In 2012 schreef ik hier een blogpost over benaderingen voor het berekenen van een mediaan. In die post heb ik het heel eenvoudige geval behandeld:we wilden de mediaan van een kolom over een hele tabel vinden. Sindsdien is mij meerdere keren genoemd dat een meer praktische vereiste is om een gepartitioneerde mediaan te berekenen . Net als bij het basisgeval zijn er meerdere manieren om dit op te lossen in verschillende versies van SQL Server; het is niet verrassend dat sommige veel beter presteren dan andere.
In het vorige voorbeeld hadden we alleen generieke kolommen id en val. Laten we dit realistischer maken en zeggen dat we verkopers hebben en het aantal verkopen dat ze in een bepaalde periode hebben gedaan. Om onze zoekopdrachten te testen, maken we eerst een eenvoudige heap met 17 rijen en controleren we of ze allemaal de resultaten opleveren die we verwachten (SalesPerson 1 heeft een mediaan van 7,5 en SalesPerson 2 heeft een mediaan van 6,0):
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) VALUES (1, 6 ),(1, 11),(1, 4 ),(1, 4 ), (1, 15),(1, 14),(1, 4 ),(1, 9 ), (2, 6 ),(2, 11),(2, 4 ),(2, 4 ), (2, 15),(2, 14),(2, 4 );
Dit zijn de query's die we gaan testen (met veel meer gegevens!) tegen de bovenstaande hoop, evenals met ondersteunende indexen. Ik heb een aantal query's van de vorige test weggegooid, die ofwel helemaal niet of niet goed werden geschaald naar gepartitioneerde medianen (namelijk 2000_B, die een #temp-tabel gebruikte, en 2005_A, die een tegenoverliggende rij gebruikte nummers). Ik heb echter een paar interessante ideeën toegevoegd uit een recent artikel van Dwain Camps (@DwainCSQL), dat voortbouwde op mijn vorige bericht.
SQL Server 2000+
De enige methode van de vorige aanpak die goed genoeg werkte op SQL Server 2000 om deze zelfs in deze test op te nemen, was de "min van de ene helft, max van de andere"-benadering:
SELECT DISTINCT s.SalesPerson, Median = (
(SELECT MAX(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount) AS t)
+ (SELECT MIN(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount DESC) AS b)
) / 2.0
FROM dbo.Sales AS s; Ik heb eerlijk gezegd geprobeerd de #temp-tabelversie na te bootsen die ik in het eenvoudigere voorbeeld gebruikte, maar het schaalde helemaal niet goed. Bij 20 of 200 rijen werkte het prima; bij 2000 duurde het bijna een minuut; bij 1.000.000 gaf ik het na een uur op. Ik heb het hier opgenomen voor het nageslacht (klik om te onthullen).
CREATE TABLE #x
(
i INT IDENTITY(1,1),
SalesPerson INT,
Amount INT,
i2 INT
);
CREATE CLUSTERED INDEX v ON #x(SalesPerson, Amount);
INSERT #x(SalesPerson, Amount)
SELECT SalesPerson, Amount
FROM dbo.Sales
ORDER BY SalesPerson,Amount OPTION (MAXDOP 1);
UPDATE x SET i2 = i-
(
SELECT COUNT(*) FROM #x WHERE i <= x.i
AND SalesPerson < x.SalesPerson
)
FROM #x AS x;
SELECT SalesPerson, Median = AVG(0. + Amount)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE SalesPerson = x.SalesPerson
AND x.i2 - (SELECT MAX(i2) / 2.0 FROM #x WHERE SalesPerson = x.SalesPerson)
IN (0, 0.5, 1)
)
GROUP BY SalesPerson;
GO
DROP TABLE #x; SQL Server 2005+ 1
Dit gebruikt twee verschillende vensterfuncties om een volgorde en totaaltelling van bedragen per verkoper af te leiden.
SELECT SalesPerson, Median = AVG(1.0*Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount),
c = COUNT(*) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL Server 2005+ 2
Dit kwam uit het artikel van Dwain Camps, dat hetzelfde doet als hierboven, op een iets uitgebreidere manier. Dit maakt in feite de draaiing van de interessante rij(en) in elke groep ongedaan.
;WITH Counts AS
(
SELECT SalesPerson, c
FROM
(
SELECT SalesPerson, c1 = (c+1)/2,
c2 = CASE c%2 WHEN 0 THEN 1+c/2 ELSE 0 END
FROM
(
SELECT SalesPerson, c=COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
) a
) a
CROSS APPLY (VALUES(c1),(c2)) b(c)
)
SELECT a.SalesPerson, Median=AVG(0.+b.Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount)
FROM dbo.Sales a
) a
CROSS APPLY
(
SELECT Amount FROM Counts b
WHERE a.SalesPerson = b.SalesPerson AND a.rn = b.c
) b
GROUP BY a.SalesPerson; SQL Server 2005+ 3
Dit was gebaseerd op een suggestie van Adam Machanic in de reacties op mijn vorige post, en ook verbeterd door Dwain in zijn artikel hierboven.
;WITH Counts AS
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
)
SELECT a.SalesPerson, Median = AVG(0.+Amount)
FROM Counts a
CROSS APPLY
(
SELECT TOP (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
b.Amount, r = ROW_NUMBER() OVER (ORDER BY b.Amount)
FROM dbo.Sales b
WHERE a.SalesPerson = b.SalesPerson
ORDER BY b.Amount
) p
WHERE r BETWEEN ((a.c - 1) / 2) + 1 AND (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
GROUP BY a.SalesPerson; SQL Server 2005+ 4
Dit is vergelijkbaar met "2005+1" hierboven, maar in plaats van COUNT(*) OVER() te gebruiken om de tellingen af te leiden, voert het een self-join uit tegen een geïsoleerd aggregaat in een afgeleide tabel.
SELECT SalesPerson, Median = AVG(1.0 * Amount)
FROM
(
SELECT s.SalesPerson, s.Amount, rn = ROW_NUMBER() OVER
(PARTITION BY s.SalesPerson ORDER BY s.Amount), c.c
FROM dbo.Sales AS s
INNER JOIN
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales GROUP BY SalesPerson
) AS c
ON s.SalesPerson = c.SalesPerson
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL Server 2012+ 1
Dit was een zeer interessante bijdrage van collega SQL Server MVP Peter "Peso" Larsson (@SwePeso) in de commentaren op het artikel van Dwain; het gebruikt CROSS APPLY en de nieuwe OFFSET / FETCH functionaliteit op een nog interessantere en verrassendere manier dan de oplossing van Itzik voor de eenvoudigere mediaanberekening.
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median); SQL Server 2012+ 2
Eindelijk hebben we de nieuwe PERCENTILE_CONT() functie geïntroduceerd in SQL Server 2012.
SELECT SalesPerson, Median = MAX(Median)
FROM
(
SELECT SalesPerson,Median = PERCENTILE_CONT(0.5) WITHIN GROUP
(ORDER BY Amount) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
GROUP BY SalesPerson; De echte testen
Om de prestaties van de bovenstaande query's te testen, gaan we een veel substantiëlere tabel bouwen. We zullen 100 unieke verkopers hebben, met elk 10.000 verkoopbedragen, voor een totaal van 1.000.000 rijen. We gaan ook elke query uitvoeren tegen de heap zoals deze is, met een toegevoegde niet-geclusterde index op (SalesPerson, Amount) , en met een geclusterde index op dezelfde kolommen. Hier is de opstelling:
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO --CREATE CLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --CREATE NONCLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --DROP INDEX x ON dbo.sales; ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3;
En hier zijn de resultaten van de bovenstaande zoekopdrachten, tegen de heap, de niet-geclusterde index en de geclusterde index:
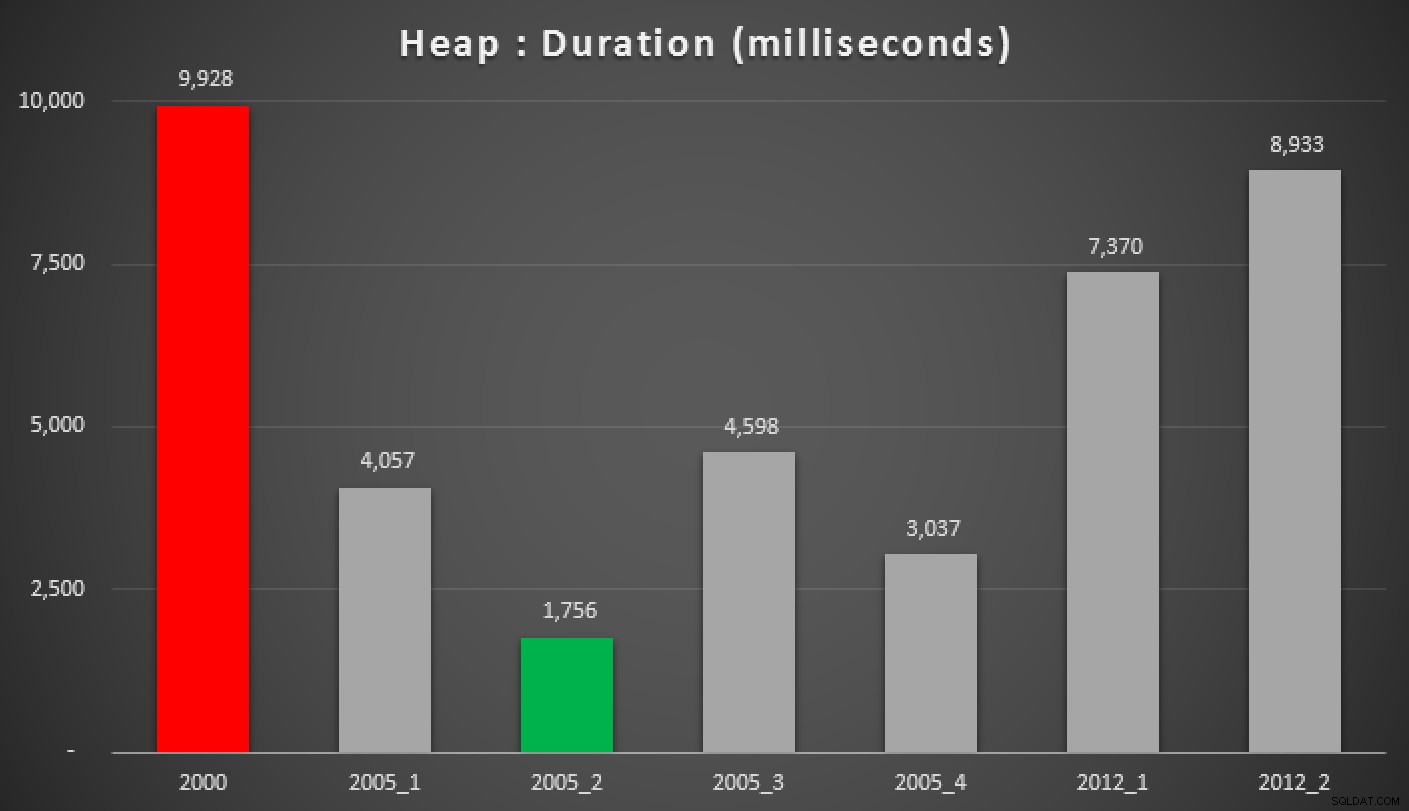
Duur, in milliseconden, van verschillende gegroepeerde mediaanbenaderingen (tegen een hoop)
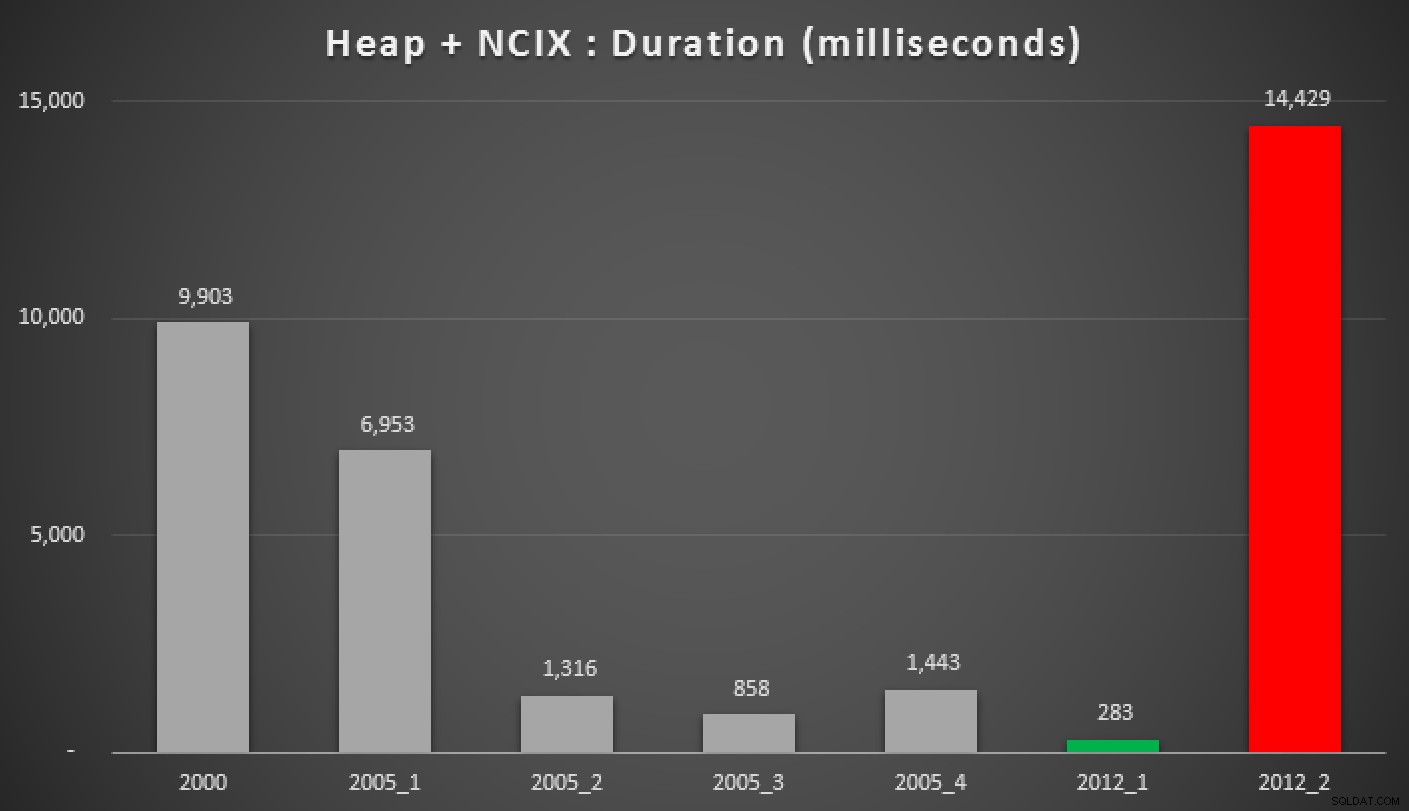
Duur, in milliseconden, van verschillende gegroepeerde mediaanbenaderingen (tegen een heap met een niet-geclusterde index)
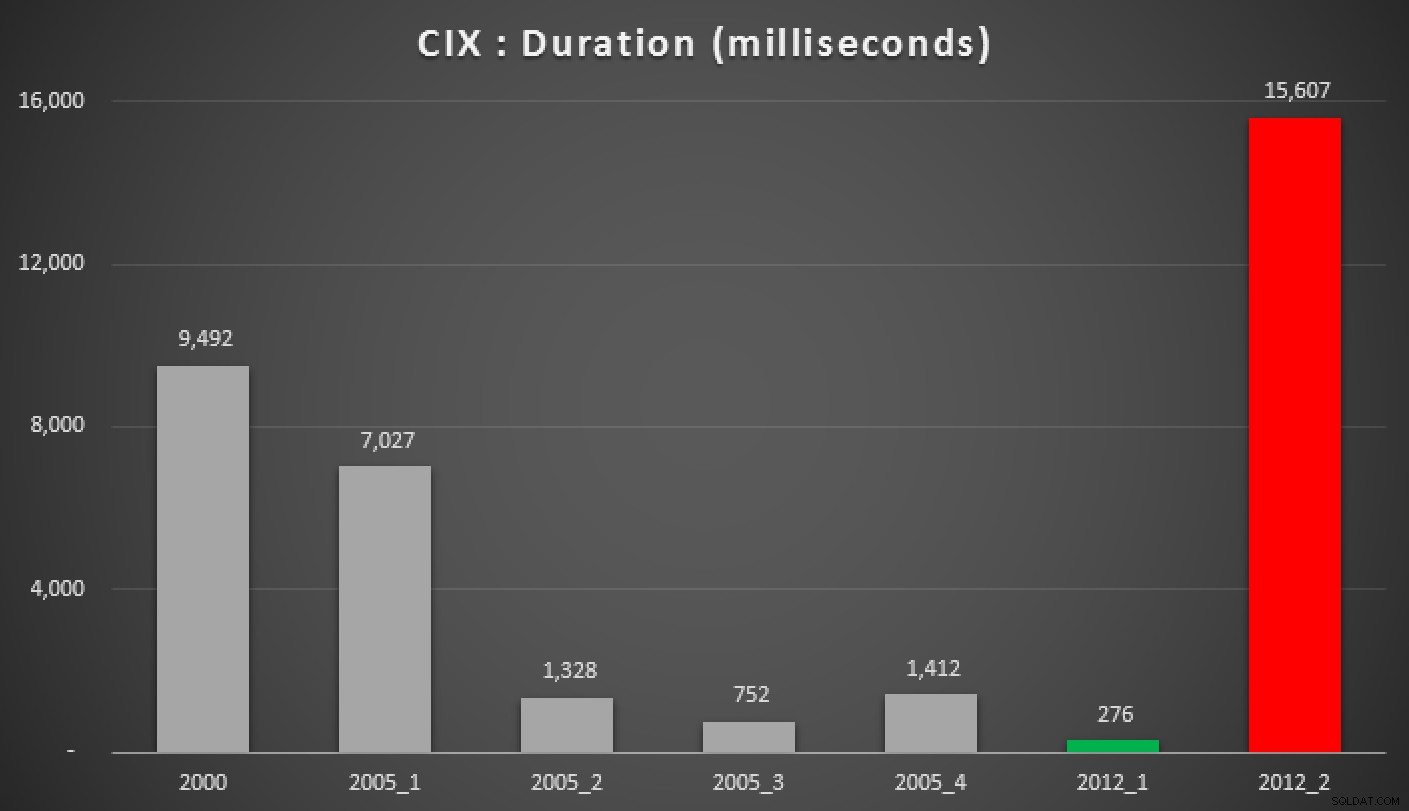
Duur, in milliseconden, van verschillende gegroepeerde mediaanbenaderingen (tegen een geclusterde index)
Hoe zit het met Hekaton?
Natuurlijk was ik benieuwd of deze nieuwe functie in SQL Server 2014 zou kunnen helpen bij een van deze vragen. Dus heb ik een In-Memory-database gemaakt, twee In-Memory-versies van de Sales-tabel (een met een hash-index op (SalesPerson, Amount) , en de andere op slechts (SalesPerson) ), en voerde dezelfde tests opnieuw uit:
CREATE DATABASE Hekaton; GO ALTER DATABASE Hekaton ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE Hekaton ADD FILE (name = 'xtp', filename = 'c:\temp\hek.mod') TO FILEGROUP xtp; GO ALTER DATABASE Hekaton SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT ON; GO USE Hekaton; GO CREATE TABLE dbo.Sales1 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson, Amount) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO CREATE TABLE dbo.Sales2 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales1 (SalesPerson, Amount) -- TABLOCK/TABLOCKX not allowed here SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3; INSERT dbo.Sales2 (SalesPerson, Amount) SELECT SalesPerson, Amount FROM dbo.Sales1;
De resultaten:
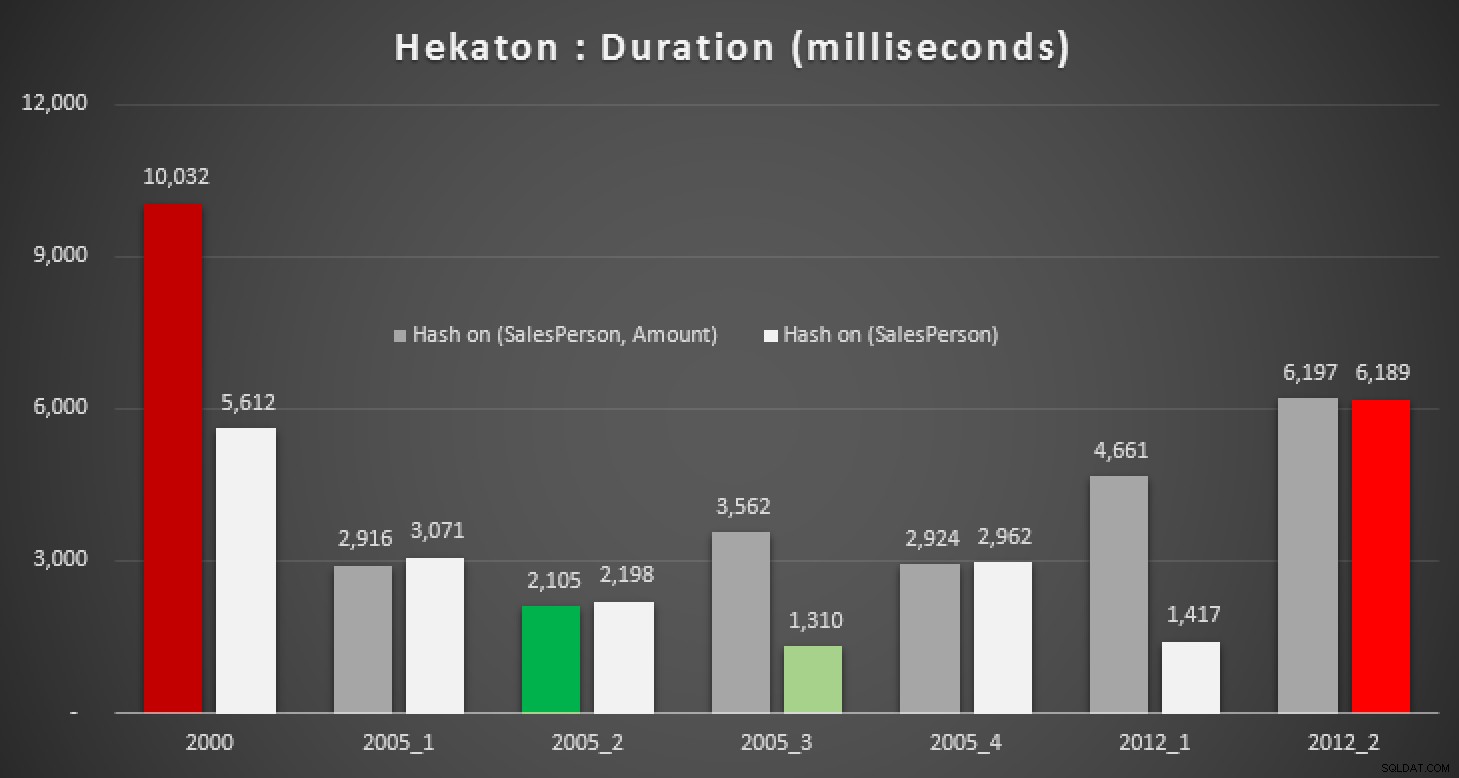
Duur, in milliseconden, voor verschillende mediaanberekeningen tegen In-Memory tafels
Zelfs met de juiste hash-index zien we niet echt significante verbeteringen ten opzichte van een traditionele tabel. Verder zal het proberen om het mediane probleem op te lossen met behulp van een native gecompileerde opgeslagen procedure geen gemakkelijke taak zijn, omdat veel van de hierboven gebruikte taalconstructies niet geldig zijn (ik was ook verbaasd over een paar hiervan). Het proberen om alle bovenstaande queryvariaties te compileren leverde deze parade van fouten op; sommige kwamen meerdere keren voor binnen elke procedure, en zelfs na het verwijderen van duplicaten is dit nog steeds een beetje komisch:
Msg 10794, Level 16, State 47, Procedure GroupedMedian_2000De optie 'DISTINCT' wordt niet ondersteund bij native gecompileerde opgeslagen procedures.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2000
Subquery's ( query's die in een andere query zijn genest) worden niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 10794, Level 16, State 48, Procedure GroupedMedian_2000
De optie 'PERCENT' wordt niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_1
Subquery's (query's genest in een andere query) worden niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 10794, Level 16, State 91 , Procedure GroupedMedian_2005_1
De aggregatiefunctie 'ROW_NUMBER' wordt niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 10794, Level 16, State 56, Procedure GroupedMedian_2005_1
De operator 'IN' wordt niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 12310, Level 16, State 36, Procedure GroupedMedian_2005_2
Common Table Expressions (CTE) worden niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 12309, Level 16, State 35, Procedure GroupedMedian_2005_2
Statements van het formulier INSERT…VALUES… die meerdere rijen invoegen worden niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 10794, Level 16, State 53, Procedure GroupedMedian_2005_2
De operator 'APPLY' wordt niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_2
Subquery's (query's genest in een andere query) worden niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 10794, Level 16, State 91, Procedure GroupedMedian_2005_2
De verzamelfunctie 'ROW_NUMBER' wordt niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 12310, Level 16, State 36, Procedure GroupedMedian_2005_3
Common Table Expressions (CTE) zijn niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_3
Subquery's (query's genest in een andere query) worden niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 10794, Level 16, State 91 , Procedure GroupedMedian_2005_3
De aggregatiefunctie 'ROW_NUMBER' wordt niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 10794, Level 16, State 53, Procedure GroupedMedian_2005_3
De operator 'APPLY' wordt niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_4
Subquery's (query's genest in een andere query) worden niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 10794, Level 16, State 91, Procedure GroupedMedian_2005_4
De aggregatiefunctie 'ROW_NUMBER' wordt niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 10794, Level 16, State 56, Procedure GroupedMedian_2005_4
De operator 'IN' wordt niet ondersteund met native gecompileerde stor ed procedures.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2012_1
Subquery's (query's genest in een andere query) worden niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 10794, Level 16, State 38, Procedure GroupedMedian_2012_1
De operator 'OFFSET' wordt niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 10794, Level 16, State 53, Procedure GroupedMedian_2012_1
De operator 'APPLY' wordt niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2012_2
Subquery's (query's genest in een andere query) worden niet ondersteund met native gecompileerde opgeslagen procedures.
Msg 10794, Level 16, State 90, Procedure GroupedMedian_2012_2
De aggregatiefunctie 'PERCENTILE_CONT' wordt niet ondersteund met native gecompileerde opgeslagen procedures.
Zoals momenteel geschreven, kon geen van deze query's worden geporteerd naar een native gecompileerde opgeslagen procedure. Misschien iets om naar te kijken voor een volgende vervolgpost.
Conclusie
De Hekaton-resultaten weggooien en wanneer een ondersteunende index aanwezig is, de zoekopdracht van Peter Larsson ("2012+1") met behulp van OFFSET/FETCH kwam uit als de verre winnaar in deze tests. Hoewel het iets complexer was dan de equivalente zoekopdracht in de niet-gepartitioneerde tests, kwam dit overeen met de resultaten die ik de vorige keer zag.
In diezelfde gevallen is de 2000 MIN/MAX aanpak en 2012's PERCENTILE_CONT() kwam uit als echte honden; nogmaals, net als mijn vorige tests tegen de eenvoudigere zaak.
Als u nog geen SQL Server 2012 gebruikt, is uw volgende beste optie "2005+ 3" (als u een ondersteunende index heeft) of "2005+ 2" als u met een hoop te maken heeft. Sorry dat ik hiervoor een nieuw naamgevingsschema moest bedenken, vooral om verwarring met de methoden in mijn vorige post te voorkomen.
Dit zijn natuurlijk mijn resultaten ten opzichte van een zeer specifiek schema en dataset - zoals bij alle aanbevelingen, moet u deze benaderingen testen aan de hand van uw schema en gegevens, aangezien andere factoren andere resultaten kunnen beïnvloeden.
Nog een opmerking
Behalve dat het slecht presteert en niet wordt ondersteund in native gecompileerde opgeslagen procedures, is er nog een ander pijnpunt van PERCENTILE_CONT() is dat het niet kan worden gebruikt in oudere compatibiliteitsmodi. Als je het probeert, krijg je deze foutmelding:
De functie PERCENTILE_CONT is niet toegestaan in de huidige compatibiliteitsmodus. Het is alleen toegestaan in de 110-modus of hoger.