lage opstartkosten en extra lineaire schaling zou je verwachten dat deze strategie het goed doet met zeer kleine aantallen rijen, maar niet zo goed met grote aantallen. Het feit dat de Stream Aggregate-operator alleen zo'n klein deel van de kosten vertegenwoordigt in vergelijking met wanneer een sortering ook nodig is, vertelt u ook dat u aanzienlijk betere prestaties kunt krijgen als de situatie zodanig is dat u een ondersteunende index kunt maken .
In het volgende deel van de serie behandel ik de schaling van het Hash Aggregate-algoritme. Als je het leuk vindt om te proberen kostprijsformules te bedenken, kijk dan of je het voor dit algoritme kunt achterhalen. Het is belangrijk om erachter te komen welke factoren het beïnvloeden, de manier waarop het schaalt en de omstandigheden waarin het het beter doet dan de andere algoritmen.