Eerder hebben we een blog gepost over het bereiken van MySQL Failover &Failback op Google Cloud Platform (GCP) en in deze blog zullen we kijken hoe zijn rivaal, Amazon Relational Database Service (RDS), omgaat met failover. We zullen ook bekijken hoe u een failback van uw voormalige masternode kunt uitvoeren, zodat deze teruggaat naar de oorspronkelijke volgorde als master.
Bij het vergelijken van de tech-gigantische openbare clouds die beheerde relationele databaseservices ondersteunen, is Amazon de enige die een alternatieve optie biedt (samen met MySQL/MariaDB, PostgreSQL, Oracle en SQL Server) om te leveren zijn eigen soort databasebeheer genaamd Amazon Aurora. Voor degenen die niet bekend zijn met Aurora, het is een volledig beheerde relationele database-engine die compatibel is met MySQL en PostgreSQL. Aurora maakt deel uit van de beheerde databaseservice Amazon RDS, een webservice waarmee u eenvoudig een relationele database in de cloud kunt opzetten, bedienen en schalen.
Waarom zou u failover of failback moeten uitvoeren?
Het ontwerpen van een groot systeem dat fouttolerant, zeer beschikbaar en zonder Single-Point-Of-Failure (SPOF) is, vereist goede tests om te bepalen hoe het zou reageren als er iets misgaat.
Als u zich zorgen maakt over hoe uw systeem zou presteren bij het reageren op de foutdetectie, isolatie en herstel (FDIR) van uw systeem, dan zouden failover en failback van groot belang moeten zijn.
Database-failover in Amazon RDS
Failover vindt automatisch plaats (aangezien handmatige failover omschakeling wordt genoemd). Zoals besproken in een vorige blog, treedt de noodzaak van een failover op zodra uw huidige databasemaster een netwerkstoring of abnormale beëindiging van het hostsysteem ervaart. Failover schakelt het naar een stabiele staat van redundantie of naar een stand-by computerserver, systeem, hardwarecomponent of netwerk.
In Amazon RDS hoeft u dit niet te doen en hoeft u het ook niet zelf te controleren, aangezien RDS een beheerde databaseservice is (wat betekent dat Amazon de taak voor u afhandelt). Deze service beheert zaken als hardwareproblemen, back-up en herstel, software-updates, opslagupgrades en zelfs softwarepatches. Daar praten we later in deze blog over.
Database-failback in Amazon RDS
In de vorige blog hebben we ook besproken waarom je zou moeten failbacken. In een typische gerepliceerde omgeving moet de master krachtig genoeg zijn om een enorme belasting te dragen, vooral wanneer de werkbelasting hoog is. Uw hoofdconfiguratie vereist adequate hardwarespecificaties om ervoor te zorgen dat het schrijfbewerkingen kan verwerken, replicatiegebeurtenissen kan genereren, kritieke leesbewerkingen kan verwerken, enz. op een stabiele manier. Wanneer failover vereist is tijdens noodherstel (of voor onderhoud), is het niet ongebruikelijk dat u bij het promoten van een nieuwe master inferieure hardware gebruikt. Deze situatie kan tijdelijk in orde zijn, maar op de lange termijn moet de aangewezen master worden teruggehaald om de replicatie te leiden nadat deze als gezond wordt beschouwd (of als het onderhoud is voltooid).
In tegenstelling tot failover, vinden failback-bewerkingen meestal plaats in een gecontroleerde omgeving met behulp van omschakeling. Het wordt zelden gedaan in de paniekmodus. Deze aanpak geeft uw engineers voldoende tijd om zorgvuldig te plannen en de oefening te oefenen om een soepele overgang te garanderen. Het belangrijkste doel is om eenvoudig de goede, oude meester terug te brengen naar de nieuwste staat en de replicatie-instellingen te herstellen naar de oorspronkelijke topologie. Aangezien we te maken hebben met Amazon RDS, hoeft u zich geen zorgen te maken over dit soort problemen, aangezien het een beheerde service is waarbij de meeste taken door Amazon worden afgehandeld.
Hoe gaat Amazon RDS om met databasefailover?
Wanneer u uw Amazon RDS-knooppunten implementeert, kunt u uw databasecluster instellen met Multi-Availability Zone (AZ) of naar een Single-Availability Zone. Laten we eens kijken hoe de failover wordt verwerkt.
Wat is een Multi-AZ-configuratie?
Als zich een ramp of ramp voordoet, zoals ongeplande uitval of natuurrampen waarbij uw database-instanties worden getroffen, schakelt Amazon RDS automatisch over naar een stand-by-replica in een andere beschikbaarheidszone. Dit AZ bevindt zich meestal in een andere tak van het datacenter, vaak ver van de huidige beschikbaarheidszone waar de instanties zich bevinden. Deze AZ's zijn zeer beschikbare, ultramoderne faciliteiten die uw database-instances beschermen. Failover-tijden zijn afhankelijk van de voltooiing van de installatie, die vaak gebaseerd is op de grootte en activiteit van de database, evenals andere omstandigheden die aanwezig waren op het moment dat de primaire DB-instance niet meer beschikbaar was.
Failover-tijden zijn doorgaans 60-120 seconden. Ze kunnen echter langer zijn, omdat grote transacties of een langdurig herstelproces de failovertijd kunnen verlengen. Wanneer de failover is voltooid, kan het ook langer duren voordat de RDS-console (UI) de nieuwe beschikbaarheidszone weerspiegelt.
Wat is een Single-AZ Setup?
Single-AZ setups mogen alleen worden gebruikt voor uw database-instances als uw RTO (Recovery Time Objective) en RPO (Recovery Point Objective) hoog genoeg zijn om dit toe te staan. Aan het gebruik van een Single-AZ zijn risico's verbonden, zoals grote uitvaltijden die de bedrijfsvoering kunnen verstoren.
Veelvoorkomende scenario's voor RDS-storingen
De hoeveelheid uitvaltijd is afhankelijk van het type storing. Laten we eens kijken wat dit zijn en hoe het herstel van de instantie wordt afgehandeld.
Herstelbare instantiefout
Een Amazon RDS-instantiefout treedt op wanneer de onderliggende EC2-instantie een fout vertoont. Bij het optreden zal AWS een gebeurtenismelding activeren en een waarschuwing naar u sturen met behulp van Amazon RDS Event Notifications. Dit systeem gebruikt AWS Simple Notification Service (SNS) als waarschuwingsprocessor.
RDS zal automatisch proberen een nieuwe instantie te starten in dezelfde beschikbaarheidszone, het EBS-volume koppelen en herstel proberen. In dit scenario is de RTO doorgaans minder dan 30 minuten. RPO is nul omdat het EBS-volume kon worden hersteld. Het EBS-volume bevindt zich in één beschikbaarheidszone en dit type herstel vindt plaats in dezelfde beschikbaarheidszone als het oorspronkelijke exemplaar.
Niet-herstelbare instantiefouten of EBS-volumefouten
Voor mislukt RDS-instanceherstel (of als het onderliggende EBS-volume een storing in gegevensverlies heeft) is point-in-time recovery (PITR) vereist. PITR wordt niet automatisch afgehandeld door Amazon, dus je moet ofwel een script maken om het te automatiseren (met AWS Lambda) of het handmatig doen.
De RTO-timing vereist het opstarten van een nieuwe Amazon RDS-instantie, die een nieuwe DNS-naam krijgt zodra deze is gemaakt, en het toepassen van alle wijzigingen sinds de laatste back-up.
De RPO duurt doorgaans 5 minuten, maar u kunt deze vinden door RDS:describe-db-instances:LatestRestorableTime aan te roepen. De tijd kan variëren van 10 minuten tot uren, afhankelijk van het aantal logs dat moet worden aangebracht. Het kan alleen worden bepaald door te testen, omdat het afhangt van de grootte van de database, het aantal wijzigingen dat is aangebracht sinds de laatste back-up en de werkbelasting van de database. Aangezien de back-ups en transactielogboeken worden opgeslagen in Amazon S3, kan dit herstel plaatsvinden in elke ondersteunde beschikbaarheidszone in de regio.
Zodra de nieuwe instantie is gemaakt, moet u de naam van het eindpunt van uw client bijwerken. Je hebt ook de mogelijkheid om het te hernoemen naar de eindpuntnaam van de oude DB-instantie (maar daarvoor moet je de oude mislukte instantie verwijderen), maar dat maakt het onmogelijk om de hoofdoorzaak van het probleem te achterhalen.
Verstoringen in de beschikbaarheidszone
Verstoringen van de beschikbaarheidszone kunnen tijdelijk zijn en zijn zeldzaam, maar als de AZ-storing meer permanent is, wordt de instantie in een mislukte staat gezet. Het herstel zou werken zoals eerder beschreven en een nieuwe instantie zou in een andere AZ kunnen worden gemaakt met behulp van herstel op een bepaald tijdstip. Deze stap moet handmatig of door middel van scripts worden uitgevoerd. De strategie voor dit type herstelscenario moet deel uitmaken van uw grotere rampenherstelplannen (DR).
Als de storing in de beschikbaarheidszone tijdelijk is, is de database niet beschikbaar, maar blijft deze beschikbaar. Je bent verantwoordelijk voor monitoring op applicatieniveau (met behulp van Amazon's of tools van derden) om dit soort scenario's te detecteren. Als dit gebeurt, kunt u wachten tot de beschikbaarheidszone is hersteld, of u kunt ervoor kiezen om de instantie te herstellen naar een andere beschikbaarheidszone met herstel op een bepaald tijdstip.
De RTO is de tijd die nodig is om een nieuwe RDS-instantie op te starten en vervolgens alle wijzigingen sinds de laatste back-up toe te passen. De RPO kan langer zijn, tot het moment dat de storing in de beschikbaarheidszone optrad.
Failover en failback testen op Amazon RDS
We hebben een Amazon RDS Aurora gemaakt en ingesteld met db.r4.large met een Multi-AZ-implementatie (waardoor een Aurora-replica/lezer in een andere AZ wordt gemaakt) die alleen toegankelijk is via EC2. U moet ervoor zorgen dat u deze optie kiest bij het maken als u van plan bent om Amazon RDS als failover-mechanisme te gebruiken.
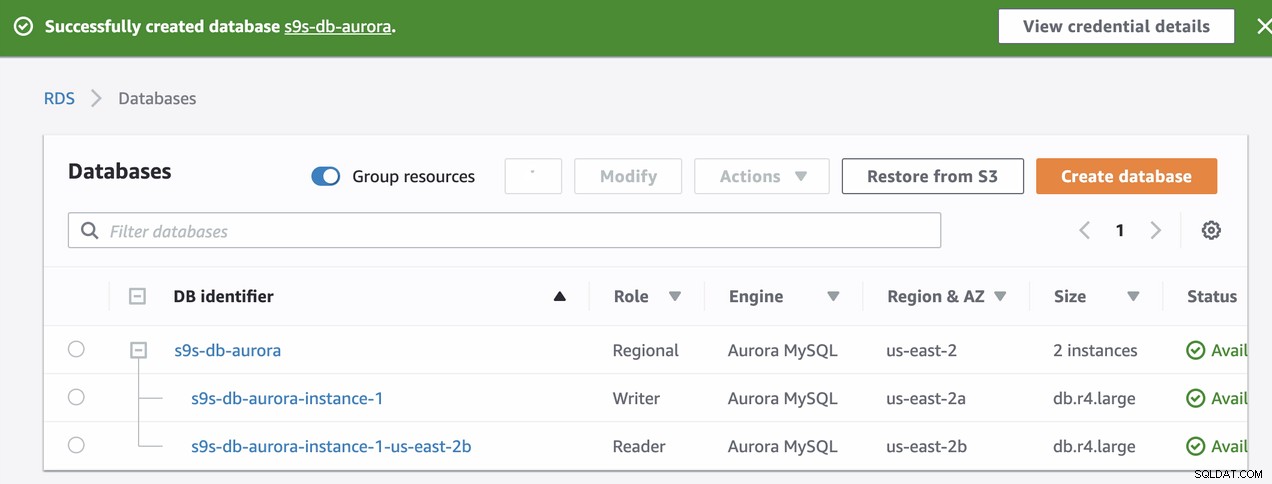
Tijdens de inrichting van onze RDS-instantie duurde het ongeveer 11 minuten voordat de instances werden beschikbaar en toegankelijk. Hieronder is een screenshot van de nodes die beschikbaar zijn in RDS na het maken:
Deze twee knooppunten hebben hun eigen toegewezen eindpuntnamen, die we zullen gebruiken om verbinding te maken vanuit het perspectief van de klant. Controleer het eerst en controleer de onderliggende hostnaam voor elk van deze knooppunten. Om dit te controleren, kunt u deze bash-opdracht hieronder uitvoeren en de hostnamen/eindpuntnamen dienovereenkomstig vervangen:
example@sqldat.com:~# host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done;
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Het resultaat wordt als volgt verduidelijkt,
s9s-db-aurora-instance-1 = s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-0-94 (read-write)
s9s-db-aurora-instance-1-us-east-2b = s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-1-139 (read-only)Amazon RDS-failover simuleren
Laten we nu een crash simuleren om een failover te simuleren voor de Amazon RDS Aurora-schrijverinstantie, namelijk s9s-db-aurora-instance-1 met eindpunt s9s-db-aurora.cluster-cmu8qdlvkepg.us -east-2.rds.amazonaws.com.
Om dit te doen, maakt u verbinding met uw writer-instantie via de opdrachtprompt van de mysql-client en geeft u de onderstaande syntaxis op:
ALTER SYSTEM SIMULATE percentage_of_failure PERCENT DISK FAILURE [ IN DISK index | NODE index ]
FOR INTERVAL quantity [ YEAR | QUARTER | MONTH | WEEK| DAY | HOUR | MINUTE | SECOND ];Het uitgeven van deze opdracht heeft zijn Amazon RDS-hersteldetectie en werkt vrij snel. Hoewel de zoekopdracht voor testdoeleinden is, kan het verschillen wanneer dit gebeurt in een feitelijke gebeurtenis. Mogelijk bent u geïnteresseerd in meer informatie over het testen van een instance-crash in hun documentatie. Bekijk hieronder hoe we eindigen:
mysql> ALTER SYSTEM SIMULATE 100 PERCENT DISK FAILURE FOR INTERVAL 3 MINUTE;
Query OK, 0 rows affected (0.01 sec)Het uitvoeren van het bovenstaande SQL-commando betekent dat het een schijffout moet simuleren gedurende ten minste 3 minuten. Ik bewaakte het tijdstip waarop de simulatie begon en het duurde ongeveer 18 seconden voordat de failover begon.
Zie hieronder hoe RDS omgaat met de simulatiefout en de failover,
Tue Sep 24 10:06:29 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
….
…..
………..
Tue Sep 24 10:06:44 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
……..
………..
Tue Sep 24 10:06:51 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
….
………..
…………………
Tue Sep 24 10:07:13 UTC 2019
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+De resultaten van deze simulatie zijn behoorlijk interessant. Laten we deze een voor een bekijken.
- Om ongeveer 10:06:29 begon ik de simulatiequery uit te voeren zoals hierboven vermeld.
- Rond 10:06:44, laat het zien dat eindpunt s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com met toegewezen hostnaam van ip-10-20-1- 139 waar het in feite de alleen-lezen-instantie is, werd ontoegankelijk, maar de simulatieopdracht werd uitgevoerd onder de lees-schrijfinstantie.
- Om ongeveer 10:06:51 laat het zien dat eindpunt s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com met toegewezen hostnaam van ip-10-20-1- 139 is geactiveerd, maar heeft een lees-schrijfstatus. Houd er rekening mee dat de variabele innodb_read_only, voor door Aurora MySQL beheerde instanties, dit de id is om te bepalen of de host een lees-schrijf- of alleen-lezen knooppunt is en Aurora werkt ook alleen op de InnoDB-opslagengine voor MySQL-compatibele instanties.
- Om ongeveer 10:07:13 is de volgorde gewijzigd. Dit betekent dat de failover is uitgevoerd en dat de instances zijn toegewezen aan de toegewezen eindpunten.
Bekijk het resultaat hieronder dat wordt weergegeven in de RDS-console:
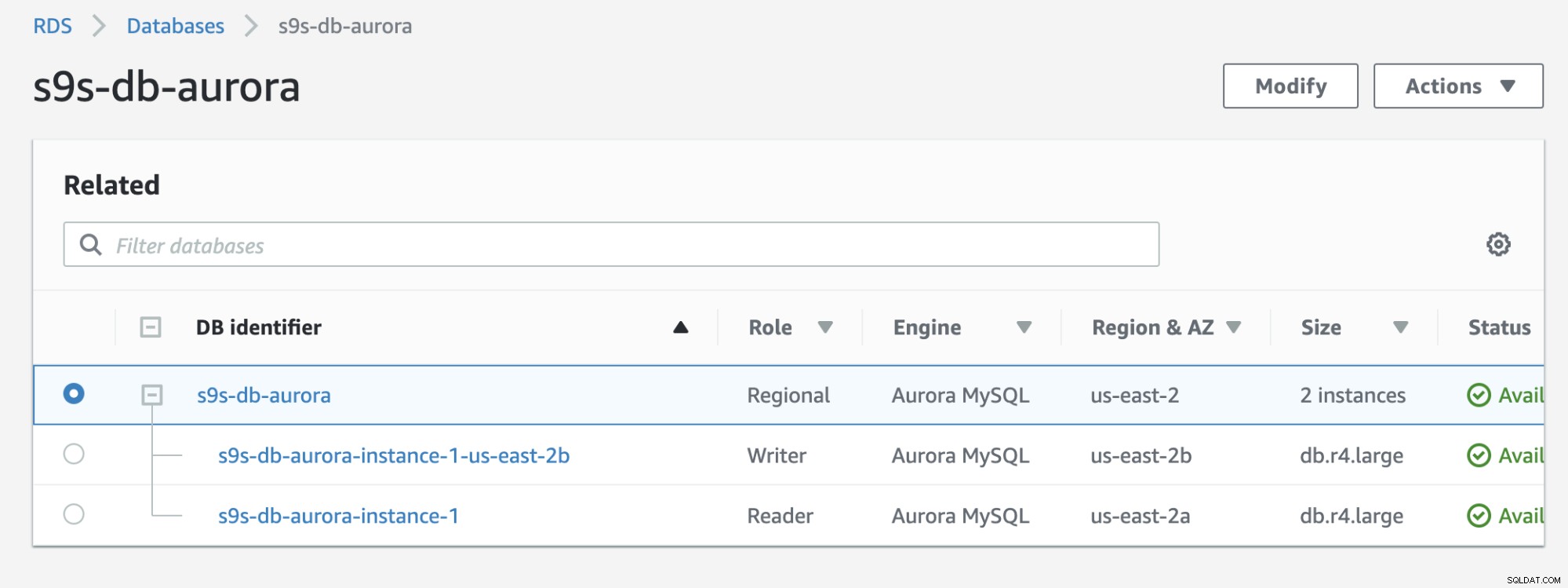
Als je het vergelijkt met de eerdere, is de s9s-db-aurora- instance-1 was een lezer, maar werd na de failover gepromoot als schrijver. Het proces, inclusief de test, nam ongeveer 44 seconden in beslag om de taak te voltooien, maar de failover toont aan dat het bijna 30 seconden duurt. Dat is indrukwekkend en snel voor een failover, vooral als je bedenkt dat dit een beheerde servicedatabase is; wat betekent dat u zich geen zorgen hoeft te maken over hardware- of onderhoudsproblemen.
Een failback uitvoeren in Amazon RDS
Failback in Amazon RDS is vrij eenvoudig. Laten we, voordat we het doornemen, een nieuwe lezerreplica toevoegen. We hebben een optie nodig om te testen en te identificeren uit welk knooppunt AWS RDS zou kiezen wanneer het probeert een failback naar de gewenste master (of failback naar de vorige master) uit te voeren en om te zien of het het juiste knooppunt selecteert op basis van prioriteit. De huidige lijst met instanties vanaf nu en de eindpunten worden hieronder weergegeven.
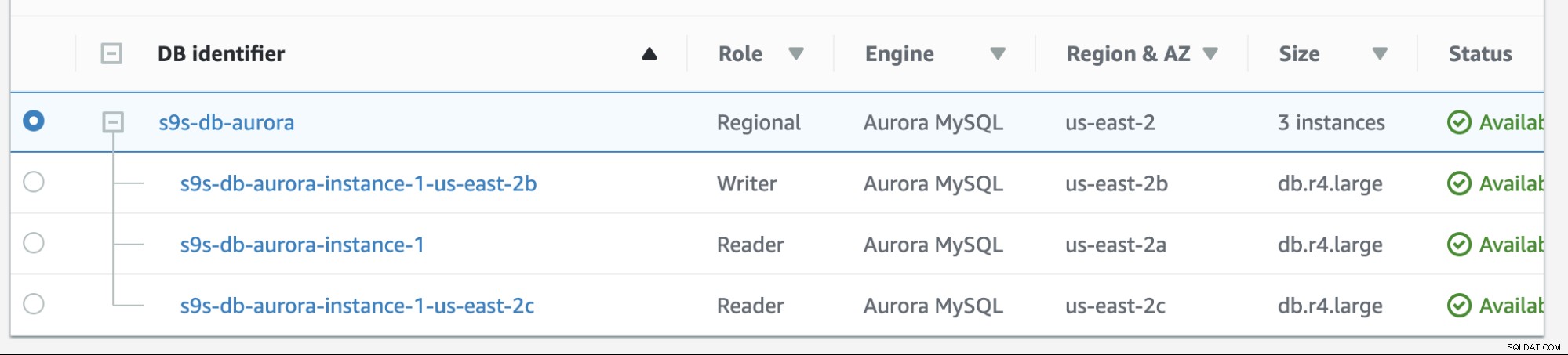

De nieuwe replica bevindt zich op us-east-2c AZ met db-hostnaam van ip-10-20-2-239.
We zullen proberen een failback uit te voeren met de instantie s9s-db-aurora-instance-1 als het gewenste failback-doel. In deze opstelling hebben we twee lezersinstanties. Om ervoor te zorgen dat het juiste knooppunt wordt opgehaald tijdens de failover, moet u vaststellen of prioriteit of beschikbaarheid bovenaan staat (tier-0> tier-1> tier-2 enzovoort tot tier-15). Dit kan worden gedaan door de instantie te wijzigen of tijdens het maken van de replica.
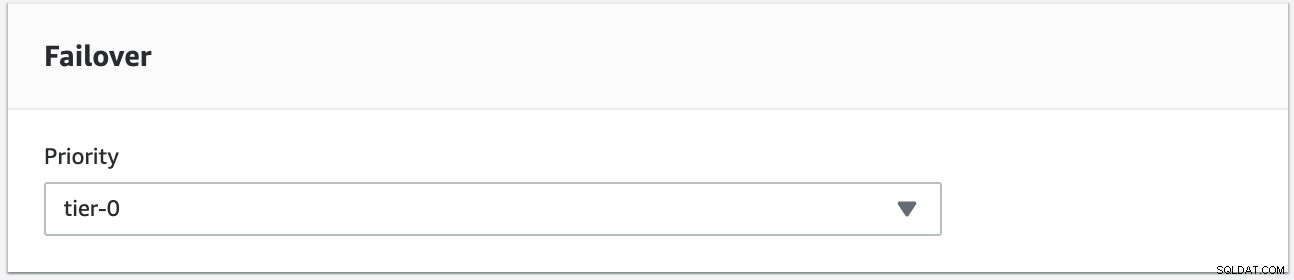
U kunt dit verifiëren in uw RDS-console.
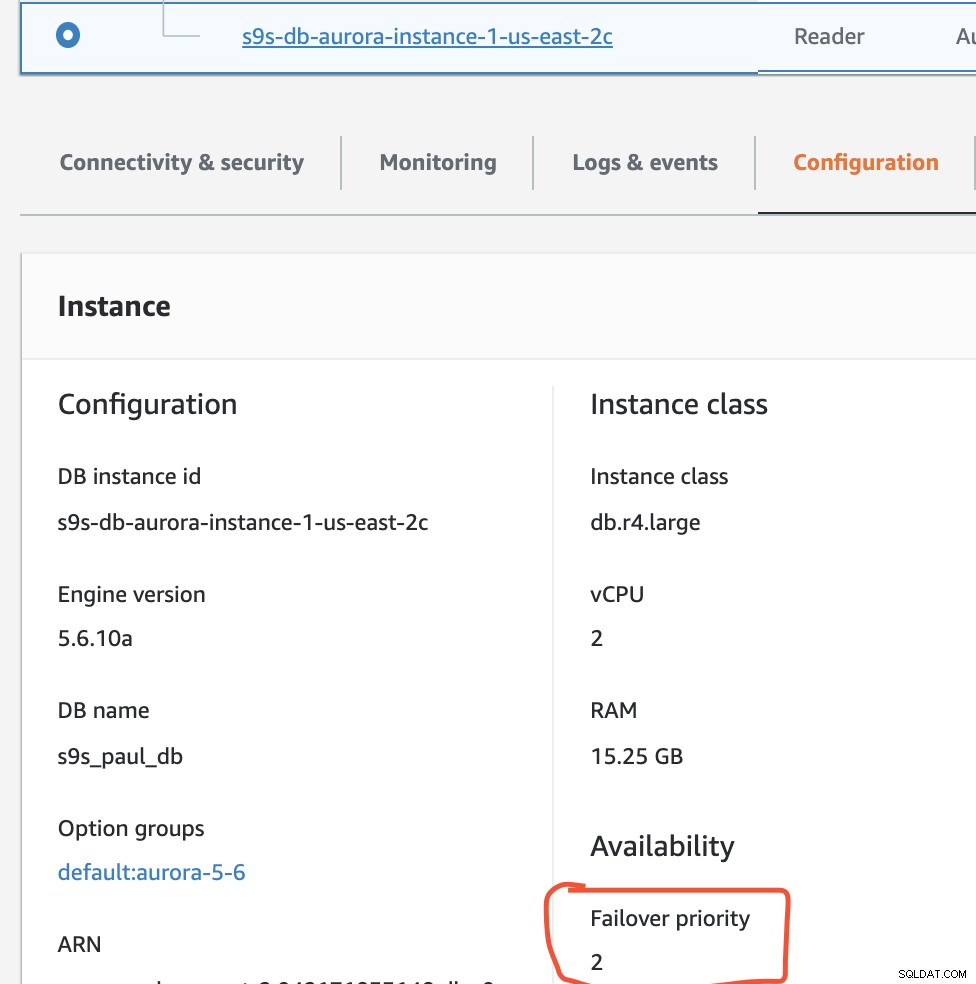
In deze configuratie heeft s9s-db-aurora-instance-1 prioriteit =0 (en is een lees-replica), s9s-db-aurora-instance-1-us-east-2b heeft prioriteit =1 (en is de huidige schrijver), en s9s-db-aurora-instance-1-us- east-2c heeft prioriteit =2 (en is ook een lees-replica). Laten we eens kijken wat er gebeurt als we een failback proberen.
Je kunt de status controleren met dit commando.
$ host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); while true; do echo -e "\n==========================================="; date; echo -e "===========================================\n"; for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done; sleep 1; done;Nadat de failover is geactiveerd, wordt er een failback uitgevoerd naar ons gewenste doel, namelijk het knooppunt s9s-db-aurora-instance-1.
===========================================
Tue Sep 24 13:30:59 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
…
……
………
===========================================
Tue Sep 24 13:31:35 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
…..
===========================================
Tue Sep 24 13:31:38 UTC 2019
===========================================
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+De failback-poging begon om 13:30:59 en eindigde rond 13:31:38 (bijna 30 seconden). Het eindigt ~ 32 seconden op deze test, wat nog steeds snel is.
Ik heb de failover/failback meerdere keren geverifieerd en het heeft de lees-schrijfstatus consequent uitgewisseld tussen instanties s9s-db-aurora-instance-1 en s9s-db-aurora-instance-1- us-oost-2b. Hierdoor blijft s9s-db-aurora-instance-1-us-east-2c ongeselecteerd, tenzij beide knooppunten problemen ondervinden (wat zeer zeldzaam is omdat ze zich allemaal in verschillende AZ's bevinden).
Tijdens de failover/failback-pogingen gaat RDS tijdens de failover in een snel overgangstempo van ongeveer 15 - 25 seconden (wat erg snel is). Houd er rekening mee dat we geen enorme gegevensbestanden hebben opgeslagen op deze instantie, maar het is nog steeds behoorlijk indrukwekkend, aangezien er verder niets te beheren is.
Conclusie
Het uitvoeren van een Single-AZ brengt gevaar met zich mee bij het uitvoeren van een failover. Met Amazon RDS kun je je Single-AZ aanpassen en converteren naar een Multi-AZ-compatibele installatie, hoewel dit wat kosten met zich meebrengt. Single-AZ is misschien prima als je akkoord gaat met een hogere RTO en RPO-tijd, maar wordt zeker niet aanbevolen voor bedrijfskritieke bedrijfsapplicaties met veel verkeer.
Met Multi-AZ kun je failover en failback op Amazon RDS automatiseren, zodat je je tijd kunt besteden aan het afstemmen of optimaliseren van zoekopdrachten. Dit verlicht veel problemen waarmee DevOps of DBA's worden geconfronteerd.
Hoewel Amazon RDS in sommige organisaties een dilemma kan veroorzaken (omdat het niet platformonafhankelijk is), is het toch het overwegen waard; vooral als uw toepassing een DR-plan voor de lange termijn vereist en u zich geen zorgen wilt maken over hardware- en capaciteitsplanning.