Welkom bij het derde – en laatste – deel van deze blogreeks, waarin wordt onderzocht hoe de PostgreSQL-prestaties in de loop der jaren zijn geëvolueerd. In het eerste deel werd gekeken naar OLTP-workloads, weergegeven door pgbench-tests. Het tweede deel keek naar analytische / BI-query's, met behulp van een subset van de traditionele TPC-H-benchmark (in wezen een deel van de powertest).
En dit laatste deel kijkt naar full-text zoeken, d.w.z. de mogelijkheid om grote hoeveelheden tekstgegevens te indexeren en te doorzoeken. Dezelfde infrastructuur (vooral de indexen) kan nuttig zijn voor het indexeren van semi-gestructureerde gegevens zoals JSONB-documenten enz., maar daar is deze benchmark niet op gericht.
Maar laten we eerst eens kijken naar de geschiedenis van zoeken in volledige tekst in PostgreSQL, wat misschien een vreemde functie lijkt om toe te voegen aan een RDBMS, dat traditioneel bedoeld was voor het opslaan van gestructureerde gegevens in rijen en kolommen.
De geschiedenis van zoeken in volledige tekst
Toen Postgres in 1996 open source was, had het niets dat we full-text zoeken konden noemen. Maar mensen die Postgres gingen gebruiken, wilden intelligent zoeken in tekstdocumenten, en de LIKE-query's waren niet goed genoeg. Ze wilden de termen kunnen lemmatiseren met behulp van woordenboeken, stopwoorden negeren, de overeenkomende documenten sorteren op relevantie, indexen gebruiken om die zoekopdrachten uit te voeren, en nog veel meer. Dingen die je redelijkerwijs niet kunt doen met de traditionele SQL-operators.
Gelukkig waren sommige van die mensen ook ontwikkelaars, dus begonnen ze hieraan te werken - en dat konden ze, dankzij het feit dat PostgreSQL over de hele wereld als open source beschikbaar was. Er hebben in de loop der jaren veel bijdragen geleverd aan het zoeken in volledige tekst, maar aanvankelijk werd deze inspanning geleid door Oleg Bartunov en Teodor Sigaev, te zien op de volgende foto. Beiden leveren nog steeds een grote bijdrage aan PostgreSQL en werken aan zoeken in volledige tekst, indexering, JSON-ondersteuning en vele andere functies.

Teodor Sigaev en Oleg Bartunov
Aanvankelijk werd de functionaliteit ontwikkeld als een externe "contrib" -module (tegenwoordig zouden we zeggen dat het een extensie is) genaamd "tsearch", uitgebracht in 2002. Later werd dit achterhaald door tsearch2, waardoor de functie op veel manieren aanzienlijk werd verbeterd, en in PostgreSQL 8.3 (uitgebracht in 2008) dit was volledig geïntegreerd in de PostgreSQL-kern (d.w.z. zonder de noodzaak om enige extensie te installeren, hoewel de extensies nog steeds waren voorzien voor achterwaartse compatibiliteit).
Sindsdien zijn er veel verbeteringen geweest (en het werk gaat door, bijvoorbeeld om gegevenstypen zoals JSONB te ondersteunen, query's uit te voeren met behulp van jsonpath enz.). maar deze plug-ins introduceerden de meeste full-text-functionaliteit die we nu in PostgreSQL hebben - woordenboeken, full-text indexering en querymogelijkheden, enz.
De maatstaf
In tegenstelling tot de OLTP / TPC-H-benchmarks, ken ik geen full-text benchmark die als "industriestandaard" kan worden beschouwd of die is ontworpen voor meerdere databasesystemen. De meeste benchmarks die ik ken, zijn bedoeld om te worden gebruikt met een enkele database / product, en het is moeilijk om ze zinvol over te zetten, dus moest ik een andere weg inslaan en mijn eigen full-text benchmark schrijven.
Jaren geleden schreef ik archie - een paar pythonscripts waarmee je PostgreSQL-mailinglijstarchieven kunt downloaden en de geparseerde berichten in een PostgreSQL-database kunt laden, die vervolgens kan worden geïndexeerd en doorzocht. De huidige momentopname van alle archieven heeft ongeveer 1 miljoen rijen en na het laden in een database is de tabel ongeveer 9,5 GB (de indexen niet meegerekend).
Wat betreft de vragen, ik zou waarschijnlijk enkele willekeurige kunnen genereren, maar ik weet niet zeker hoe realistisch dat zou zijn. Gelukkig heb ik een paar jaar geleden een steekproef van 33k daadwerkelijke zoekopdrachten verkregen van de PostgreSQL-website (d.w.z. dingen die mensen daadwerkelijk hebben gezocht in de gemeenschapsarchieven). Het is onwaarschijnlijk dat ik iets realistischer/representatiever zou kunnen krijgen.
De combinatie van die twee delen (dataset + queries) lijkt me een mooie benchmark. We kunnen eenvoudig de gegevens laden en de zoekopdrachten uitvoeren met verschillende soorten full-text-query's met verschillende soorten indexen.
Vragen
Er zijn verschillende vormen van full-text query's - de query kan eenvoudig alle overeenkomende rijen selecteren, de resultaten rangschikken (sorteren op relevantie), slechts een klein aantal of de meest relevante resultaten retourneren, enz. Ik heb een benchmark uitgevoerd met verschillende soorten zoekopdrachten, maar in dit bericht zal ik resultaten presenteren voor twee eenvoudige zoekopdrachten waarvan ik denk dat ze het algemene gedrag redelijk goed weergeven.
- SELECT id, onderwerp FROM berichten WHERE body_tsvector @@ $1
- SELECTEER ID, onderwerp FROM berichten WAAR body_tsvector @@ $1
BESTEL DOOR ts_rank(body_tsvector, $1) DESC LIMIT 100
De eerste zoekopdracht retourneert eenvoudigweg alle overeenkomende rijen, terwijl de tweede de 100 meest relevante resultaten retourneert (dit is iets dat u waarschijnlijk zou gebruiken voor zoekopdrachten van gebruikers).
Ik heb met verschillende andere soorten zoekopdrachten geëxperimenteerd, maar uiteindelijk gedroegen ze zich allemaal op een manier die vergelijkbaar is met een van deze twee soorten zoekopdrachten.
Indexen
Elk bericht heeft twee hoofdonderdelen waarin we kunnen zoeken:onderwerp en hoofdtekst. Elk van hen heeft een afzonderlijke tsvector-kolom en wordt afzonderlijk geïndexeerd. De berichtonderwerpen zijn veel korter dan hoofdteksten, dus de indexen zijn natuurlijk kleiner.
PostgreSQL heeft twee soorten indexen die handig zijn voor zoeken in volledige tekst:GIN en GiST. De belangrijkste verschillen worden uitgelegd in de documenten, maar in het kort:
- GIN-indexen zijn sneller voor zoekopdrachten
- GiST-indexen zijn lossy, d.w.z. moeten tijdens zoekopdrachten opnieuw worden gecontroleerd (en zijn dus langzamer)
Vroeger beweerden we dat GiST-indexen goedkoper te updaten zijn (vooral met veel gelijktijdige sessies), maar dit is enige tijd geleden uit de documentatie verwijderd vanwege verbeteringen in de indexeringscode.
Deze benchmark test het gedrag niet met updates - het laadt gewoon de tabel zonder de volledige tekstindexen, bouwt ze in één keer op en voert vervolgens de 33k-query's op de gegevens uit. Dat betekent dat ik geen uitspraken kan doen over hoe die indextypen omgaan met gelijktijdige updates op basis van deze benchmark, maar ik denk dat de documentatiewijzigingen verschillende recente GIN-verbeteringen weerspiegelen.
Dit zou ook vrij goed moeten overeenkomen met de use-case van het archief van de mailinglijst, waar we slechts af en toe nieuwe e-mails zouden toevoegen (weinig updates, bijna geen gelijktijdigheid van schrijven). Maar als uw toepassing veel gelijktijdige updates uitvoert, moet u dat zelf benchmarken.
De hardware
Ik heb de benchmark gedaan op dezelfde twee machines als voorheen, maar de resultaten/conclusies zijn bijna identiek, dus ik zal alleen de cijfers van de kleinere presenteren, d.w.z.
- CPU i5-2500K (4 cores/threads)
- 8 GB RAM
- 6 x 100 GB SSD RAID0
- kernel 5.6.15, ext4-bestandssysteem
Ik heb eerder vermeld dat de dataset bijna 10 GB heeft wanneer deze is geladen, dus groter dan RAM. Maar de indexen zijn nog steeds kleiner dan RAM, wat belangrijk is voor de benchmark.
Resultaten
Oké, tijd voor wat cijfers en grafieken. Ik zal resultaten presenteren voor zowel het laden van gegevens als het bevragen, eerst met GIN en vervolgens met GiST-indexen.
GIN/gegevens laden
De lading is niet bijzonder interessant, denk ik. Ten eerste heeft het meeste (het blauwe gedeelte) niets te maken met full-text, omdat het gebeurt voordat de twee indexen zijn gemaakt. Het grootste deel van deze tijd wordt besteed aan het ontleden van de berichten, het opnieuw opbouwen van de e-mailthreads, het bijhouden van de lijst met antwoorden, enzovoort. Een deel van deze code is geïmplementeerd in PL/pgSQL-triggers, een deel is buiten de database geïmplementeerd. Het enige deel dat mogelijk relevant is voor full-text is het bouwen van de tsvectors, maar het is onmogelijk om de tijd die daaraan wordt besteed te isoleren.
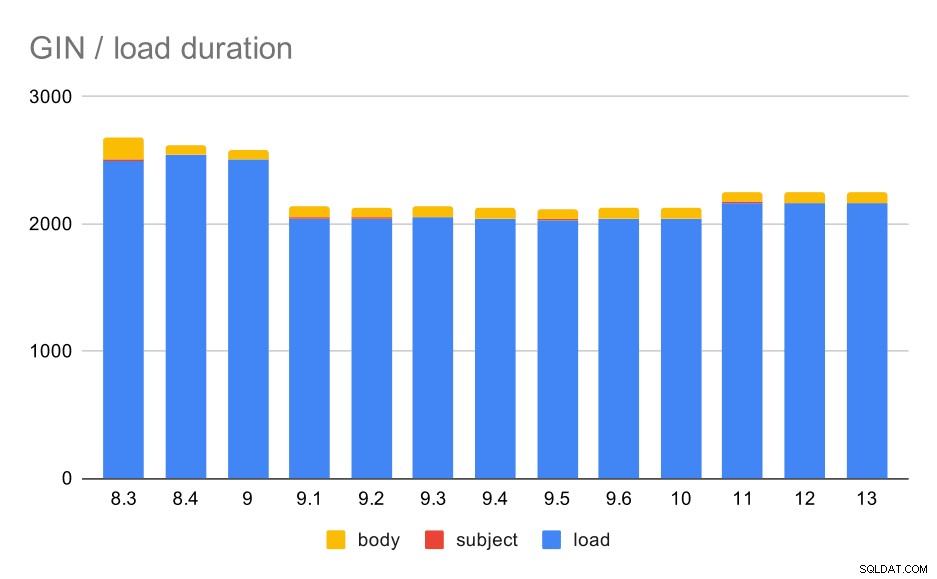
Bewerkingen voor het laden van gegevens met een tabel en GIN-indexen.
De volgende tabel toont de brongegevens voor dit diagram - waarden zijn duur in seconden. LOAD omvat het ontleden van de mbox-archieven (van een Python-script), het invoegen in een tabel en verschillende aanvullende taken (het opnieuw opbouwen van e-mailthreads, enz.). De SUBJECT/BODY INDEX verwijst naar het maken van een full-text GIN-index op de onderwerp/body-kolommen nadat de gegevens zijn geladen.
| LOAD | ONDERWERPINDEX | BODY INDEX | |
| 8,3 | 2501 | 8 | 173 |
| 8.4 | 2540 | 4 | 78 |
| 9.0 | 2502 | 4 | 75 |
| 9.1 | 2046 | 4 | 84 |
| 9.2 | 2045 | 3 | 85 |
| 9.3 | 2049 | 4 | 85 |
| 9.4 | 2043 | 4 | 85 |
| 9.5 | 2034 | 4 | 82 |
| 9,6 | 2039 | 4 | 81 |
| 10 | 2037 | 4 | 82 |
| 11 | 2169 | 4 | 82 |
| 12 | 2164 | 4 | 79 |
| 13 | 2164 | 4 | 81 |
Het is duidelijk dat de prestaties behoorlijk stabiel zijn - er is een vrij aanzienlijke verbetering (ongeveer 20%) tussen 9,0 en 9,1. Ik weet niet helemaal zeker welke verandering verantwoordelijk zou kunnen zijn voor deze verbetering - niets in de release-opmerkingen van 9.1 lijkt duidelijk relevant. Er is ook een duidelijke verbetering in het opbouwen van de GIN-indexen in 8.4, waardoor de tijd ongeveer gehalveerd wordt. Wat natuurlijk leuk is. Interessant genoeg zie ik hier ook geen duidelijk gerelateerd item met release-opmerkingen voor.
Hoe zit het echter met de grootte van de GIN-indexen? Er is veel meer variabiliteit, in ieder geval tot 9,4, waarna de grootte van indexen daalt van ~ 1 GB tot slechts ongeveer 670 MB (ongeveer 30%).
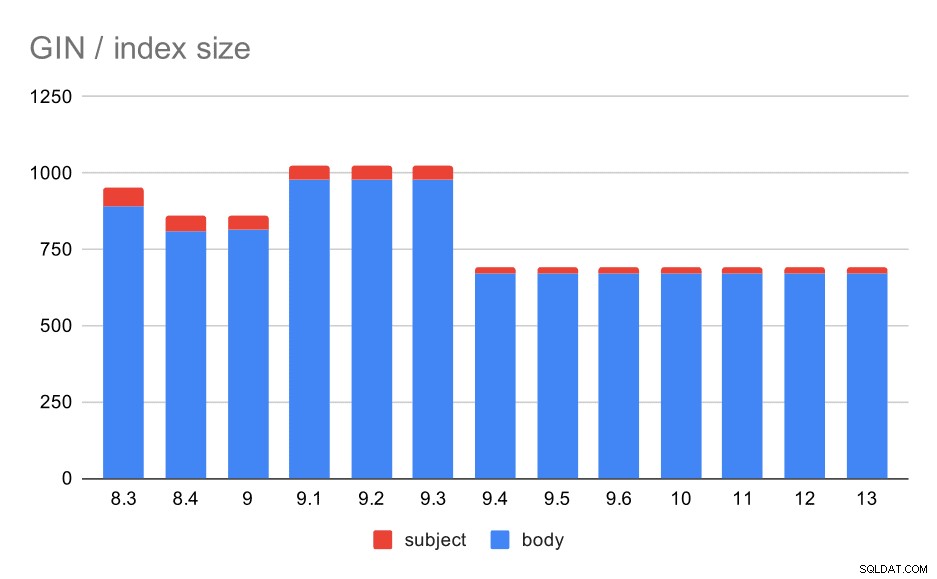
Grootte van GIN-indexen op onderwerp/tekst van het bericht. Waarden zijn megabytes.
De volgende tabel toont de grootte van GIN-indexen op berichttekst en onderwerp. De waarden zijn in megabytes.
| BODY | ONDERWERP | |
| 8.3 | 890 | 62 |
| 8.4 | 811 | 47 |
| 9.0 | 813 | 47 |
| 9.1 | 977 | 47 |
| 9.2 | 978 | 47 |
| 9.3 | 977 | 47 |
| 9.4 | 671 | 20 |
| 9.5 | 671 | 20 |
| 9,6 | 671 | 20 |
| 10 | 672 | 20 |
| 11 | 672 | 20 |
| 12 | 672 | 20 |
| 13 | 672 | 20 |
In dit geval denk ik dat we veilig kunnen aannemen dat deze versnelling verband houdt met dit item in release-opmerkingen 9.4:
- Verminder de grootte van de GIN-index (Alexander Korotkov, Heikki Linnakangas)
De variabiliteit in grootte tussen 8.3 en 9.1 lijkt te wijten te zijn aan veranderingen in lemmatisering (hoe woorden worden getransformeerd naar de "basis" vorm). Afgezien van de verschillen in grootte, leveren de zoekopdrachten op die versies bijvoorbeeld iets andere aantallen resultaten op.
GIN / vragen
Nu, het belangrijkste onderdeel van deze benchmark:queryprestaties. Alle hier gepresenteerde cijfers zijn voor een enkele klant - we hebben de schaalbaarheid van de klant al besproken in het deel met betrekking tot OLTP-prestaties, de bevindingen zijn ook van toepassing op deze vragen. (Bovendien heeft deze specifieke machine slechts 4 cores, dus we zouden sowieso niet ver komen op het gebied van schaalbaarheidstests.)
SELECT id, onderwerp FROM berichten WHERE tsvector @@ $1
Eerst zoekt de zoekopdracht naar alle overeenkomende documenten. Voor zoekopdrachten in de kolom "onderwerp" kunnen we ongeveer 800 zoekopdrachten per seconde doen (en het daalt zelfs een beetje in 9.1), maar in 9.4 schiet het plotseling op tot 3000 zoekopdrachten per seconde. Voor de kolom 'body' is het eigenlijk hetzelfde verhaal:aanvankelijk 160 zoekopdrachten, een daling tot ~90 zoekopdrachten in 9.1 en vervolgens een toename tot 300 in 9.4.
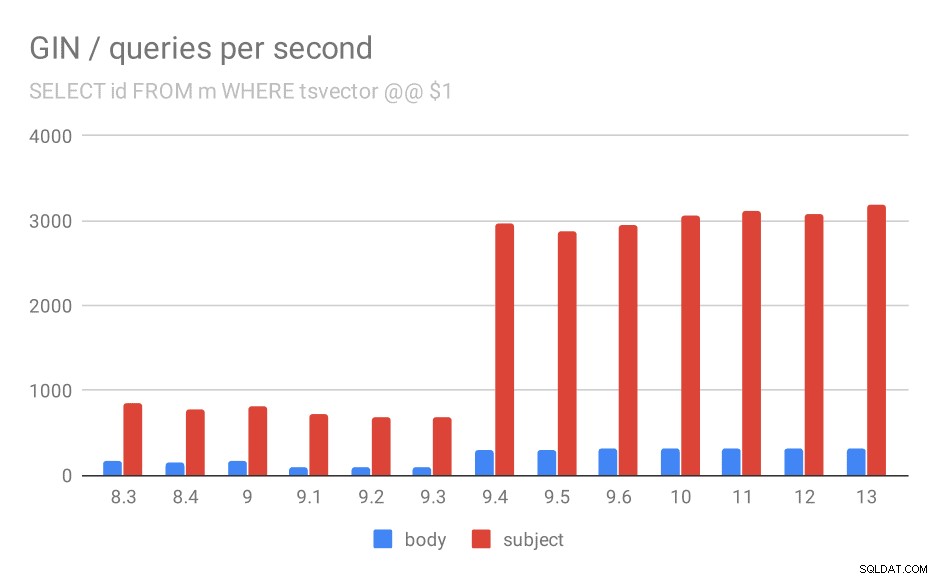
Aantal zoekopdrachten per seconde voor de eerste zoekopdracht (alle overeenkomende rijen worden opgehaald).
En nogmaals, de brongegevens - de cijfers zijn doorvoer (query's per seconde).
| BODY | ONDERWERP | |
| 8.3 | 168 | 848 |
| 8.4 | 155 | 774 |
| 9.0 | 160 | 816 |
| 9.1 | 93 | 712 |
| 9.2 | 93 | 675 |
| 9.3 | 95 | 692 |
| 9.4 | 303 | 2966 |
| 9.5 | 303 | 2871 |
| 9,6 | 310 | 2942 |
| 10 | 311 | 3066 |
| 11 | 317 | 3121 |
| 12 | 312 | 3085 |
| 13 | 320 | 3192 |
Ik denk dat we veilig kunnen aannemen dat de verbetering in 9.4 gerelateerd is aan dit item in de release-opmerkingen:
- Verbeter de snelheid van multi-key GIN-zoekopdrachten (Alexander Korotkov, Heikki Linnakangas)
Dus nog een 9.4-verbetering in GIN van dezelfde twee ontwikkelaars - het is duidelijk dat Alexander en Heikki veel goed werk hebben gedaan aan GIN-indexen in de 9.4-release 😉
SELECTEER ID, onderwerp FROM berichten WAAR tsvector @@ $1
BESTEL DOOR ts_rank(tsvector, $2) DESC LIMIT 100
Voor de zoekopdracht die de resultaten rangschikt op relevantie met behulp van ts_rank en LIMIT, is het algemene gedrag bijna precies hetzelfde, ik denk dat het niet nodig is om de grafiek in detail te beschrijven.
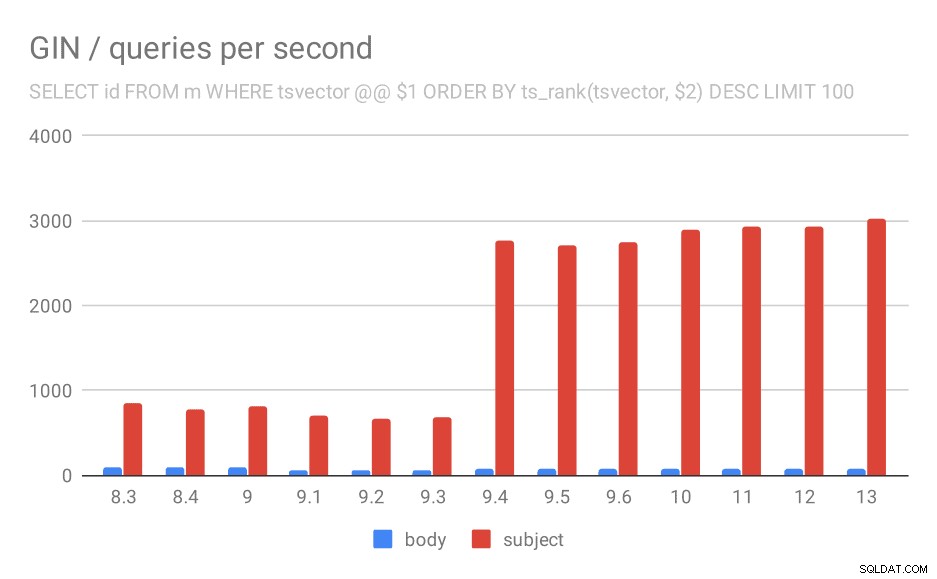
Aantal zoekopdrachten per seconde voor de tweede zoekopdracht (ophalen van de meest relevante rijen).
| BODY | ONDERWERP | |
| 8.3 | 94 | 840 |
| 8.4 | 98 | 775 |
| 9.0 | 102 | 818 |
| 9.1 | 51 | 704 |
| 9.2 | 51 | 666 |
| 9.3 | 51 | 678 |
| 9.4 | 80 | 2766 |
| 9.5 | 81 | 2704 |
| 9,6 | 78 | 2750 |
| 10 | 78 | 2886 |
| 11 | 79 | 2938 |
| 12 | 78 | 2924 |
| 13 | 77 | 3028 |
Er is echter één vraag:waarom zijn de prestaties gedaald tussen 9.0 en 9.1? Er lijkt een behoorlijk significante daling van de doorvoer te zijn - met ongeveer 50% voor de body-zoekopdrachten en 20% voor zoekopdrachten in berichtonderwerpen. Ik heb geen duidelijke verklaring voor wat er is gebeurd, maar ik heb twee opmerkingen ...
Ten eerste is de indexgrootte gewijzigd - als je naar de eerste grafiek "GIN / indexgrootte" en de tabel kijkt, zie je dat de index op berichtlichamen groeide van 813 MB tot ongeveer 977 MB. Dat is een aanzienlijke toename, en het zou een deel van de vertraging kunnen verklaren. Het probleem is echter dat de index op onderwerpen helemaal niet groeide, maar de zoekopdrachten werden ook langzamer.
Ten tweede kunnen we kijken hoeveel resultaten de query's hebben geretourneerd. De geïndexeerde dataset is precies hetzelfde, dus het lijkt redelijk om hetzelfde aantal resultaten te verwachten in alle PostgreSQL-versies, toch? Nou, in de praktijk ziet het er zo uit:
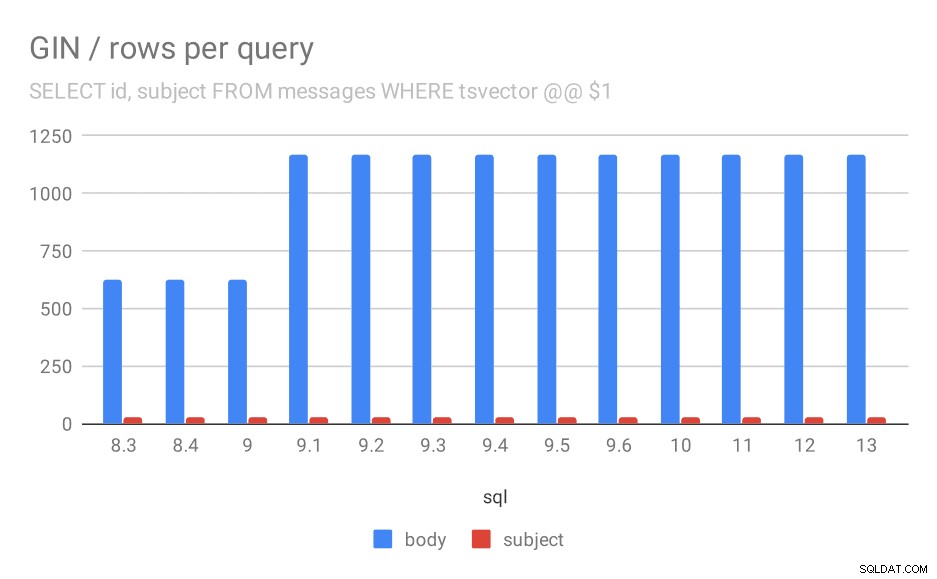
Gemiddeld aantal geretourneerde rijen voor een zoekopdracht.
| BODY | ONDERWERP | |
| 8.3 | 624 | 26 |
| 8.4 | 624 | 26 |
| 9.0 | 622 | 26 |
| 9.1 | 1165 | 26 |
| 9.2 | 1165 | 26 |
| 9.3 | 1165 | 26 |
| 9.4 | 1165 | 26 |
| 9.5 | 1165 | 26 |
| 9,6 | 1165 | 26 |
| 10 | 1165 | 26 |
| 11 | 1165 | 26 |
| 12 | 1165 | 26 |
| 13 | 1165 | 26 |
Het is duidelijk dat in 9.1 het gemiddelde aantal resultaten voor zoekopdrachten in berichtlichamen plotseling verdubbelt, wat bijna perfect evenredig is met de vertraging. Het aantal resultaten voor zoekopdrachten op onderwerp blijft echter hetzelfde. Ik heb hier geen goede verklaring voor, behalve dat de indexering zodanig is gewijzigd dat het mogelijk is meer berichten te matchen, maar het een beetje langzamer maakt. Als je betere verklaringen hebt, hoor ik ze graag!
GiST/gegevens laden
Nu, het andere type full-text indexen - GiST. Deze indexen zijn lossy, d.w.z. dat de resultaten opnieuw moeten worden gecontroleerd met behulp van waarden uit de tabel. We kunnen dus een lagere doorvoer verwachten in vergelijking met de GIN-indexen, maar verder is het redelijk om ongeveer hetzelfde patroon te verwachten.
De laadtijden komen inderdaad bijna perfect overeen met de GIN - de tijden voor het maken van de index zijn anders, maar het algemene patroon is hetzelfde. Versnelling in 9.1, kleine vertraging in 11.
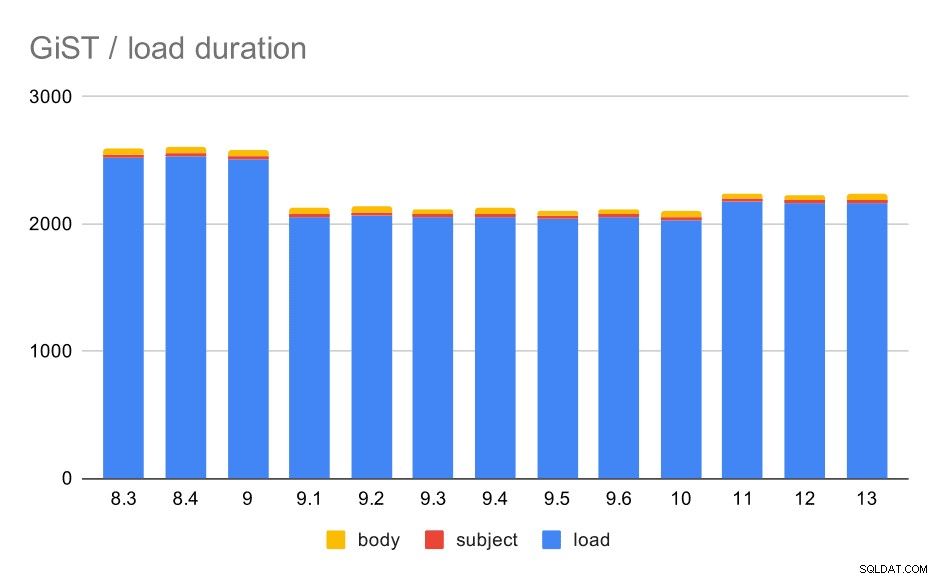
Bewerkingen voor het laden van gegevens met een tabel en GiST-indexen.
| LOAD | ONDERWERP | BODY | |
| 8.3 | 2522 | 23 | 47 |
| 8.4 | 2527 | 23 | 49 |
| 9.0 | 2511 | 23 | 45 |
| 9.1 | 2054 | 22 | 46 |
| 9.2 | 2067 | 22 | 47 |
| 9.3 | 2049 | 23 | 46 |
| 9.4 | 2055 | 23 | 47 |
| 9.5 | 2038 | 22 | 45 |
| 9,6 | 2052 | 22 | 44 |
| 10 | 2029 | 22 | 49 |
| 11 | 2174 | 22 | 46 |
| 12 | 2162 | 22 | 46 |
| 13 | 2170 | 22 | 44 |
De indexgrootte bleef echter vrijwel constant - er waren geen GiST-verbeteringen vergelijkbaar met GIN in 9.4, waardoor de grootte met ~30% werd verminderd. Er is een toename van 9.1, wat een ander teken is dat de indexering van de volledige tekst in die versie is gewijzigd om meer woorden te indexeren.
Dit wordt verder ondersteund door het gemiddeld aantal resultaten waarbij GiST precies hetzelfde is als voor GIN (met een stijging van 9,1).
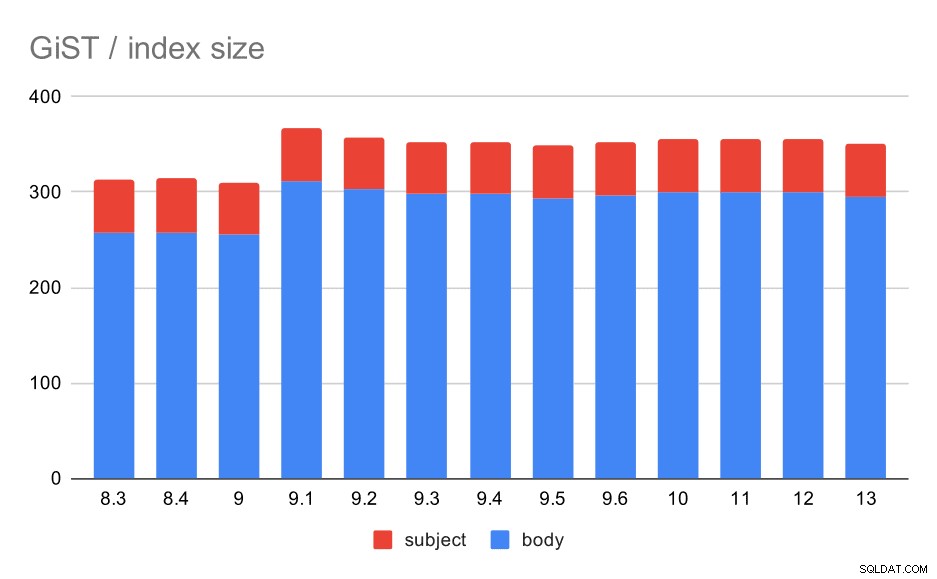
Grootte van GiST-indexen op onderwerp/hoofdtekst van bericht. Waarden zijn megabytes.
| BODY | ONDERWERP | |
| 8.3 | 257 | 56 |
| 8.4 | 258 | 56 |
| 9.0 | 255 | 55 |
| 9.1 | 312 | 55 |
| 9.2 | 303 | 55 |
| 9.3 | 298 | 55 |
| 9.4 | 298 | 55 |
| 9.5 | 294 | 55 |
| 9.6 | 297 | 55 |
| 10 | 300 | 55 |
| 11 | 300 | 55 |
| 12 | 300 | 55 |
| 13 | 295 | 55 |
GiST / queries
Unfortunately, for the queries the results are nowhere as good as for GIN, where the throughput more than tripled in 9.4. With GiST indexes, we actually observe continuous degradation over the time.
SELECT id, subject FROM messages WHERE tsvector @@ $1
Even if we ignore versions before 9.1 (due to the indexes being smaller and returning fewer results faster), the throughput drops from ~270 to ~200 queries per second, with the main drop between 9.2 and 9.3.
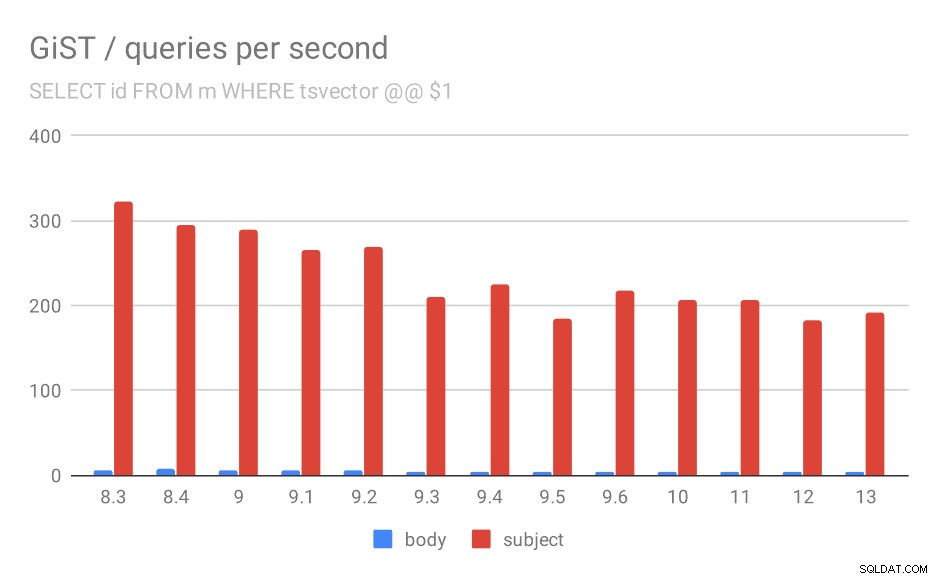
Number of queries per second for the first query (fetching all matching rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 322 |
| 8.4 | 7 | 295 |
| 9.0 | 6 | 290 |
| 9.1 | 5 | 265 |
| 9.2 | 5 | 269 |
| 9.3 | 4 | 211 |
| 9.4 | 4 | 225 |
| 9.5 | 4 | 185 |
| 9.6 | 4 | 217 |
| 10 | 4 | 206 |
| 11 | 4 | 206 |
| 12 | 4 | 183 |
| 13 | 4 | 191 |
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
And for queries with ts_rank the behavior is almost exactly the same.
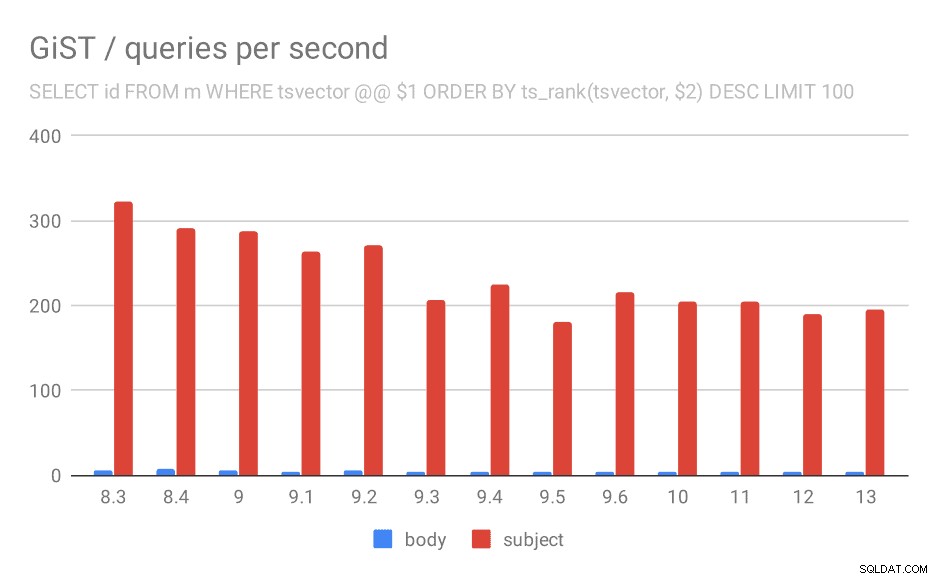
Number of queries per second for the second query (fetching the most relevant rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 323 |
| 8.4 | 7 | 291 |
| 9.0 | 6 | 288 |
| 9.1 | 4 | 264 |
| 9.2 | 5 | 270 |
| 9.3 | 4 | 207 |
| 9.4 | 4 | 224 |
| 9.5 | 4 | 181 |
| 9.6 | 4 | 216 |
| 10 | 4 | 205 |
| 11 | 4 | 205 |
| 12 | 4 | 189 |
| 13 | 4 | 195 |
I’m not entirely sure what’s causing this, but it seems like a potentially serious regression sometime in the past, and it might be interesting to know what exactly changed.
It’s true no one complained about this until now – possibly thanks to upgrading to a faster hardware which masked the impact, or maybe because if you really care about speed of the searches you will prefer GIN indexes anyway.
But we can also see this as an optimization opportunity – if we identify what caused the regression and we manage to undo that, it might mean ~30% speedup for GiST indexes.
Summary and future
By now I’ve (hopefully) convinced you there were many significant improvements since PostgreSQL 8.3 (and in 9.4 in particular). I don’t know how much faster can this be made, but I hope we’ll investigate at least some of the regressions in GiST (even if performance-sensitive systems are likely using GIN). Oleg and Teodor and their colleagues were working on more powerful variants of the GIN indexing, named VODKA and RUM (I kinda see a naming pattern here!), and this will probably help at least some query types.
I do however expect to see features buil extending the existing full-text capabilities – either to better support new query types (e.g. the new index types are designed to speed up phrase search), data types and things introduced by recent revisions of the SQL standard (like jsonpath).