De snelste manier om een mediaan te berekenen gebruikt de SQL Server 2012 OFFSET uitbreiding van de ORDER BY clausule. De op één na snelste oplossing loopt een goede tweede en gebruikt een (mogelijk geneste) dynamische cursor die op alle versies werkt. In dit artikel wordt gekeken naar een veelvoorkomende ROW_NUMBER . van vóór 2012 oplossing voor het mediaanberekeningsprobleem om te zien waarom het minder goed presteert en wat er kan worden gedaan om het sneller te laten gaan.
Enkele mediane test
De voorbeeldgegevens voor deze test bestaan uit een enkele tabel met tien miljoen rijen (overgenomen uit het originele artikel van Aaron Bertrand):
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); De OFFSET-oplossing
Om de maatstaf te bepalen, is hier de SQL Server 2012 (of later) OFFSET-oplossing gemaakt door Peter Larsson:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - (@Count % 2)) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); De query om de rijen in de tabel te tellen, wordt becommentarieerd en vervangen door een hardgecodeerde waarde om zich te concentreren op de prestaties van de kerncode. Met een warme cache en het verzamelen van uitvoeringsplan uitgeschakeld, wordt deze query uitgevoerd gedurende 910 ms gemiddeld op mijn testmachine. Het uitvoeringsplan wordt hieronder weergegeven:

Even terzijde:het is interessant dat deze redelijk complexe vraag in aanmerking komt voor een triviaal plan:
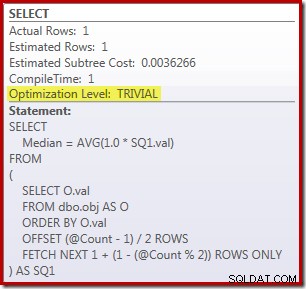
De ROW_NUMBER-oplossing
Voor systemen met SQL Server 2008 R2 of eerder gebruiken de best presterende alternatieve oplossingen een dynamische cursor zoals eerder vermeld. Als u dat niet als een optie kunt (of wilt) beschouwen, is het normaal om na te denken over het emuleren van de 2012 OFFSET uitvoeringsplan met behulp van ROW_NUMBER .
Het basisidee is om de rijen in de juiste volgorde te nummeren en vervolgens te filteren op slechts één of twee rijen die nodig zijn om de mediaan te berekenen. Er zijn verschillende manieren om dit in Transact SQL te schrijven; een compacte versie die alle belangrijke elementen bevat, is als volgt:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
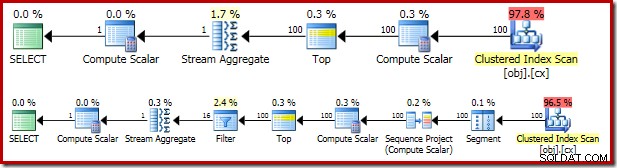
Het resulterende uitvoeringsplan lijkt veel op de OFFSET versie:

Het is de moeite waard om naar elk van de planoperators te kijken om ze volledig te begrijpen:
- De Segment-operator is overbodig in dit plan. Het is vereist als de
ROW_NUMBERrangschikkingsfunctie had eenPARTITION BYclausule, maar dat doet het niet. Toch blijft het in het definitieve plan. - Het Sequentieproject voegt een berekend rijnummer toe aan de reeks rijen.
- De Compute Scalar definieert een uitdrukking die is gekoppeld aan de noodzaak om de
valimpliciet te converteren kolom naar numeriek zodat het kan worden vermenigvuldigd met de constante letterlijke1.0in de vraag. Deze berekening wordt uitgesteld totdat een latere operator deze nodig heeft (wat toevallig het stroomaggregaat is). Deze runtime-optimalisatie betekent dat de impliciete conversie alleen wordt uitgevoerd voor de twee rijen die worden verwerkt door de Stream Aggregate, niet voor de 5.000.001 rijen die zijn aangegeven voor de Compute Scalar. - De operator Top wordt geïntroduceerd door de query-optimizer. Het erkent dat hoogstens alleen de eerste
(@Count + 2) / 2rijen zijn nodig voor de query. We hadden eenTOP ... ORDER BYkunnen toevoegen in de subquery om dit expliciet te maken, maar deze optimalisatie maakt dat grotendeels overbodig. - Het filter implementeert de voorwaarde in de
WHEREclausule, waarbij alle behalve de twee 'middelste' rijen worden weggefilterd die nodig zijn om de mediaan te berekenen (de geïntroduceerde Top is ook gebaseerd op deze voorwaarde). - The Stream Aggregate berekent de
SUMenCOUNTvan de twee mediaanrijen. - De laatste Compute Scalar berekent het gemiddelde van de som en telling.
Ruwe prestaties
Vergeleken met de OFFSET plan, kunnen we verwachten dat de extra operators Segment, Sequence Project en Filter een nadelig effect zullen hebben op de prestaties. Het is de moeite waard om even de geschatte . te vergelijken kosten van de twee abonnementen:
De OFFSET abonnement kost naar schatting 0,0036266 eenheden, terwijl de ROW_NUMBER abonnement wordt geschat op 0,0036744 eenheden. Dit zijn zeer kleine aantallen en er is weinig verschil tussen de twee.
Het is dus misschien verrassend dat de ROW_NUMBER query loopt daadwerkelijk 4000 ms gemiddeld vergeleken met 910 ms gemiddelde voor de OFFSET oplossing. Een deel van deze stijging kan zeker worden verklaard door de overhead van de extra planoperators, maar een factor vier lijkt overdreven. Er moet meer aan de hand zijn.
Je hebt waarschijnlijk ook gemerkt dat de kardinaliteitsschattingen voor beide geschatte plannen hierboven behoorlijk hopeloos verkeerd zijn. Dit komt door het effect van de Top-operators, die een uitdrukking hebben die verwijst naar een variabele als hun rij-tellingslimieten. De query-optimizer kan de inhoud van variabelen niet zien tijdens het compileren, dus neemt het zijn toevlucht tot zijn standaardschatting van 100 rijen. Beide plannen komen tijdens runtime in feite 5,000.001 rijen tegen.
Dit is allemaal erg interessant, maar het verklaart niet direct waarom de ROW_NUMBER zoekopdracht is meer dan vier keer langzamer dan de OFFSET versie. De schatting van de kardinaliteit van 100 rijen is in beide gevallen immers even fout.
De prestaties van de ROW_NUMBER-oplossing verbeteren
In mijn vorige artikel zagen we hoe de prestaties van de gegroepeerde mediaan OFFSET test kan bijna worden verdubbeld door simpelweg een PAGLOCK . toe te voegen hint. Deze hint heft de normale beslissing van de opslagengine op om gedeelde vergrendelingen te verwerven en vrij te geven bij de rijgranulariteit (vanwege de lage verwachte kardinaliteit).
Ter herinnering:de PAGLOCK hint was niet nodig in de enkele mediaan OFFSET test vanwege een afzonderlijke interne optimalisatie die gedeelde vergrendelingen op rijniveau kan overslaan, wat resulteert in slechts een klein aantal met intentie gedeelde vergrendelingen op paginaniveau.
We kunnen de ROW_NUMBER . verwachten enkele mediane oplossing om te profiteren van dezelfde interne optimalisatie, maar dat doet het niet. Bewaken van vergrendelingsactiviteit terwijl de ROW_NUMBER query wordt uitgevoerd, zien we meer dan een half miljoen gedeelde vergrendelingen op individuele rijniveaus genomen en vrijgelaten.
Nu we dus weten wat het probleem is, kunnen we de sluitprestaties op dezelfde manier verbeteren als voorheen:ofwel met een PAGLOCK hint granulariteit vergrendelen, of door de schatting van de kardinaliteit te verhogen met behulp van gedocumenteerde traceringsvlag 4138.
Het uitschakelen van het "rijdoel" met behulp van de traceringsvlag is om verschillende redenen de minder bevredigende oplossing. Ten eerste is het alleen effectief in SQL Server 2008 R2 of hoger. We zouden hoogstwaarschijnlijk de voorkeur geven aan de OFFSET oplossing in SQL Server 2012, dus dit beperkt de fixatie van de traceringsvlag effectief tot alleen SQL Server 2008 R2. Ten tweede zijn voor het toepassen van de traceringsvlag machtigingen op beheerdersniveau vereist, tenzij toegepast via een planhandleiding. Een derde reden is dat het uitschakelen van rijdoelen voor de hele zoekopdracht andere ongewenste effecten kan hebben, vooral bij complexere plannen.
Daarentegen is de PAGLOCK hint is effectief, beschikbaar in alle versies van SQL Server zonder speciale machtigingen, en heeft geen grote bijwerkingen buiten de granulariteit van de vergrendeling.
Het PAGLOCK toepassen hint naar de ROW_NUMBER query verbetert de prestaties enorm:vanaf 4000 ms tot 1500 ms:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK) -- New!
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
De 1500 ms resultaat is nog steeds aanzienlijk langzamer dan de 910 ms voor de OFFSET oplossing, maar het is nu in ieder geval in dezelfde marge. Het resterende prestatieverschil is simpelweg te wijten aan het extra werk in het uitvoeringsplan:

In de OFFSET plan worden vijf miljoen rijen verwerkt tot aan de Top (met de expressies die zijn gedefinieerd bij de Compute Scalar uitgesteld zoals eerder besproken). In de ROW_NUMBER plan, hetzelfde aantal rijen moet worden verwerkt door het Segment, Sequentieproject, Top en Filter.