Een paar jaar geleden (op de pgconf.eu 2014 in Madrid) presenteerde ik een lezing genaamd "Performance Archaeology", die liet zien hoe de prestaties veranderden in recente PostgreSQL-releases. Ik deed dat gesprek omdat ik denk dat de langetermijnvisie interessant is en ons inzichten kan geven die heel waardevol kunnen zijn. Voor mensen die daadwerkelijk aan PostgreSQL-code werken, zoals ik, is het een nuttige gids voor toekomstige ontwikkeling, en voor PostgreSQL-gebruikers kan het helpen bij het evalueren van upgrades.
Daarom heb ik besloten deze oefening te herhalen en een paar blogposts te schrijven waarin ik de prestaties van een aantal PostgreSQL-versies analyseer. In de talk van 2014 begon ik met PostgreSQL 7.4, dat op dat moment ongeveer 10 jaar oud was (uitgebracht in 2003). Deze keer begin ik met PostgreSQL 8.3, dat ongeveer 12 jaar oud is.
Waarom niet opnieuw beginnen met PostgreSQL 7.4? Er zijn ongeveer drie hoofdredenen waarom ik besloot te beginnen met PostgreSQL 8.3. Ten eerste algemene luiheid. Hoe ouder de versie, hoe moeilijker het kan zijn om te bouwen met de huidige compilerversies enz. Ten tweede kost het tijd om goede benchmarks uit te voeren, vooral met grotere hoeveelheden gegevens, dus het toevoegen van een enkele hoofdversie kan gemakkelijk een paar dagen machinetijd toevoegen. Het leek het gewoon niet waard. En tot slot introduceerde 8.3 een aantal belangrijke wijzigingen:autovacuümverbeteringen (standaard ingeschakeld, gelijktijdige werkprocessen, ...), zoeken in volledige tekst geïntegreerd in de kern, gespreide controlepunten, enzovoort. Dus ik denk dat het volkomen logisch is om met PostgreSQL 8.3 te beginnen. Die ongeveer 12 jaar geleden werd uitgebracht, dus deze vergelijking dekt eigenlijk een langere periode.
Ik heb besloten om drie basistypen werkbelasting te benchmarken:OLTP, analyse en zoeken in volledige tekst. Ik denk dat de OLTP en analyse vrij voor de hand liggende keuzes zijn, aangezien de meeste toepassingen een mix zijn van die twee basistypen. Door de volledige tekst te zoeken kan ik verbeteringen demonstreren in speciale typen indexen, die ook worden gebruikt om populaire gegevenstypen zoals JSONB, typen die worden gebruikt door PostGIS enz. te indexeren.
Waarom doe je dit überhaupt?
Is het echt de moeite? We doen immers voortdurend benchmarks tijdens de ontwikkeling om aan te tonen dat een patch helpt en/of dat het geen regressie veroorzaakt, toch? Het probleem is dat dit meestal slechts "gedeeltelijke" benchmarks zijn, waarbij twee specifieke commits worden vergeleken, en meestal met een vrij beperkte selectie van workloads waarvan we denken dat ze relevant kunnen zijn. Dat is volkomen logisch - je kunt gewoon niet een volledige batterij aan workloads uitvoeren voor elke commit.
Af en toe (meestal kort na het uitbrengen van een nieuwe hoofdversie van PostgreSQL) voeren mensen tests uit om de nieuwe versie te vergelijken met de vorige, wat leuk is en ik moedig u aan om dergelijke benchmarks uit te voeren (of het nu een soort standaardbenchmark is, of iets specifieks voor uw toepassing). Maar het is moeilijk om deze resultaten te combineren in een langetermijnvisie, omdat die tests verschillende configuraties en hardware gebruiken (meestal een recentere voor de nieuwere versie), enzovoort. Het is dus moeilijk om duidelijke uitspraken te doen over veranderingen in het algemeen.
Hetzelfde geldt voor applicatieprestaties, wat natuurlijk de "ultieme benchmark" is. Maar mensen mogen niet upgraden naar elke hoofdversie (soms kunnen ze een paar versies overslaan, bijvoorbeeld van 9.5 naar 12). En wanneer ze upgraden, wordt dit vaak gecombineerd met hardware-upgrades enz. Om nog maar te zwijgen van het feit dat applicaties in de loop van de tijd evolueren (nieuwe functies, extra complexiteit), de hoeveelheden gegevens en het aantal gelijktijdige gebruikers groeien, enz.
Dat is wat deze blogserie probeert te laten zien:langetermijntrends in PostgreSQL-prestaties voor sommige basisworkloads, zodat wij - de ontwikkelaars - een warm en vaag gevoel krijgen over het goede werk door de jaren heen. En om gebruikers te laten zien dat hoewel PostgreSQL op dit moment een volwassen product is, er nog steeds aanzienlijke verbeteringen zijn in elke nieuwe belangrijke versie.
Het is niet mijn doel om deze benchmarks te gebruiken voor vergelijking met andere databaseproducten, of om resultaten te produceren die voldoen aan een officiële ranking (zoals die van TPC-H). Mijn doel is gewoon om mezelf op te leiden als PostgreSQL-ontwikkelaar, misschien wat problemen te identificeren en te onderzoeken, en de bevindingen met anderen te delen.
Eerlijke vergelijking?
Ik denk niet dat dergelijke vergelijkingen van versies die over 12 jaar zijn uitgebracht, niet helemaal eerlijk kunnen zijn, omdat alle software in een bepaalde context wordt ontwikkeld - hardware is een goed voorbeeld voor een databasesysteem. Als je kijkt naar de machines die je 12 jaar geleden gebruikte, hoeveel cores hadden ze, hoeveel RAM? Welk type opslag hebben ze gebruikt?
Een typische midrange-server in 2008 had misschien 8-12 cores, 16 GB RAM en een RAID met een paar SAS-schijven. Een typische midrange-server van tegenwoordig heeft misschien een paar tientallen kernen, honderden GB RAM en SSD-opslag.
Softwareontwikkeling wordt georganiseerd op prioriteit - er zijn altijd meer potentiële taken dan waar u tijd voor heeft, dus u moet taken kiezen met de beste kosten-batenverhouding voor uw gebruikers (vooral degenen die het project direct of indirect financieren). En in 2008 waren sommige optimalisaties waarschijnlijk nog niet relevant - de meeste machines hadden geen extreme hoeveelheden RAM, dus optimaliseren voor grote gedeelde buffers was bijvoorbeeld nog niet de moeite waard. En veel van de CPU-knelpunten werden overschaduwd door I/O, omdat de meeste machines "spinning roest" -opslag hadden.
Opmerking:Natuurlijk waren er toen al klanten die behoorlijk grote machines gebruikten. Sommigen gebruikten community Postgres met verschillende aanpassingen, anderen besloten om te werken met een van de verschillende Postgres-forks met extra mogelijkheden (bijvoorbeeld massaal parallellisme, gedistribueerde zoekopdrachten, gebruik van FPGA enz.). En dit had natuurlijk ook invloed op de ontwikkeling van de gemeenschap.
Naarmate de grotere machines in de loop der jaren steeds gebruikelijker werden, konden meer mensen zich machines veroorloven met grote hoeveelheden RAM en een hoog aantal cores, waardoor de kosten-batenverhouding veranderde. De knelpunten werden onderzocht en aangepakt, waardoor nieuwere versies beter konden presteren.
Dit betekent dat een benchmark als deze altijd een beetje oneerlijk is - het zal de voorkeur geven aan de oudere of nieuwere versie, afhankelijk van de setup (hardware, configuratie). Ik heb geprobeerd hardware- en configuratieparameters te kiezen, zodat het niet al te slecht is voor oudere versies.
Het punt dat ik probeer te maken is dat dit niet betekent dat de oudere PostgreSQL-versies waardeloos waren - dit is hoe softwareontwikkeling werkt. U adresseert de knelpunten die uw gebruikers waarschijnlijk zullen tegenkomen, niet de knelpunten die ze over 10 jaar kunnen tegenkomen.
Hardware
Ik doe liever benchmarks op fysieke hardware waar ik direct toegang toe heb, omdat ik dan alle details kan controleren, ik toegang heb tot alle details, enzovoort. Dus ik heb de machine gebruikt die ik in ons kantoor heb – niets bijzonders, maar hopelijk goed genoeg voor dit doel.
- 2x E5-2620 v4 (16 cores, 32 threads)
- 64 GB RAM
- Intel Optane 900P 280GB NVMe SSD (gegevens)
- 3 x 7.2k SATA RAID0 (tijdelijke tabelruimte)
- kernel 5.6.15, ext4
- gcc 9.2.0, clang 9.0.1
Ik heb ook een tweede – veel kleinere – machine gebruikt, met slechts 4 cores en 8GB RAM, die over het algemeen dezelfde verbeteringen/regressies laat zien, alleen minder uitgesproken.
pgbench
Als benchmarking tool heb ik de bekende pgbench gebruikt, met de nieuwste versie (van PostgreSQL 13) om alle versies te testen. Dit elimineert mogelijke vertekening als gevolg van optimalisaties die in de loop van de tijd in pgbench zijn gedaan, waardoor de resultaten beter vergelijkbaar worden.
De benchmark test een aantal verschillende gevallen, waarbij een aantal parameters wordt gevarieerd, namelijk:
schaal
- klein – gegevens passen in gedeelde buffers, waardoor vergrendelingsproblemen enz. worden weergegeven.
- medium – gegevens groter dan gedeelde buffers maar passen in RAM, meestal CPU-gebonden (of mogelijk I/O voor lees-schrijfwerkbelastingen)
- groot – gegevens groter dan RAM, voornamelijk I/O-gebonden
modi
- alleen-lezen – pgbench -S
- lezen-schrijven – pgbench -N
klantenaantallen
- 1, 4, 8, 16, 32, 64, 128, 256
- het aantal pgbench-threads (-j) wordt dienovereenkomstig aangepast
Resultaten
Oké, laten we eens kijken naar de resultaten. Ik zal eerst de resultaten van de NVMe-opslag presenteren, daarna zal ik enkele interessante resultaten laten zien met behulp van de SATA RAID-opslag.
NVMe SSD / alleen-lezen
Voor de kleine dataset (die volledig in gedeelde buffers past), zien de alleen-lezen resultaten er als volgt uit:
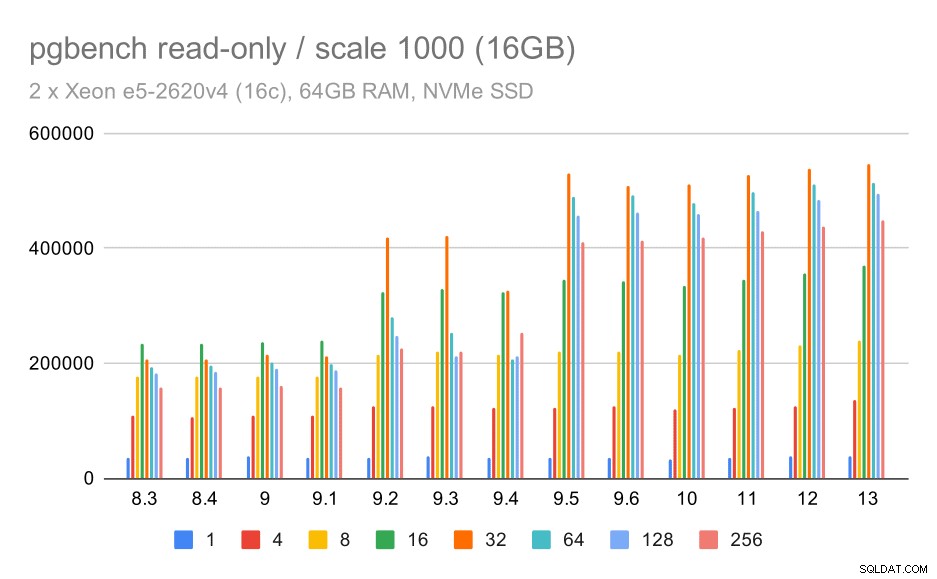
pgbench-resultaten / alleen-lezen op kleine dataset (schaal 100, d.w.z. 1,6 GB)
Er was duidelijk een aanzienlijke toename van de doorvoer in 9.2, die een aantal prestatieverbeteringen bevatte, bijvoorbeeld fast-path voor vergrendeling. De doorvoer voor een enkele client daalt eigenlijk een beetje - van 47k tps naar slechts ongeveer 42k tps. Maar voor hogere klantenaantallen is de verbetering in 9.2 vrij duidelijk.
pgbench resultaten / alleen-lezen op medium dataset (schaal 1000, d.w.z. 16GB)
Voor de middelgrote dataset (die groter is dan gedeelde buffers maar nog steeds in RAM past) lijkt er ook enige verbetering in 9.2 te zijn, hoewel niet zo duidelijk als hierboven, gevolgd door een veel duidelijkere verbetering in 9.5, hoogstwaarschijnlijk dankzij verbeteringen aan de schaalbaarheid van het slot .
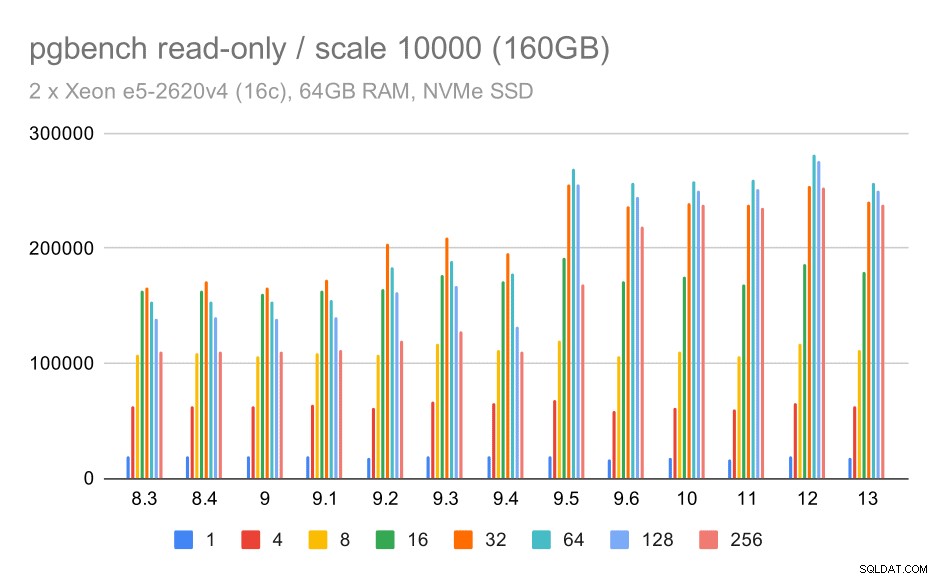
pgbench resultaten / alleen-lezen op grote dataset (schaal 10000, d.w.z. 160GB)
Op de grootste dataset, die vooral gaat over de mogelijkheid om de opslag efficiënt te gebruiken, is er ook enige versnelling - hoogstwaarschijnlijk ook dankzij de 9.5-verbeteringen.
NVMe SSD / lezen-schrijven
De lees-schrijfresultaten laten ook enkele verbeteringen zien, hoewel niet zo uitgesproken. Op de kleine dataset zien de resultaten er als volgt uit:
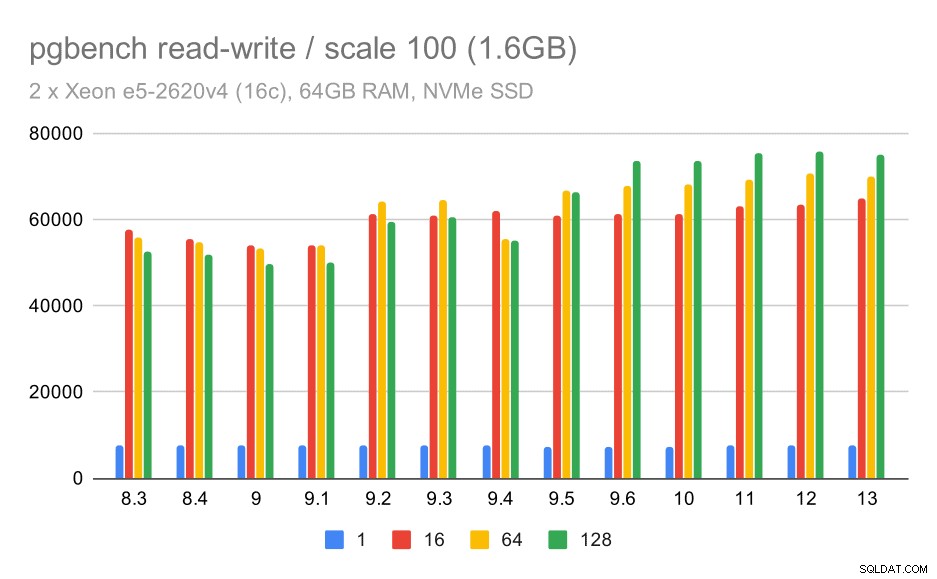
pgbench-resultaten / lezen-schrijven op kleine dataset (schaal 100, d.w.z. 1,6 GB)
Dus een bescheiden verbetering van ongeveer 52k naar 75k tps met voldoende aantal clients.
Voor de middelgrote dataset is de verbetering veel duidelijker - van ongeveer 27k tot 63k tps, d.w.z. de doorvoer verdubbelt meer dan.
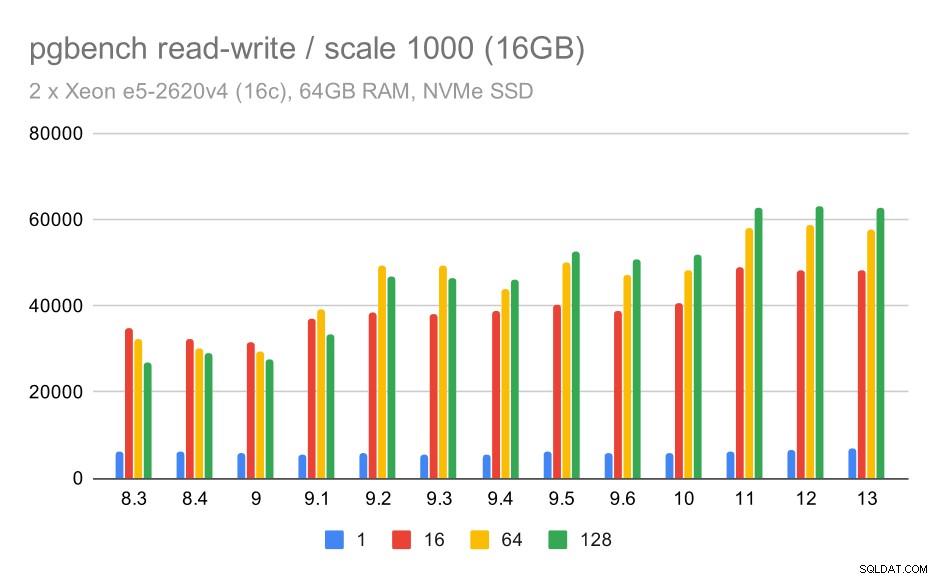
pgbench resultaten / lezen-schrijven op medium dataset (schaal 1000, d.w.z. 16GB)
Voor de grootste dataset zien we een vergelijkbare algemene verbetering, maar er lijkt enige regressie te zijn tussen 9,5 en 11.
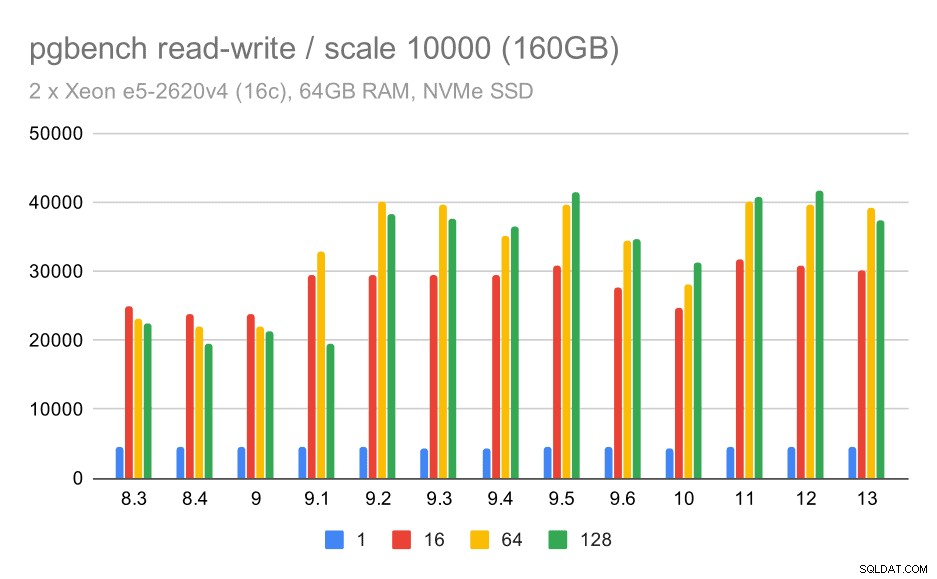
pgbench resultaten / lezen-schrijven op grote dataset (schaal 10000, d.w.z. 160GB)
SATA RAID / alleen-lezen
Voor de SATA RAID-opslag zijn de alleen-lezen resultaten niet zo mooi. We kunnen voorbijgaan aan de kleine en middelgrote datasets, waarvoor het opslagsysteem niet relevant is. Voor de grote dataset is de doorvoer enigszins luidruchtig, maar deze lijkt in de loop van de tijd af te nemen, vooral sinds PostgreSQL 9.6. Ik weet niet wat de reden hiervoor is (niets in de release-opmerkingen van 9.6 springt eruit als een duidelijke kandidaat), maar het lijkt op een soort regressie.
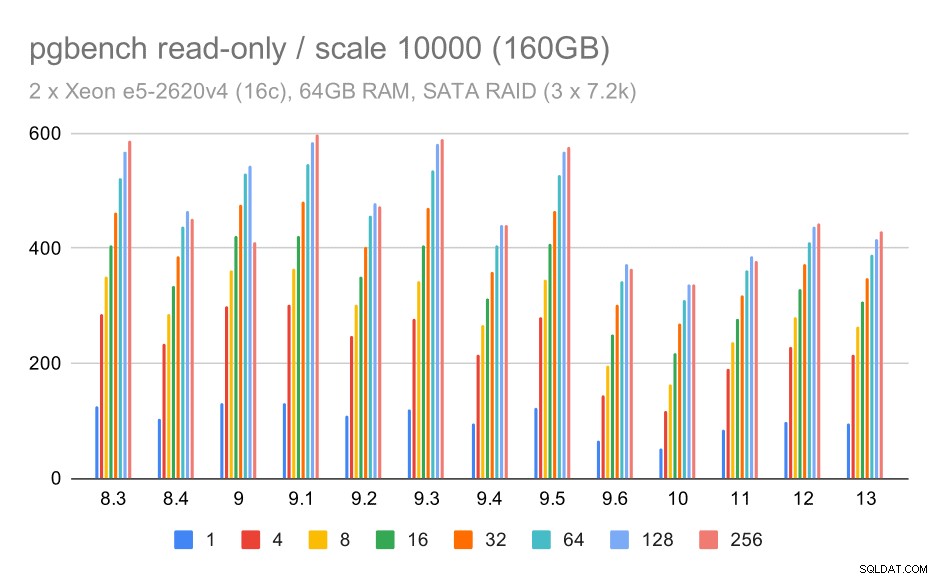
pgbench resultaten op SATA RAID / alleen-lezen op grote dataset (schaal 10000, d.w.z. 160GB)
SATA RAID / lezen-schrijven
Het lees-schrijfgedrag lijkt echter veel prettiger. Op de kleine dataset neemt de doorvoer toe van ongeveer 600 tps tot meer dan 6000 tps. Ik wed dat dit te danken is aan verbeteringen aan de groepscommit in 9.1 en 9.2.
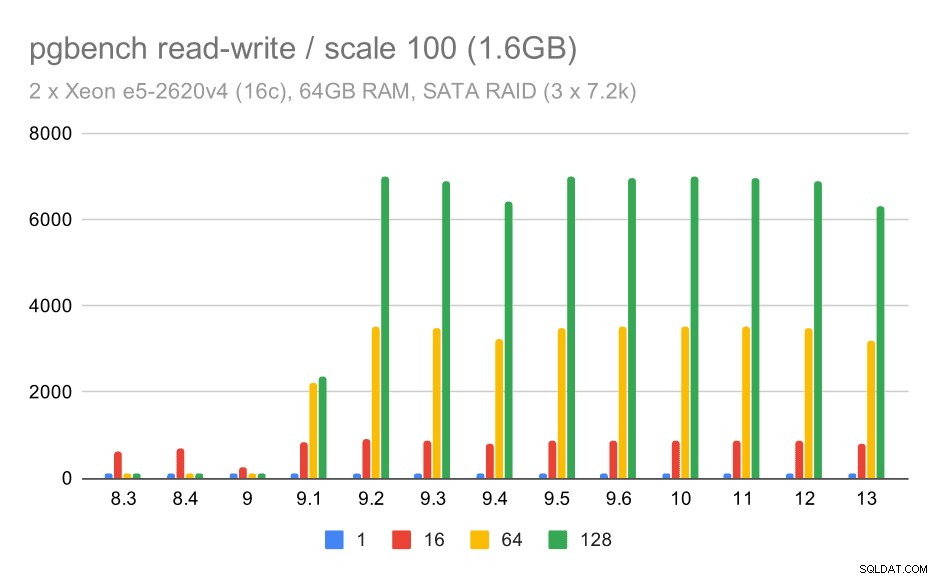
pgbench resultaten op SATA RAID / read-write op kleine dataset (schaal 100, d.w.z. 1,6 GB)
Voor de middelgrote en grote schaal zien we vergelijkbare – maar kleinere – verbetering, omdat de opslag ook de I/O-verzoeken moet verwerken om de datablokken te lezen en te schrijven. Voor de middelgrote schaal hoeven we alleen de schrijfbewerkingen uit te voeren (omdat de gegevens in het RAM passen), voor de grote schaal moeten we ook de leesbewerkingen doen - dus de maximale doorvoer is nog lager.
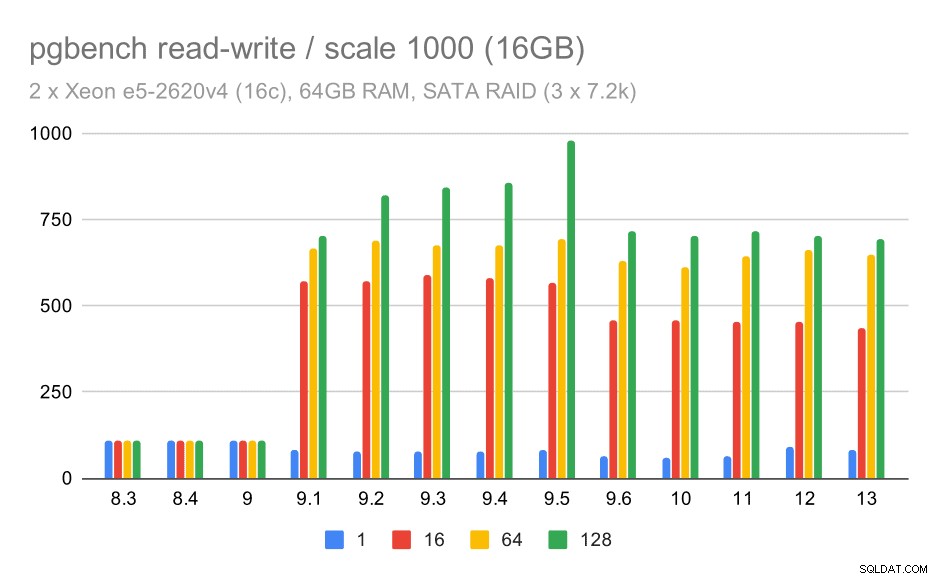
pgbench resultaten op SATA RAID / read-write op medium dataset (schaal 1000, d.w.z. 16GB)
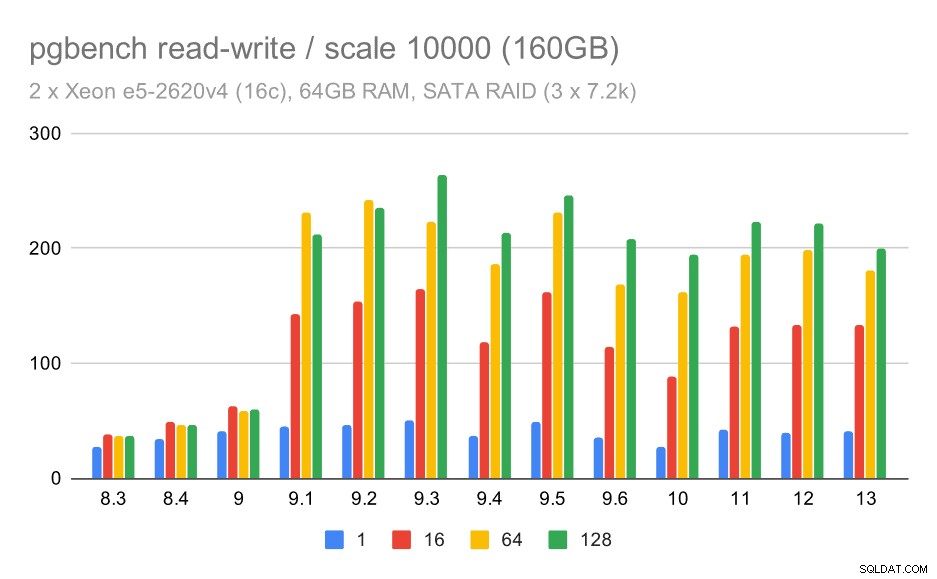
pgbench resultaten op SATA RAID / read-write op grote dataset (schaal 10000, d.w.z. 160GB)
Samenvatting en toekomst
Om dit samen te vatten, voor de NVMe-opstelling lijken de conclusies redelijk positief. Voor de alleen-lezen-workload is er een matige versnelling in 9.2 en een aanzienlijke versnelling in 9.5, dankzij schaalbaarheidsoptimalisaties, terwijl voor de lees-schrijfwerkbelasting de prestaties in de loop van de tijd met ongeveer 2x zijn verbeterd, in meerdere versies/stappen.
Met de SATA RAID-configuratie zijn de conclusies echter enigszins gemengd. In het geval van de alleen-lezen werkbelasting is er veel variabiliteit / ruis en mogelijke regressie in 9.6. Voor de lees-schrijfwerklast is er een enorme versnelling in 9.1, waarbij de doorvoer plotseling toenam van 100 tps naar ongeveer 600 tps.
Hoe zit het met verbeteringen in toekomstige PostgreSQL-versies? Ik heb geen duidelijk idee wat de volgende grote verbetering zal zijn – ik ben er echter zeker van dat andere PostgreSQL-hackers met briljante ideeën zullen komen die dingen efficiënter maken of het mogelijk maken om beschikbare hardwarebronnen te benutten. De patch om de schaalbaarheid met veel verbindingen te verbeteren of de patch om ondersteuning toe te voegen voor niet-vluchtige WAL-buffers zijn voorbeelden van dergelijke verbeteringen. Mogelijk zien we enkele radicale verbeteringen aan PostgreSQL-opslag (efficiënter formaat op schijf, gebruik van directe I/O enz.), indexering, enz.