Karen Ly, een Jr. Fixed Income Analyst bij RBC, gaf me een T-SQL-uitdaging waarbij ik de dichtstbijzijnde match moet vinden, in plaats van een exacte match te vinden. In dit artikel behandel ik een algemene, simplistische vorm van de uitdaging.
De uitdaging
De uitdaging omvat het matchen van rijen van twee tabellen, T1 en T2. Gebruik de volgende code om een voorbeelddatabase te maken met de naam testdb, met daarin de tabellen T1 en T2:
SET NOCOUNT ON;
IF DB_ID('testdb') IS NULL
CREATE DATABASE testdb;
GO
USE testdb;
DROP TABLE IF EXISTS dbo.T1, dbo.T2;
CREATE TABLE dbo.T1
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T1 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T1_col1 DEFAULT(0xAA)
);
CREATE TABLE dbo.T2
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T2 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T2_col1 DEFAULT(0xBB)
); Zoals u kunt zien, hebben zowel T1 als T2 een numerieke kolom (INT-type in dit voorbeeld) genaamd val. De uitdaging is om voor elke rij uit T1 de rij uit T2 te matchen waar het absolute verschil tussen T2.val en T1.val het laagst is. In het geval van gelijkspel (meerdere overeenkomende rijen in T2), match de bovenste rij op basis van val oplopend, keycol oplopende volgorde. Dat wil zeggen, de rij met de laagste waarde in de val-kolom, en als je nog steeds banden hebt, de rij met de laagste keycol-waarde. De tiebreaker wordt gebruikt om determinisme te garanderen.
Gebruik de volgende code om T1 en T2 te vullen met kleine sets voorbeeldgegevens om de juistheid van uw oplossingen te kunnen controleren:
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 (val)
VALUES(1),(1),(3),(3),(5),(8),(13),(16),(18),(20),(21);
INSERT INTO dbo.T2 (val)
VALUES(2),(2),(7),(3),(3),(11),(11),(13),(17),(19); Controleer de inhoud van T1:
SELECT keycol, val, SUBSTRING(othercols, 1, 1) AS othercols FROM dbo.T1 ORDER BY val, keycol;
Deze code genereert de volgende uitvoer:
keycol val othercols ----------- ----------- --------- 1 1 0xAA 2 1 0xAA 3 3 0xAA 4 3 0xAA 5 5 0xAA 6 8 0xAA 7 13 0xAA 8 16 0xAA 9 18 0xAA 10 20 0xAA 11 21 0xAA
Controleer de inhoud van T2:
SELECT keycol, val, SUBSTRING(othercols, 1, 1) AS othercols FROM dbo.T2 ORDER BY val, keycol;
Deze code genereert de volgende uitvoer:
keycol val othercols ----------- ----------- --------- 1 2 0xBB 2 2 0xBB 4 3 0xBB 5 3 0xBB 3 7 0xBB 6 11 0xBB 7 11 0xBB 8 13 0xBB 9 17 0xBB 10 19 0xBB
Dit is het gewenste resultaat voor de gegeven voorbeeldgegevens:
keycol1 val1 othercols1 keycol2 val2 othercols2 ----------- ----------- ---------- ----------- ----------- ---------- 1 1 0xAA 1 2 0xBB 2 1 0xAA 1 2 0xBB 3 3 0xAA 4 3 0xBB 4 3 0xAA 4 3 0xBB 5 5 0xAA 4 3 0xBB 6 8 0xAA 3 7 0xBB 7 13 0xAA 8 13 0xBB 8 16 0xAA 9 17 0xBB 9 18 0xAA 9 17 0xBB 10 20 0xAA 10 19 0xBB 11 21 0xAA 10 19 0xBB
Voordat je aan de uitdaging begint, onderzoek je het gewenste resultaat en zorg je ervoor dat je de matching-logica begrijpt, inclusief de tiebreaking-logica. Beschouw bijvoorbeeld de rij in T1 waar keycol 5 is en val 5 is. Deze rij heeft meerdere overeenkomsten in T2:
keycol val othercols ----------- ----------- --------- 4 3 0xBB 5 3 0xBB 3 7 0xBB
In al deze rijen is het absolute verschil tussen T2.val en T1.val (5) 2. Gebruikmakend van de tiebreaking-logica gebaseerd op de volgorde val oplopend, is keycol oplopend de bovenste rij hier degene waar val 3 is en keycol 4.
U gebruikt de kleine sets met voorbeeldgegevens om de geldigheid van uw oplossingen te controleren. Om de prestaties te controleren, hebt u grotere sets nodig. Gebruik de volgende code om een helperfunctie met de naam GetNums te maken, die een reeks gehele getallen in een aangevraagd bereik genereert:
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE OR ALTER FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO Gebruik de volgende code om T1 en T2 te vullen met grote sets voorbeeldgegevens:
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; De variabelen @numrowsT1 en @numrowsT2 bepalen het aantal rijen waarmee u de tabellen wilt vullen. De variabelen @maxvalT1 en @maxvalT2 bepalen het bereik van verschillende waarden in de val-kolom en beïnvloeden daarom de dichtheid van de kolom. De bovenstaande code vult de tabellen met elk 1.000.000 rijen en gebruikt het bereik van 1 - 10.000.000 voor de val-kolom in beide tabellen. Dit resulteert in een lage dichtheid in de kolom (groot aantal verschillende waarden, met een klein aantal duplicaten). Het gebruik van lagere maximale waarden resulteert in een hogere dichtheid (kleiner aantal verschillende waarden, en dus meer duplicaten).
Oplossing 1, met één TOP-subquery
De eenvoudigste en meest voor de hand liggende oplossing is er waarschijnlijk een die een query uitvoert op T1, en met behulp van de CROSS APPLY-operator wordt een query toegepast met een TOP (1)-filter, waarbij de rijen worden gerangschikt op het absolute verschil tussen T1.val en T2.val, met behulp van T2.val , T2.keycol als de tiebreak. Hier is de code van de oplossing:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) T2.*
FROM dbo.T2
ORDER BY ABS(T2.val - T1.val), T2.val, T2.keycol ) AS A; Onthoud dat er in elk van de tabellen 1.000.000 rijen zijn. En de dichtheid van de val-kolom is laag in beide tabellen. Helaas, aangezien er geen filterpredikaat is in de toegepaste query en de volgorde een uitdrukking omvat die kolommen manipuleert, is er hier geen mogelijkheid om ondersteunende indexen te maken. Deze query genereert het plan in figuur 1.
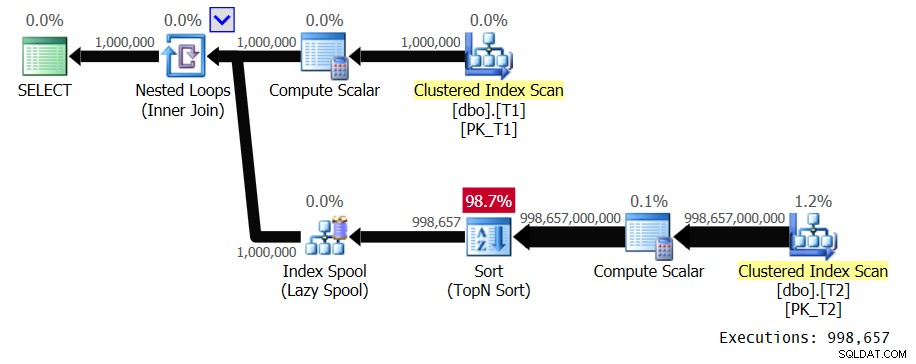 Figuur 1:plan voor oplossing 1
Figuur 1:plan voor oplossing 1
De buitenste ingang van de lus scant 1.000.000 rijen van T1. De binnenste ingang van de lus voert een volledige scan uit van T2 en een TopN-sortering voor elke afzonderlijke T1.val-waarde. In ons plan gebeurt dit 998.657 keer omdat we een zeer lage dichtheid hebben. Het plaatst de rijen in een indexspoel, gecodeerd door T1.val, zodat het deze kan hergebruiken voor dubbele exemplaren van T1.val-waarden, maar we hebben maar heel weinig duplicaten. Dit plan heeft kwadratische complexiteit. Tussen alle verwachte uitvoeringen van de binnenste tak van de lus, wordt verwacht dat deze bijna een biljoen rijen zal verwerken. Als je het hebt over grote aantallen rijen die een zoekopdracht moet verwerken, weten mensen al dat je te maken hebt met een dure zoekopdracht als je eenmaal miljarden rijen begint te noemen. Normaal gesproken spreken mensen geen termen als biljoenen uit, tenzij ze het hebben over de Amerikaanse staatsschuld of beurscrashes. U behandelt dergelijke getallen meestal niet in de context van queryverwerking. Maar plannen met kwadratische complexiteit kunnen snel eindigen met dergelijke aantallen. Het uitvoeren van de query in SSMS met Include Live Query Statistics ingeschakeld duurde 39,6 seconden om slechts 100 rijen van T1 op mijn laptop te verwerken. Dit betekent dat het ongeveer 4,5 dagen duurt om deze query te voltooien. De vraag is, houdt u echt van binge-watching live query-plannen? Zou een interessant Guinness-record kunnen zijn om te proberen en te vestigen.
Oplossing 2, met twee TOP-subquery's
Ervan uitgaande dat u op zoek bent naar een oplossing die seconden, niet dagen, duurt om te voltooien, hier is een idee. Verenig in de toegepaste tabelexpressie twee binnenste TOP (1)-query's:één filtert een rij waar T2.val
Hier zijn de aanbevolen indexen om deze oplossing te ondersteunen:
CREATE INDEX idx_val_key ON dbo.T1(val, keycol) INCLUDE(othercols); CREATE INDEX idx_val_key ON dbo.T2(val, keycol) INCLUDE(othercols); CREATE INDEX idx_valD_key ON dbo.T2(val DESC, keycol) INCLUDE(othercols);
Hier is de volledige oplossingscode:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; Onthoud dat we in elke tabel 1.000.000 rijen hebben, waarbij de kolom val waarden heeft in het bereik van 1 - 10.000.000 (lage dichtheid) en optimale indexen.
Het plan voor deze zoekopdracht wordt getoond in figuur 2.
Figuur 2:Plan voor Oplossing 2
Observeer het optimale gebruik van de indexen op T2, resulterend in een plan met lineaire schaal. Dit plan gebruikt een indexspoel op dezelfde manier als het vorige plan, d.w.z. om herhaling van het werk in de binnenste tak van de lus voor dubbele T1.val-waarden te voorkomen. Dit zijn de prestatiestatistieken die ik heb gekregen voor het uitvoeren van deze query op mijn systeem:
Elapsed: 27.7 sec, CPU: 27.6 sec, logical reads: 17,304,674
Oplossing 2, met spoolen uitgeschakeld
Je kunt het niet helpen, maar vraag je af of de indexspoel hier echt nuttig is. Het punt is om herhaling van het werk voor dubbele T1.val-waarden te voorkomen, maar in een situatie als de onze, waar we een zeer lage dichtheid hebben, zijn er maar heel weinig duplicaten. Dit betekent dat het werk bij het spoolen hoogstwaarschijnlijk groter is dan alleen het herhalen van het werk voor duplicaten. Er is een eenvoudige manier om dit te verifiëren:met traceringsvlag 8690 kunt u spoolen in het plan uitschakelen, zoals:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A
OPTION(QUERYTRACEON 8690); Ik heb het plan weergegeven in figuur 3 voor deze uitvoering:
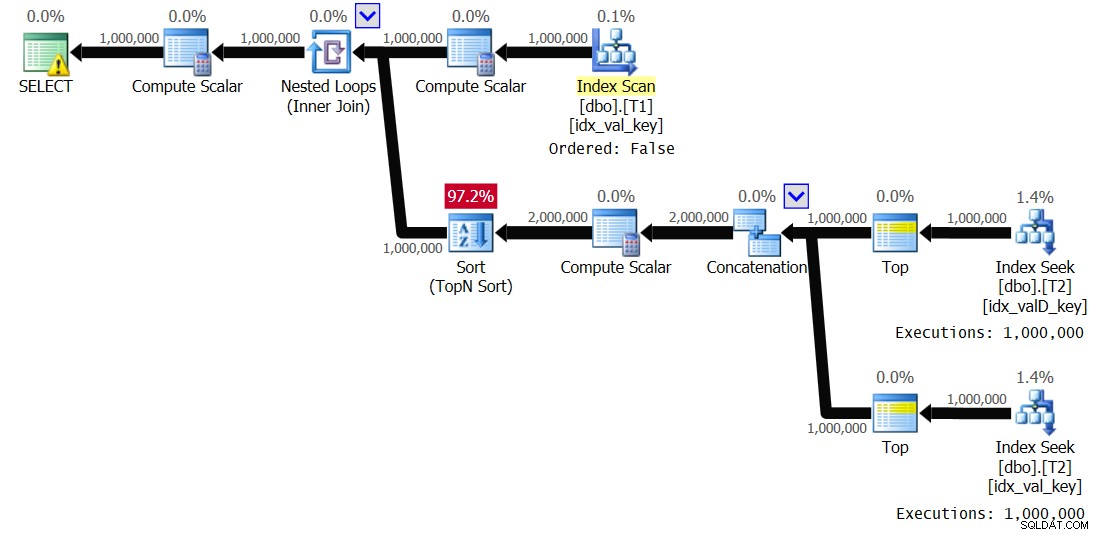 Figuur 3:Plan voor oplossing 2, met spooling uitgeschakeld
Figuur 3:Plan voor oplossing 2, met spooling uitgeschakeld
Merk op dat de indexspoel is verdwenen en deze keer wordt de binnenste tak van de lus 1.000.000 keer uitgevoerd. Dit zijn de prestatiestatistieken die ik voor deze uitvoering heb gekregen:
Elapsed: 19.18 sec, CPU: 19.17 sec, logical reads: 6,042,148
Dat is een reductie van 44 procent in de uitvoeringstijd.
Oplossing 2, met aangepast waardebereik en indexering
Het uitschakelen van spoolen heeft veel zin als u een lage dichtheid hebt in de T1.val-waarden; het spoelen kan echter zeer nuttig zijn als u een hoge dichtheid heeft. Voer bijvoorbeeld de volgende code uit om T1 en T2 opnieuw te vullen met voorbeeldgegevensinstelling @maxvalT1 en @maxvalT2 tot 1000 (maximaal 1000 verschillende waarden):
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 1000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 1000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; Voer Oplossing 2 opnieuw uit, eerst zonder de traceringsvlag:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; Het plan voor deze uitvoering is weergegeven in figuur 4:
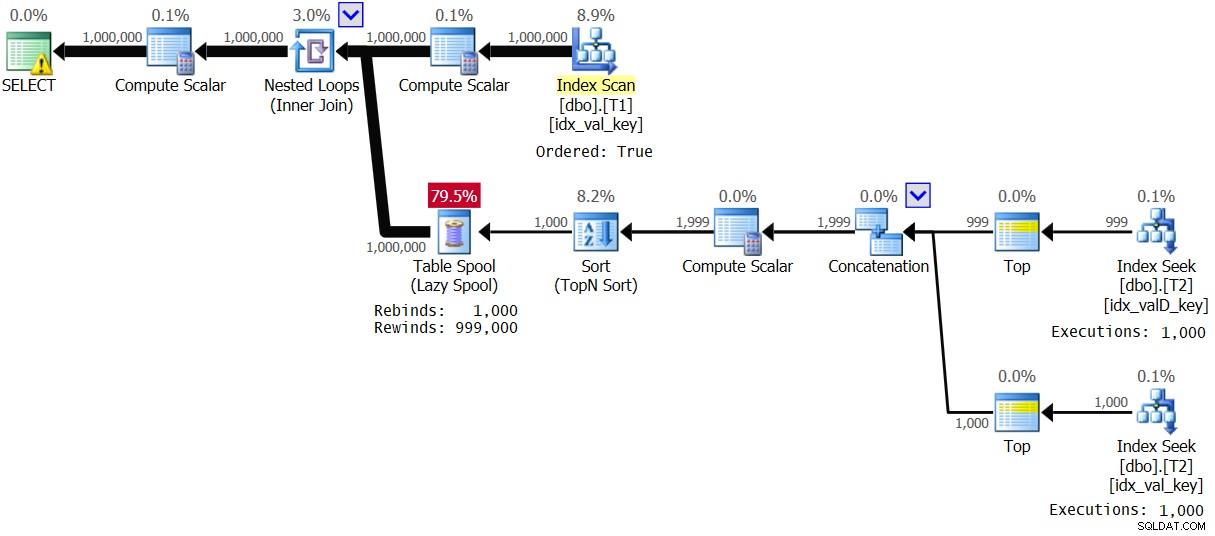 Figuur 4:Plan voor oplossing 2, met waardebereik 1 – 1000
Figuur 4:Plan voor oplossing 2, met waardebereik 1 – 1000
De optimizer besloot een ander plan te gebruiken vanwege de hoge dichtheid in T1.val. Merk op dat de index op T1 in sleutelvolgorde wordt gescand. Dus voor elke eerste keer dat een afzonderlijke T1.val-waarde voorkomt, wordt de binnenste tak van de lus uitgevoerd en wordt het resultaat in een gewone tabelspoel (rebind) gespoold. Vervolgens wordt voor elk niet-eerste voorkomen van de waarde een terugspoeling toegepast. Met 1.000 verschillende waarden wordt de binnenste tak slechts 1.000 keer uitgevoerd. Dit resulteert in uitstekende prestatiestatistieken:
Elapsed: 1.16 sec, CPU: 1.14 sec, logical reads: 23,278
Probeer nu de oplossing uit te voeren met spooling uitgeschakeld:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A
OPTION(QUERYTRACEON 8690); Ik heb het plan weergegeven in figuur 5.
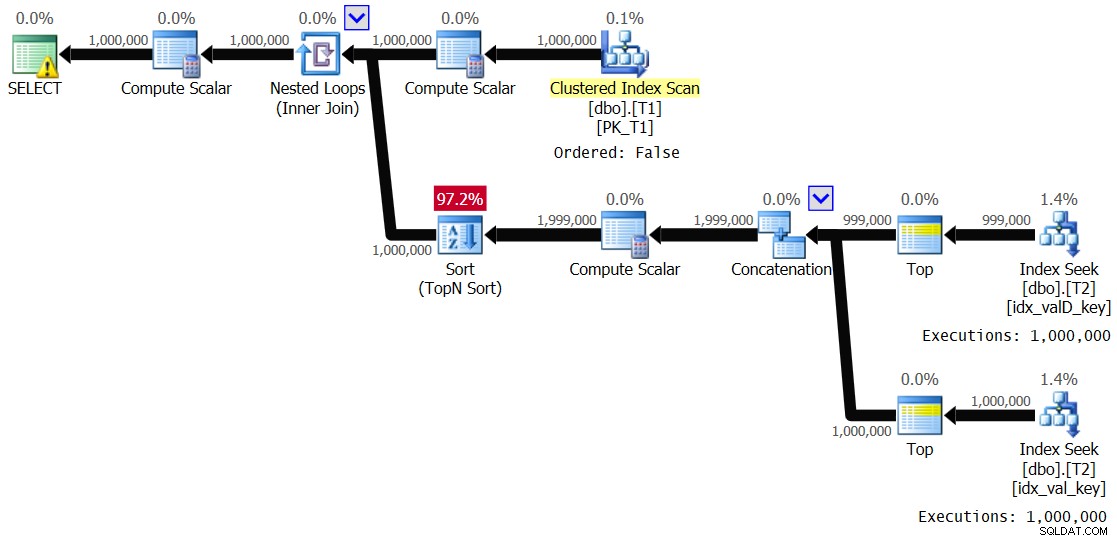 Figuur 5:Plan voor oplossing 2, met waardebereik 1 – 1.000 en spoolen uitgeschakeld
Figuur 5:Plan voor oplossing 2, met waardebereik 1 – 1.000 en spoolen uitgeschakeld
Het is in wezen hetzelfde plan als eerder in figuur 3. De binnenste tak van de lus wordt 1.000.000 keer uitgevoerd. Dit zijn de prestatiestatistieken die ik voor deze uitvoering heb gekregen:
Elapsed: 24.5 sec, CPU: 24.2 sec, logical reads: 8,012,548
Het is duidelijk dat je voorzichtig wilt zijn om spoolen niet uit te schakelen als je een hoge dichtheid in T1.val hebt.
Het leven is goed als uw situatie zo eenvoudig is dat u ondersteunende indexen kunt maken. De realiteit is dat er in de praktijk in sommige gevallen voldoende extra logica in de query zit, waardoor het onmogelijk is om optimale ondersteunende indexen te maken. In dergelijke gevallen zal Oplossing 2 het niet goed doen.
Om de prestaties van Oplossing 2 te demonstreren zonder ondersteunende indexen, vult u T1 en T2 opnieuw in met voorbeeldgegevensinstelling @maxvalT1 en @maxvalT2 tot 10000000 (waardebereik 1 – 10M), en verwijdert u ook de ondersteunende indexen:
DROP INDEX IF EXISTS idx_val_key ON dbo.T1;
DROP INDEX IF EXISTS idx_val_key ON dbo.T2;
DROP INDEX IF EXISTS idx_valD_key ON dbo.T2;
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; Voer Oplossing 2 opnieuw uit, met Inclusief Live Query-statistieken ingeschakeld in SSMS:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; Ik heb het plan weergegeven in figuur 6 voor deze vraag:
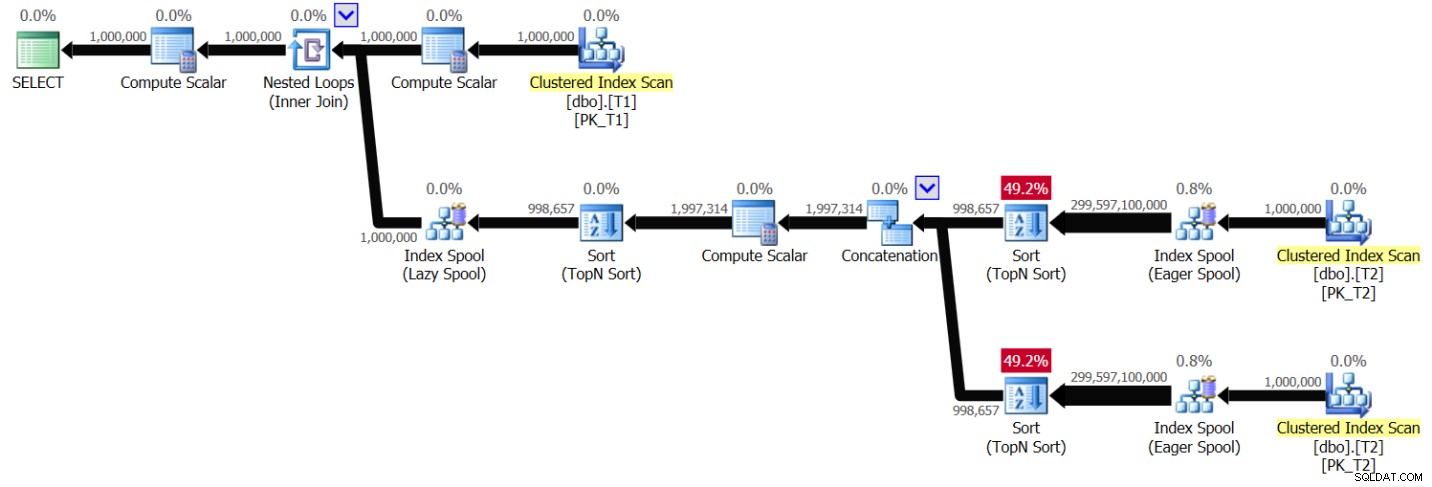 Figuur 6:Plan voor oplossing 2, zonder indexering, met waardebereik 1 – 1.000.000
Figuur 6:Plan voor oplossing 2, zonder indexering, met waardebereik 1 – 1.000.000
U kunt een patroon zien dat erg lijkt op het patroon dat eerder in figuur 1 is getoond, maar deze keer scant het plan T2 twee keer per afzonderlijke T1.val-waarde. Nogmaals, de complexiteit van het plan wordt kwadratisch. Het uitvoeren van de query in SSMS met Include Live Query Statistics ingeschakeld duurde 49,6 seconden om 100 rijen van T1 op mijn laptop te verwerken, wat betekent dat het ongeveer 5,7 dagen zou duren om deze query te voltooien. Dit kan natuurlijk goed nieuws betekenen als je het Guinness-wereldrecord probeert te verbreken voor het bingewatchen van een live-queryplan.
Conclusie
Ik wil Karen Ly van RBC bedanken voor het aanbieden van deze mooie uitdaging voor de beste match. Ik was behoorlijk onder de indruk van haar code om ermee om te gaan, die veel extra logica bevatte die specifiek was voor haar systeem. In dit artikel heb ik redelijk presterende oplossingen laten zien wanneer je in staat bent om optimale ondersteunende indexen te creëren. Maar zoals je kon zien, in gevallen waarin dit geen optie is, zijn de uitvoeringstijden die je krijgt natuurlijk verschrikkelijk. Kun je oplossingen bedenken die het goed doen, zelfs zonder optimale ondersteunende indexen? Wordt vervolgd…