Inleiding
Het bereiken van minimale logboekregistratie met INSERT...SELECT kan een ingewikkelde onderneming zijn. De overwegingen die worden vermeld in de Prestatiegids voor het laden van gegevens zijn nog steeds behoorlijk uitgebreid, hoewel je ook SQL Server 2016, Minimal logging en Impact of the Batchsize in bulkload-bewerkingen door Parikshit Savjani van het SQL Server Tiger Team moet lezen om de bijgewerkte afbeelding te krijgen voor SQL Server 2016 en later, wanneer bulksgewijs wordt geladen in geclusterde rowstore-tabellen. Dat gezegd hebbende, is dit artikel puur gericht op het verstrekken van nieuwe details over minimale logboekregistratie bij het bulksgewijs laden van traditionele (niet "voor het geheugen geoptimaliseerde") heaptabellen met behulp van INSERT...SELECT . Tabellen met een b-tree geclusterde index worden apart behandeld in deel twee van deze serie.
Heap-tabellen
Bij het invoegen van rijen met INSERT...SELECT op een hoop zonder niet-geclusterde indexen, stelt de documentatie universeel dat dergelijke invoegingen minimaal zullen worden gelogd zolang een TABLOCK hint is aanwezig. Dit wordt weerspiegeld in de samenvattende tabellen in de Handleiding voor het laden van gegevens en de Tiger Team-post. De samenvattingsrijen voor heaptabellen zonder indexen zijn hetzelfde in beide documenten (geen wijzigingen voor SQL Server 2016):

Een expliciete TABLOCK hint is niet de enige manier om te voldoen aan de vereiste voor vergrendeling op tafelniveau . We kunnen ook de 'tafelvergrendeling op bulklading' . instellen optie voor de doeltabel met behulp van sp_tableoption of door gedocumenteerde traceringsvlag 715 in te schakelen. (Opmerking:deze opties zijn niet voldoende om minimale logboekregistratie in te schakelen bij gebruik van INSERT...SELECT omdat INSERT...SELECT ondersteunt geen vergrendelingen voor bulkupdates).
De "gelijktijdig mogelijk" kolom in de samenvatting is alleen van toepassing op bulklaadmethoden anders dan INSERT...SELECT . Gelijktijdig laden van een heaptabel is niet mogelijk met INSERT...SELECT . Zoals vermeld in de Prestatiegids voor het laden van gegevens , bulk laden met INSERT...SELECT neemt een exclusieve X slot op de tafel, niet de bulk-update BU slot vereist voor gelijktijdige bulkladingen.
Dat alles terzijde - en ervan uitgaande dat er geen andere reden is om geen minimale logging te verwachten bij het bulksgewijs laden van een niet-geïndexeerde heap met TABLOCK (of equivalent) — de invoeging misschien niet minimaal ingelogd zijn…
Een uitzondering op de regel
Het volgende demoscript moet worden uitgevoerd op een ontwikkelingsinstantie in een nieuwe testdatabase ingesteld om de SIMPLE . te gebruiken herstelmodel. Het laadt een aantal rijen in een heaptabel met behulp van INSERT...SELECT met TABLOCK , en rapporten over de gegenereerde transactielogrecords:
CREATE TABLE dbo.TestHeap
(
id integer NOT NULL IDENTITY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.TestHeap WITH (TABLOCK)
(c1)
SELECT TOP (897)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_HEAP'
AND FD.AllocUnitName = N'dbo.TestHeap'; De uitvoer laat zien dat alle 897 rijen volledig zijn geregistreerd ondanks schijnbaar aan alle voorwaarden voor minimale logging te voldoen (om ruimteredenen wordt slechts een voorbeeld van logrecords getoond):
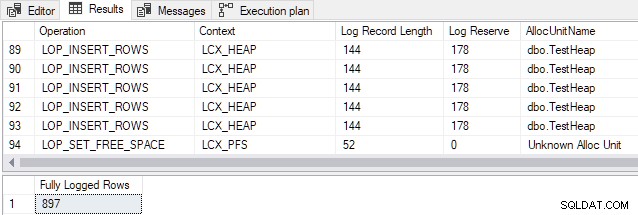
Hetzelfde resultaat wordt gezien als de invoeging wordt herhaald (d.w.z. het maakt niet uit of de heaptabel leeg is of niet). Dit resultaat is in tegenspraak met de documentatie.
De minimale logdrempel voor heaps
Het aantal rijen dat men moet toevoegen in een enkele INSERT...SELECT verklaring om minimale logging te bereiken in een niet-geïndexeerde heap met tabelvergrendeling ingeschakeld, hangt af van een berekening die SQL Server uitvoert bij het schatten van de totale grootte van de in te voegen gegevens. De invoer voor deze berekening is:
- De versie van SQL Server.
- Het geschatte aantal rijen dat leidt naar de Invoegen operator.
- Doel tabelrijgrootte.
Voor SQL Server 2012 en eerder , het overgangspunt voor deze specifieke tabel is 898 rijen . Het nummer wijzigen in het demoscript TOP clausule van 897 tot 898 produceert de volgende uitvoer:
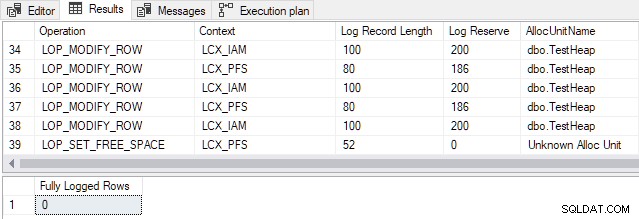
De gegenereerde transactieloggegevens hebben betrekking op paginatoewijzing en het onderhoud van Indextoewijzingskaart (IAM) en Page Free Space (PFS) structuren. Onthoud dat minimale logboekregistratie betekent dat SQL Server niet elke rij-invoeging afzonderlijk logt. In plaats daarvan worden alleen wijzigingen in metadata en allocatiestructuren gelogd. Wijzigen van 897 naar 898 rijen maakt minimale logboekregistratie mogelijk voor deze specifieke tafel.
Voor SQL Server 2014 en later , het overgangspunt is 950 rijen voor deze tafel. Uitvoeren van de INSERT...SELECT met TOP (949) gebruikt volledige logboekregistratie – veranderen naar TOP (950) produceert minimale logboekregistratie .
De drempels zijn niet afhankelijk van de Kadinaliteitsschatting model in gebruik of het compatibiliteitsniveau van de database.
De berekening van de gegevensgrootte
Of SQL Server besluit om rowset bulk load te gebruiken — en dus of minimale logging beschikbaar is of niet — hangt af van het resultaat van een reeks berekeningen uitgevoerd in een methode genaamd sqllang!CUpdUtil::FOptimizeInsert , die ofwel true . retourneert voor minimale logging, of false voor volledige registratie. Een voorbeeld van een call-stack wordt hieronder getoond:
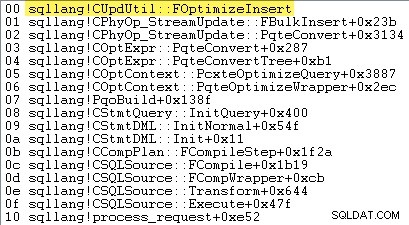
De essentie van de test is:
- De invoeging moet voor meer dan 250 rijen . zijn .
- De totale grootte van de invoeggegevens moet worden berekend als minstens 8 pagina's .
De controle op meer dan 250 rijen hangt uitsluitend af van het geschatte aantal rijen dat aankomt bij de Tabel invoegen exploitant. Dit wordt in het uitvoeringsplan weergegeven als 'Geschat aantal rijen' . Wees hier voorzichtig mee. Het is eenvoudig om een plan te maken met een laag geschat aantal rijen, bijvoorbeeld door een variabele te gebruiken in de TOP clausule zonder OPTION (RECOMPILE) . In dat geval schat de optimizer op 100 rijen, die de drempel niet zullen bereiken, en zo bulklading en minimale logging voorkomen.
De berekening van de totale gegevensomvang is complexer en komt niet overeen de 'Geschatte rijgrootte' stroomt in de Tabel Invoegen exploitant. De manier waarop de berekening wordt uitgevoerd, is in SQL Server 2012 en eerder iets anders dan in SQL Server 2014 en later. Toch produceren beide een resultaat met rijgrootte dat verschilt van wat wordt gezien in het uitvoeringsplan.
De rijgrootteberekening
De totale grootte van de invoeggegevens wordt berekend door het geschatte aantal rijen te vermenigvuldigen door de verwachte maximale rijgrootte . De berekening van de rijgrootte is het punt dat verschilt tussen SQL Server-versies.
In SQL Server 2012 en eerder wordt de berekening uitgevoerd door sqllang!OptimizerUtil::ComputeRowLength . Voor de testheaptabel (opzettelijk ontworpen met eenvoudige niet-nulkolommen met een vaste lengte met gebruik van de originele FixedVar rij-opslagformaat) is een overzicht van de berekening:
- Initialiseer een FixedVar metagegevensgenerator.
- Verkrijg type- en attribuutinformatie voor elke kolom in de Tabel invoegen invoerstroom.
- Voeg getypte kolommen en attributen toe aan de metadata.
- Voltooi de generator en vraag hem om de maximale rijgrootte.
- Overhead toevoegen voor de null-bitmap en aantal kolommen.
- Voeg vier bytes toe voor de rij statusbits en rijverschuiving naar het aantal kolommengegevens.
Fysieke rijgrootte
Het resultaat van deze berekening zou kunnen worden verwacht dat het overeenkomt met de fysieke rijgrootte, maar dat is niet het geval. Bijvoorbeeld, met rijversiebeheer uitgeschakeld voor de database:
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.min_record_size_in_bytes,
DDIPS.max_record_size_in_bytes,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.TestHeap', N'U'),
0, -- heap
NULL, -- all partitions
'DETAILED'
) AS DDIPS; …geeft een recordgrootte van 60 bytes in elke rij van de testtabel:

Dit is zoals beschreven in Schat de grootte van een hoop:
- Totale bytegrootte van alle vaste-lengte kolommen =53 bytes:
id integer NOT NULL=4 bytesc1 integer NOT NULL=4 bytespadding char(45) NOT NULL=45 bytes.
- Null-bitmap =3 bytes :
- =2 + int((Num_Cols + 7) / 8)
- =2 + int((3 + 7) / 8)
- =3 bytes.
- Rijkoptekst =4 bytes .
- Totaal 53 + 3 + 4 =60 bytes .
Het komt ook overeen met de geschatte rijgrootte die wordt weergegeven in het uitvoeringsplan:

Interne berekeningsdetails
De interne berekening die wordt gebruikt om te bepalen of bulklading wordt gebruikt, komt met een ander resultaat, gebaseerd op de volgende insert stream kolominformatie verkregen met behulp van een debugger. De gebruikte typenummers komen overeen met sys.types :
- Totaal vaste lengte kolomgrootte =66 bytes :
- Type id 173
binary(8)=8 bytes (intern). - Typ id 56
integer=4 bytes (intern). - Typ id 104
bit=1 byte (intern). - Typ id 56
integer=4 bytes (idkolom). - Typ id 56
integer=4 bytes (c1kolom). - Typ id 175
char(45)=45 bytes (paddingkolom).
- Type id 173
- Null-bitmap =3 bytes (zoals eerder).
- Rijkoptekst overhead =4 bytes (zoals eerder).
- Berekende rijgrootte =66 + 3 + 4 =73 bytes .
Het verschil is dat de invoerstroom die de Table Insert . voedt operator bevat drie extra interne kolommen . Deze worden verwijderd wanneer showplan wordt gegenereerd. De extra kolommen vormen de table insert locator , die de bladwijzer (RID of rijzoeker) als eerste onderdeel bevat. Het zijn metadata voor de insert en wordt uiteindelijk niet aan de tabel toegevoegd.
De extra kolommen verklaren de discrepantie tussen de berekening uitgevoerd door OptimizerUtil::ComputeRowLength en de fysieke grootte van de rijen. Dit kan worden gezien als een bug :SQL Server mag metagegevenskolommen in de invoegstroom niet meetellen voor de uiteindelijke fysieke grootte van de rij. Aan de andere kant kan de berekening ook gewoon een schatting zijn naar beste vermogen met behulp van de generieke update telefoniste.
De berekening houdt ook geen rekening met andere factoren, zoals de 14-byte overhead van rijversiebeheer. Dit kan worden getest door het demoscript opnieuw uit te voeren met een van de snapshot-isolatie of lees vastgelegde snapshot-isolatie database-opties ingeschakeld. De fysieke grootte van de rij zal toenemen met 14 bytes (van 60 bytes naar 74), maar de drempel voor minimale logging blijft ongewijzigd op 898 rijen.
Drempelberekening
We hebben nu alle details die we nodig hebben om te zien waarom de drempel 898 rijen is voor deze tabel op SQL Server 2012 en eerder:
- 898 rijen voldoen aan de eerste vereiste voor meer dan 250 rijen .
- Berekende rijgrootte =73 bytes.
- Geschat aantal rijen =897.
- Totale gegevensgrootte =73 bytes * 897 rijen =65481 bytes.
- Totaal aantal pagina's =65481 / 8192 =7.9932861328125.
- Dit is net onder de tweede vereiste voor>=8 pagina's.
- Voor 898 rijen is het aantal pagina's 8.002197265625.
- Dit is >=8 pagina's dus minimale logboekregistratie is geactiveerd.
In SQL Server 2014 en later , de wijzigingen zijn:
- De rijgrootte wordt berekend door de metadatagenerator.
- De interne integerkolom in de tabelzoeker is niet meer aanwezig in de invoegstroom. Dit vertegenwoordigt de uniquifier , die alleen van toepassing is op indexen. Het lijkt erop dat dit is verwijderd als een bugfix.
- De verwachte rijgrootte verandert van 73 in 69 bytes vanwege de weggelaten integerkolom (4 bytes).
- De fysieke grootte is nog steeds 60 bytes. Het resterende verschil van 9 bytes wordt verklaard door de extra 8-byte RID en 1-byte bit interne kolommen in de invoegstroom.
Om de drempel van 8 pagina's met 69 bytes per rij te bereiken:
- 8 pagina's * 8192 bytes per pagina =65536 bytes.
- 65535 bytes / 69 bytes per rij =949.7971014492754 rijen.
- We verwachten daarom minimaal 950 rijen om bulklading rijen in te schakelen voor deze tabel op SQL Server 2014 en later.
Samenvatting en laatste gedachten
In tegenstelling tot de bulklaadmethoden die batchgrootte ondersteunen , zoals beschreven in de post van Parikshit Savjani, INSERT...SELECT in een niet-geïndexeerde hoop (leeg of niet) doet niet altijd resulteren in minimale logging wanneer table-locking is gespecificeerd.
Minimale logging inschakelen met INSERT...SELECT , SQL Server moet meer dan 250 rijen verwachten met een totale grootte van minstens één extensie (8 pagina's).
Bij het berekenen van de geschatte totale invoeggrootte (ter vergelijking met de drempel van 8 pagina's), vermenigvuldigt SQL Server het geschatte aantal rijen met een berekende maximale rijgrootte. SQL Server telt interne kolommen aanwezig in de invoegstroom bij het berekenen van de rijgrootte. Voor SQL Server 2012 en eerder voegt dit 13 bytes per rij toe. Voor SQL Server 2014 en later voegt het 9 bytes per rij toe. Dit heeft alleen invloed op de berekening; het heeft geen invloed op de uiteindelijke fysieke grootte van de rijen.
Wanneer minimaal gelogde heap-bulklading actief is, doet SQL Server niet rijen één voor één invoegen. De omvang wordt van tevoren toegewezen en de in te voegen rijen worden door sqlmin!RowsetBulk op geheel nieuwe pagina's verzameld. alvorens te worden toegevoegd aan de bestaande structuur. Een voorbeeld van een call-stack wordt hieronder getoond:
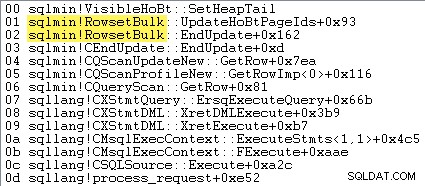
Logische uitlezingen worden niet gerapporteerd voor de doeltabel wanneer minimaal gelogde heap-bulklading wordt gebruikt - de Table Insert operator hoeft geen bestaande pagina te lezen om het invoegpunt voor elke nieuwe rij te vinden.
Uitvoeringsplannen worden momenteel niet weergegeven hoeveel rijen of pagina's zijn ingevoegd met rowset bulk load en minimale logboekregistratie . Misschien wordt deze nuttige informatie in een toekomstige release aan het product toegevoegd.