Vorige week presenteerde ik mijn T-SQL :Bad Habits and Best Practices-sessie tijdens de GroupBy-conferentie. Een video-replay en ander materiaal zijn hier beschikbaar:
- T-SQL:slechte gewoonten en beste praktijken
Een van de dingen die ik altijd in die sessie vermeld, is dat ik over het algemeen de voorkeur geef aan GROUP BY boven DISTINCT bij het verwijderen van duplicaten. Hoewel DISTINCT de bedoeling beter uitlegt, en GROUP BY alleen vereist is wanneer aggregaties aanwezig zijn, zijn ze in veel gevallen uitwisselbaar.
Laten we beginnen met iets eenvoudigs met Wide World Importers. Deze twee zoekopdrachten geven hetzelfde resultaat:
SELECT DISTINCT Description FROM Sales.OrderLines; SELECT Description FROM Sales.OrderLines GROUP BY Description;
En in feite leiden hun resultaten af met exact hetzelfde uitvoeringsplan:

Dezelfde operators, hetzelfde aantal reads, verwaarloosbare verschillen in CPU en totale duur (ze "winnen" om de beurt).
Dus waarom zou ik aanraden om de meer uitgebreide en minder intuïtieve GROUP BY-syntaxis te gebruiken in plaats van DISTINCT? In dit eenvoudige geval is het een muntstuk. In complexere gevallen kan DISTINCT echter meer werk doen. In wezen verzamelt DISTINCT alle rijen, inclusief alle expressies die moeten worden geëvalueerd, en gooit vervolgens duplicaten weg. GROUP BY kan (opnieuw, in sommige gevallen) de dubbele rijen uitfilteren vóór het uitvoeren van een van dat werk.
Laten we het bijvoorbeeld hebben over stringaggregatie. In SQL Server v.Next kun je STRING_AGG gebruiken (zie berichten hier en hier), de rest van ons moet doorgaan met FOR XML PATH (en voordat je me vertelt hoe geweldig recursieve CTE's hiervoor zijn, alsjeblieft lees ook dit bericht). We hebben mogelijk een vraag als deze, die probeert alle bestellingen uit de tabel Sales.OrderLines te retourneren, samen met artikelbeschrijvingen als een door sluiers gescheiden lijst:
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Dit is een typische vraag om dit soort problemen op te lossen, met het volgende uitvoeringsplan (de waarschuwing in alle plannen is alleen voor de impliciete conversie die uit het XPath-filter komt):
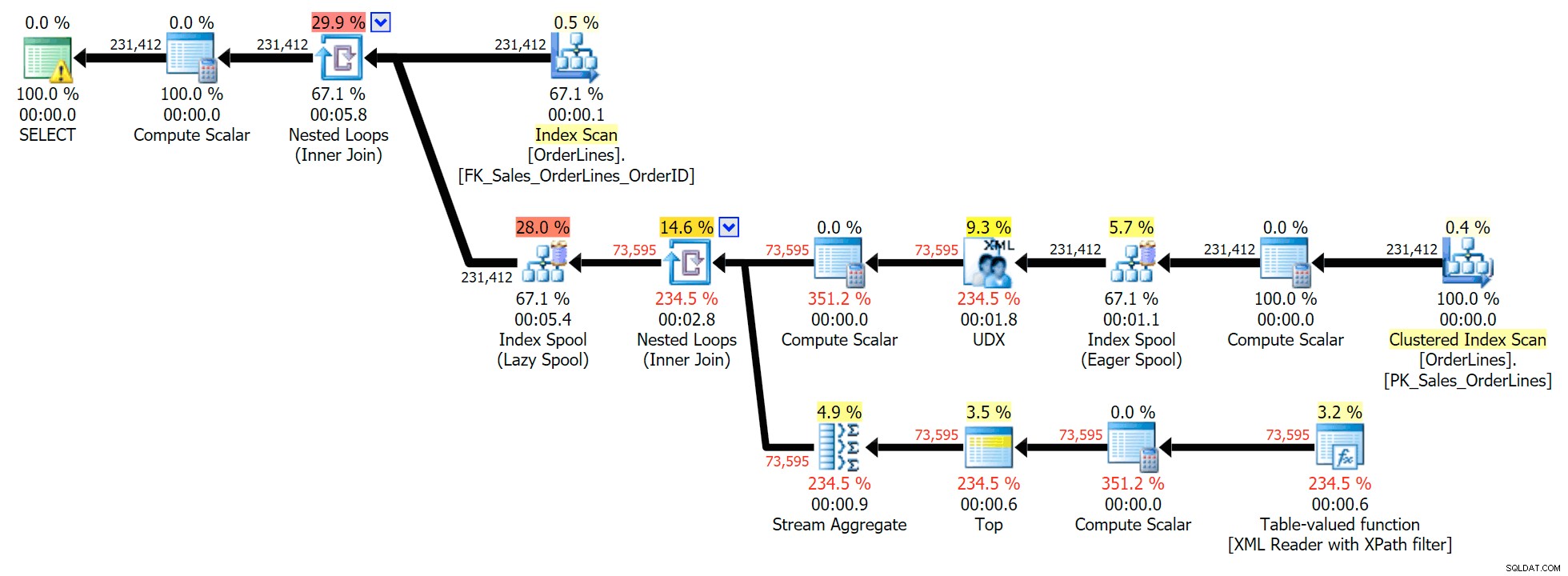
Het heeft echter een probleem dat u mogelijk opmerkt in het uitvoeraantal rijen. Je kunt het zeker herkennen als je de uitvoer terloops scant:

Voor elke bestelling zien we de door sluistekens gescheiden lijst, maar we zien een rij voor elk item bij elke bestelling. De reflexmatige reactie is om een DISTINCT op de kolomlijst te gooien:
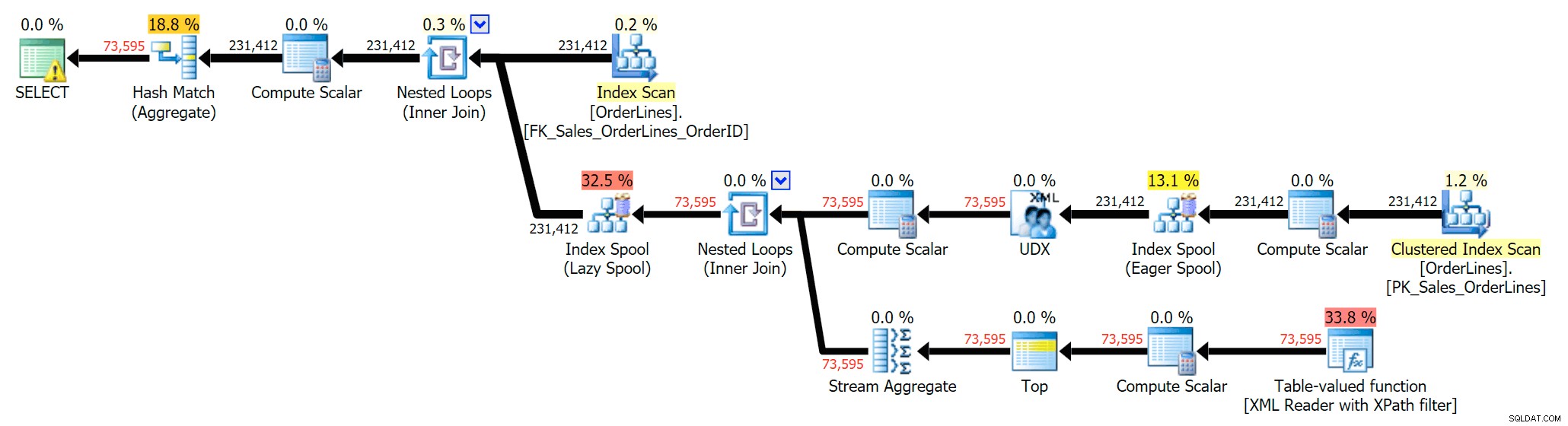
SELECT DISTINCT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Dat elimineert de duplicaten (en verandert de volgorde-eigenschappen op de scans, zodat de resultaten niet noodzakelijkerwijs in een voorspelbare volgorde verschijnen), en levert het volgende uitvoeringsplan op:
Een andere manier om dit te doen is door een GROUP BY toe te voegen voor de OrderID (aangezien de subquery niet expliciet nodig om opnieuw naar te verwijzen in de GROUP BY):
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o GROUP BY o.OrderID;
Dit levert dezelfde resultaten op (hoewel de bestelling is teruggekeerd) en een iets ander plan:
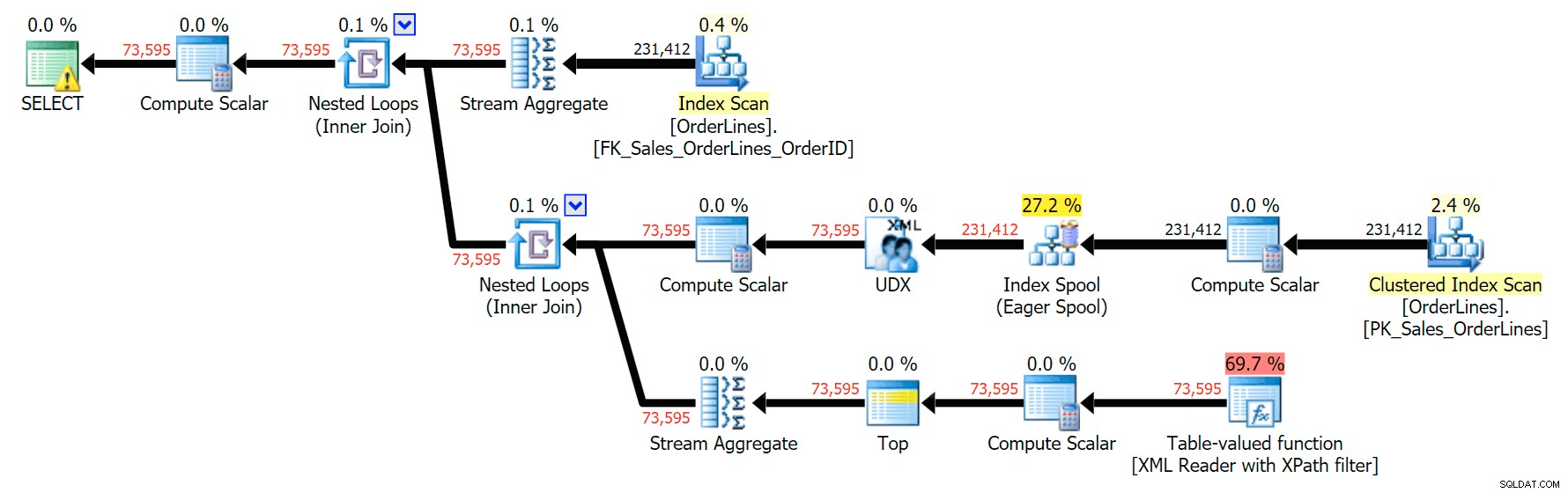
De prestatiestatistieken zijn echter interessant om te vergelijken.

De DISTINCT-variatie duurde 4x zo lang, gebruikte 4x de CPU en bijna 6x de uitlezingen in vergelijking met de GROUP BY-variatie. (Vergeet niet dat deze zoekopdrachten exact dezelfde resultaten opleveren.)
We kunnen de uitvoeringsplannen ook vergelijken wanneer we de kosten wijzigen van CPU + I/O gecombineerd naar I/O alleen, een functie die exclusief is voor Plan Explorer. We tonen ook de opnieuw berekende waarden (die zijn gebaseerd op de werkelijke kosten waargenomen tijdens het uitvoeren van query's, een functie die ook alleen te vinden is in Plan Explorer). Hier is het DISTINCT-abonnement:
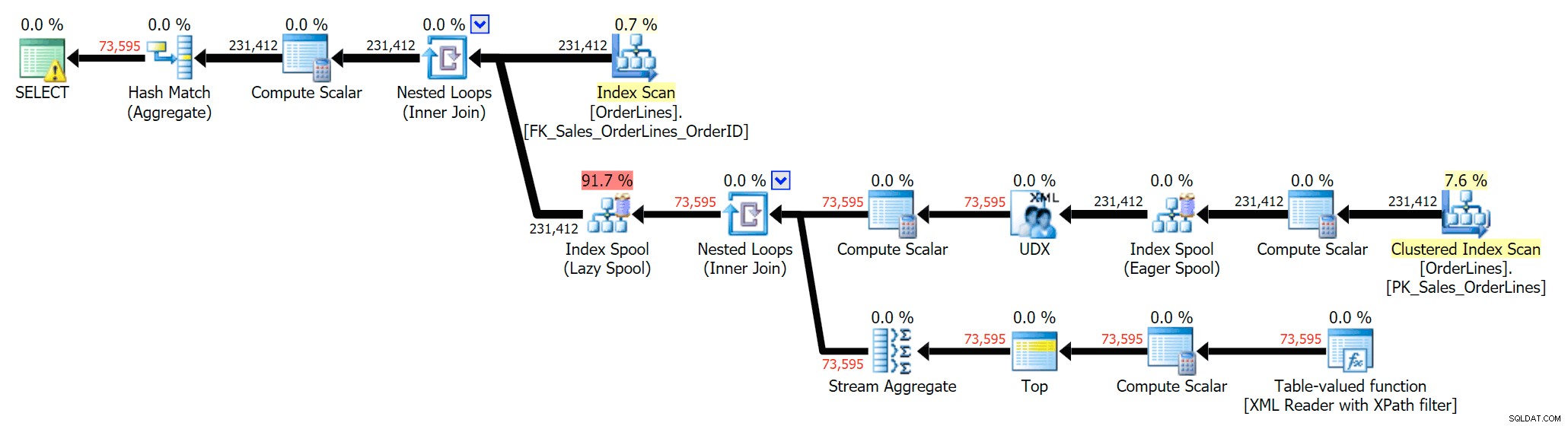
En hier is het GROUP BY-plan:
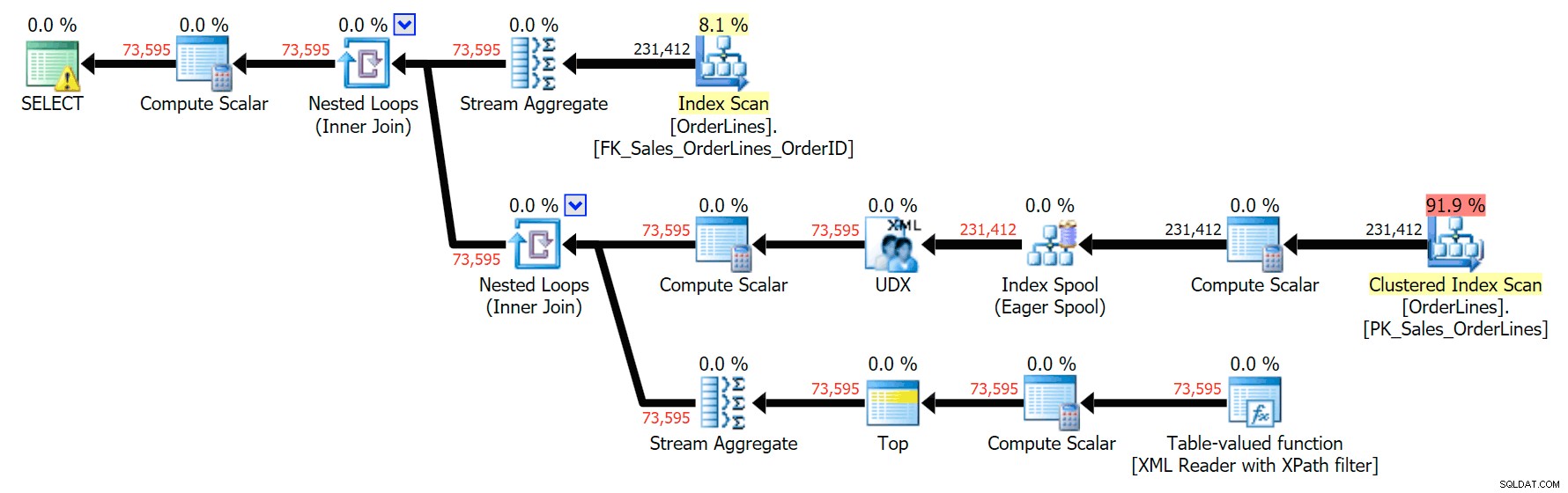
Je kunt zien dat in het GROUP BY-plan bijna alle I/O-kosten in de scans zitten (hier is de tooltip voor de CI-scan, met een I/O-kost van ~3,4 "query bucks"). Maar in het DISTINCT-plan zitten de meeste I/O-kosten in de index-spool (en hier is die tooltip; de I/O-kosten zijn hier ~ 41,4 "query-dollars"). Merk op dat de CPU ook een stuk hoger is met de indexspoel. We zullen het nog een keer hebben over "query bucks", maar het punt is dat de indexspoel meer dan 10x zo duur is als de scan - maar de scan is nog steeds dezelfde 3,4 in beide plannen. Dit is een van de redenen waarom het me altijd irriteert als mensen zeggen dat ze de operator in het plan met de hoogste kosten moeten "repareren". Sommige operators in het plan zullen altijd de duurste zijn; dat betekent niet dat het gerepareerd moet worden.
@AaronBertrand die zoekopdrachten zijn niet echt logisch equivalent — DISTINCT is op beide kolommen, terwijl uw GROUP BY slechts op één staat
— Adam Machanic (@AdamMachanic) 20 januari 2017
Hoewel Adam Machanic gelijk heeft als hij zegt dat deze zoekopdrachten semantisch verschillend zijn, is het resultaat hetzelfde:we krijgen hetzelfde aantal rijen, met exact dezelfde resultaten, en we hebben het gedaan met veel minder reads en CPU.
Dus hoewel DISTINCT en GROUP BY in veel scenario's identiek zijn, is hier een geval waarin de GROUP BY-benadering zeker leidt tot betere prestaties (ten koste van een minder duidelijke declaratieve intentie in de query zelf). Ik zou graag willen weten of u denkt dat er scenario's zijn waarin DISTINCT beter is dan GROUP BY, in ieder geval in termen van prestaties, die veel minder subjectief zijn dan stijl, of dat een verklaring zelfdocumenterend moet zijn.
Dit bericht past in mijn serie 'verrassingen en aannames' omdat veel dingen die we als waarheden beschouwen op basis van beperkte observaties of specifieke gebruiksscenario's kunnen worden getest wanneer ze in andere scenario's worden gebruikt. We moeten alleen onthouden dat we de tijd moeten nemen om het te doen als onderdeel van SQL-queryoptimalisatie...
Referenties
- Gegroepeerde aaneenschakeling in SQL Server
- Gegroepeerde aaneenschakeling:duplicaten bestellen en verwijderen
- Vier praktische use-cases voor gegroepeerde aaneenschakeling
- SQL Server v.Next:STRING_AGG() prestaties
- SQL Server v.Next:STRING_AGG Performance, Part 2