Welke problemen gaan we overwegen?
Als de server meldt dat er geen ruimte meer is op de E-schijf, is er geen diepgaande analyse nodig. Fouten waarvan de oplossing duidelijk blijkt uit de tekst van het bericht zullen we niet in overweging nemen en waarvoor Google meteen een link naar MSDN gooit met de oplossing.
Laten we eens kijken naar de problemen die niet voor de hand liggen voor Google, zoals bijvoorbeeld een plotselinge daling van de prestaties of het ontbreken van een verbinding. Overweeg de belangrijkste hulpmiddelen voor aanpassing en analyse. Laten we eens kijken waar de logboeken en andere nuttige informatie zich bevinden. Ik zal zelfs proberen om in één artikel alle benodigde informatie te verzamelen voor een snelle start.
Allereerst
We beginnen met de meest voorkomende vragen en bekijken ze afzonderlijk.
Als uw database plotseling, zonder duidelijke reden, langzaam begon te werken, maar u niets had veranderd, werk dan eerst de statistieken bij en herbouw de indexen.
Op internet zijn er veel van dit soort methoden, voorbeelden van scripts worden gegeven. Ik ga ervan uit dat al die methoden voor professionals zijn. Nou, ik zal de eenvoudigste manier beschrijven:je hebt alleen een muis nodig om het te implementeren.
Afkortingen
- SSMS is een toepassing van Microsoft SQL Server Management Studio. Vanaf de 2016-versie is het gratis beschikbaar op de MS-website als een op zichzelf staande applicatie. docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
- Profiler is een toepassing van "SQL Server Profiler" die is geïnstalleerd met SSMS.
- Prestatiemonitor is een module van het bedieningspaneel waarmee u de prestatiemeters kunt bewaken, loggen en de geschiedenis van metingen kunt bekijken.
Statistieken bijwerken met behulp van een "serviceplan":
- voer SSMS uit;
- verbind met een vereiste server;
- breid de structuur uit in Object Inspector:Beheer\Onderhoudsplannen (Serviceplannen);
- klik met de rechtermuisknop op het knooppunt en selecteer "Wizard Onderhoudsplan";
- markeer in de wizard de vereiste taken:index opnieuw opbouwen en statistieken bijwerken
- u kunt beide taken tegelijk markeren of twee onderhoudsplannen maken met elk één taak (zie de "belangrijke opmerkingen" hieronder);
- verder controleren we een vereiste DB (of meerdere databases). We doen dit voor elke taak (als er twee taken worden gekozen, zullen er twee dialoogvensters zijn met de keuze voor een database);
- Volgende, Volgende, Voltooien.
Na deze acties wordt er een “onderhoudsplan” gemaakt (niet uitgevoerd). U kunt het handmatig uitvoeren door er met de rechtermuisknop op te klikken en "Uitvoeren" te selecteren. Als alternatief configureert u de lancering via SQL Agent.
Belangrijke opmerkingen:
- Het bijwerken van statistieken is een niet-blokkerende bewerking. Je kunt het in een werkende modus uitvoeren.
- Het opnieuw opbouwen van de index is een blokkerende bewerking. Je kunt het alleen buiten de werkuren draaien. Er is een uitzondering:met de Enterprise-editie van de server kan een "online rebuild" worden uitgevoerd. Deze optie kan worden ingeschakeld in de taakinstellingen. Let op:er is een vinkje in alle edities, maar het werkt alleen in Enterprise.
- Natuurlijk moeten deze taken regelmatig worden uitgevoerd. Ik stel een eenvoudige manier voor om te bepalen hoe vaak je dit doet:
– Voer bij de eerste problemen het onderhoudsplan uit;
– Als het geholpen heeft, wacht dan tot de problemen zich weer voordoen (meestal tot de volgende maandafsluiting/salarisberekening/ etc. van bulktransacties);
– De resulterende periode van een normale operatie zal uw referentiepunt zijn;
– Configureer bijvoorbeeld twee keer zo vaak de uitvoering van het onderhoudsplan.
De server is traag - wat moet u doen?
De bronnen die door de server worden gebruikt
Net als elk ander programma heeft de server processortijd, gegevens op de schijf, de hoeveelheid RAM en netwerkbandbreedte nodig.
Taakbeheer zal u helpen het gebrek aan een bepaalde bron in de eerste benadering te beoordelen, hoe erg het ook mag klinken.
CPU Laden
Zelfs een schooljongen kan het gebruik in de Manager controleren. We moeten er alleen voor zorgen dat als de processor is geladen, dit het sqlserver.exe-proces is.
Als dit uw geval is, moet u naar de analyse van gebruikersactiviteit gaan om te begrijpen wat de belasting precies heeft veroorzaakt (zie hieronder).
Schijf Loa d
Veel mensen kijken alleen naar de CPU-belasting, maar vergeten dat het DBMS een gegevensarchief is. De datavolumes groeien, de processorprestaties nemen toe, terwijl de HDD-snelheid vrijwel hetzelfde is. Met SSD's is de situatie beter, maar het opslaan van terabytes daarop is duur.
Het blijkt dat ik vaak situaties tegenkom waarin het schijfsysteem de bottleneck wordt, in plaats van de CPU.
Voor schijven zijn de volgende statistieken belangrijk:
- gemiddelde wachtrijlengte (uitstaande I/O-bewerkingen, aantal);
- lees-schrijfsnelheid (in Mb/s).
De serverversie van Taakbeheer toont in de regel (afhankelijk van de systeemversie) beide. Als dat niet het geval is, voert u de module Prestatiemonitor (systeemmonitor) uit. Wij zijn geïnteresseerd in de volgende tellers:
- Fysieke (logische) schijf/Gemiddelde lees- (schrijf) tijd
- Fysieke (logische) schijf/gemiddelde schijfwachtrijlengte
- Fysieke (logische) schijf/schijfsnelheid
Voor meer details kunt u bijvoorbeeld de handleidingen van de fabrikant hier lezen:social.technet.microsoft.com/wiki/contents/articles/3214.monitoring-disk-usage.aspx.
In het kort:
- De wachtrij mag niet langer zijn dan 1. Korte bursts zijn toegestaan als ze snel verdwijnen. De bursts kunnen verschillen, afhankelijk van uw systeem. Voor een eenvoudige RAID-mirror van twee HDD's is de wachtrij van meer dan 10-20 een probleem. Voor een coole bibliotheek met supercaching zag ik uitbarstingen van maximaal 600-800 die onmiddellijk werden opgelost zonder vertragingen te veroorzaken.
- De normale wisselkoers hangt ook af van het type schijfsysteem. De gebruikelijke (desktop) HDD zendt met 50-100 MB/sec. Een goede schijfbibliotheek - met 500 MB/s en meer. Voor kleine willekeurige bewerkingen is de snelheid lager. Dit kan uw referentiepunt zijn.
- Deze parameters moeten als een geheel worden beschouwd. Als uw bibliotheek 50 MB/s verzendt en een wachtrij van 50 bewerkingen in de rij staat, is er duidelijk iets mis met de hardware. Als de wachtrij in de rij staat wanneer de transmissie bijna het maximum bereikt - hoogstwaarschijnlijk zijn de schijven niet de schuld - ze kunnen gewoon niet meer doen - moeten we een manier zoeken om de belasting te verminderen.
- De belasting moet afzonderlijk worden gecontroleerd op schijven (als er meerdere zijn) en vergeleken met de locatie van serverbestanden. De Taakmanager kan de meest actief gebruikte bestanden tonen. Dit kan worden gebruikt om ervoor te zorgen dat de belasting wordt veroorzaakt door DBMS.
Wat kan de schijfsysteemproblemen veroorzaken:
- problemen met hardware
- cache opgebrand, prestatie drastisch gedaald;
- het schijfsysteem wordt door iets anders gebruikt;
- RAM-tekort. Wisselen. Сpijn verslechterd, prestatie gedaald (zie het gedeelte over RAM hieronder).
- Gebruikersbelasting verhoogd. Het is noodzakelijk om het werk van gebruikers te evalueren (problematische zoekopdracht/nieuwe functionaliteit/toename van het aantal gebruikers/toename van de hoeveelheid gegevens/enz.).
- Database datafragmentatie (zie de index opnieuw opbouwen hierboven), systeembestanden fragmentatie.
- Het schijfsysteem heeft zijn maximale capaciteiten bereikt.
In het geval van de laatste optie:gooi de hardware niet in één keer weg. Soms kun je iets meer uit het systeem halen als je het probleem verstandig benadert. Controleer de locatie van de systeembestanden op naleving van de aanbevolen vereisten:
- Vermeng OS-bestanden niet met databasegegevensbestanden. Bewaar ze op verschillende fysieke media, zodat het systeem niet concurreert met DBMS voor I/O.
- De database bestaat uit twee bestandstypen:data (*.mdf, *.ndf) en logs (*.ldf).
Gegevensbestanden worden in de regel meestal gebruikt om te lezen. Logs dienen om te schrijven (waarbij het schrijven opeenvolgend is). Het wordt daarom aanbevolen om logboeken en gegevens op verschillende fysieke media op te slaan, zodat de logboekregistratie het lezen van gegevens niet onderbreekt (in de regel heeft de schrijfbewerking voorrang op het lezen). - MS SQL kan "tijdelijke tabellen" gebruiken voor het verwerken van query's. Ze worden opgeslagen in de tempdb-systeemdatabase. Als de bestanden van deze database zwaar worden belast, kunt u proberen deze op fysiek gescheiden media weer te geven.
Samenvattend het probleem met de bestandslocatie, gebruik het principe van "verdeel en heers". Evalueer welke bestanden worden geopend en probeer deze naar verschillende media te distribueren. Gebruik ook de functies van RAID-systemen. RAID-5-leesbewerkingen zijn bijvoorbeeld sneller dan schrijven, wat goed is voor gegevensbestanden.
Laten we eens kijken hoe we informatie over gebruikersprestaties kunnen ophalen:wie maakt wat en hoeveel resources worden verbruikt
Ik heb taken voor het controleren van gebruikersactiviteit in de volgende groepen verdeeld:
- Taken voor het analyseren van een bepaald verzoek.
- Taken voor het analyseren van de belasting van de applicatie in specifieke omstandigheden (bijvoorbeeld wanneer een gebruiker op een knop klikt in een applicatie van derden die compatibel is met de database).
- Taken voor het analyseren van de huidige situatie.
Laten we ze allemaal in detail bekijken.
Waarschuwing
De prestatieanalyse vereist een diep begrip van de structuur en de werkingsprincipes van de databaseserver en het besturingssysteem. Dat is de reden waarom het lezen van alleen deze artikelen je geen professional maakt.
De overwogen criteria en tellers in echte systemen zijn sterk van elkaar afhankelijk. Een hoge HDD-belasting wordt bijvoorbeeld vaak veroorzaakt door een gebrek aan RAM. Zelfs als u enkele metingen uitvoert, is dit niet voldoende om de problemen redelijk te beoordelen.
Het doel van de artikelen is om de essentie van eenvoudige voorbeelden te introduceren. Je moet mijn aanbevelingen niet als een gids beschouwen. Ik raad je aan ze te gebruiken als trainingstaken die de stroom van gedachten kunnen verklaren.
Ik hoop dat je leert hoe je je conclusies over de serverprestaties in cijfers kunt rationaliseren.
In plaats van te zeggen "server vertraagt", geeft u specifieke waarden van specifieke indicatoren op.
Analyseer een P articulaire R verzoek
Het eerste punt is vrij eenvoudig, laten we er kort bij stilstaan. We zullen enkele minder voor de hand liggende zaken bespreken.
Naast de resultaten van de zoekopdracht, maakt SSMS het mogelijk om aanvullende informatie over de uitvoering van de zoekopdracht op te halen:
- U kunt het queryplan verkrijgen door op de knoppen "Geschat uitvoeringsplan weergeven" en "Werkelijk uitvoeringsplan opnemen" te klikken. Het verschil tussen beide is dat het schattingsplan is gebouwd zonder het uitvoeren van een query. De informatie over het aantal verwerkte rijen zal dus worden geschat. In het eigenlijke plan zullen er zowel geschatte als werkelijke gegevens zijn. Sterke discrepanties van deze waarden geven aan dat de statistieken niet relevant zijn. De analyse van het plan is echter een onderwerp voor een ander artikel - tot nu toe gaan we er niet dieper op in.
- We kunnen metingen krijgen van processorkosten en schijfbewerkingen van de server. Om dit te doen, is het noodzakelijk om de SET-optie in te schakelen. U kunt het als volgt doen in het dialoogvenster 'Query-opties':
Of met de directe SET-commando's in de query:
SET STATISTICS IO ON
SET STATISTICS TIME ON
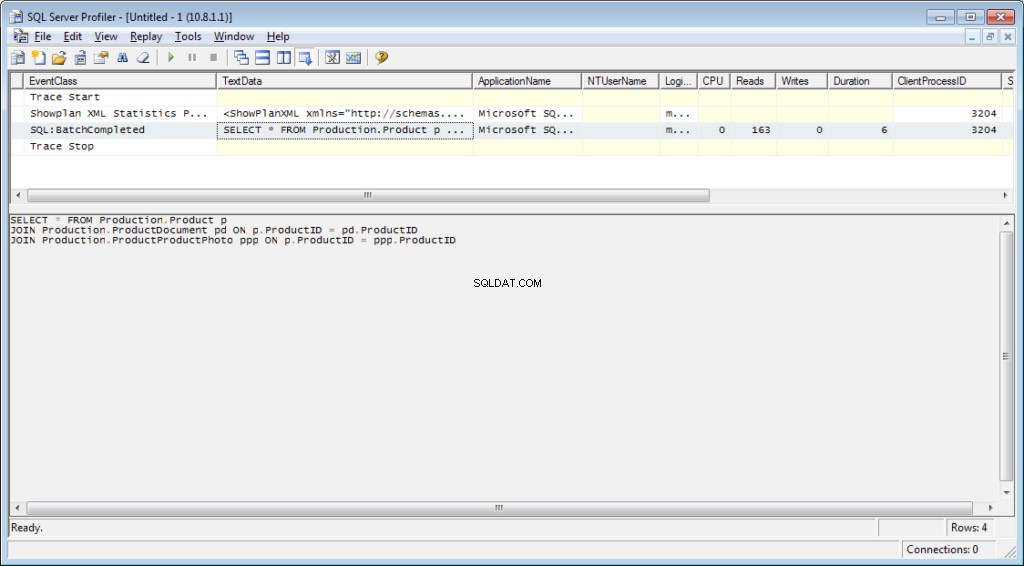
SELECT * FROM Production.Product p
JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID
JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductIDAls gevolg hiervan krijgen we gegevens over de tijd die is besteed aan compilatie en uitvoering, evenals het aantal schijfbewerkingen.
Time of SQL Server parsing and compilation:
CPU time = 16 ms, elapsed time = 89 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
(32 row(s) affected)
The «ProductProductPhoto» table. The number of views is 32, logic reads – 96, physical reads 5, read-ahead reads 0, lob of logical reads 0, lob of physical reads 0, lob of read-ahead reads 0.
The ‘Product’ table. The number of views is 0, logic reads – 64, physical reads – 0, read-ahead reads – 0, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
The «ProductDocument» table. The number of views is 1, logical reads – 3, physical reads – 1, read-ahead reads -, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
Time of SQL activity:
CPU time = 15 ms, spent time = 35 ms.Ik zou je aandacht willen vestigen op de compilatietijd, logische uitlezingen 96 en fysieke uitlezingen 5. Wanneer dezelfde query voor de tweede keer en later wordt uitgevoerd, kunnen fysieke uitlezingen afnemen en is hercompilatie wellicht niet nodig. Hierdoor komt het vaak voor dat de query de tweede en volgende keer sneller wordt uitgevoerd dan de eerste keer. De reden, zoals u begrijpt, ligt in het cachen van de gegevens en gecompileerde queryplannen.
- De knop «Inclusief klantstatistieken» toont de informatie over netwerkuitwisseling, het aantal uitgevoerde bewerkingen en de totale uitvoeringstijd, inclusief de kosten voor netwerkuitwisseling en verwerking door een klant. Het voorbeeld laat zien dat het meer tijd kost om de query voor de eerste keer uit te voeren:
- In SSMS 2016 is er de knop «Include Live Query Statistics». Het geeft de afbeelding weer zoals in het geval van het queryplan, maar bevat de niet-willekeurige cijfers van de verwerkte rijen, die op het scherm veranderen tijdens het uitvoeren van de query. Het beeld is heel duidelijk - knipperende pijlen en lopende nummers, je kunt meteen zien waar de tijd wordt verspild. De knop werkt ook voor SQL Server 2014 en later.
Samenvattend:
- Controleer de CPU-kosten met STATISTIEKEN INSTELLEN TIJD AAN.
- Schijfbewerkingen:STEL STATISTIEKEN IO IN. Vergeet niet dat logisch lezen een leesbewerking is die wordt voltooid in de schijfcache zonder fysieke toegang tot het schijfsysteem. "Fysiek lezen" kost veel meer tijd.
- Evalueer het volume van het netwerkverkeer met behulp van "Include Client Statistics".
- Analyseer het algoritme voor het uitvoeren van de query door het uitvoeringsplan met behulp van «Include Actual Execution Plan» en «Include Live Query Statistics».
Analyseer de applicatiebelasting
Hier zullen we SQL Server Profiler gebruiken. Na het starten en verbinden met de server, is het noodzakelijk om loggebeurtenissen te selecteren. Voer hiervoor profilering uit met een standaard traceersjabloon. Op de Algemeen tabblad in het Gebruik de sjabloon veld, selecteer Standaard (standaard) en klik op Uitvoeren .
De meer gecompliceerde manier is om filters of gebeurtenissen toe te voegen aan/uit de geselecteerde sjabloon te verwijderen. Deze opties zijn te vinden op het tweede tabblad van het dialoogvenstermenu. Selecteer Alle evenementen weergeven . om alle mogelijke evenementen en kolommen te zien die u kunt selecteren en Alle kolommen weergeven selectievakjes.

We hebben de volgende evenementen nodig:
- Opgeslagen procedures \ RPC:voltooid
- TSQL \ SQL:BatchCompleted
Deze gebeurtenissen bewaken alle externe SQL-aanroepen naar de server. Ze verschijnen nadat de queryverwerking is voltooid. Er zijn vergelijkbare gebeurtenissen die de start van SQL Server bijhouden:
- Opgeslagen Procedures \ RPC:Starten
- TSQL \ SQL:BatchBegint
We hebben deze procedures echter niet nodig omdat ze geen informatie bevatten over de serverbronnen die zijn besteed aan de uitvoering van de query. Het is duidelijk dat dergelijke informatie pas beschikbaar is na voltooiing van het uitvoeringsproces. Dus kolommen met gegevens over CPU, Lezen, Schrijven in de *Startgebeurtenissen zullen leeg zijn.
De volgende evenementen kunnen ons ook interesseren, maar we zullen ze tot nu toe niet inschakelen:
- Opgeslagen procedures \ SP:Starting (*Voltooid) controleert de interne aanroep naar de opgeslagen procedure niet van de client, maar binnen het huidige verzoek of een andere procedure.
- Opgeslagen procedures \ SP:StmtStarting (*Completed) volgt het begin van elke instructie binnen de opgeslagen procedure. Als de procedure een cyclus bevat, is het aantal gebeurtenissen voor de opdrachten in de cyclus gelijk aan het aantal herhalingen in de cyclus.
- TSQL \ SQL:StmtStarting (*Completed) controleert de start van elke instructie binnen de SQL-batch. Als er meerdere commando's in uw query zijn, zal elk van hen één gebeurtenis bevatten. Het werkt dus voor de commando's in de query.
Deze gebeurtenissen zijn handig voor het bewaken van het uitvoeringsproces.
Door C olumns
Welke kolommen u moet selecteren, blijkt uit de naam van de knop. We hebben de volgende nodig:
- TextData, BinaryData bevatten de zoektekst.
- CPU, Leest, Schrijft, Duur geeft gegevens over het verbruik van bronnen weer.
- StartTime, EndTime is de tijd om het uitvoeringsproces te starten en te beëindigen. Ze zijn handig om te sorteren.
Voeg andere kolommen toe op basis van uw voorkeuren.
De Kolomfilters… knop opent het dialoogvenster voor het configureren van gebeurtenisfilters. Als u geïnteresseerd bent in de activiteit van de specifieke gebruiker, kunt u het filter instellen op SID-nummer of gebruikersnaam. Helaas, in het geval van het verbinden van de app via de app-server met het trekken van verbindingen, wordt het monitoren van de specifieke gebruiker ingewikkelder.
U kunt filters gebruiken voor de selectie van alleen gecompliceerde query's (Duur>X), query's die intensief schrijven veroorzaken (Writes>Y), evenals selecties van query-inhoud, enz.
Wat hebben we nog meer nodig van de profiler? Natuurlijk het uitvoeringsplan!
Het is noodzakelijk om de gebeurtenis «Performance \ Showplan XML Statistics Profile» toe te voegen aan de tracering. Tijdens het uitvoeren van onze query krijgen we de volgende afbeelding:
De vraagtekst:
Het uitvoeringsplan:
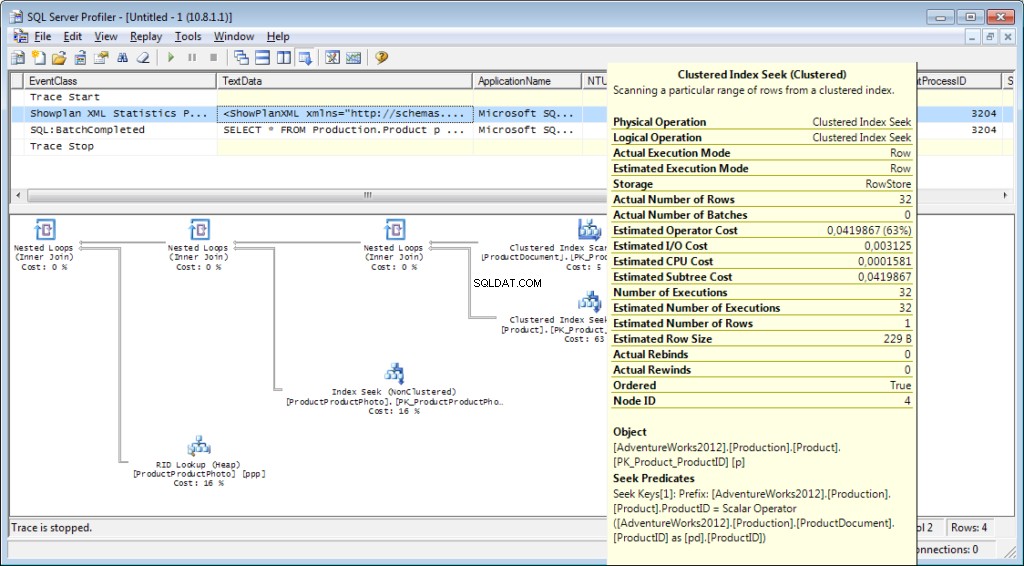
En dat is niet alles
Het is mogelijk om een tracering naar een bestand of een databasetabel op te slaan. Traceringsinstellingen kunnen worden opgeslagen als een persoonlijke sjabloon voor een snelle run. U kunt de tracering uitvoeren zonder profiler, door simpelweg een T-SQL-code te gebruiken en de procedures sp_trace_create, sp_trace_setevent, sp_trace_setstatus, sp_trace_getdata. Een voorbeeld vind je hier. Deze aanpak kan bijvoorbeeld handig zijn om automatisch een tracering naar een bestand volgens een schema op te slaan. U kunt een kijkje nemen in de profiler om te zien hoe u deze opdrachten kunt gebruiken. Je kunt twee sporen uitvoeren en in een ervan volgen wat er gebeurt als de tweede begint. Controleer of er geen filter is op de kolom "Applicatienaam" op de profiler zelf.
De lijst met gebeurtenissen die door de profiler worden gecontroleerd, is erg groot en beperkt zich niet tot het ontvangen van vraagteksten. Er zijn evenementen die volledige scan, hercompilatie, autogrow, deadlock en nog veel meer volgen.
Gebruikersactiviteit op de server analyseren
Er zijn verschillende situaties. Een vraag kan lang op ‘uitvoering’ blijven hangen en het is onduidelijk of deze wel of niet wordt ingevuld. Ik zou de problematische vraag afzonderlijk willen analyseren; we moeten echter eerst bepalen wat de query is. Het is nutteloos om het te vangen met een profiler - we hebben de startgebeurtenis al gemist en het is niet duidelijk hoe lang we moeten wachten tot het proces is voltooid.
Laten we het uitzoeken
Je hebt misschien wel eens gehoord van 'Activiteitsmonitor'. De hogere edities hebben echt rijke functionaliteit. Hoe kan het ons helpen? Activity Monitor bevat veel handige en interessante functies. We halen alles wat we nodig hebben uit systeemweergaven en -functies. Monitor zelf is handig omdat je de profiler erop kunt instellen en kunt zien welke zoekopdrachten het uitvoert.
We hebben nodig:
- dm_exec_sessions biedt informatie over sessies van verbonden gebruikers. In ons artikel zijn de nuttige velden de velden die een gebruiker identificeren (login_name, login_time, host_name, program_name, …) en velden met de informatie over gebruikte resources (cpu_time, reads, writes, memory_usage, …)
- dm_exec_requests biedt informatie over query's die momenteel worden uitgevoerd.
- session_id is een identificatie van de sessie die moet worden gekoppeld aan de vorige weergave.
- start_time is de tijd voor de weergaverun.
- opdracht is een veld dat een type van de uitgevoerde opdracht bevat. Voor gebruikersvragen is dit select/update/delete/
- sql_handle, statement_start_offset, statement_end_offset bieden informatie voor het ophalen van querytekst:handle, evenals de start- en eindpositie in de tekst van de query, wat het deel betekent dat momenteel wordt uitgevoerd (voor het geval dat uw query meerdere commando's).
- plan_handle is een handvat van het gegenereerde plan.
- blocking_session_id geeft het nummer van de sessie aan die de blokkering veroorzaakte als er blokkades zijn die de uitvoering van de query verhinderen
- wait_type, wait_time, wait_resource zijn velden met de informatie over de reden en duur van het wachten. Voor sommige soorten wachttijden, bijvoorbeeld gegevensvergrendeling, is het nodig om bovendien een code voor de geblokkeerde bron op te geven.
- percent_complete is het voltooiingspercentage. Helaas is het alleen beschikbaar voor opdrachten met een duidelijk voorspelbare voortgang (bijvoorbeeld back-up of herstel).
- cpu_time, reads, writes, logical_reads, grant_query_memory zijn resourcekosten.
- dm_exec_sql_text(sql_handle | plan_handle), sys.dm_exec_query_plan(plan_handle) zijn functies voor het verkrijgen van de tekst en het uitvoeringsplan. Hieronder zullen we een voorbeeld van het gebruik ervan bekijken.
- dm_exec_query_stats is een overzichtsstatistiek van het uitvoeren van query's. Het toont de zoekopdracht, het aantal uitvoeringen en het volume van de gebruikte middelen.
Belangrijke opmerkingen
Bovenstaande lijst is slechts een klein deel. Een volledige lijst van alle systeemaanzichten en functies wordt beschreven in de documentatie. Er is ook een prachtige afbeelding met een diagram van koppelingen tussen de hoofdobjecten.
De querytekst, het plan en de uitvoeringsstatistieken zijn gegevens die zijn opgeslagen in de procedurecache. Ze zijn beschikbaar tijdens de uitvoering. De beschikbaarheid is dan niet gegarandeerd en is afhankelijk van de cachebelasting. Ja, de cache kan handmatig worden opgeschoond. Soms is het aan te raden wanneer de uitvoeringsplannen ‘uit elkaar vallen’. Toch zijn er veel nuances.
Het veld "commando" is zinloos voor gebruikersverzoeken, omdat we de volledige tekst kunnen krijgen. Het is echter erg belangrijk voor het verkrijgen van informatie over systeemprocessen. In de regel voeren ze enkele interne taken uit en beschikken ze niet over de SQL-tekst. Voor dergelijke processen is de informatie over de opdracht de enige aanwijzing voor het type activiteit.
In de reacties op het vorige artikel stond een vraag over waar de server bij betrokken is wanneer deze niet zou moeten werken. Het antwoord zal waarschijnlijk in de betekenis van dit veld liggen. In mijn praktijk bood het veld "commando" altijd iets heel begrijpelijks voor actieve systeemprocessen:autoshrink / autogrow / checkpoint / logwriter / etc.
Hoe het te gebruiken
We gaan naar het praktische gedeelte. Ik zal verschillende voorbeelden geven van het gebruik ervan. De servermogelijkheden zijn niet beperkt - u kunt uw eigen voorbeelden bedenken.
Voorbeeld 1. Welk proces verbruikt CPU/lezen/schrijven/geheugen
Bekijk eerst de sessies die meer bronnen verbruiken, bijvoorbeeld CPU. U kunt deze informatie vinden in sys.dm_exec_sessions. Gegevens over de CPU, inclusief lees- en schrijfbewerkingen, zijn echter cumulatief. Het betekent dat het nummer het totaal voor de hele tijd van verbinding bevat. Het is duidelijk dat de gebruiker die een maand geleden verbinding heeft gemaakt en niet werd verbroken, een hogere waarde zal hebben. Het betekent niet dat ze het systeem overbelasten.
Een code met het volgende algoritme kan dit probleem oplossen:
- Maak een selectie en sla deze op in een tijdelijke tabel
- Wacht even
- Maak voor de tweede keer een keuze
- Vergelijk deze resultaten. Hun verschil geeft de kosten aan die bij stap 2 zijn uitgegeven.
- Gemakshalve kan het verschil worden gedeeld door de duur van stap 2 om de gemiddelde "kosten per seconde" te verkrijgen.
if object_id('tempdb..#tmp') is NULL
BEGIN
SELECT * into #tmp from sys.dm_exec_sessions s
PRINT 'wait for a second to collect statistics at the first run '
-- we do not wait for the next launches, because we compare with the result of the previous launch
WAITFOR DELAY '00:00:01';
END
if object_id('tempdb..#tmp1') is not null drop table #tmp1
declare @d datetime
declare @dd float
select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp')
select * into #tmp1 from sys.dm_exec_sessions s
select @dd=datediff(ms,@d,getdate())
select @dd AS [time interval, ms]
SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec,
s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec,
s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D],
s.nt_user_name,s.nt_domain
from #tmp1 s
LEFT join #tmp t on s.session_id=t.session_id
order BY
cpu_Diff desc
--totIO_Diff desc
--logical_reads_Diff desc
drop table #tmp
GO
select * into #tmp from #tmp1
drop table #tmp1 Ik gebruik twee tabellen in de code:#tmp – voor de eerste selectie, en #tmp1 – voor de tweede. Tijdens de eerste run maakt en vult het script #tmp en #tmp1 met een interval van één seconde, en voert vervolgens andere taken uit. Bij de volgende uitvoeringen gebruikt het script de resultaten van de vorige uitvoering als basis voor vergelijking. De duur van stap 2 zal dus gelijk zijn aan de duur van uw wachttijd tussen de scriptuitvoeringen.
Probeer het uit te voeren, zelfs op de productieserver. Het script maakt alleen 'tijdelijke tabellen' (beschikbaar binnen de huidige sessie en verwijderd wanneer uitgeschakeld) en heeft geen thread.
Degenen die er niet van houden om een zoekopdracht in MS SSMS uit te voeren, kunnen deze in een applicatie plaatsen die is geschreven in hun favoriete programmeertaal. Ik zal je laten zien hoe je dit in MS Excel kunt doen zonder een enkele regel code.
Maak in het menu Gegevens verbinding met de server. Als u wordt gevraagd een tafel te selecteren, selecteert u een willekeurige. Klik op Volgende en Voltooien totdat u het dialoogvenster Gegevens importeren ziet. In dat venster moet u op Eigenschappen klikken. In Eigenschappen is het noodzakelijk om een opdrachttype te vervangen door de SQL-waarde en onze aangepaste query in het tekstveld Opdracht in te voegen.
Je zult de zoekopdracht een beetje moeten aanpassen:
- Voeg «STEL NOCOUNT IN» toe
- Vervang tijdelijke tabellen door variabele tabellen
- Vertraging duurt binnen 1 sec. Velden met gemiddelde waarden zijn niet verplicht
De aangepaste Query voor Excel
SET NOCOUNT ON;
declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint)
declare @d datetime;
select @d=GETDATE()
INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id)
SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id
from sys.dm_exec_sessions s;
WAITFOR DELAY '00:00:01';
declare @dd float;
select @dd=datediff(ms,@d,getdate());
SELECT
s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff,
s.reads-isnull(t.reads,0) as reads_Diff,
s.writes-isnull(t.writes,0) as writes_Diff,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff],
s.nt_user_name,s.nt_domain
from sys.dm_exec_sessions s
left join @tmp t on s.session_id=t.session_id Resultaat:
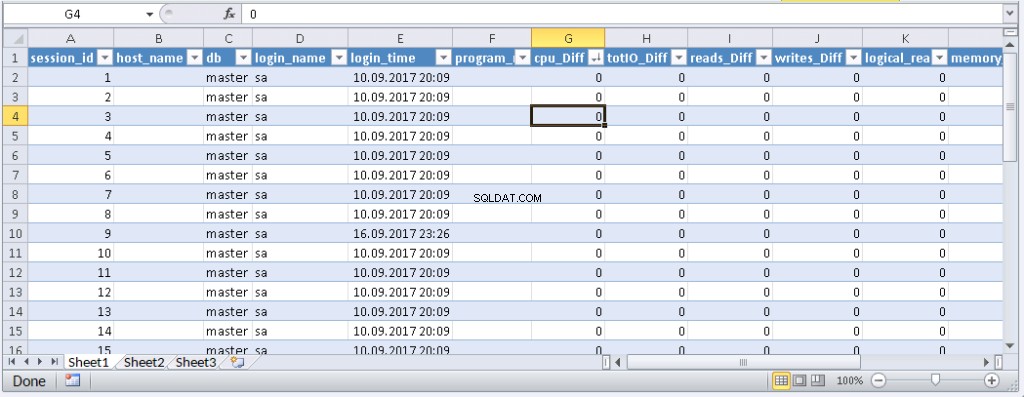
Wanneer gegevens in Excel verschijnen, kunt u deze naar behoefte sorteren. Om de informatie bij te werken, klikt u op 'Vernieuwen'. In de werkmapinstellingen kunt u "auto-update" in een bepaalde periode en "update aan het begin" plaatsen. U kunt het bestand opslaan en doorgeven aan uw collega's. Daarom hebben we een handige en eenvoudige tool gemaakt.
Voorbeeld 2. Waar besteedt een sessie middelen aan?
Nu gaan we bepalen wat de probleemsessies daadwerkelijk doen. Gebruik hiervoor sys.dm_exec_requests and functions om querytekst en queryplan te ontvangen.
Het query- en uitvoeringsplan op het sessienummer
DECLARE @sql_handle varbinary(64) DECLARE @plan_handle varbinary(64) DECLARE @sid INT Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT -- for the information by a particular user – indicate a session number SELECT @sid=182 -- receive state variables for further processing IF @sid IS NOT NULL SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id FROM sys.dm_exec_requests der WHERE example@sqldat.com -- print the text of the query being executed DECLARE @txt VARCHAR(max) IF @sql_handle IS NOT NULL SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle) PRINT @txt -- output the plan of the batch/procedure being executed IF @plan_handle IS NOT NULL select * from sys.dm_exec_query_plan(@plan_handle) -- and the plan of the query being executed within the batch/procedure IF @plan_handle IS NOT NULL SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)
Voeg het sessienummer in de query in en voer deze uit. After execution, there will be plans on the Results tab (the first one is for the whole query, and the second one is for the current step if there are several steps in the query) and the query text on the Messages tab. To view the plan, you need to click the text that looks like the URL in the row. The plan will be opened in a separate tab. Sometimes, it happens that the plan is opened not in a graphical form, but in the form of XML-text. This may happen because the MS SSMS version is lower than the server. Delete the “Version” and “Build” from the first row and then save the result XML to a file with the .sqlplan extension. After that, open it separately. If this does not help, I remind you that the 2016 studio is officially available for free on the MS website.
It is obvious that the result plan will be an estimated one, as the query is being executed. Still, it is possible to receive some execution statistics. To do this, use the sys.dm_exec_query_stats view with the filter by our handles.
Add this information at the end of the previous query
-- plan statistics IF @sql_handle IS NOT NULL SELECT * FROM sys.dm_exec_query_stats QS WHERE example@sqldat.com_handle
As a result, we will get the information about the steps of the executed query:how many times they were executed and what resources were spent. This information is added to the statistics only after the execution process is completed. The statistics are not tied to the user but are maintained within the whole server. If different users execute the same query, the statistics will be total for all users.
Example 3. Can I see all of them?
Let’s combine the system views we considered with the functions in one query. It can be useful for evaluating the whole situation.
-- receive a list of all current queries SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt --,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat ,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, * from sys.dm_exec_requests der left join sys.dm_exec_sessions s ON s.session_id = der.session_id WHERE der.session_id<>@@SPID -- AND der.session_id>50
The query outputs a list of active sessions and texts of their queries. For system processes, usually, there is no query; however, the command field is filled up. You can see the information about blocks and waits, and mix this query with example 1 in order to sort by the load. Still, be careful, query texts may be large. Their massive selection can be resource-intensive and lead to a huge traffic increase. In the example, I limited the result query to the first 500 characters but did not execute the plan.
Conclusie
It would be great to get Live Query Statistics for an arbitrary session. According to the manufacturer, now, monitoring statistics requires many resources and therefore, it is disabled by default. Its enabling is not a problem, but additional manipulations complicate the process and reduce the practical benefit.
In this article, we analyzed user activity in the following ways:using possibilities MS SSMS, profiler, direct calls to system views. All these methods allow estimating costs on executing a query and getting the execution plan. Each method is suitable for a particular situation. Thus, the best solution is to combine them.