Op PASS Summit een paar weken geleden heeft Microsoft CTP2.1 van SQL Server 2019 uitgebracht, en een van de grote functieverbeteringen die is opgenomen in de CTP is Scalar UDF Inlining. Voorafgaand aan deze release wilde ik spelen met het prestatieverschil tussen de inlining van scalaire UDF's en de RBAR-uitvoering (row-by-agonizing-row) van scalaire UDF's in eerdere versies van SQL Server en ik stuitte op een syntaxisoptie voor de FUNCTIE MAKEN verklaring in de SQL Server Books Online die ik nog nooit eerder had gezien.
De DDL voor CREATE FUNCTION ondersteunt een WITH-clausule voor functie-opties en tijdens het lezen van Books Online merkte ik dat de syntaxis het volgende bevatte:
-- Transact-SQL-functieclausules::= { [ ENCRYPTIE ] | [ SCHEMABINDING ] | [ RETOURNEERT NULL OP NULL INPUT | GEROEPEN OP NULL INPUT ] | [ EXECUTE_AS_Clause ] }
Ik was erg benieuwd naar de RETURNS NULL ON NULL INPUT functie-optie, dus besloot ik wat te testen. Ik was zeer verrast toen ik ontdekte dat het eigenlijk een vorm van scalaire UDF-optimalisatie is die al sinds SQL Server 2008 R2 in het product zit.
Het blijkt dat als u weet dat een scalaire UDF altijd een NULL-resultaat retourneert wanneer een NULL-invoer wordt gegeven, de UDF ALTIJD moet worden gemaakt met de RETURNS NULL ON NULL INPUT optie, want dan voert SQL Server zelfs helemaal geen functiedefinitie uit voor rijen waar de invoer NULL is - waardoor het effectief wordt kortgesloten en de verspilde uitvoering van de functie-body wordt vermeden.
Om u dit gedrag te laten zien, ga ik een SQL Server 2017-instantie gebruiken waarop de nieuwste cumulatieve update is toegepast en de AdventureWorks2017 database van GitHub (u kunt deze hier downloaden) die wordt geleverd met een dbo.ufnLeadingZeros functie die eenvoudig voorloopnullen toevoegt aan de invoerwaarde en een reeks van acht tekens retourneert die deze voorloopnullen bevat. Ik ga een nieuwe versie van die functie maken die de RETURNS NULL ON NULL INPUT bevat optie zodat ik het kan vergelijken met de originele functie voor uitvoeringsprestaties.
GEBRUIK [AdventureWorks2017];GO CREATE FUNCTION [dbo].[ufnLeadingZeros_new]( @Value int ) RETURN varchar(8) MET SCHEMABINDING, RETURNS NULL OP NULL INPUT ALS BEGIN VERKLAREN @ReturnValue varchar(8); SET @ReturnValue =CONVERT (varchar (8), @Value); SET @ReturnValue =REPLICATE('0', 8 - DATALENGTH(@ReturnValue)) + @ReturnValue; RETOUR (@ReturnValue); EINDE; GO Om de verschillen in uitvoeringsprestaties binnen de database-engine van de twee functies te testen, heb ik besloten om een Extended Events-sessie op de server te maken om de sqlserver.module_end te volgen. gebeurtenis, die wordt geactiveerd aan het einde van elke uitvoering van de scalaire UDF voor elke rij. Hierdoor kon ik de rij-voor-rij verwerkingssemantiek demonstreren en kon ik ook bijhouden hoe vaak de functie daadwerkelijk werd aangeroepen tijdens de test. Ik besloot om ook de sql_batch_completed . te verzamelen en sql_statement_completed evenementen en filter alles op session_id om er zeker van te zijn dat ik alleen informatie vastlegde met betrekking tot de sessie waarop ik de tests uitvoerde (als u deze resultaten wilt repliceren, moet u de 74 op alle plaatsen in de onderstaande code wijzigen in de sessie-ID van uw test code zal inlopen). De gebeurtenissessie gebruikt TRACK_CAUSALITY zodat het gemakkelijk is om te tellen hoeveel uitvoeringen van de functie hebben plaatsgevonden via de activity_id.seq_no waarde voor de gebeurtenissen (die met één wordt verhoogd voor elke gebeurtenis die voldoet aan de session_id filter).
GEBEURTENISSESSIE MAKEN [Session72] OP SERVER GEBEURTENIS TOEVOEGEN sqlserver.module_end( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), GEBEURTENIS TOEVOEGEN sqlserver.sql_batch_ WHERE ( [package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_batch_starting( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74) ))), GEBEURTENIS TOEVOEGEN sqlserver.sql_statement_completed( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), GEBEURTENIS TOEVOEGEN sqlserver.sql_statement_starting( WHERE ([package064][equal_uint].[equal_uint].[equal_uint64] ([sqlserver].[session_id],(74)))) MET (TRACK_CAUSALITY=ON) GO
Nadat ik de gebeurtenissessie had gestart en de Live Data Viewer in Management Studio had geopend, voerde ik twee query's uit; een die de originele versie van de functie gebruikt om nullen op te vullen naar de CurrencyRateID kolom in de Sales.SalesOrderHeader tabel, en de nieuwe functie om de identieke uitvoer te produceren, maar met behulp van de RETURNS NULL ON NULL INPUT optie, en ik heb de informatie over het werkelijke uitvoeringsplan vastgelegd ter vergelijking.
SELECT SalesOrderID, dbo.ufnLeadingZeros(CurrencyRateID) FROM Sales.SalesOrderHeader; GA SELECT SalesOrderID, dbo.ufnLeadingZeros_new (CurrencyRateID) FROM Sales.SalesOrderHeader; GO
Bij het bekijken van de gegevens van Extended Events kwamen een aantal interessante dingen naar voren. Ten eerste is de oorspronkelijke functie 31.465 keer uitgevoerd (vanaf de telling van module_end events) en de totale CPU-tijd voor de sql_statement_completed gebeurtenis was 204 ms met een duur van 482 ms.
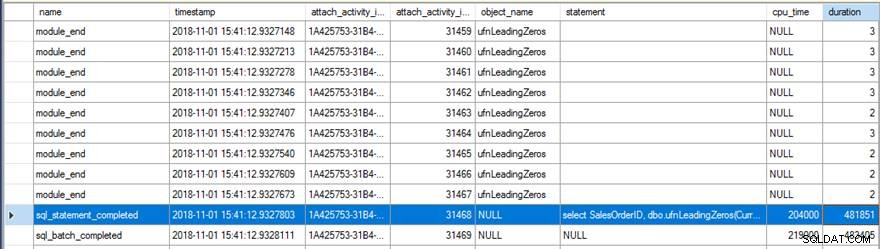
De nieuwe versie met de RETURNS NULL ON NULL INPUT gespecificeerde optie is slechts 13.976 keer uitgevoerd (opnieuw, vanaf de telling van module_end events) en de CPU-tijd voor de sql_statement_completed gebeurtenis was 78 ms met een duur van 359 ms.

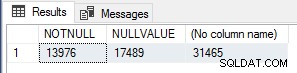
Ik vond dit interessant, dus om de uitvoeringstellingen te verifiëren, heb ik de volgende query uitgevoerd om NIET NULL te tellen waarderijen, NULL-waarderijen en totaalrijen in de Sales.SalesOrderHeader tafel.
SELECT SUM(CASE WHEN CurrencyRateID IS NOT NULL THEN 1 ELSE 0 END) AS NOTNULL, SUM(CASE WHEN CurrencyRateID IS NULL THEN 1 ELSE 0 END) AS NULLVALUE, COUNTSales.;
Deze nummers komen exact overeen met het nummer van module_end gebeurtenissen voor elk van de tests, dus dit is absoluut een zeer eenvoudige prestatie-optimalisatie voor scalaire UDF's die moet worden gebruikt als u weet dat het resultaat van de functie NULL is als de invoerwaarden NULL zijn, om de uitvoering van de functie kort te sluiten/te omzeilen helemaal voor die rijen.
De QueryTimeStats-informatie in de werkelijke uitvoeringsplannen weerspiegelde ook de prestatieverbeteringen:
Dit is een behoorlijk aanzienlijke vermindering van de CPU-tijd alleen, wat voor sommige systemen een aanzienlijk pijnpunt kan zijn.
Het gebruik van scalaire UDF's is een bekend ontwerp-antipatroon voor prestaties en er zijn verschillende methoden om de code te herschrijven om het gebruik en de prestatieproblemen te voorkomen. Maar als ze al aanwezig zijn en niet gemakkelijk kunnen worden gewijzigd of verwijderd, kunt u de UDF eenvoudig opnieuw maken met de RETURNS NULL ON NULL INPUT optie kan een zeer eenvoudige manier zijn om de prestaties te verbeteren als er veel NULL-invoer is in de dataset waar de UDF wordt gebruikt.