Er zijn tegenwoordig talloze cloudproviders. Ze kunnen klein of groot zijn, lokaal of met datacenters verspreid over de hele wereld. Veel van deze cloudproviders bieden een soort beheerde relationele database-oplossing. De ondersteunde databases zijn meestal MySQL of PostgreSQL of een andere soort relationele database.
Bij het ontwerpen van een database-infrastructuur is het belangrijk om uw zakelijke behoeften te begrijpen en te beslissen wat voor soort beschikbaarheid u moet bereiken.
In deze blogpost gaan we in op hoge-beschikbaarheidsopties voor MySQL-gebaseerde oplossingen van een van de grootste cloudproviders:Google Cloud Platform.
Een zeer beschikbare omgeving implementeren met GCP SQL-instantie
Voor deze blog willen we een heel eenvoudige omgeving - één database, met misschien één of twee replica's. We willen gemakkelijk een failover kunnen uitvoeren en operaties zo snel mogelijk kunnen herstellen als de master uitvalt. We gebruiken MySQL 5.7 als de versie naar keuze en beginnen met de instantie-implementatiewizard:
We moeten dan het root-wachtwoord maken, de instantienaam instellen en bepalen waar het moet worden geplaatst:
Vervolgens zullen we kijken naar de configuratie-opties:
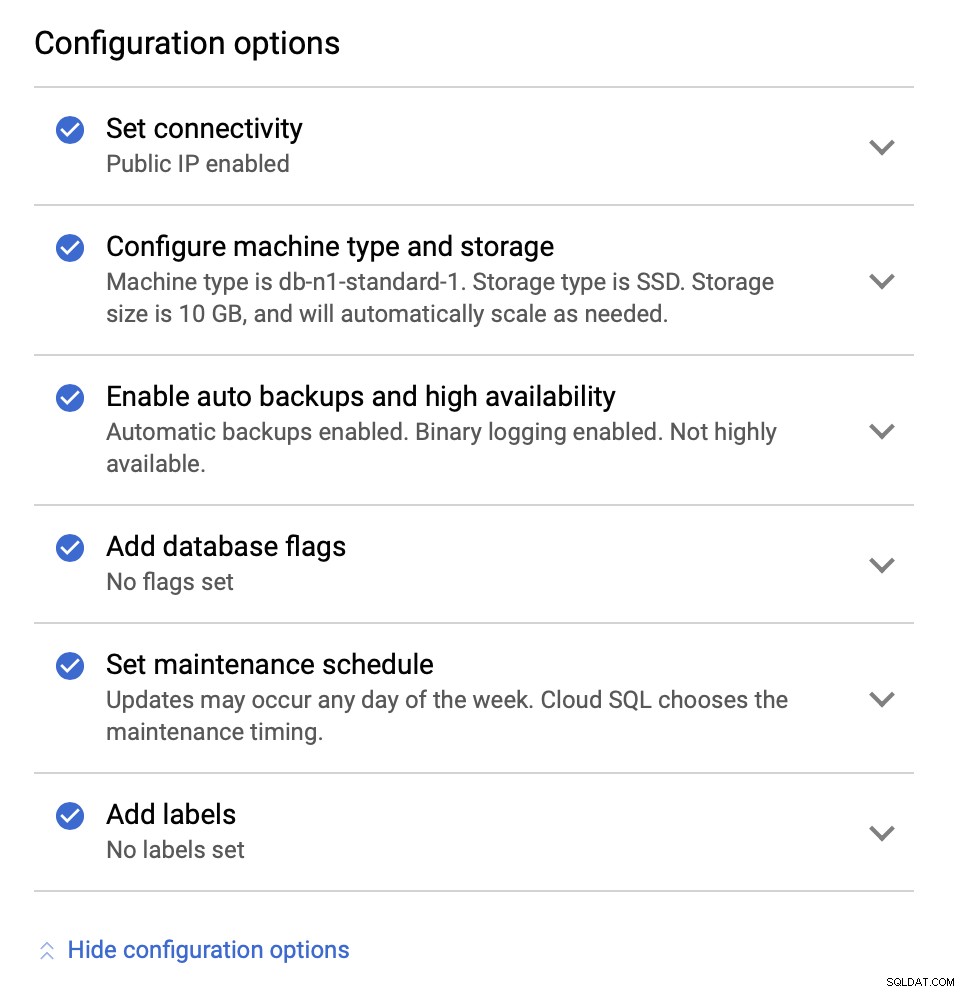
We kunnen wijzigingen aanbrengen in de instantiegrootte (we gaan voor db-n1-standard-4), opslag- en onderhoudsschema. Wat voor ons het belangrijkst is in deze opzet, zijn de opties voor hoge beschikbaarheid:
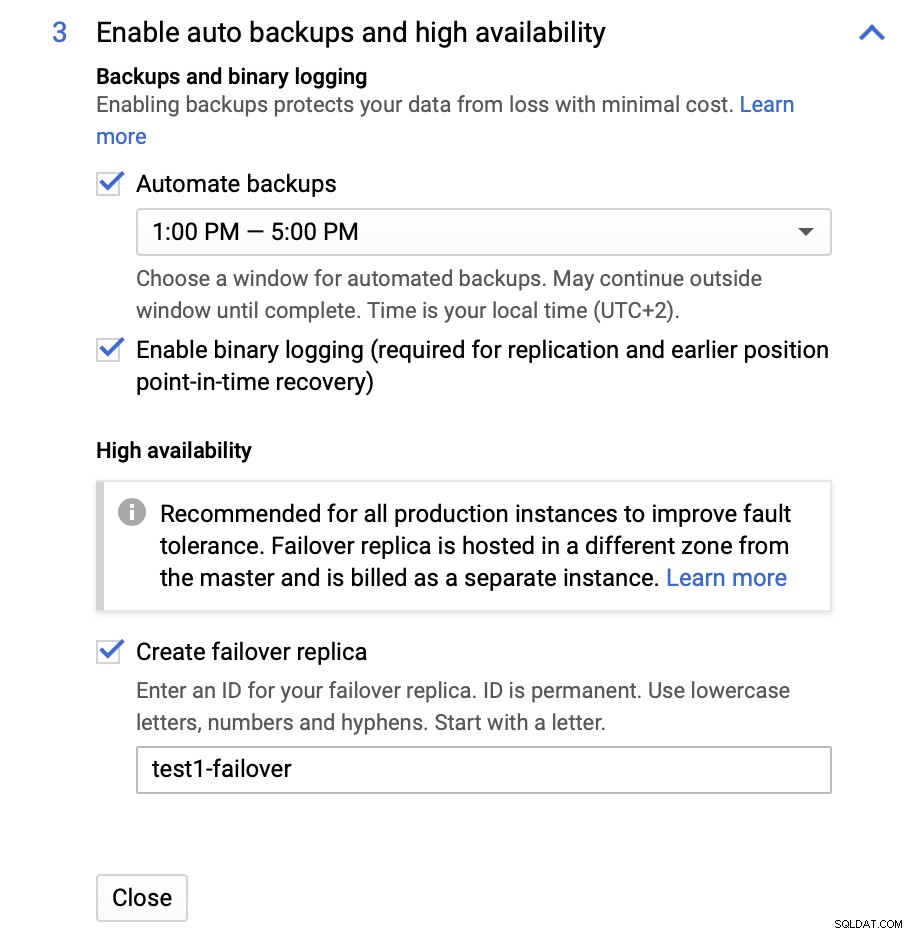
Hier kunnen we ervoor kiezen om een failover-replica te maken. Deze replica wordt gepromoveerd tot een master als de originele master faalt.

Laten we, nadat we de installatie hebben geïmplementeerd, een replicatieslave toevoegen:
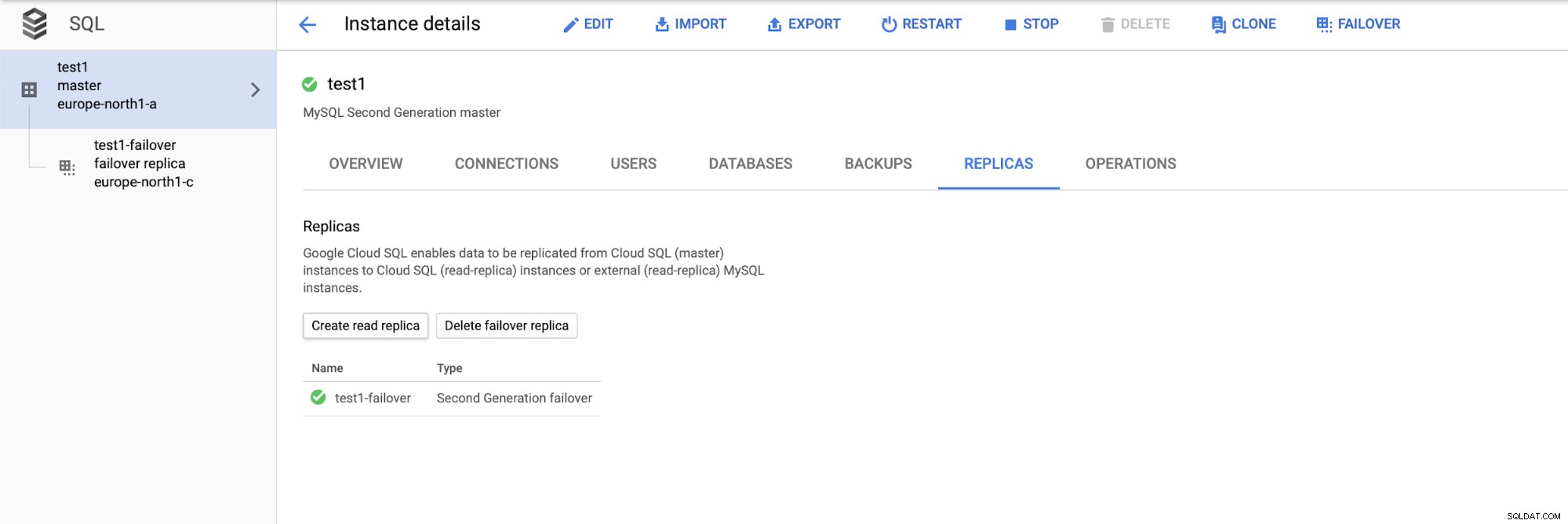
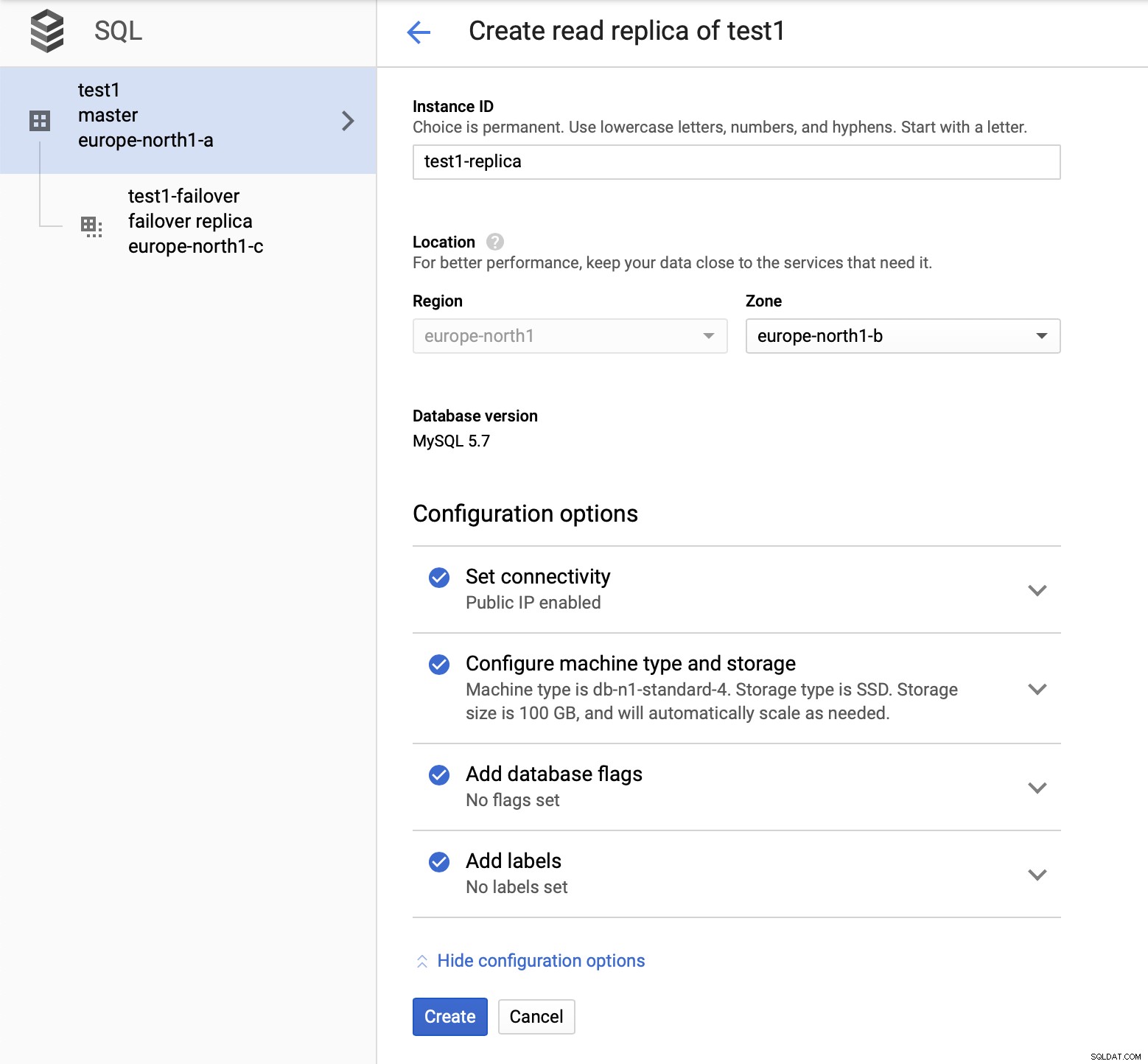
Zodra het proces van het toevoegen van de replica is voltooid, zijn we klaar voor een aantal testen. We gaan testwerkbelasting uitvoeren met Sysbench op onze master, failover-replica en leesreplica om te zien hoe dit uitpakt. We zullen drie exemplaren van Sysbench uitvoeren, waarbij we de eindpunten voor alle drie de typen knooppunten gebruiken.
Vervolgens activeren we de handmatige failover via de gebruikersinterface:
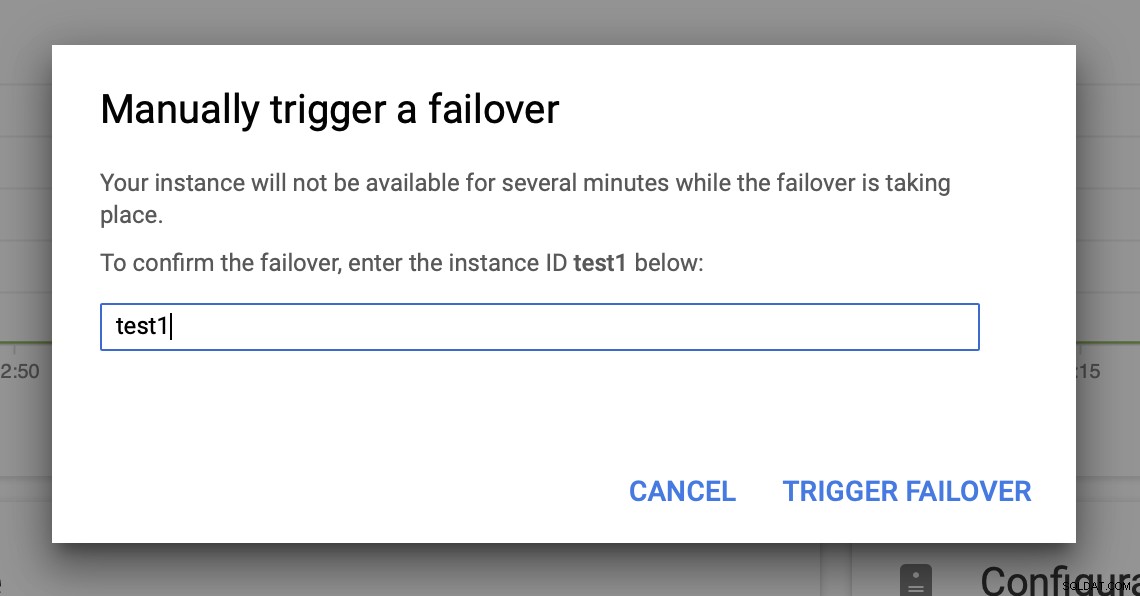
MySQL-failover testen op Google Cloud Platform?
Ik ben op dit punt gekomen zonder enige gedetailleerde kennis van hoe de SQL-knooppunten in GCP werken. Ik had echter enkele verwachtingen op basis van eerdere MySQL-ervaring en wat ik heb gezien bij de andere cloudproviders. Om te beginnen zou de failover naar het failover-knooppunt zeer snel moeten zijn. Wat we zouden willen is om de replicatieslaves beschikbaar te houden, zonder de noodzaak van een rebuild. We zouden ook graag willen zien hoe snel we de failover een tweede keer kunnen uitvoeren (omdat het niet ongebruikelijk is dat het probleem zich van de ene database naar de andere verspreidt).
Wat we hebben vastgesteld tijdens onze tests...
- Bij een failover kwam de master binnen 75 - 80 seconden weer beschikbaar.
- Failover-replica was 5-6 minuten niet beschikbaar.
- Leesreplica was beschikbaar tijdens het failoverproces, maar werd 55 - 60 seconden nadat de failoverreplica beschikbaar kwam niet meer beschikbaar
Waar we niet zeker van zijn...
Wat gebeurt er als de failover-replica niet beschikbaar is? Op basis van de tijd lijkt het erop dat de failover-replica opnieuw wordt opgebouwd. Dit is logisch, maar dan zou de hersteltijd sterk gerelateerd zijn aan de grootte van de instantie (vooral I/O-prestaties) en de grootte van het gegevensbestand.
Wat gebeurt er met de leesreplica nadat de failoverreplica opnieuw zou zijn opgebouwd? Oorspronkelijk was de leesreplica verbonden met de master. Wanneer de master mislukt, verwachten we dat de leesreplica een verouderde weergave van de gegevensset biedt. Zodra de nieuwe master verschijnt, moet deze via replicatie opnieuw verbinding maken met de instantie (die vroeger een failover-replica was en die is gepromoveerd tot master). Er is geen minuut downtime nodig wanneer CHANGE MASTER wordt uitgevoerd.
Belangrijker is dat er tijdens het failoverproces geen manier is om nog een failover uit te voeren (wat logisch is):
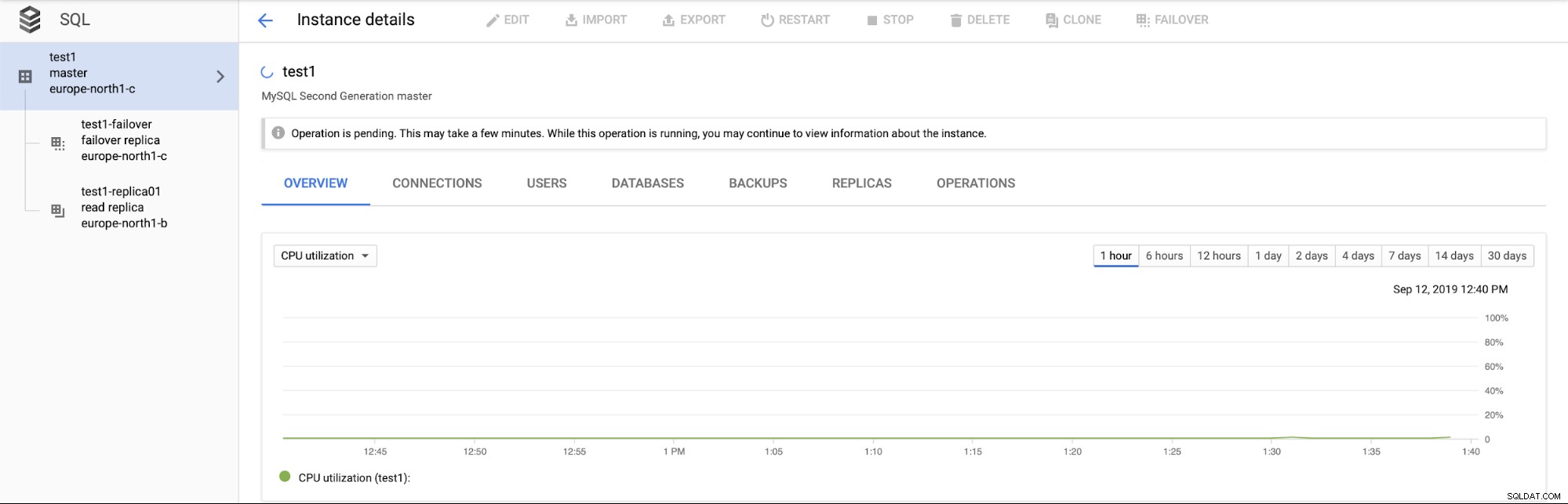
Het is ook niet mogelijk om leesreplica te promoten (wat niet per se logisch is) - we verwachten dat we op elk moment leesreplica's kunnen promoten).

Het is belangrijk op te merken dat u vertrouwt op de gelezen replica's om een hoge beschikbaarheid te bieden (zonder een failover-replica te maken) is geen haalbare oplossing. U kunt een leesreplica promoveren tot master, maar er wordt dan een nieuw cluster gemaakt; los van de rest van de knooppunten.
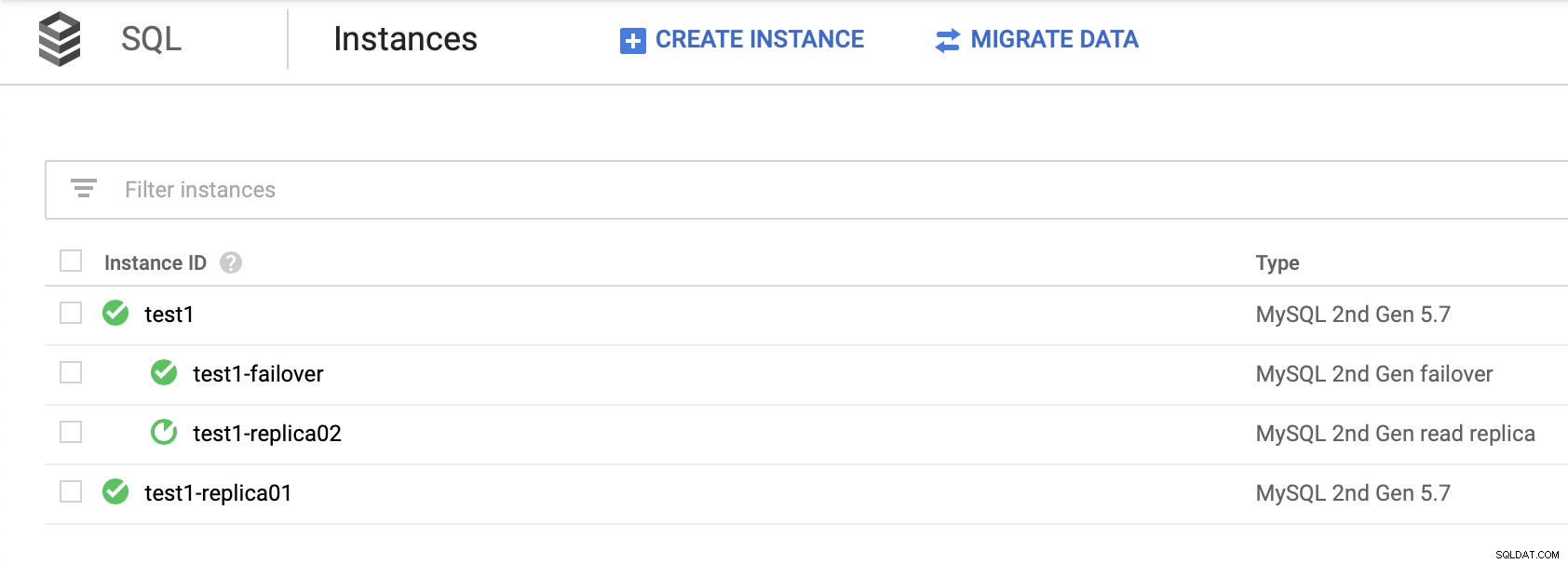
Er is geen manier om uw andere replica's van het nieuwe cluster te slaven. De enige manier om dit te doen zou zijn om nieuwe replica's te maken, maar dit is een tijdrovend proces. Het is ook vrijwel onbruikbaar, waardoor de failover-replica de enige echte optie is voor hoge beschikbaarheid voor SQL-knooppunten in Google Cloud Platform.
Conclusie
Hoewel het mogelijk is om een zeer beschikbare omgeving voor SQL-knooppunten in GCP te maken, is de master ongeveer anderhalve minuut niet beschikbaar. Het hele proces (inclusief het opnieuw opbouwen van de failover-replica en enkele acties op de leesreplica's) duurde enkele minuten. Gedurende die tijd waren we niet in staat om een extra failover te activeren, noch konden we een leesreplica promoten.
Hebben we GCP-gebruikers? Hoe bereik je een hoge beschikbaarheid?