In 2014 begon ik hier een reeks blogposts om te praten over specifieke soorten wachten en wat ze wel en niet betekenen. Dat bracht me op het idee om de wacht- en vergrendelingsbibliotheken te maken die ik onderhoud (hierover later meer).
Als je dit leest en denkt "waar heeft hij het over?" dan is dit bericht voor jou. Ik ga je voorstellen aan wachtstatistieken en uitleggen hoe belangrijk ze zijn voor het oplossen van problemen met de werkbelastingprestaties in SQL Server.
Planning
De uitvoering van de interne code van SQL Server wordt gedaan met behulp van een mechanisme genaamd threads . Elke thread kan SQL Server-code uitvoeren en meerdere threads coördineren samen wanneer een query parallel wordt uitgevoerd. Deze threads worden gemaakt wanneer SQL Server wordt gestart, afhankelijk van het aantal processorcores dat beschikbaar is voor gebruik door SQL Server.
Discussies worden op een planner geplaatst wanneer een query begint, met één planner per processorkern, en ga niet van die planner af totdat de query is voltooid. Een planner heeft drie basis 'onderdelen':
- De verwerker , die precies één thread heeft die momenteel code uitvoert.
- De kelnerlijst , die alle threads heeft die in principe vast zitten, wachtend tot een bepaalde bron beschikbaar komt.
- De uitvoerbare wachtrij , die alle threads heeft die kunnen worden uitgevoerd, maar wachten om op de processor te komen.
Discussies gaan over van status 1 naar 2 naar 3 naar 1, rond en rond totdat de query is voltooid.
Wacht
Vanuit ons perspectief is het meest interessante deel van planning wanneer een thread moet wachten op een resource voordat deze kan doorgaan. Enkele voorbeelden hiervan zijn:
- Een thread moet een pagina lezen en de pagina bevindt zich niet in het geheugen, dus de thread geeft een asynchrone fysieke I/O uit en moet dan buiten de processor wachten totdat de I/O is voltooid.
- Een thread moet een gedeelde vergrendeling op een rij verkrijgen om deze te kunnen lezen, maar een andere thread heeft al een conflicterende exclusieve vergrendeling terwijl de rij wordt bijgewerkt.
Wanneer een thread een resource nodig heeft die hij niet kan krijgen, heeft deze geen andere keuze dan te stoppen en te wachten tot de resource beschikbaar komt (het mechanisme voor hoe de thread wordt geïnformeerd over de beschikbaarheid van resources valt buiten het bestek van dit artikel). Wanneer dat gebeurt, noteert SQL Server waarom de thread moest wachten en dit wordt het wait type genoemd . Enkele voorbeelden hiervan zijn:
- Als een thread wacht op het inlezen van een pagina in het geheugen zodat deze kan worden gelezen, is het wachttype PAGEIOLATCH_SH (als de thread wacht op een pagina die wordt gewijzigd, is het wachttype PAGEIOLATCH_EX ).
- Als een thread wacht op een gedeelde vergrendeling op een rij, is het wachttype LCK_M_S (lock-mode-share)
SQL Server houdt ook bij hoe lang de thread moet wachten. Dit wordt de resource-wachttijd . genoemd , en staat meestal gewoon bekend als de wachttijd .
Wachtstatistieken
De algemene set statistieken van hoeveel threads hebben gewacht op welke bronnen en hoe lang gemiddeld, wordt wachtstatistieken genoemd. . Deze informatie is uiterst nuttig voor het oplossen van problemen met de prestaties van de werkbelasting, omdat u gemakkelijk kunt zien waar de knelpunten zich kunnen bevinden.
Het basisidee is dat SQL Server de informatie heeft over waarom threads moeten stoppen en wachten, en waar ze op wachten. Dus in plaats van te moeten raden waar u moet beginnen met het oplossen van problemen, kan een zorgvuldige analyse van wachtstatistieken u meestal in een richting wijzen die u moet nemen.
Als de meeste wachttijden op de server bijvoorbeeld PAGEIOLATCH_SH . zijn , dit kan erop duiden dat er geheugendruk op de server is, of dat er query's zijn die grote tabelscans uitvoeren in plaats van niet-geclusterde indexen te gebruiken, of dat er een probleem is met het onderliggende I/O-subsysteem, of een aantal andere redenen.
Er zijn een groot aantal soorten wacht, maar de meeste komen niet vaak voor, dus er is een kernset die je keer op keer op je servers zult zien. Begrijpen wat deze betekenen en hoe je ze kunt onderzoeken, is van cruciaal belang, zodat je niet bezwijkt voor wat ik 'knie-jerk-prestatieafstemming' noem en tijd en moeite verspilt aan het proberen een probleem op te lossen dat eigenlijk geen probleem is. Ik heb hier een reeks blogposts geschreven die daar op details ingaan, en Aaron Bertrand schreef vorig jaar ook een samenvattende post van de top 10 wachtstatistieken.
Wacht op tracking
Er zijn een aantal manieren waarop u wachttijden kunt bijhouden. De eenvoudigste is om te kijken naar wat er op dit moment op de server gebeurt, met behulp van een script dat de sys.dm_os_waiting_tasks onderzoekt DMV. Je kunt hier een script vinden om dat te doen, en dat heeft automatisch gegenereerde URL's in de wachtbibliotheek.
Een andere manier is om naar de verzamelde wachtstatistieken voor de hele server te kijken, met een script dat de sys.dm_os_wait_stats onderzoekt DMV. Je kunt hier een script vinden om dat te doen, en dat heeft automatisch gegenereerde URL's in de wachtbibliotheek. Je moet echter voorzichtig zijn met die methode, want dan worden alle wachttijden weergegeven die zijn opgetreden sinds de server is gestart. Een betere manier is om wachttijden bij te houden over kleine intervallen, bijvoorbeeld een half uur, en een script om dat te doen is hier.
U kunt ook wachtstatistieken krijgen met de Server Reports-invoegtoepassing voor de nieuwe Azure Data Studio-tool en met Query Store vanaf SQL Server 2017.
Onthoud dat u nog steeds moet begrijpen wat de soorten wachten betekenen als u de statistieken eenmaal heeft verzameld.
Wacht bronnen
Om hierbij te helpen, en omdat Microsoft geen documentatie heeft over het interpreteren van wachtstatistieken, heb ik in 2016 een wachttypebibliotheek uitgebracht, met details van honderden veelvoorkomende soorten wachten en hoe u deze kunt oplossen. U kunt naar de bibliotheek gaan op https://www.SQLskills.com/help/waits. En in 2017 creëerde SentryOne een geautomatiseerd systeem om voor elke pagina in de bibliotheek een infographic te bieden die je snel kunt gebruiken om te zien of het wachttype waarin je geïnteresseerd bent echt gebruikelijk is of niet (zie dit bericht voor details) . Hieronder vindt u een voorbeeldinfographic voor de PAGEIOLATCH_SH wacht type:
Op de horizontale as staat een schaal (omschakelbaar tussen lineair en logaritmisch) van welk percentage van de gevallen (op afstand gemonitord door SentryOne) deze wachttijd hebben ervaren in de afgelopen kalendermaand, en op de verticale as staat het percentage van de tijd dat die gevallen die dat hebben ervaren wait had eigenlijk een thread die wachtte op dat type wait.
Een andere bron om u te helpen de wachttijden te begrijpen, is een online training die ik heb opgenomen voor Pluralsight - zie hier.
U moet op zijn minst de verschillende blogposts lezen in de gedeelten Wachtstatistieken en Wachttijden bijhouden hierboven.
Wachten bijhouden met SentryOne Tools
SQL Sentry houdt de wachttijden op instantieniveau automatisch bij in de loop van de tijd, zodat u geen hoge wachttijden "op heterdaad" hoeft te betrappen. Iemand klaagde over een traag systeem gistermiddag of een melding die afgelopen dinsdag uitviel? Geen probleem. U kunt ingaan op alle wachttijden voor elk tijdstip of over een bereik, en deze correleren met verschillende andere prestatiestatistieken die op dat moment zijn verzameld - of het nu andere trends op het dashboard zijn, zoals back-up of database I/O-activiteit, springen naar alle de Top SQL-commando's die in hetzelfde venster werden uitgevoerd, onderzoek naar langlopende blokkeringen of gebruik baselines om het wachtprofiel te vergelijken met andere perioden.
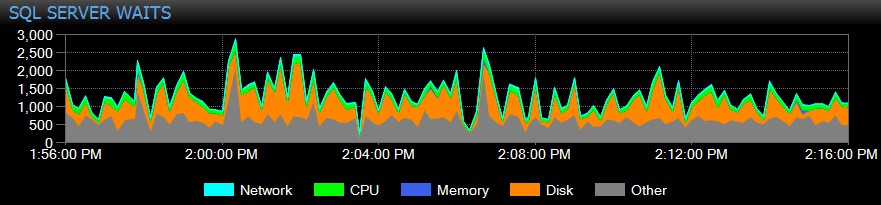
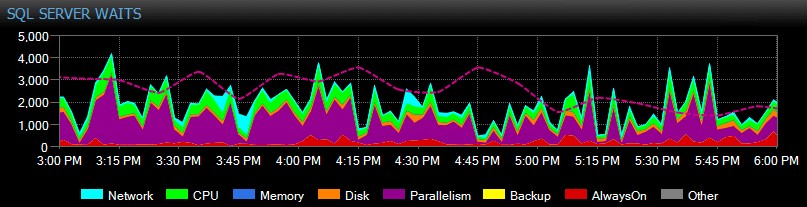
U kunt zelfs wachttijden aanpassen die al dan niet worden verzameld, de categorieën wijzigen die visueel worden weergegeven en intelligente waarschuwingen en/of reacties op specifieke wachtscenario's maken. Veel van onze klanten gebruiken SQL Sentry om zich te concentreren op echte prestatieproblemen met betrekking tot wachttijden, omdat het hen in staat stelt veel van de ruis te negeren die gewoon normale SQL Server-threadactiviteit is.
Samenvatting
Zoals je kunt zien aan de hand van de bovenstaande informatie, gebeuren er altijd wachttijden in SQL Server, want dat is precies hoe threadplanning en multi-threaded systemen werken. Ze zijn een van de krachtigste tools in uw toolbox voor het oplossen van problemen, dus als u ze nog niet gebruikt, is dit het moment om te beginnen. De leercurve is kort en steil - als je de verschillende zoekopdrachten en tools een paar keer hebt uitgevoerd, heb je het snel onder de knie, en dan is het een kwestie van de handleidingen doorlezen voor de wachttijden die je ziet en bepalen of ze een probleem zijn van niet.
Veel plezier met het oplossen van problemen!