In het eerste deel van deze blogserie heb ik een aantal benchmarkresultaten gepresenteerd die laten zien hoe PostgreSQL OLTP-prestaties zijn veranderd sinds 8.3, uitgebracht in 2008. In dit deel ben ik van plan hetzelfde te doen, maar voor analytische / BI-query's, het verwerken van grote hoeveelheden gegevens.
Er zijn een aantal industriële benchmarks voor het testen van deze werklast, maar waarschijnlijk de meest gebruikte is TPC-H, dus dat is wat ik voor deze blogpost zal gebruiken. Er is ook TPC-DS, een andere TPC-benchmark voor het testen van beslissingsondersteunende systemen, die kan worden gezien als een evolutie of vervanging van TPC-H. Ik heb om een aantal redenen besloten bij TPC-H te blijven.
Ten eerste is TPC-DS veel complexer, zowel qua schema (meer tabellen) als qua aantal queries (22 vs. 99). Dit goed afstemmen, vooral als het om meerdere PostgreSQL-versies gaat, zou veel moeilijker zijn. Ten tweede gebruiken sommige van de TPC-DS-query's functies die niet worden ondersteund door oudere PostgreSQL-versies (bijv. groeperingssets), waardoor die query's voor sommige versies niet relevant zijn. En tot slot zou ik zeggen dat mensen veel meer vertrouwd zijn met TPC-H dan met TPC-DS.
Het doel hiervan is niet om vergelijking met andere databaseproducten mogelijk te maken, maar alleen om een redelijke langetermijnkarakterisering te geven van hoe de PostgreSQL-prestaties zijn geëvolueerd sinds PostgreSQL 8.3.
Opmerking :Voor een zeer interessante analyse van de TPC-H-benchmark raad ik ten zeerste het artikel "TPC-H Analyzed:Hidden Messages and Lessons Learned from an Influential Benchmark" van Boncz, Neumann en Erling aan.
De hardware
De meeste resultaten in deze blogpost komen uit de "grotere doos" die ik op ons kantoor heb, die deze parameters heeft:
- 2x E5-2620 v4 (16 cores, 32 threads)
- 64 GB RAM
- Intel Optane 900P 280GB NVMe SSD (gegevens)
- 3 x 7.2k SATA RAID0 (tijdelijke tabelruimte)
- kernel 5.6.15, ext4-bestandssysteem
Ik weet zeker dat je aanzienlijk sterkere machines kunt kopen, maar ik geloof dat dit goed genoeg is om ons relevante gegevens te geven. Er waren twee configuratievarianten:een met parallellisme uitgeschakeld en een met parallellisme ingeschakeld. De meeste parameterwaarden zijn in beide gevallen hetzelfde, afgestemd op beschikbare hardwarebronnen (CPU, RAM, opslag). U vindt meer gedetailleerde informatie over de configuratie aan het einde van dit bericht.
De maatstaf
Ik wil heel duidelijk maken dat het niet mijn doel is om een geldige TPC-H-benchmark te implementeren die voldoet aan alle criteria die door de TPC worden vereist. Mijn doel is om te evalueren hoe de prestaties van verschillende analytische zoekopdrachten in de loop van de tijd zijn veranderd, niet om een abstracte maatstaf voor prestaties per dollar of iets dergelijks na te jagen.
Dus ik heb besloten om alleen een subset van TPC-H te gebruiken - laad in feite gewoon de gegevens en voer de 22 query's uit (dezelfde parameters op alle versies). Er zijn geen gegevensverversingen, de gegevensset is statisch na de eerste belasting. Ik heb een aantal schaalfactoren gekozen, 1, 10 en 75, zodat we resultaten hebben voor fits-in-shared-buffers (1), fits-in-memory (10) en meer-dan-geheugen (75) . Ik zou voor 100 gaan om er een "mooie reeks" van te maken, die in sommige gevallen niet in de opslag van 280 GB zou passen (dankzij indexen, tijdelijke bestanden, enz.). Merk op dat schaalfactor 75 door TPC-H niet eens wordt herkend als een geldige schaalfactor.
Maar heeft het zelfs zin om datasets van 1 GB of 10 GB te benchmarken? Mensen hebben de neiging zich te concentreren op veel grotere databases, dus het lijkt misschien een beetje dwaas om die te testen. Maar ik denk niet dat dat nuttig zou zijn – de overgrote meerderheid van de databases in het wild is naar mijn ervaring vrij klein. En zelfs als de hele database groot is, werken mensen meestal maar met een kleine subset ervan – recente gegevens, onopgeloste bestellingen, enz. Dus ik denk dat het zinvol is om zelfs met die kleine datasets te testen.
Gegevens worden geladen
Laten we eerst eens kijken hoe lang het duurt om gegevens in de database te laden - zonder en met parallellisme. Ik laat alleen resultaten zien van de 75 GB-dataset, omdat het algemene gedrag bijna hetzelfde is voor de kleinere gevallen.
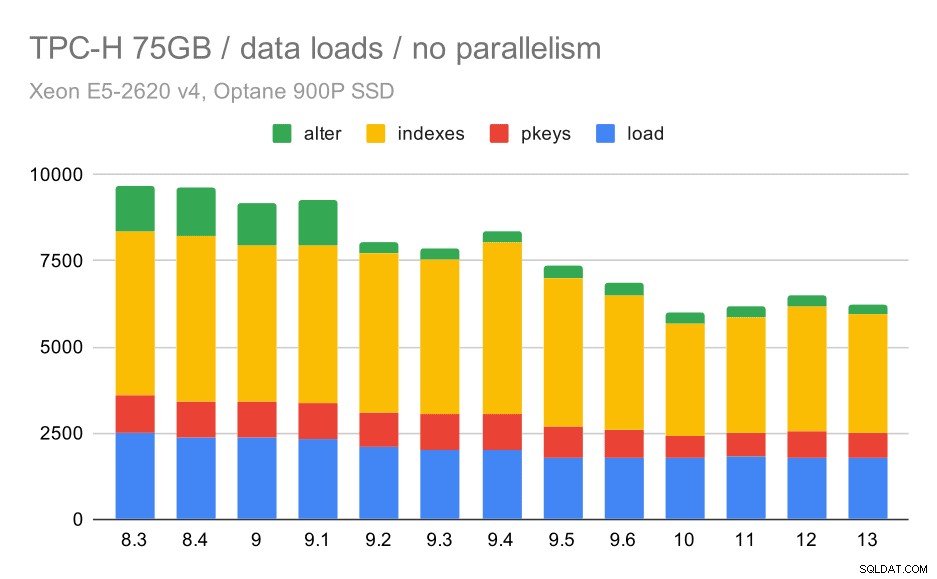
TPC-H data laadduur – schaal 75GB, geen parallellisme
Je kunt duidelijk zien dat er een gestage trend van verbeteringen is, waarbij ongeveer 30% van de duur wordt weggenomen door de efficiëntie in alle vier de stappen te verbeteren:KOPIEREN, primaire sleutels en indexen maken en (vooral) externe sleutels instellen. De "alter" verbetering in 9.2 is bijzonder duidelijk.
| KOPIE | PKEYS | INDEXES | ALTER | |
| 8.3 | 2531 | 1156 | 1922 | 1615 |
| 8.4 | 2374 | 1171 | 1891 | 1370 |
| 9.0 | 2374 | 1137 | 1797 | 1282 |
| 9.1 | 2376 | 1118 | 1807 | 1268 |
| 9.2 | 2104 | 1120 | 1833 | 1157 |
| 9.3 | 2008 | 1089 | 1836 | 1229 |
| 9.4 | 1990 | 1168 | 1818 | 1197 |
| 9.5 | 1982 | 1000 | 1903 | 1203 |
| 9,6 | 1779 | 872 | 1797 | 1174 |
| 10 | 1773 | 777 | 1469 | 1012 |
| 11 | 1807 | 762 | 1492 | 758 |
| 12 | 1760 | 768 | 1513 | 741 |
| 13 | 1782 | 836 | 1587 | 675 |
Laten we nu eens kijken hoe het inschakelen van parallellisme het gedrag verandert. De volgende grafiek vergelijkt resultaten met parallellisme ingeschakeld - gemarkeerd met "(p)" - met resultaten waarbij parallellisme is uitgeschakeld.
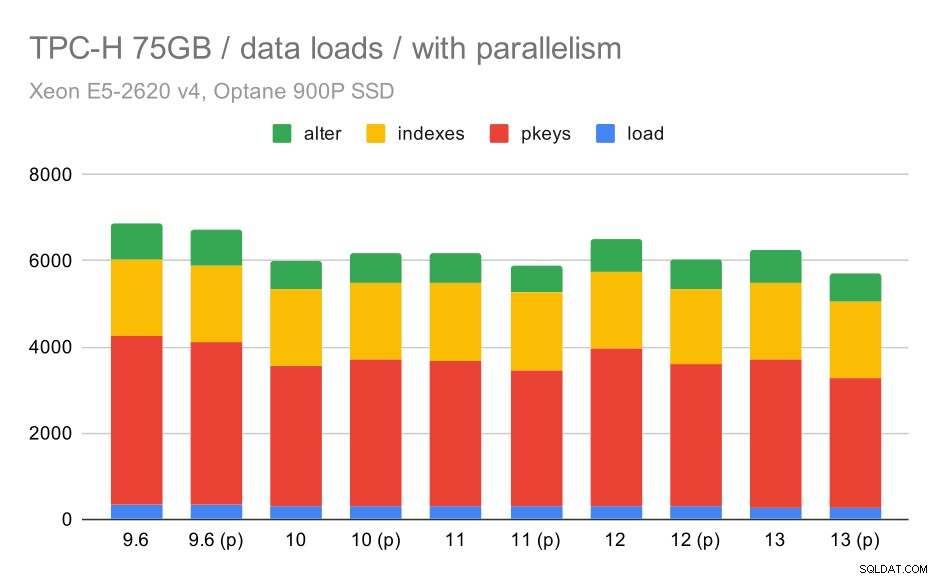
TPC-H data laadduur – schaal 75GB, parallellisme ingeschakeld.
Helaas lijkt het effect van parallellisme in deze test erg beperkt te zijn – het helpt wel een beetje, maar de verschillen zijn vrij klein. Dus de algehele verbetering blijft ongeveer 30%.
| KOPIE | PKEYS | INDEXES | ALTER | |
| 9,6 | 344 | 3902 | 1786 | 831 |
| 9.6 (p) | 346 | 3781 | 1780 | 832 |
| 10 | 318 | 3259 | 1766 | 671 |
| 10 (p) | 315 | 3400 | 1769 | 693 |
| 11 | 319 | 3357 | 1817 | 690 |
| 11 (p) | 320 | 3144 | 1791 | 618 |
| 12 | 314 | 3643 | 1803 | 754 |
| 12 (p) | 313 | 3296 | 1752 | 657 |
| 13 | 276 | 3437 | 1790 | 744 |
| 13 (P) | 274 | 3011 | 1770 | 641 |
Vragen
Nu kunnen we de vragen bekijken. TPC-H heeft 22 querysjablonen - ik heb één set echte query's gegenereerd en deze twee keer op alle versies uitgevoerd - eerst nadat alle caches zijn verwijderd en de instantie opnieuw is opgestart, en vervolgens met de opgewarmde cache. Alle cijfers in de grafieken zijn de beste van deze twee runs (in de meeste gevallen is het natuurlijk de tweede).
Geen parallellisme
Zonder parallellisme zijn de resultaten op de kleinste dataset vrij duidelijk:elke balk is opgesplitst in meerdere delen met verschillende kleuren voor elk van de 22 zoekopdrachten. Het is moeilijk te zeggen welk deel naar welke exacte zoekopdracht verwijst, maar het is voldoende om gevallen te identificeren waarin een zoekopdracht tussen twee runs verbetert of veel slechter wordt. In de eerste grafiek is het bijvoorbeeld heel duidelijk dat Q21 veel sneller werd tussen 8,3 en 8,4.
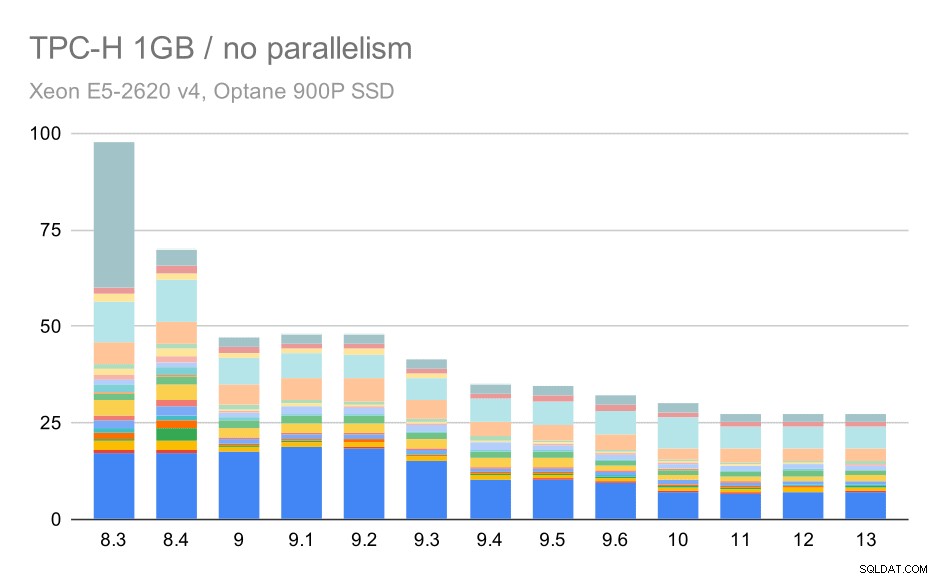
TPC-H-query's op kleine dataset (1 GB) - parallellisme uitgeschakeld
Voor de schaal van 10 GB zijn de resultaten enigszins moeilijk te interpreteren, omdat op 8.3 een van de query's (Q21) zo veel tijd kost om uit te voeren dat al het andere in het niet valt.
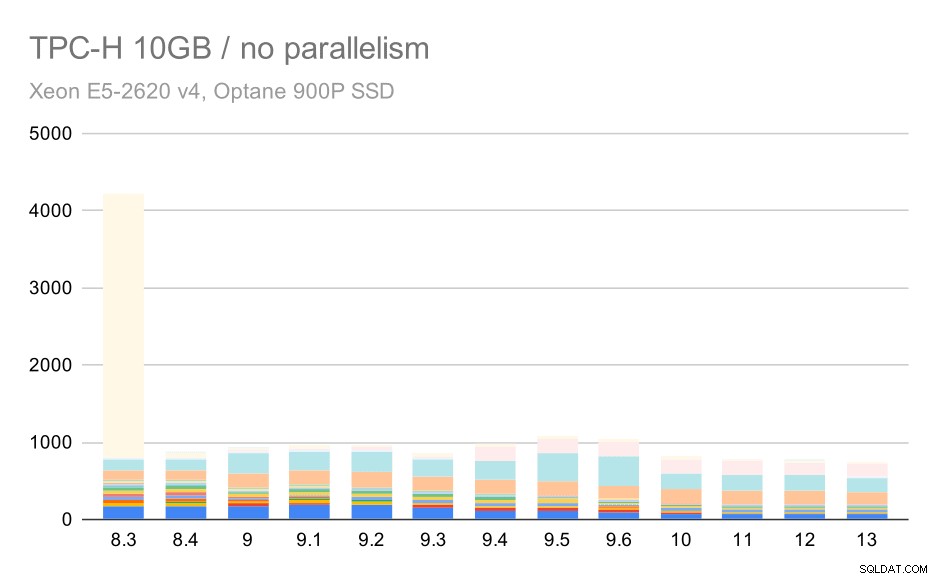
TPC-H-query's op middelgrote dataset (10 GB) - parallellisme uitgeschakeld
Dus laten we eens kijken hoe de grafiek eruit zou zien zonder Q21:
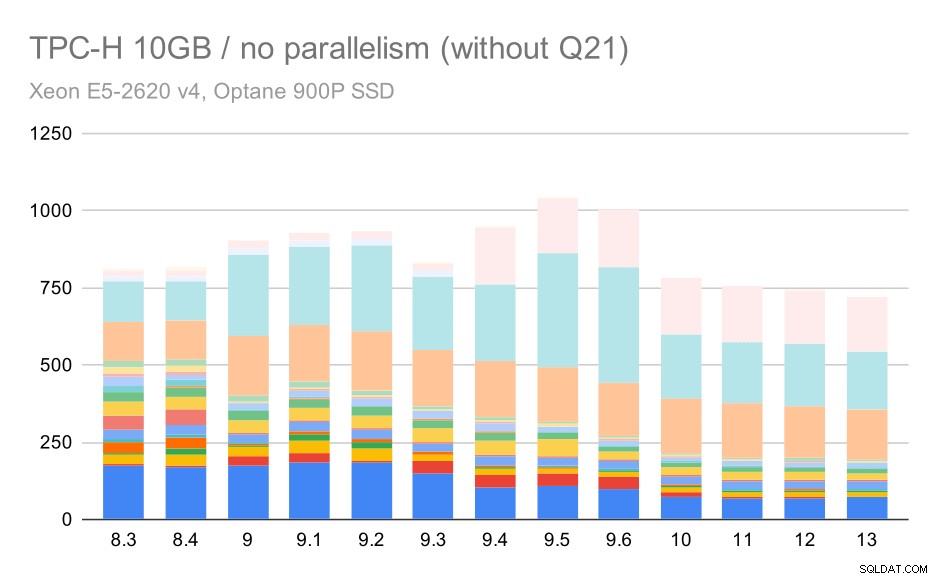
TPC-H-query's op middelgrote dataset (10 GB) - parallellisme uitgeschakeld, zonder problematische Q2
Oké, dat is makkelijker te lezen. We kunnen duidelijk zien dat de meeste zoekopdrachten (tot Q17) sneller werden, maar daarna werden twee van de queries (Q18 en Q20) iets langzamer. We zullen een soortgelijk probleem zien op de grootste dataset, dus ik zal dan bespreken wat de oorzaak zou kunnen zijn.
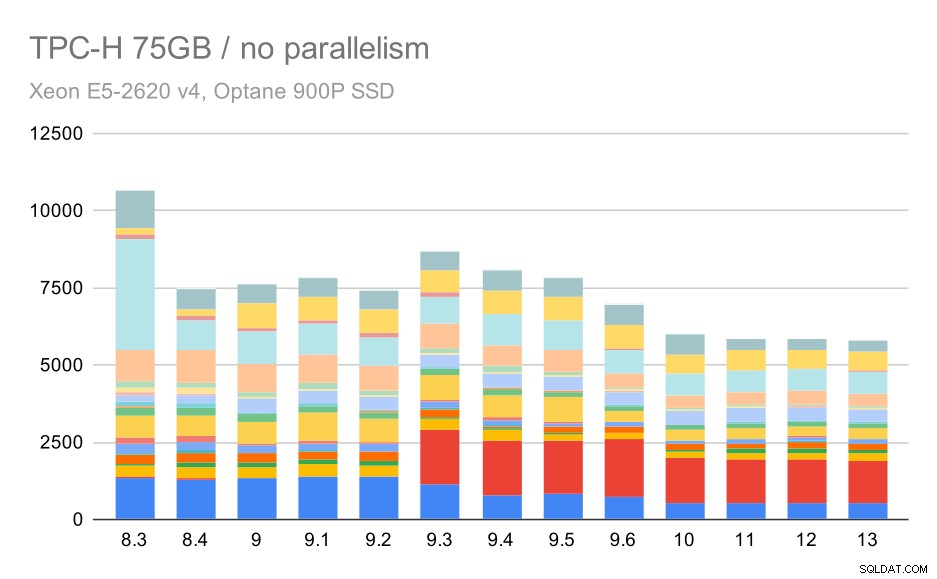
TPC-H-query's op grote dataset (75 GB) - parallellisme uitgeschakeld
Nogmaals, we zien een plotselinge toename voor een van de zoekopdrachten in 9.3 - dit keer is het Q2, zonder welke de grafiek er als volgt uitziet:
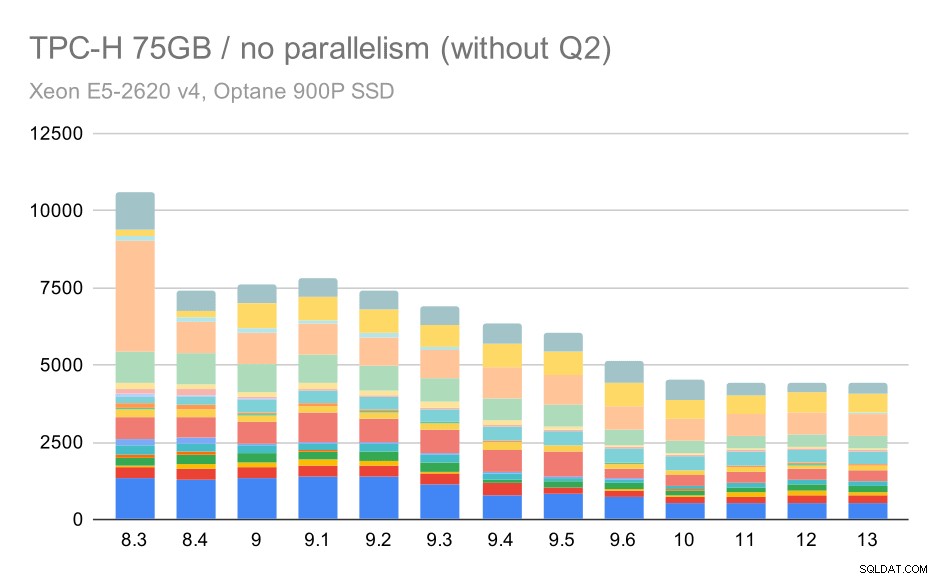
TPC-H-query's op grote dataset (75 GB) - parallellisme uitgeschakeld, zonder problematische Q2
Dat is over het algemeen een behoorlijk mooie verbetering, waarbij de hele uitvoering wordt versneld van ~ 2,7 uur naar slechts ~ 1,2 uur, alleen door de planner en optimizer slimmer te maken en door de uitvoerder efficiënter te maken (onthoud dat het parallellisme in deze runs was uitgeschakeld) .
Dus, wat zou het probleem kunnen zijn met Q2, waardoor het langzamer wordt in 9.3? Het simpele antwoord is dat elke keer dat je de planner en optimizer slimmer maakt – ofwel door nieuwe soorten paden / plannen te construeren, of door het afhankelijk te maken van bepaalde statistieken, het ook betekent dat er nieuwe fouten kunnen worden gemaakt wanneer de statistieken of schattingen niet kloppen. In Q2 verwijst de WHERE-clausule naar een geaggregeerde subquery - een vereenvoudigde versie van de query kan er als volgt uitzien:
select 1 from partsupp where ps_supplycost = ( select min(ps_supplycost) from partsupp, supplier, nation, region where p_partkey = ps_partkey and s_suppkey = ps_suppkey and s_nationkey = n_nationkey and n_regionkey = r_regionkey and r_name = 'AMERICA' );
Het probleem is dat we de gemiddelde waarde op het moment van plannen niet kennen, waardoor het onmogelijk is om voldoende goede schattingen te berekenen voor de WHERE-voorwaarde. Het eigenlijke tweede kwartaal bevat extra joins, en het plannen daarvan hangt in wezen af van goede schattingen van de join-relaties. In oudere versies lijkt de optimizer het juiste te hebben gedaan, maar in 9.3 hebben we het op de een of andere manier slimmer gemaakt, maar met de slechte schatting kan het niet de juiste beslissing nemen. Met andere woorden, de goede plannen in oudere versies waren gewoon geluk, dankzij de beperkingen van de planner.
Ik durf te wedden dat de regressies van Q18 en Q20 op de kleinere dataset ook worden veroorzaakt door iets soortgelijks, hoewel ik die niet in detail heb onderzocht.
Ik geloof dat sommige van die optimalisatieproblemen kunnen worden opgelost door de kostenparameters af te stemmen (bijvoorbeeld random_page_cost enz.), maar ik heb dat niet geprobeerd vanwege tijdgebrek. Het laat echter zien dat upgrades niet automatisch alle zoekopdrachten verbeteren - soms kan een upgrade een regressie veroorzaken, dus het is een goed idee om uw applicatie goed te testen.
Parallelisme
Laten we dus eens kijken in hoeverre het parallellisme van query's de resultaten verandert. Nogmaals, we kijken alleen naar resultaten van releases sinds 9.6 en labelen resultaten met "(p)" waar parallelle zoekopdrachten zijn ingeschakeld.
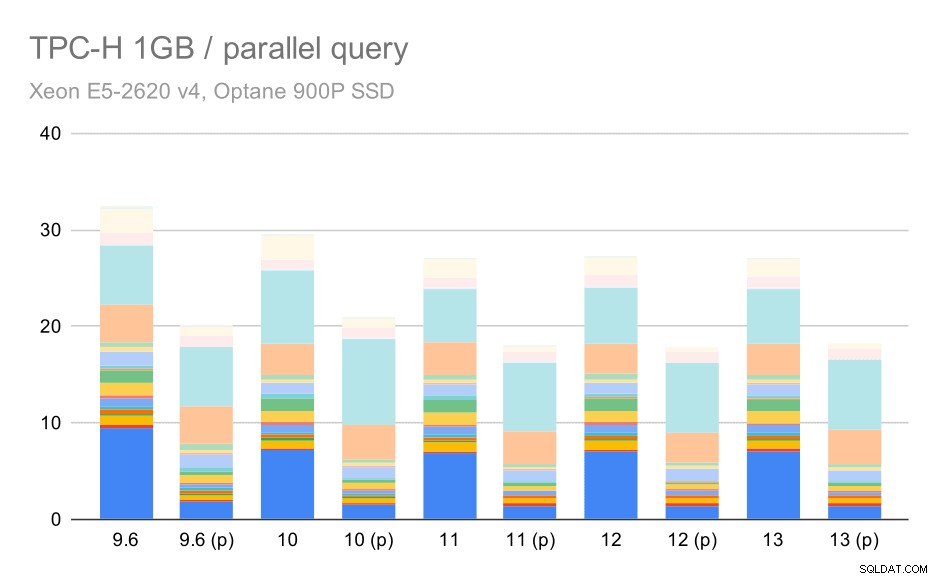
TPC-H-query's op kleine dataset (1 GB) - parallellisme ingeschakeld
Het is duidelijk dat parallellisme behoorlijk helpt - het scheert ongeveer 30% af, zelfs op deze kleine dataset. Op de gemiddelde dataset is er niet veel verschil tussen reguliere en parallelle runs:
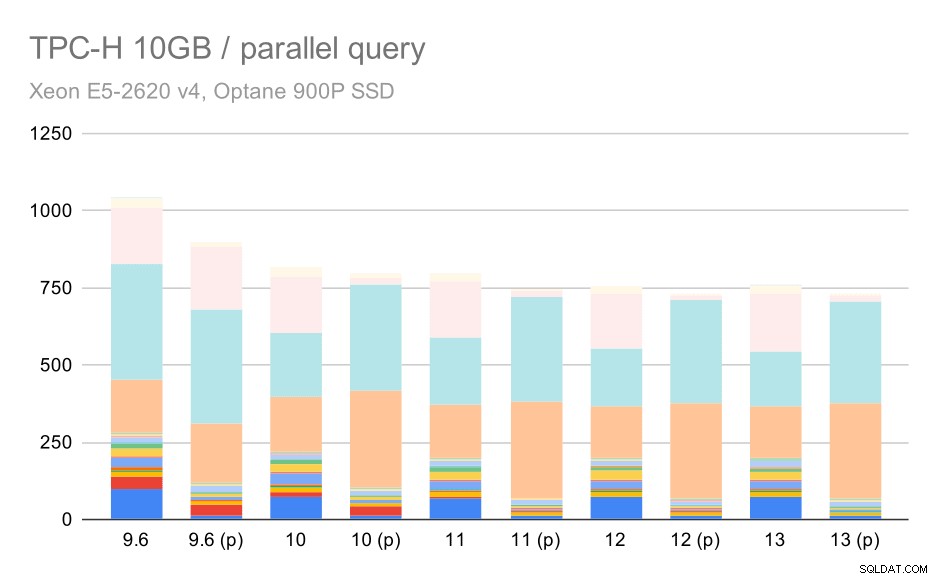
TPC-H-query's op middelgrote dataset (10 GB) - parallellisme ingeschakeld
Dit is weer een demonstratie van het reeds besproken probleem:door parallellisme in te schakelen, kunnen aanvullende queryplannen worden overwogen, en het is duidelijk dat de schattingen of kosten niet overeenkomen met de realiteit, wat resulteert in slechte plankeuzes.
En tot slot de grote dataset, waar de volledige resultaten er als volgt uitzien:
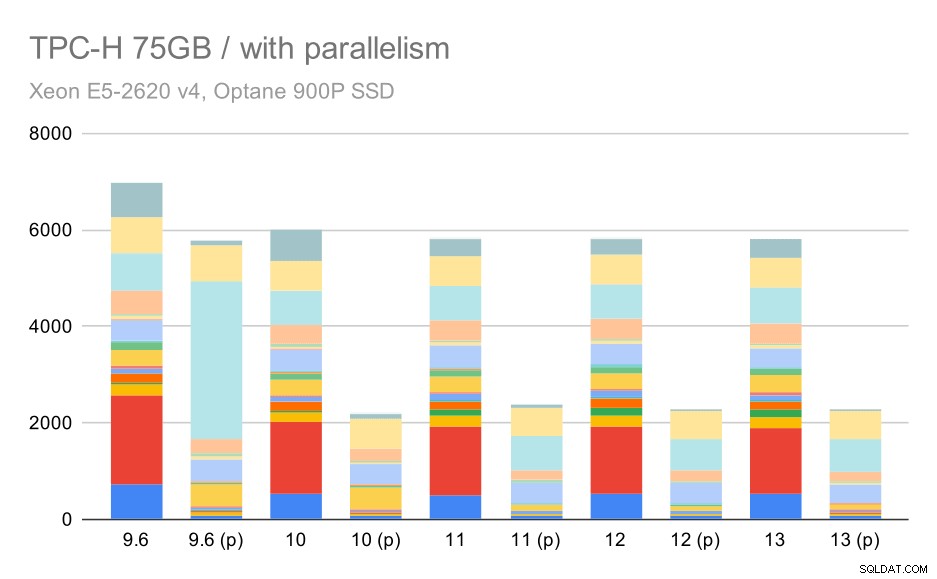
TPC-H-query's op grote dataset (75 GB) - parallellisme ingeschakeld
Hier werkt het inschakelen van het parallellisme in ons voordeel - de optimizer slaagt erin om een goedkoper parallel plan voor Q2 te bouwen, waarbij de slechte plankeuze die in 9.3 is geïntroduceerd, wordt genegeerd. Maar voor de volledigheid, hier zijn de resultaten zonder Q2.
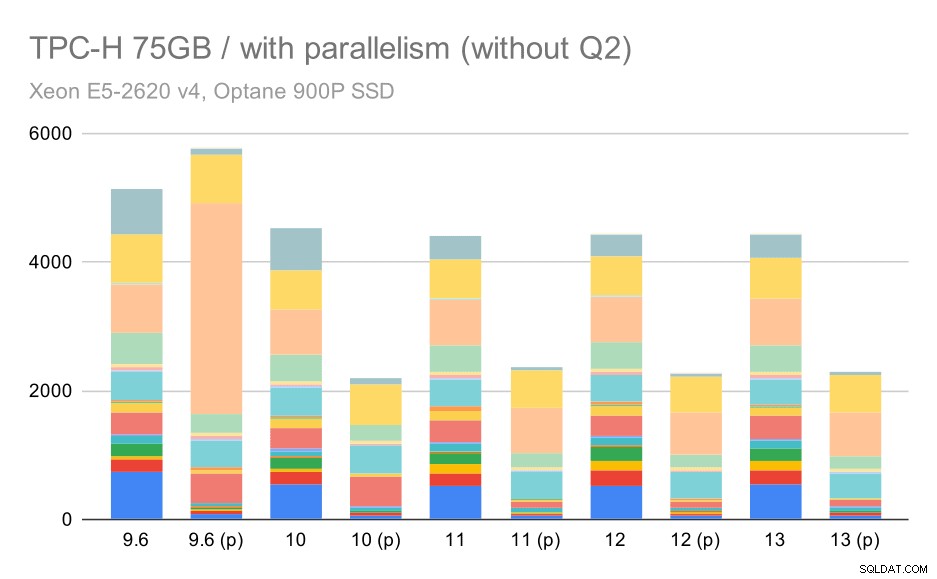
TPC-H-query's op grote dataset (75 GB) - parallellisme ingeschakeld, zonder problematische Q2
Zelfs hier kun je een aantal slechte parallelle plankeuzes zien – het parallelle plan voor Q9 is bijvoorbeeld slechter tot 11, waar het sneller wordt – waarschijnlijk dankzij 11 ondersteuning van extra parallelle uitvoerderknooppunten. Aan de andere kant worden sommige parallelle zoekopdrachten (Q18, Q20) langzamer op 11, dus het zijn niet alleen regenbogen en eenhoorns.
Samenvatting en toekomst
Ik denk dat deze resultaten mooi de optimalisaties demonstreren die sinds PostgreSQL 8.3 zijn geïmplementeerd. De tests met uitgeschakeld parallellisme illustreren verbeteringen in efficiëntie (d.w.z. meer doen met dezelfde hoeveelheid middelen) - het laden van gegevens werd ~30% sneller en query's werden ~2x sneller. Het is waar dat ik een aantal problemen ben tegengekomen met inefficiënte queryplannen, maar dat is een inherent risico bij het slimmer maken van de queryplanner. We werken er voortdurend aan om de resultaten betrouwbaarder te maken en ik weet zeker dat ik de meeste van deze problemen kan verhelpen door de configuratie een beetje aan te passen.
De resultaten met ingeschakeld parallellisme laten zien dat we extra middelen effectief kunnen gebruiken (met name CPU-kernen). Het laden van gegevens lijkt hier niet veel van te profiteren - althans niet in deze benchmark, maar de impact op de uitvoering van query's is aanzienlijk, wat resulteert in ~ 2x sneller (hoewel verschillende query's natuurlijk anders worden beïnvloed).
Er zijn veel mogelijkheden om dit in toekomstige PostgreSQL-versies te verbeteren. Er is bijvoorbeeld een patchreeks die parallellisme implementeert voor COPY, waardoor het laden van gegevens wordt versneld. Er zijn verschillende patches die de uitvoering van analytische query's verbeteren - van kleine gelokaliseerde optimalisaties tot grote projecten zoals opslag en uitvoering in kolommen, geaggregeerde push-down, enz. Er kan veel worden gewonnen door ook declaratieve partitionering te gebruiken - een functie die ik meestal negeerde terwijl ik hieraan werkte benchmark, simpelweg omdat het de reikwijdte veel te veel zou vergroten. En ik weet zeker dat er nog veel meer mogelijkheden zijn die ik me niet eens kan voorstellen, maar slimmere mensen in de PostgreSQL-gemeenschap werken er al aan.
Bijlage:PostgreSQL-configuratie
Parallelisme uitgeschakeld
shared_buffers = 4GB work_mem = 128MB vacuum_cost_limit = 1000 max_wal_size = 24GB checkpoint_timeout = 30min checkpoint_completion_target = 0.9 # logging log_checkpoints = on log_connections = on log_disconnections = on log_line_prefix = '%t %c:%l %x/%v ' log_lock_waits = on log_temp_files = 1024 # parallel query max_parallel_workers_per_gather = 0 max_parallel_maintenance_workers = 0 # optimizer default_statistics_target = 1000 random_page_cost = 60 effective_cache_size = 32GB
Parallelisme ingeschakeld
shared_buffers = 4GB work_mem = 128MB vacuum_cost_limit = 1000 max_wal_size = 24GB checkpoint_timeout = 30min checkpoint_completion_target = 0.9 # logging log_checkpoints = on log_connections = on log_disconnections = on log_line_prefix = '%t %c:%l %x/%v ' log_lock_waits = on log_temp_files = 1024 # parallel query max_parallel_workers_per_gather = 16 max_parallel_maintenance_workers = 16 max_worker_processes = 32 max_parallel_workers = 32 # optimizer default_statistics_target = 1000 random_page_cost = 60 effective_cache_size = 32GB