Een van de vele nieuwe functies die in SQL Server 2008 werden geïntroduceerd, was gegevenscompressie. Compressie op rij- of paginaniveau biedt de mogelijkheid om schijfruimte te besparen, met als nadeel dat er wat meer CPU nodig is om de gegevens te comprimeren en te decomprimeren. Er wordt vaak beweerd dat de meeste systemen IO-gebonden zijn en niet CPU-gebonden, dus de afweging is de moeite waard. De vangst? U moest Enterprise Edition gebruiken om gegevenscompressie te gebruiken. Met de release van SQL Server 2016 SP1 is daar verandering in gekomen! Als u de Standard Edition van SQL Server 2016 SP1 en hoger gebruikt, kunt u nu gegevenscompressie gebruiken. Er is ook een nieuwe ingebouwde functie voor compressie, COMPRESS (en zijn tegenhanger DECOMPRESS). Gegevenscompressie werkt niet op off-row gegevens, dus als u een kolom zoals NVARCHAR(MAX) in uw tabel heeft met waarden die doorgaans groter zijn dan 8000 bytes, worden die gegevens niet gecomprimeerd (bedankt Adam Machanic voor die herinnering) . De COMPRESS-functie lost dit probleem op en comprimeert gegevens tot 2 GB. Bovendien, hoewel ik zou beweren dat de functie alleen zou moeten worden gebruikt voor grote, off-row gegevens, dacht ik dat het een waardevol experiment was om het rechtstreeks te vergelijken met rij- en paginacompressie.
INSTELLEN
Voor testgegevens werk ik vanuit een script dat Aaron Bertrand eerder heeft gebruikt, maar ik heb enkele aanpassingen gemaakt. Ik heb een aparte database gemaakt om te testen, maar je kunt tempdb of een andere voorbeelddatabase gebruiken, en toen begon ik met een tabel Klanten met drie NVARCHAR-kolommen. Ik heb overwogen grotere kolommen te maken en ze te vullen met reeksen herhalende letters, maar het gebruik van leesbare tekst geeft een voorbeeld dat realistischer is en dus meer nauwkeurigheid biedt.
Opmerking: Als u geïnteresseerd bent in het implementeren van compressie en u wilt weten hoe dit van invloed is op de opslag en prestaties in uw omgeving, raad ik u ten zeerste aan het te testen. Ik geef je de methodologie met voorbeeldgegevens; het implementeren van dit in uw omgeving zou geen extra werk met zich mee moeten brengen.
U zult hieronder zien dat we na het maken van de database Query Store inschakelen. Waarom een aparte tabel maken om onze prestatiestatistieken bij te houden als we gewoon functionaliteit kunnen gebruiken die is ingebouwd in SQL Server?!
USE [master]; GO CREATE DATABASE [CustomerDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' , SIZE = 4096MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' , SIZE = 2048MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB ); GO ALTER DATABASE [CustomerDB] SET COMPATIBILITY_LEVEL = 130; GO ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30), DATA_FLUSH_INTERVAL_SECONDS = 60, INTERVAL_LENGTH_MINUTES = 5, MAX_STORAGE_SIZE_MB = 256, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = AUTO, MAX_PLANS_PER_QUERY = 200 ); GO
Nu zullen we een aantal dingen in de database instellen:
USE [CustomerDB]; GO ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0; GO -- note: I removed the unique index on [Email] that was in Aaron's version CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Nu de tabel is gemaakt, voegen we wat gegevens toe, maar we voegen 5 miljoen rijen toe in plaats van 1 miljoen. Dit duurt ongeveer acht minuten om op mijn laptop te draaien.
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (5000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO Nu gaan we nog drie tabellen maken:één voor rijcompressie, één voor paginacompressie en één voor de COMPRESS-functie. Merk op dat u met de COMPRESS-functie de kolommen moet maken als VARBINARY-gegevenstypen. Als gevolg hiervan zijn er geen niet-geclusterde indexen in de tabel (omdat u geen indexsleutel op een varbinaire kolom kunt maken).
CREATE TABLE [dbo].[Customers_Page] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Page] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Page] ON [dbo].[Customers_Page]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Page] ON [dbo].[Customers_Page]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Row] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Row] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Row] ON [dbo].[Customers_Row]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Row] ON [dbo].[Customers_Row]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Compress] ( [CustomerID] [int] NOT NULL, [FirstName] [varbinary](max) NOT NULL, [LastName] [varbinary](max) NOT NULL, [EMail] [varbinary](max) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Compress] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO
Vervolgens kopiëren we de gegevens van [dbo].[Klanten] naar de andere drie tabellen. Dit is een rechtstreekse INSERT voor onze pagina- en rijtabellen en duurt ongeveer twee tot drie minuten voor elke INSERT, maar er is een schaalbaarheidsprobleem met de COMPRESS-functie:proberen om 5 miljoen rijen in één klap in te voegen is gewoon niet redelijk. Het onderstaande script voegt rijen in batches van 50.000 in en voegt slechts 1 miljoen rijen in in plaats van 5 miljoen. Ik weet het, dat betekent dat we hier geen echte appels-tot-appels zijn ter vergelijking, maar dat vind ik prima. Het invoegen van 1 miljoen rijen duurt 10 minuten op mijn machine; voel je vrij om het script aan te passen en 5 miljoen rijen in te voegen voor je eigen tests.
INSERT dbo.Customers_Page WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO INSERT dbo.Customers_Row WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO SET NOCOUNT ON DECLARE @StartID INT = 1 DECLARE @EndID INT = 50000 DECLARE @Increment INT = 50000 DECLARE @IDMax INT = 1000000 WHILE @StartID < @IDMax BEGIN INSERT dbo.Customers_Compress WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT top 100000 CustomerID, COMPRESS(FirstName), COMPRESS(LastName), COMPRESS(EMail), [Active] FROM dbo.Customers WHERE [CustomerID] BETWEEN @StartID AND @EndID; SET @StartID = @StartID + @Increment; SET @EndID = @EndID + @Increment; END
Met al onze tabellen gevuld, kunnen we de grootte controleren. Op dit moment hebben we ROW- of PAGE-compressie niet geïmplementeerd, maar de COMPRESS-functie is gebruikt:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [o].[name], [i].[index_id];
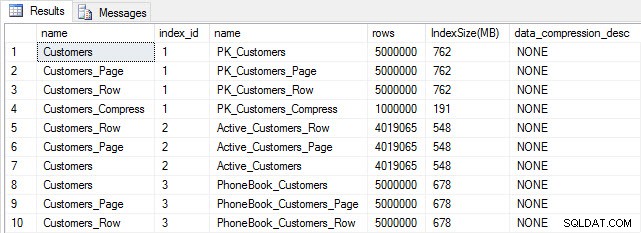 Tabel- en indexgrootte na invoegen
Tabel- en indexgrootte na invoegen
Zoals verwacht zijn alle tabellen behalve Customers_Compress ongeveer even groot. Nu gaan we indexen voor alle tabellen opnieuw opbouwen, waarbij we rij- en paginacompressie implementeren op respectievelijk Customers_Row en Customers_Page.
ALTER INDEX ALL ON dbo.Customers REBUILD; GO ALTER INDEX ALL ON dbo.Customers_Page REBUILD WITH (DATA_COMPRESSION = PAGE); GO ALTER INDEX ALL ON dbo.Customers_Row REBUILD WITH (DATA_COMPRESSION = ROW); GO ALTER INDEX ALL ON dbo.Customers_Compress REBUILD;
Als we de tabelgrootte na compressie controleren, kunnen we nu onze besparing op schijfruimte zien:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [i].[index_id], [IndexSize(MB)] DESC;
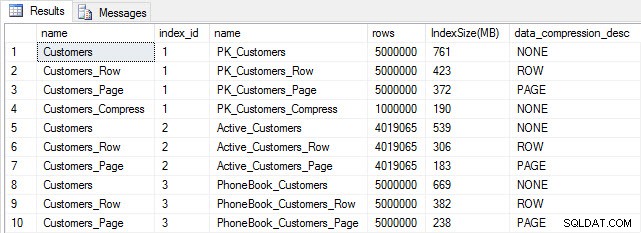
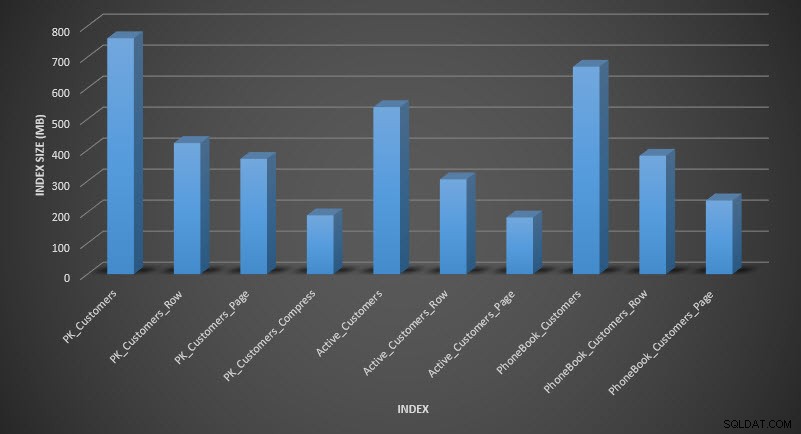 Indexgrootte na compressie
Indexgrootte na compressie
Zoals verwacht, verkleint de rij- en paginacompressie de grootte van de tabel en zijn indexen aanzienlijk. De COMPRESS-functie heeft ons de meeste ruimte bespaard - de geclusterde index is een kwart van de grootte van de oorspronkelijke tabel.
OPZOEKPRESTATIES ONDERZOEKEN
Houd er rekening mee dat we Query Store kunnen gebruiken om de prestaties van INSERT en REBUILD te bekijken voordat we de prestaties van query's testen:
SELECT [q].[query_id], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], AVG([rs].[avg_duration])/1000 [AvgDuration_ms], AVG([rs].[avg_cpu_time]) [AvgCPU], AVG([rs].[avg_logical_io_reads]) [AvgLogicalReads], AVG([rs].[avg_physical_io_reads]) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] LEFT OUTER JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [qt].[query_sql_text] LIKE '%INSERT%' OR [qt].[query_sql_text] LIKE '%ALTER%' GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [q].[query_id];
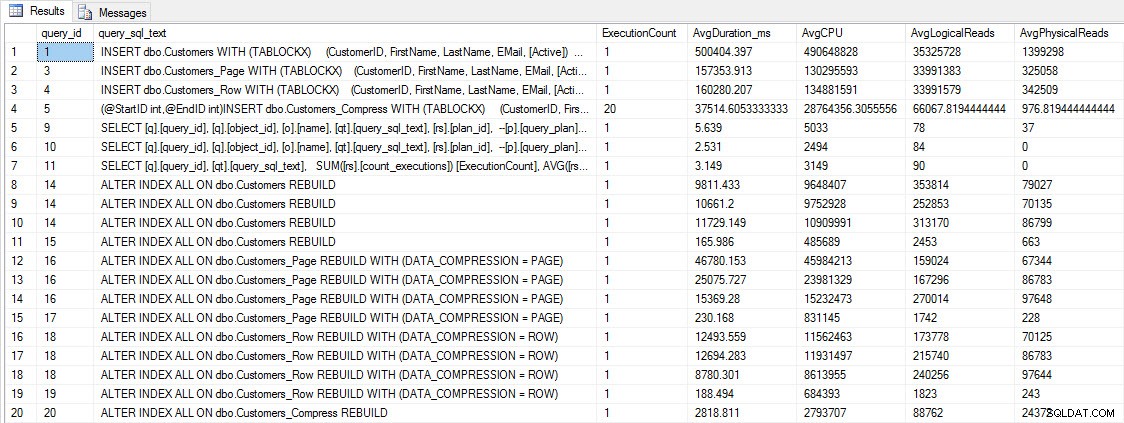 Prestatiestatistieken INSERT en REBUILD
Prestatiestatistieken INSERT en REBUILD
Hoewel deze gegevens interessant zijn, ben ik meer nieuwsgierig naar hoe compressie mijn dagelijkse SELECT-query's beïnvloedt. Ik heb een set van drie opgeslagen procedures die elk één SELECT-query hebben, zodat elke index wordt gebruikt. Ik heb deze procedures voor elke tabel gemaakt en vervolgens een script geschreven om waarden voor de voor- en achternaam op te halen om te gebruiken voor het testen. Hier is het script om de procedures te maken.
Zodra we de opgeslagen procedures hebben gemaakt, kunnen we het onderstaande script uitvoeren om ze aan te roepen. Start dit en wacht een paar minuten...
SET NOCOUNT ON; GO DECLARE @RowNum INT = 1; DECLARE @Round INT = 1; DECLARE @ID INT = 1; DECLARE @FN NVARCHAR(64); DECLARE @LN NVARCHAR(64); DECLARE @SQLstring NVARCHAR(MAX); DROP TABLE IF EXISTS #FirstNames, #LastNames; SELECT DISTINCT [FirstName], DENSE_RANK() OVER (ORDER BY [FirstName]) AS RowNum INTO #FirstNames FROM [dbo].[Customers] SELECT DISTINCT [LastName], DENSE_RANK() OVER (ORDER BY [LastName]) AS RowNum INTO #LastNames FROM [dbo].[Customers] WHILE 1=1 BEGIN SELECT @FN = ( SELECT [FirstName] FROM #FirstNames WHERE RowNum = @RowNum) SELECT @LN = ( SELECT [LastName] FROM #LastNames WHERE RowNum = @RowNum) SET @FN = SUBSTRING(@FN, 1, 5) + '%' SET @LN = SUBSTRING(@LN, 1, 5) + '%' EXEC [dbo].[usp_FindActiveCustomer_C] @FN; EXEC [dbo].[usp_FindAnyCustomer_C] @LN; EXEC [dbo].[usp_FindSpecificCustomer_C] @ID; EXEC [dbo].[usp_FindActiveCustomer_P] @FN; EXEC [dbo].[usp_FindAnyCustomer_P] @LN; EXEC [dbo].[usp_FindSpecificCustomer_P] @ID; EXEC [dbo].[usp_FindActiveCustomer_R] @FN; EXEC [dbo].[usp_FindAnyCustomer_R] @LN; EXEC [dbo].[usp_FindSpecificCustomer_R] @ID; EXEC [dbo].[usp_FindActiveCustomer_CS] @FN; EXEC [dbo].[usp_FindAnyCustomer_CS] @LN; EXEC [dbo].[usp_FindSpecificCustomer_CS] @ID; IF @ID < 5000000 BEGIN SET @ID = @ID + @Round END ELSE BEGIN SET @ID = 2 END IF @Round < 26 BEGIN SET @Round = @Round + 1 END ELSE BEGIN IF @RowNum < 2260 BEGIN SET @RowNum = @RowNum + 1 SET @Round = 1 END ELSE BEGIN SET @RowNum = 1 SET @Round = 1 END END END GO
Kijk na een paar minuten wat er in de Query Store staat:
SELECT [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], CAST(AVG([rs].[avg_duration])/1000 AS DECIMAL(10,2)) [AvgDuration_ms], CAST(AVG([rs].[avg_cpu_time]) AS DECIMAL(10,2)) [AvgCPU], CAST(AVG([rs].[avg_logical_io_reads]) AS DECIMAL(10,2)) [AvgLogicalReads], CAST(AVG([rs].[avg_physical_io_reads]) AS DECIMAL(10,2)) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [q].[object_id] <> 0 GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [o].[name];
U zult zien dat de meeste opgeslagen procedures slechts 20 keer zijn uitgevoerd, omdat twee procedures tegen [dbo].[Customers_Compress] echt zijn. traag. Dit is geen verrassing; noch [FirstName] noch [LastName] is geïndexeerd, dus elke query zal de tabel moeten scannen. Ik wil niet dat die twee vragen mijn testen vertragen, dus ik ga de werklast aanpassen en EXEC [dbo].[usp_FindActiveCustomer_CS] en EXEC [dbo].[usp_FindAnyCustomer_CS] becommentariëren en het dan opnieuw starten. Deze keer laat ik het ongeveer 10 minuten draaien, en als ik opnieuw naar de uitvoer van de Query Store kijk, heb ik nu een aantal goede gegevens. De ruwe cijfers staan hieronder, met de favoriete grafieken hieronder.
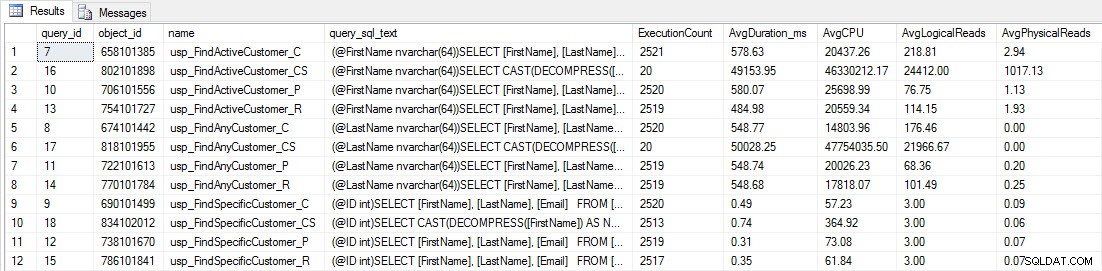 Prestatiegegevens van Query Store
Prestatiegegevens van Query Store
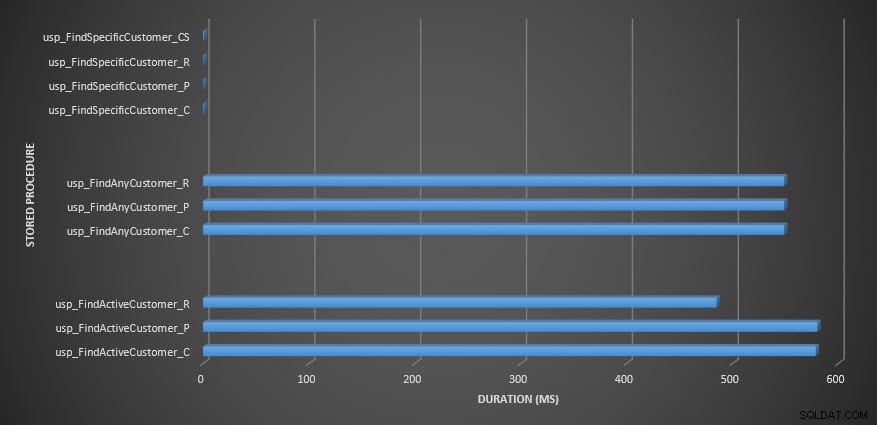 Duur opgeslagen procedure
Duur opgeslagen procedure
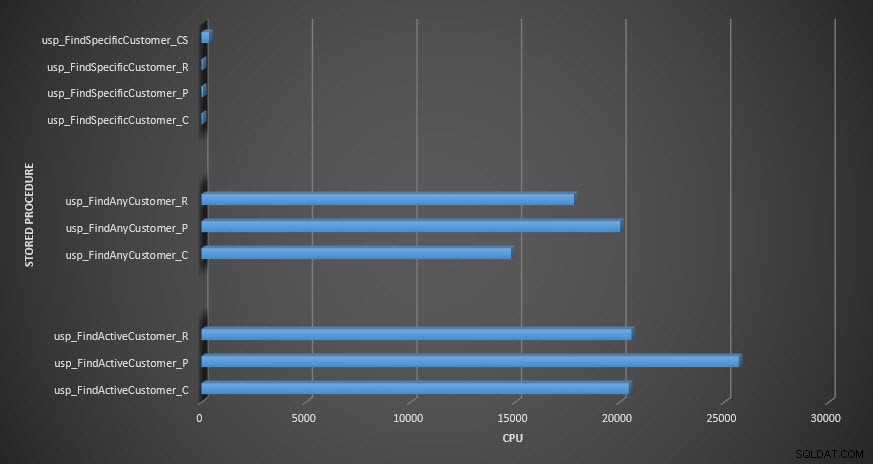 Opgeslagen procedure-CPU
Opgeslagen procedure-CPU
Herinnering:alle opgeslagen procedures die eindigen op _C komen uit de niet-gecomprimeerde tabel. De procedures die eindigen met _R zijn de rij-gecomprimeerde tabel, die eindigen met _P zijn paginagecomprimeerd, en degene met _CS gebruikt de COMPRESS-functie (ik heb de resultaten voor die tabel verwijderd voor usp_FindAnyCustomer_CS en usp_FindActiveCustomer_CS omdat ze de grafiek zo scheeftrekken dat we de verschillen in de rest van de gegevens). De procedures usp_FindAnyCustomer_* en usp_FindActiveCustomer_* gebruikten niet-geclusterde indexen en leverden duizenden rijen op voor elke uitvoering.
Ik had verwacht dat de duur van de procedures usp_FindAnyCustomer_* en usp_FindActiveCustomer_* tegen rij- en paginagecomprimeerde tabellen hoger zou zijn dan bij niet-gecomprimeerde tabellen, vanwege de overhead van het decomprimeren van de gegevens. De Query Store-gegevens ondersteunen mijn verwachting niet - de duur van die twee opgeslagen procedures is ongeveer hetzelfde (of minder in één geval!) in die drie tabellen. De logische IO voor de query's was bijna hetzelfde in de niet-gecomprimeerde tabellen en de pagina- en rij-gecomprimeerde tabellen.
In termen van CPU was het in de usp_FindActiveCustomer en usp_FindAnyCustomer opgeslagen procedures altijd hoger voor de gecomprimeerde tabellen. CPU was vergelijkbaar voor de usp_FindSpecificCustomer-procedure, die altijd een singleton-lookup was tegen de geclusterde index. Let op de hoge CPU (maar relatief lage duur) voor de usp_FindSpecificCustomer-procedure ten opzichte van de [dbo].[Customer_Compress]-tabel, waarvoor de DECOMPRESS-functie nodig was om gegevens in leesbaar formaat weer te geven.
OVERZICHT
De extra CPU die nodig is om gecomprimeerde gegevens op te halen, bestaat en kan worden gemeten met behulp van Query Store of traditionele baselining-methoden. Op basis van deze eerste tests is de CPU vergelijkbaar voor singleton-lookups, maar neemt toe met meer gegevens. Ik wilde SQL Server dwingen om meer dan 10 pagina's te decomprimeren - ik wilde er minstens 100. Ik heb variaties op dit script uitgevoerd, waarbij tienduizenden rijen werden geretourneerd, en de bevindingen kwamen overeen met wat je hier ziet. Mijn verwachting is dat om significante verschillen in duur te zien vanwege de tijd om de gegevens te decomprimeren, query's honderdduizenden of miljoenen rijen moeten retourneren. Als je in een OLTP-systeem zit, wil je niet zoveel rijen retourneren, dus de tests hier zouden je een idee moeten geven van hoe compressie de prestaties kan beïnvloeden. Als u zich in een datawarehouse bevindt, ziet u waarschijnlijk een langere duur en een hogere CPU bij het retourneren van grote datasets. Hoewel de COMPRESS-functie aanzienlijke ruimtebesparingen oplevert in vergelijking met pagina- en rijcompressie, maken de prestatieverbeteringen in termen van CPU en het onvermogen om de gecomprimeerde kolommen te indexeren vanwege hun gegevenstype het alleen haalbaar voor grote hoeveelheden gegevens die niet worden gezocht.