Gastauteur:Monica Rathbun (@SQLEspresso)
Soms komen prestatieproblemen met hardware, zoals schijf-I/O-latentie, neer op een niet-geoptimaliseerde werkbelasting in plaats van ondermaatse hardware. Veel databasebeheerders, waaronder ik, willen de opslag meteen de schuld geven van de traagheid. Voordat u een hoop geld uitgeeft aan nieuwe hardware, moet u altijd uw werklast onderzoeken op onnodige I/O.
Dingen om te onderzoeken
| Artikel | I/O-impact | Mogelijke oplossingen |
|---|---|---|
| Ongebruikte indexen | Extra schrijfacties | Index verwijderen / uitschakelen |
| Ontbrekende indexen | Extra gelezen | Index / Bedekkende Indexen toevoegen |
| Impliciete conversies | Extra lees- en schrijfbewerkingen | Verborgen of Cast Field bij de bron voordat de waarde wordt geëvalueerd |
| Functies | Extra lees- en schrijfbewerkingen | Ze verwijderd, converteer de gegevens voor evaluatie |
| ETL | Extra lees- en schrijfbewerkingen | SSIS gebruiken, replicatie, gegevensvastlegging wijzigen, beschikbaarheidsgroepen |
| Bestellen en groeperen | Extra lees- en schrijfbewerkingen | Verwijder ze waar mogelijk |
Ongebruikte indexen
We kennen allemaal de kracht van een index. Het hebben van de juiste indexen kan lichtjaren verschil maken in de querysnelheid. Maar hoeveel van ons houden onze indexen voortdurend bij boven het opnieuw opbouwen en reorganiseren van indexen? Het is belangrijk om regelmatig een indexscript uit te voeren om te evalueren welke indexen daadwerkelijk worden gebruikt. Ik gebruik persoonlijk de diagnostische vragen van Glenn Berry om dit te doen.
Het zal u verbazen dat sommige van uw indexen helemaal niet zijn gelezen. Deze indexen zijn een belasting voor bronnen, vooral op een zeer transactionele tabel. Let bij het bekijken van de resultaten op die indexen met een hoog aantal schrijfbewerkingen in combinatie met een laag aantal leesbewerkingen. In dit voorbeeld kun je zien dat ik schrijfopdrachten verspil. De niet-geclusterde index is 11 miljoen keer geschreven, maar slechts twee keer gelezen.

Ik begin met het uitschakelen van de indexen die in deze categorie vallen en laat ze vallen nadat ik heb bevestigd dat er geen problemen zijn opgetreden. Door deze oefening routinematig uit te voeren, kunnen onnodige I/O-schrijfbewerkingen naar uw systeem aanzienlijk worden verminderd, maar houd er rekening mee dat gebruiksstatistieken op uw indexen slechts zo goed zijn als de laatste keer opnieuw opstarten, dus zorg ervoor dat u gegevens hebt verzameld voor een volledige bedrijfscyclus voordat u afschrijft een index als "nutteloos".
Ontbrekende indexen
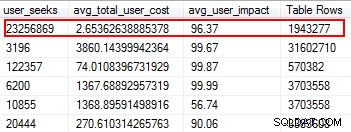
Ontbrekende indexen zijn een van de gemakkelijkste dingen om op te lossen; tenslotte, wanneer u een uitvoeringsplan uitvoert, zal het u vertellen of er geen indexen zijn gevonden, maar dat zou handig zijn geweest. Maar wacht, ik hoop dat u niet zomaar willekeurig indexen toevoegt op basis van deze suggestie. Als u dit doet, kunnen er dubbele indexen ontstaan, en indexen die minimaal worden gebruikt, waardoor I/O wordt verspild. Nogmaals, terug naar de scripts van Glenn, hij geeft ons een geweldig hulpmiddel om het nut van een index te evalueren door gebruikerszoekacties, gebruikersimpact en aantal rijen te geven. Besteed aandacht aan degenen met hoge waarden, samen met lage kosten en impact. Dit is een geweldige plek om te beginnen en het zal u helpen lees-I/O te verminderen.
Impliciete conversies
Impliciete conversies vinden vaak plaats wanneer een zoekopdracht twee of meer kolommen met verschillende gegevenstypen vergelijkt. In het onderstaande voorbeeld moet het systeem extra I/O uitvoeren om een varchar(max)-kolom te vergelijken met een nvarchar(4000)-kolom, wat leidt tot een impliciete conversie en uiteindelijk een scan in plaats van een zoekopdracht. Door ervoor te zorgen dat de tabellen overeenkomende gegevenstypen hebben, of door deze waarde eenvoudigweg vóór evaluatie om te zetten, kunt u I/O aanzienlijk verminderen en de kardinaliteit verbeteren (de geschatte rijen die de optimalisatiefunctie mag verwachten).
dbo.table1 t1 JOIN dbo.table2 t2 ON t1.ObjectName = t2.TableName
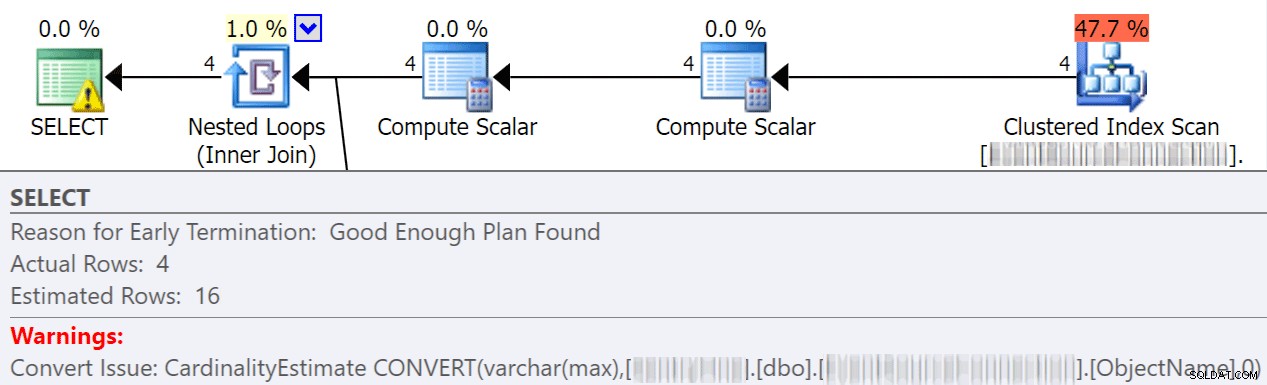
Jonathan Kehayias gaat veel meer in detail in deze geweldige post:"Hoe duur zijn impliciete conversies aan de kolomzijde?"
Functies
Een van de meest vermijdbare, gemakkelijk op te lossen dingen die ik ben tegengekomen die bespaart op I/O-kosten, is het verwijderen van functies van waar clausules. Een perfect voorbeeld is een datumvergelijking, zoals hieronder weergegeven.
CONVERT(Date,FromDate) >= CONVERT(Date, dbo.f_realdate(MyField)) AND (CONVERT(Date,ToDate) <= CONVERT(Date, dbo.f_realdate(MyField))
Of het nu in een JOIN-instructie of in een WHERE-component is, dit zorgt ervoor dat elke kolom wordt geconverteerd voordat deze wordt geëvalueerd. Door deze kolommen eenvoudig voor evaluatie om te zetten in een tijdelijke tabel, kunt u een hoop onnodige I/O elimineren.
Of, nog beter, voer helemaal geen conversies uit (voor dit specifieke geval heeft Aaron Bertrand het hier over het vermijden van functies in de waar-clausule, en merk op dat dit nog steeds slecht kan zijn, ook al is conversie naar datum mogelijk).
ETL
Neem de tijd om te onderzoeken hoe uw gegevens worden geladen. Ben je tabellen aan het afkappen en herladen? Kunt u in plaats daarvan replicatie implementeren, een alleen-lezen AG-replica of verzending loggen? Worden alle tabellen geschreven om daadwerkelijk gelezen te worden? Hoe laadt u de gegevens? Is het via opgeslagen procedures of SSIS? Het onderzoeken van dit soort dingen kan I/O drastisch verminderen.
In mijn omgeving ontdekte ik dat we dagelijks 48 tabellen afkapten met elke ochtend meer dan 120 miljoen rijen. Bovendien laadden we 9,6 miljoen rijen per uur. Je kunt je voorstellen hoeveel onnodige I/O dat heeft opgeleverd. In mijn geval was het implementeren van transactionele replicatie mijn oplossing bij uitstek. Eenmaal geïmplementeerd hadden we veel minder klachten van gebruikers over vertragingen tijdens onze laadtijden, die aanvankelijk werden toegeschreven aan de trage opslag.
Bestellen op &groeperen op
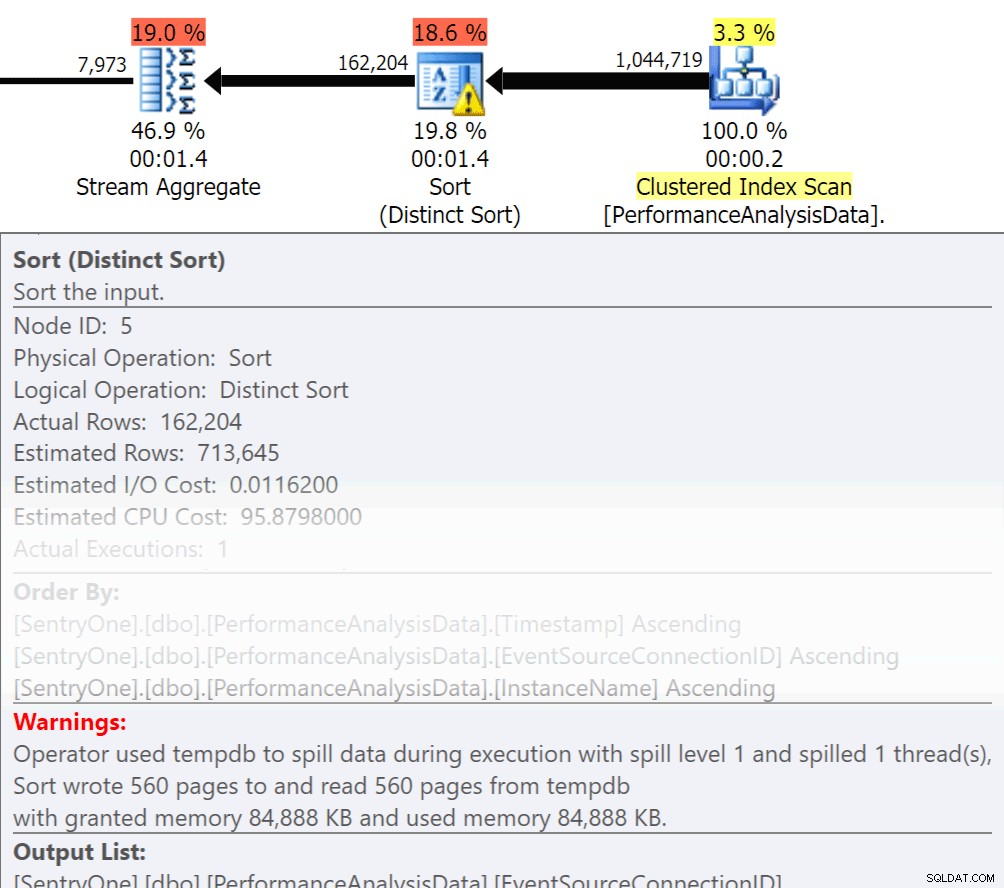 Vraag jezelf af, moeten die gegevens in volgorde worden geretourneerd? Moeten we echt groeperen in de procedure, of kunnen we dat in een melding of aanvraag doen? Order By en Group By-bewerkingen kunnen ertoe leiden dat leesbewerkingen naar de schijf gaan, wat extra schijf-I/O veroorzaakt. Als deze acties gerechtvaardigd zijn, zorg er dan voor dat u ondersteunende indexen en nieuwe statistieken hebt over de kolommen die worden gesorteerd of gegroepeerd. Dit zal de optimizer helpen bij het maken van het plan. Omdat we soms Order By en Group By gebruiken in tijdelijke tabellen. zorg ervoor dat u automatisch statistieken maakt voor TEMPDB en uw gebruikersdatabases. Hoe actueler de statistieken zijn, hoe meer kardinaliteit de optimizer kan krijgen, wat resulteert in betere plannen, minder overloop en minder I/O.
Vraag jezelf af, moeten die gegevens in volgorde worden geretourneerd? Moeten we echt groeperen in de procedure, of kunnen we dat in een melding of aanvraag doen? Order By en Group By-bewerkingen kunnen ertoe leiden dat leesbewerkingen naar de schijf gaan, wat extra schijf-I/O veroorzaakt. Als deze acties gerechtvaardigd zijn, zorg er dan voor dat u ondersteunende indexen en nieuwe statistieken hebt over de kolommen die worden gesorteerd of gegroepeerd. Dit zal de optimizer helpen bij het maken van het plan. Omdat we soms Order By en Group By gebruiken in tijdelijke tabellen. zorg ervoor dat u automatisch statistieken maakt voor TEMPDB en uw gebruikersdatabases. Hoe actueler de statistieken zijn, hoe meer kardinaliteit de optimizer kan krijgen, wat resulteert in betere plannen, minder overloop en minder I/O.
Nu heeft Group By zeker zijn plaats als het gaat om het verzamelen van gegevens in plaats van het retourneren van een heleboel rijen. Maar de sleutel hier is om I/O te verminderen, de toevoeging van de aggregatie draagt bij aan de I/O.
Samenvatting
Dit zijn nog maar het topje van de ijsberg wat je kunt doen, maar het is een geweldige plek om te beginnen met het verminderen van I/O. Voordat u hardware de schuld geeft van uw latentieproblemen, moet u eens kijken wat u kunt doen om de schijfdruk te minimaliseren.
Over de auteur
 Monica Rathbun is momenteel een Consultant bij Denny Cherry &Associates Consulting en een Microsoft Data Platform MVP. Ze is al 15 jaar een Lone DBA en werkt met alle aspecten van SQL Server en Oracle. Ze reist en spreekt op SQLSaturdays om andere Lone DBA's te helpen met technieken om het werk van velen te doen. Monica is de leider van de Hampton Roads SQL Server-gebruikersgroep en is een regionale mentor voor de Mid-Atlantic Pass. Monica is altijd te vinden op Twitter (@SQLEspresso) en deelt handige tips en trucs uit aan haar volgers. Als ze niet druk is met haar werk, zie je haar taxichauffeur spelen om haar twee dochters heen en weer te laten dansen op danslessen.
Monica Rathbun is momenteel een Consultant bij Denny Cherry &Associates Consulting en een Microsoft Data Platform MVP. Ze is al 15 jaar een Lone DBA en werkt met alle aspecten van SQL Server en Oracle. Ze reist en spreekt op SQLSaturdays om andere Lone DBA's te helpen met technieken om het werk van velen te doen. Monica is de leider van de Hampton Roads SQL Server-gebruikersgroep en is een regionale mentor voor de Mid-Atlantic Pass. Monica is altijd te vinden op Twitter (@SQLEspresso) en deelt handige tips en trucs uit aan haar volgers. Als ze niet druk is met haar werk, zie je haar taxichauffeur spelen om haar twee dochters heen en weer te laten dansen op danslessen.