Het type en aantal vergrendelingen dat is verkregen en vrijgegeven tijdens het uitvoeren van query's kan een verrassend effect hebben op de prestaties (bij gebruik van een vergrendelingsisolatieniveau zoals het standaard leescommitment), zelfs als er niet wordt gewacht of geblokkeerd. Er is geen informatie in uitvoeringsplannen om de hoeveelheid vergrendelingsactiviteit tijdens de uitvoering aan te geven, wat het moeilijker maakt om te zien wanneer overmatige vergrendeling een prestatieprobleem veroorzaakt.
Om enkele minder bekende vergrendelingsgedragingen in SQL Server te onderzoeken, zal ik de query's en voorbeeldgegevens uit mijn laatste bericht over het berekenen van medianen hergebruiken. In dat bericht vermeldde ik dat de OFFSET gegroepeerde mediaanoplossing had een expliciete PAGLOCK nodig vergrendelingshint om te voorkomen dat u zwaar verliest aan de geneste cursor oplossing, dus laten we beginnen met de redenen daarvoor in detail te bekijken.
De OFFSET gegroepeerde mediane oplossing
De gegroepeerde mediaantest hergebruikte de voorbeeldgegevens uit het eerdere artikel van Aaron Bertrand. Het onderstaande script herschept deze opstelling met miljoenen rijen, bestaande uit tienduizend records voor elk van honderd denkbeeldige verkopers:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
De SQL Server 2012 (en later) OFFSET oplossing gemaakt door Peter Larsson is als volgt (zonder enige vergrendelingshints):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); De belangrijke onderdelen van het post-uitvoeringsplan worden hieronder weergegeven:

Met alle vereiste gegevens in het geheugen, wordt deze query uitgevoerd in 580 ms gemiddeld op mijn laptop (met SQL Server 2014 Service Pack 1). De prestaties van deze query kunnen worden verbeterd tot 320 ms eenvoudig door een vergrendelingshint voor paginagranulariteit toe te voegen aan de tabel Verkoop in de subquery toepassen:
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK) -- NEW!
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Het uitvoeringsplan is ongewijzigd (nou ja, afgezien van de vergrendelingshinttekst in showplan XML natuurlijk):
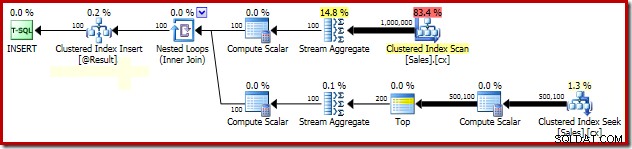
Gegroepeerde mediane vergrendelingsanalyse
De verklaring voor de dramatische prestatieverbetering dankzij de PAGLOCK hint is vrij eenvoudig, althans aanvankelijk.
Als we de vergrendelingsactiviteit handmatig controleren terwijl deze query wordt uitgevoerd, zien we dat zonder de gedetailleerde hint voor paginavergrendeling, SQL Server meer dan een half miljoen vergrendelingen op rijniveau verwerft en vrijgeeft tijdens het zoeken naar de geclusterde index. Er is geen blokkade om de schuld te geven; het simpelweg verkrijgen en vrijgeven van zoveel vergrendelingen voegt een aanzienlijke overhead toe aan de uitvoering van deze query. Het aanvragen van vergrendelingen op paginaniveau vermindert de vergrendelingsactiviteit aanzienlijk, wat resulteert in sterk verbeterde prestaties.
Het probleem met de vergrendelingsprestaties van dit specifieke plan is beperkt tot de geclusterde indexzoekopdracht in het bovenstaande plan. De volledige scan van de geclusterde index (gebruikt om het aantal aanwezige rijen voor elke verkoper te berekenen) maakt automatisch gebruik van vergrendelingen op paginaniveau. Dit is een interessant punt. Het gedetailleerde vergrendelingsgedrag van de SQL Server-engine is niet in hoge mate gedocumenteerd in Books Online, maar verschillende leden van het SQL Server-team hebben in de loop der jaren een paar algemene opmerkingen gemaakt, waaronder het feit dat de onbeperkte scans de neiging hebben om pagina's in beslag te nemen sloten, terwijl kleinere operaties meestal beginnen met rijsloten.
De query-optimizer maakt enige informatie beschikbaar voor de opslagengine, waaronder kardinaliteitsschattingen, interne hints voor isolatieniveau en vergrendelingsgranulariteit, welke interne optimalisaties veilig kunnen worden toegepast, enzovoort. Nogmaals, deze details zijn niet gedocumenteerd in Books Online. Uiteindelijk gebruikt de opslagengine een verscheidenheid aan informatie om te beslissen welke vergrendelingen tijdens runtime nodig zijn en in welke mate ze moeten worden genomen.
Even terzijde, en onthoud dat we het hebben over een query die wordt uitgevoerd onder het standaard vergrendelingsniveau voor leescommitted transactie-isolatie, houd er rekening mee dat de rijvergrendelingen die zonder de granulariteitshint worden genomen, in dit geval niet escaleren naar een tabelvergrendeling. Dit komt omdat het normale gedrag onder read-commit is om de vorige vergrendeling op te heffen net voordat de volgende vergrendeling wordt verkregen, wat betekent dat slechts een enkele gedeelde rijvergrendeling (met de bijbehorende hogere intentie-gedeelde vergrendelingen) op een bepaald moment zal worden vastgehouden. Aangezien het aantal gelijktijdig gehouden rijvergrendelingen nooit de drempel bereikt, wordt er geen escalatie van de vergrendeling geprobeerd.
De OFFSET enkelvoudige mediane oplossing
De prestatietest voor een enkele mediaanberekening maakt gebruik van een andere set voorbeeldgegevens, opnieuw overgenomen uit het eerdere artikel van Aaron. Het onderstaande script maakt een tabel met tien miljoen rijen pseudo-willekeurige gegevens:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
De OFFSET oplossing is:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Het post-uitvoeringsplan is:

Deze query wordt uitgevoerd in 910 ms gemiddeld op mijn testmachine. Prestaties zijn ongewijzigd als een PAGLOCK hint is toegevoegd, maar de reden daarvoor is niet wat je misschien denkt...
Enkele mediane vergrendelingsanalyse
Je zou kunnen verwachten dat de opslagengine toch gedeelde vergrendelingen op paginaniveau kiest, vanwege de geclusterde indexscan, wat uitlegt waarom een PAGLOCK hint heeft geen effect. In feite blijkt uit het monitoren van de vergrendelingen die zijn genomen terwijl deze query wordt uitgevoerd, dat er helemaal geen gedeelde vergrendelingen (S) worden genomen, in welke mate dan ook . De enige vergrendelingen zijn intent-shared (IS) op object- en paginaniveau.
De verklaring voor dit gedrag bestaat uit twee delen. Het eerste wat opvalt is dat de Clustered Index Scan onder een Top operator in het uitvoeringsplan staat. Dit heeft een belangrijk effect op kardinaliteitsschattingen, zoals blijkt uit het (geschatte) plan voor uitvoering:

De OFFSET en FETCH clausules in de query verwijzen naar een expressie en een variabele, dus de query-optimizer raadt het aantal rijen dat nodig is tijdens runtime. De standaard gok voor Top is honderd rijen. Dit is natuurlijk een vreselijke gok, maar het is voldoende om de opslagengine te overtuigen om te vergrendelen op rijgranulariteit in plaats van op paginaniveau.
Als we het "rijdoel"-effect van de Top-operator uitschakelen met behulp van gedocumenteerde traceringsvlag 4138, verandert het geschatte aantal rijen bij de scan in tien miljoen (wat nog steeds verkeerd is, maar in de andere richting). Dit is voldoende om de granulariteitsbeslissing van de opslagengine te wijzigen, zodat gedeelde vergrendelingen op paginaniveau (let op, niet met opzet gedeelde vergrendelingen) worden genomen:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1
OPTION (QUERYTRACEON 4138); -- NEW!
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Het geschatte uitvoeringsplan geproduceerd onder traceringsvlag 4138 is:

Terugkerend naar het hoofdvoorbeeld, de schatting van honderd rijen vanwege het geraden rijdoel betekent dat de opslagengine ervoor kiest om op rijniveau te vergrendelen. We zien echter alleen intent-shared (IS) locks op tabel- en paginaniveau. Deze vergrendelingen op een hoger niveau zouden heel normaal zijn als we gedeelde (S) vergrendelingen op rijniveau zouden zien, dus waar zijn ze gebleven?
Het antwoord is dat de opslagengine een andere optimalisatie bevat die in bepaalde omstandigheden de gedeelde vergrendelingen op rijniveau kan overslaan. Wanneer deze optimalisatie wordt toegepast, worden de intent-shared locks op een hoger niveau nog steeds verkregen.
Samenvattend, voor de single-mediaan zoekopdracht:
- Het gebruik van een variabele en uitdrukking in de
OFFSETclausule betekent dat de optimizer kardinaliteit raadt. - De lage schatting betekent dat de opslagengine beslist over een vergrendelingsstrategie op rijniveau.
- Een interne optimalisatie betekent dat de S-vergrendelingen op rijniveau tijdens runtime worden overgeslagen, waardoor alleen de IS-vergrendelingen op pagina- en objectniveau overblijven.
De single mediaan-query zou hetzelfde prestatieprobleem met rijvergrendeling hebben gehad als de gegroepeerde mediaan (vanwege de onnauwkeurige schatting van de query-optimizer), maar deze is opgeslagen door een afzonderlijke storage-engine-optimalisatie die ertoe heeft geleid dat alleen de intentie-gedeelde pagina- en tabelvergrendelingen zijn genomen tijdens runtime.
De gegroepeerde mediane test opnieuw bezocht
U vraagt zich misschien af waarom de Clustered Index Seek in de gegroepeerde mediaantest geen gebruik heeft gemaakt van dezelfde optimalisatie van de opslagengine om gedeelde vergrendelingen op rijniveau over te slaan. Waarom werden er zoveel gedeelde rijsloten gebruikt, waardoor de PAGLOCK hint nodig?
Het korte antwoord is dat deze optimalisatie niet beschikbaar is voor INSERT...SELECT vragen. Als we de SELECT op zichzelf (d.w.z. zonder de resultaten naar een tabel te schrijven), en zonder een PAGLOCK hint, de optimalisatie voor het overslaan van rijvergrendeling is toegepast:
DECLARE @s datetime2 = SYSUTCDATETIME();
--DECLARE @Result AS table
--(
-- SalesPerson integer PRIMARY KEY,
-- Median float NOT NULL
--);
--INSERT @Result
-- (SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());
Alleen intent-shared (IS)-vergrendelingen op tabel- en paginaniveau worden gebruikt en de prestaties nemen toe tot hetzelfde niveau als wanneer we de PAGLOCK gebruiken hint. U vindt dit gedrag natuurlijk niet in de documentatie en kan op elk moment veranderen. Toch is het goed om je hiervan bewust te zijn.
In het geval dat u zich afvroeg, heeft traceringsvlag 4138 in dit geval geen effect op de vergrendelingsgranulariteitskeuze van de opslagengine, omdat het geschatte aantal rijen bij het zoeken te laag is (per toepassingsiteratie), zelfs als het rijdoel is uitgeschakeld.
Voordat u conclusies trekt over de prestaties van een query, moet u het aantal en het type vergrendelingen controleren die tijdens de uitvoering worden gebruikt. Hoewel SQL Server meestal de 'juiste' granulariteit kiest, zijn er momenten waarop het fout kan gaan, soms met dramatische gevolgen voor de prestaties.