Een prestatieprobleem dat ik vaak zie, is wanneer gebruikers een deel van een tekenreeks moeten matchen met een zoekopdracht zoals de volgende:
... WHERE SomeColumn LIKE N'%SomePortion%';
Met een leidende wildcard is dit predikaat "niet-SARGable" - gewoon een mooie manier om te zeggen dat we de relevante rijen niet kunnen vinden door een zoekopdracht te gebruiken tegen een index op SomeColumn .
Een oplossing waar we nogal voorzichtig over zijn, is zoeken in volledige tekst; dit is echter een complexe oplossing en vereist dat het zoekpatroon uit volledige woorden bestaat, geen stopwoorden gebruikt, enzovoort. Dit kan helpen als we op zoek zijn naar rijen waarin een beschrijving het woord 'zacht' (of andere afgeleiden zoals 'zachter' of 'zacht') bevat, maar het helpt niet als we op zoek zijn naar tekenreeksen die kunnen worden opgenomen binnen woorden (of die helemaal geen woorden zijn, zoals alle product-SKU's die "X45-B" bevatten of alle kentekenplaten die de reeks "7RA" bevatten).
Wat als SQL Server op de een of andere manier op de hoogte was van alle mogelijke delen van een string? Mijn denkproces is in de trant van trigram / trigraph in PostgreSQL. Het basisconcept is dat de engine de mogelijkheid heeft om zoekacties in puntstijl uit te voeren op substrings, wat betekent dat je niet de hele tabel hoeft te scannen en elke volledige waarde hoeft te ontleden.
Het specifieke voorbeeld dat ze daar gebruiken is het woord cat . Naast het volledige woord, kan het worden opgesplitst in delen:c , ca , en at (ze laten a weg en t per definitie - geen enkele subtekenreeks kan korter zijn dan twee tekens). In SQL Server hoeven we het niet zo ingewikkeld te maken; we hebben maar de helft van het trigram nodig - als we nadenken over het bouwen van een datastructuur die alle substrings van cat bevat , we hebben alleen deze waarden nodig:
- kat
- om
- t
We hebben c niet nodig of ca , omdat iedereen die zoekt naar LIKE '%ca%' kon gemakkelijk waarde 1 vinden met LIKE 'ca%' in plaats van. Evenzo, iedereen die zoekt naar LIKE '%at%' of LIKE '%a%' zou alleen een volgwildcard kunnen gebruiken voor deze drie waarden en degene vinden die overeenkomt (bijv. LIKE 'at%' zal waarde 2 vinden, en LIKE 'a%' zal ook waarde 2 vinden, zonder die substrings binnen waarde 1 te hoeven vinden, waar de echte pijn vandaan zou komen).
Dus, gezien het feit dat SQL Server zoiets niet ingebouwd heeft, hoe genereren we zo'n trigram?
Een aparte fragmententabel
Ik stop met het verwijzen naar "trigram" hier omdat dit niet echt analoog is aan die functie in PostgreSQL. Wat we in wezen gaan doen, is een aparte tabel bouwen met alle "fragmenten" van de originele string. (Dus in de cat er zou bijvoorbeeld een nieuwe tabel zijn met die drie rijen, en LIKE '%pattern%' zoekopdrachten zouden tegen die nieuwe tabel worden gericht als LIKE 'pattern%' predikaten.)
Laat me, voordat ik begin te laten zien hoe mijn voorgestelde oplossing zou werken, absoluut duidelijk zijn dat deze oplossing niet in elk afzonderlijk geval moet worden gebruikt waar LIKE '%wildcard%' zoekopdrachten zijn traag. Vanwege de manier waarop we de brongegevens in fragmenten gaan "exploderen", is het waarschijnlijk praktisch beperkt tot kleinere strings, zoals adressen of namen, in tegenstelling tot grotere strings, zoals productbeschrijvingen of sessie-samenvattingen.
Een praktischer voorbeeld dan cat is om te kijken naar de Sales.Customer tabel in de WideWorldImporters-voorbeelddatabase. Het heeft adresregels (beide nvarchar(60) ), met de waardevolle adresgegevens in de kolom DeliveryAddressLine2 (om onbekende redenen). Iemand is misschien op zoek naar iemand die in een straat woont met de naam Hudecova , dus ze zullen een zoekopdracht als volgt uitvoeren:
SELECT CustomerID, DeliveryAddressLine2
FROM Sales.Customers
WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
/* This returns two rows:
CustomerID DeliveryAddressLine2
---------- ----------------------
61 1695 Hudecova Avenue
181 1846 Hudecova Crescent
*/ Zoals je zou verwachten, moet SQL Server een scan uitvoeren om die twee rijen te vinden. Wat eenvoudig zou moeten zijn; vanwege de complexiteit van de tabel levert deze triviale query echter een zeer rommelig uitvoeringsplan op (de scan is gemarkeerd en heeft een waarschuwing voor resterende I/O):
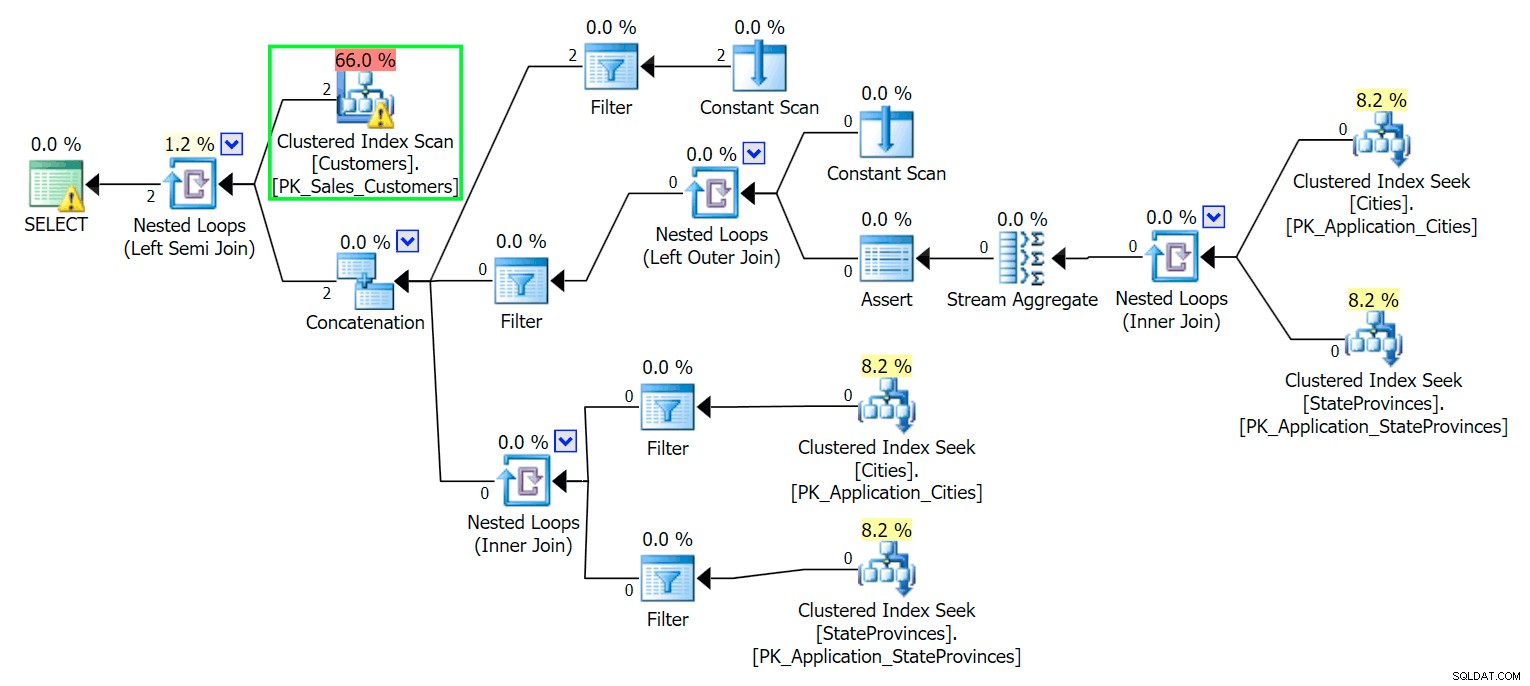
Bleken. Om ons leven eenvoudig te houden, en om ervoor te zorgen dat we niet op een hoop rode haring jagen, laten we een nieuwe tabel maken met een subset van de kolommen, en om te beginnen voegen we diezelfde twee rijen van boven in:
CREATE TABLE Sales.CustomersCopy ( CustomerID int IDENTITY(1,1) CONSTRAINT PK_CustomersCopy PRIMARY KEY, CustomerName nvarchar(100) NOT NULL, DeliveryAddressLine1 nvarchar(60) NOT NULL, DeliveryAddressLine2 nvarchar(60) ); GO INSERT Sales.CustomersCopy ( CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 ) SELECT CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 FROM Sales.Customers WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
Als we nu dezelfde query uitvoeren die we tegen de hoofdtabel hebben uitgevoerd, krijgen we iets dat veel redelijker is om als uitgangspunt te nemen. Dit wordt nog steeds een scan, wat we ook doen - als we een index toevoegen met DeliveryAddressLine2 als de leidende sleutelkolom, zullen we hoogstwaarschijnlijk een indexscan krijgen, met een sleutelzoekopdracht afhankelijk van of de index de kolommen in de query dekt. Zoals het is, krijgen we een geclusterde indexscan:
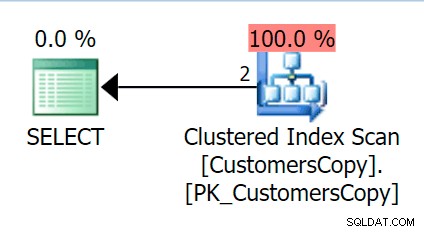
Laten we vervolgens een functie maken die deze adreswaarden in fragmenten zal "exploderen". We verwachten 1846 Hudecova Crescent , om bijvoorbeeld de volgende set fragmenten te hebben:
- 1846 Hudecova Halve Maan
- 846 Hudecova Halve Maan
- 46 Hudecova Halve Maan
- 6 Hudecova Halve Maan
- Hudecova Halve Maan
- Hudecova Halve Maan
- udecova Halve maan
- decova halve maan
- ecova Halve maan
- cova halve maan
- ovaal halve maan
- va Crescent
- een halve maan
- Halve maan
- Sikkel
- recent
- cent
- geur
- cent
- ent
- nt
- t
Het is vrij triviaal om een functie te schrijven die deze uitvoer zal produceren - we hebben alleen een recursieve CTE nodig die kan worden gebruikt om door elk teken over de hele lengte van de invoer te stappen:
CREATE FUNCTION dbo.CreateStringFragments( @input nvarchar(60) )
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
WITH x(x) AS
(
SELECT 1 UNION ALL SELECT x+1 FROM x WHERE x < (LEN(@input))
)
SELECT Fragment = SUBSTRING(@input, x, LEN(@input)) FROM x
);
GO
SELECT Fragment FROM dbo.CreateStringFragments(N'1846 Hudecova Crescent');
-- same output as above bulleted list Laten we nu een tabel maken waarin alle adresfragmenten worden opgeslagen en tot welke klant ze behoren:
CREATE TABLE Sales.CustomerAddressFragments ( CustomerID int NOT NULL, Fragment nvarchar(60) NOT NULL, CONSTRAINT FK_Customers FOREIGN KEY(CustomerID) REFERENCES Sales.CustomersCopy(CustomerID) ); CREATE CLUSTERED INDEX s_cat ON Sales.CustomerAddressFragments(Fragment, CustomerID);
Dan kunnen we het als volgt invullen:
INSERT Sales.CustomerAddressFragments(CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;
Voor onze twee waarden voegt dit 42 rijen in (het ene adres heeft 20 tekens en het andere heeft 22). Nu wordt onze vraag:
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
INNER JOIN Sales.CustomerAddressFragments AS f
ON f.CustomerID = c.CustomerID
AND f.Fragment LIKE N'Hudecova%'; Hier is een veel mooier plan – twee geclusterde index *zoekt* en een geneste loops join:
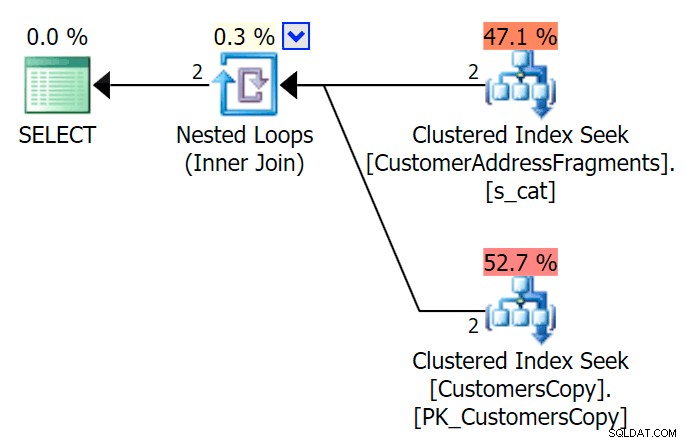
We kunnen dit ook op een andere manier doen, met behulp van EXISTS :
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
WHERE EXISTS
(
SELECT 1 FROM Sales.CustomerAddressFragments
WHERE CustomerID = c.CustomerID
AND Fragment LIKE N'Hudecova%'
); Hier is dat plan, dat op het eerste gezicht duurder lijkt - het kiest ervoor om de CustomersCopy-tabel te scannen. We zullen binnenkort zien waarom dit de betere benadering is voor zoekopdrachten:
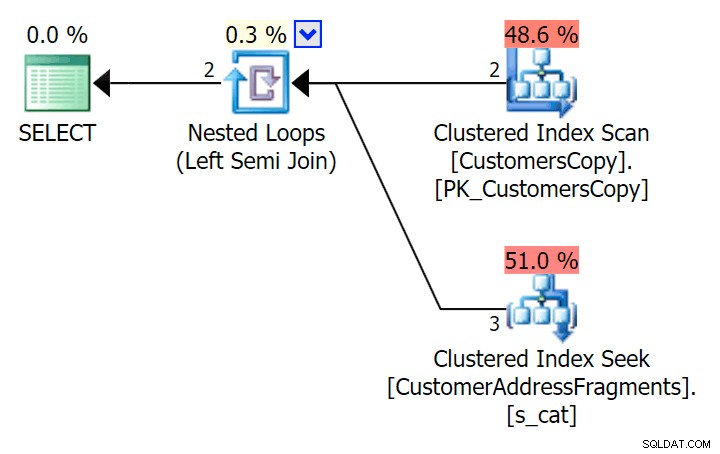
Nu, op deze enorme dataset van 42 rijen, zijn de verschillen in duur en I/O zo minuscuul dat ze niet relevant zijn (en in feite, bij dit kleine formaat ziet de scan tegen de basistabel er goedkoper uit in termen van I/ O dan de andere twee plannen die de fragmenttabel gebruiken):

Wat als we deze tabellen met veel meer gegevens zouden vullen? Mijn exemplaar van Sales.Customers heeft 663 rijen, dus als we die tegen zichzelf kruisen, komen we ergens in de buurt van 440.000 rijen. Dus laten we gewoon 400K pureren en een veel grotere tabel genereren:
TRUNCATE TABLE Sales.CustomerAddressFragments; DELETE Sales.CustomersCopy; DBCC FREEPROCCACHE WITH NO_INFOMSGS; INSERT Sales.CustomersCopy WITH (TABLOCKX) (CustomerName, DeliveryAddressLine1, DeliveryAddressLine2) SELECT TOP (400000) c1.CustomerName, c1.DeliveryAddressLine1, c2.DeliveryAddressLine2 FROM Sales.Customers c1 CROSS JOIN Sales.Customers c2 ORDER BY NEWID(); -- fun for distribution -- this will take a bit longer - on my system, ~4 minutes -- probably because I didn't bother to pre-expand files INSERT Sales.CustomerAddressFragments WITH (TABLOCKX) (CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f; -- repeated for compressed version of the table -- 7.25 million rows, 278MB (79MB compressed; saving those tests for another day)
Om nu de prestatie- en uitvoeringsplannen te vergelijken met een verscheidenheid aan mogelijke zoekparameters, heb ik de bovenstaande drie zoekopdrachten getest met deze predikaten:
| Query | Predikaten | ||||
|---|---|---|---|---|---|
| WAAR DeliveryLineAddress2 LIKE … | N'%Hudecova%' | N'%cova%' | N'%ova%' | N'%va%' | |
| DOE MEE … WAAR Fragment LIKE … | N'Hudecova%' | N'cova%' | N'ova%' | N'va%' | |
| WAAR BESTAAT (… WAAR Fragment LIKE …) | |||||
Als we letters uit het zoekpatroon verwijderen, zou ik verwachten dat er meer rijen worden weergegeven, en misschien andere strategieën die door de optimizer zijn gekozen. Laten we eens kijken hoe het voor elk patroon ging:
Hudecova%
Voor dit patroon was de scan nog steeds hetzelfde voor de LIKE-conditie; met meer gegevens zijn de kosten echter veel hoger. De zoekopdrachten in de fragmententabel werpen echt hun vruchten af bij dit aantal rijen (1206), zelfs met erg lage schattingen. Het EXISTS-plan voegt een aparte soort toe, waarvan je zou verwachten dat het de kosten zou verhogen, maar in dit geval leidt het tot minder leesbewerkingen:

 Plan voor de JOIN naar de fragmententabel
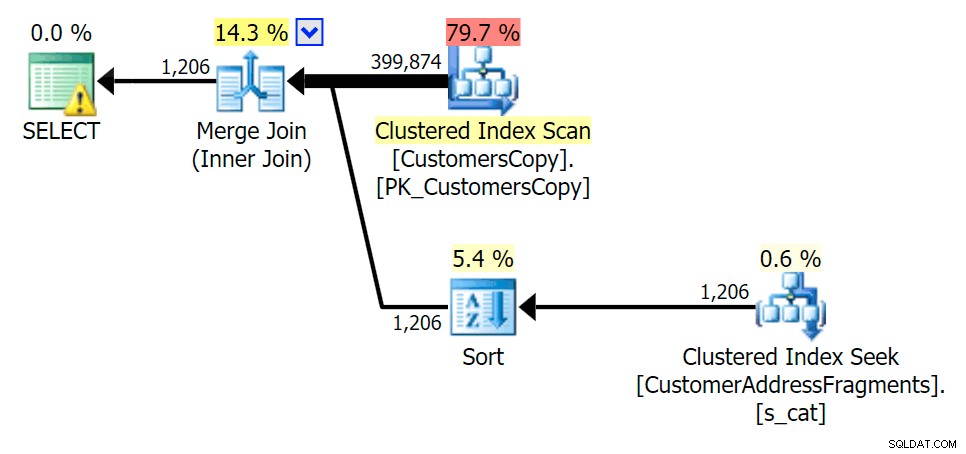
Plan voor de JOIN naar de fragmententabel 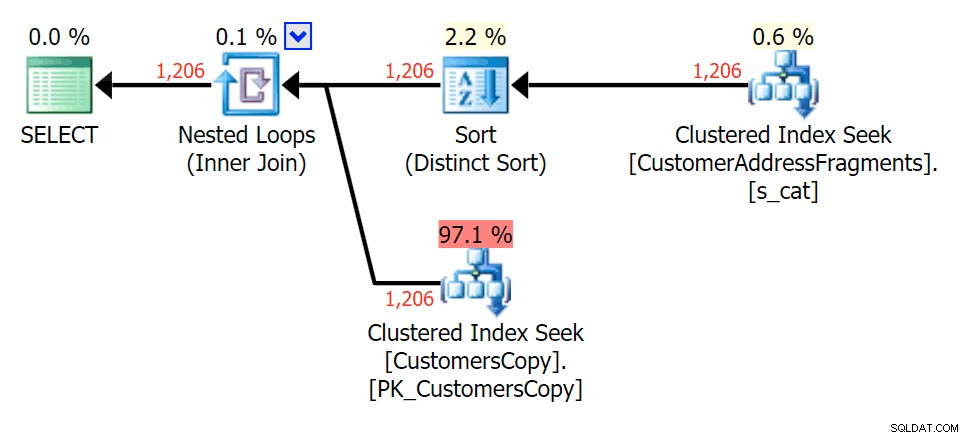 Plan voor de EXISTS tegen de fragmententabel
Plan voor de EXISTS tegen de fragmententabel cova%
Terwijl we enkele letters van ons predikaat verwijderen, zien we dat de waardes eigenlijk iets hoger zijn dan bij de originele geclusterde indexscan, en nu zijn we over -schat de rijen. Zelfs nog, onze duur blijft aanzienlijk lager bij beide fragmentquery's; het verschil is deze keer subtieler - beide hebben een soort (alleen EXISTS is te onderscheiden):

 Plan voor de JOIN naar de fragmententabel
Plan voor de JOIN naar de fragmententabel 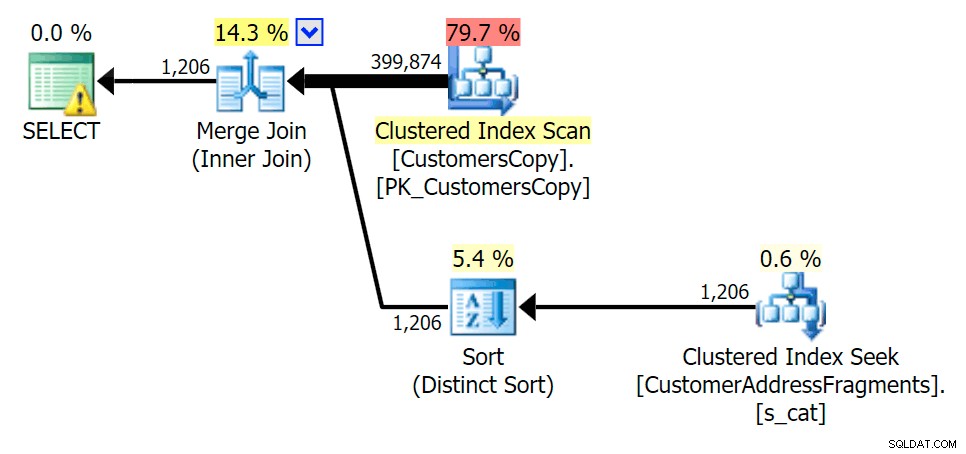 Plan voor de EXISTS tegen de fragmententabel
Plan voor de EXISTS tegen de fragmententabel ova%
Het strippen van een extra letter veranderde niet veel; hoewel het de moeite waard is om op te merken hoeveel de geschatte en werkelijke rijen hier springen - wat betekent dat dit een veelvoorkomend substringpatroon kan zijn. De originele LIKE-query is nog steeds een stuk langzamer dan de fragment-query's.

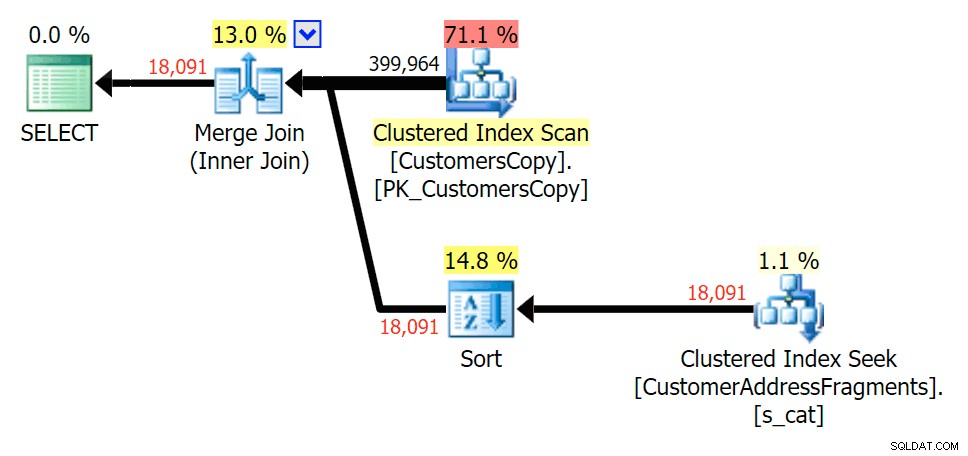 Plan voor de JOIN naar de fragmententabel
Plan voor de JOIN naar de fragmententabel 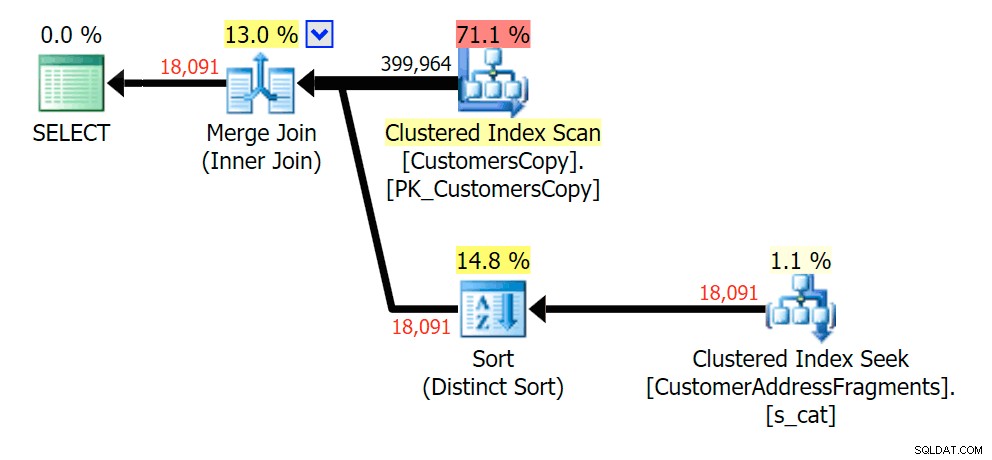 Plan voor de EXISTS tegen de fragmententabel
Plan voor de EXISTS tegen de fragmententabel va%
Tot twee letters, dit introduceert onze eerste discrepantie. Merk op dat de JOIN meer . produceert rijen dan de oorspronkelijke query of de EXISTS. Waarom zou dat zijn?

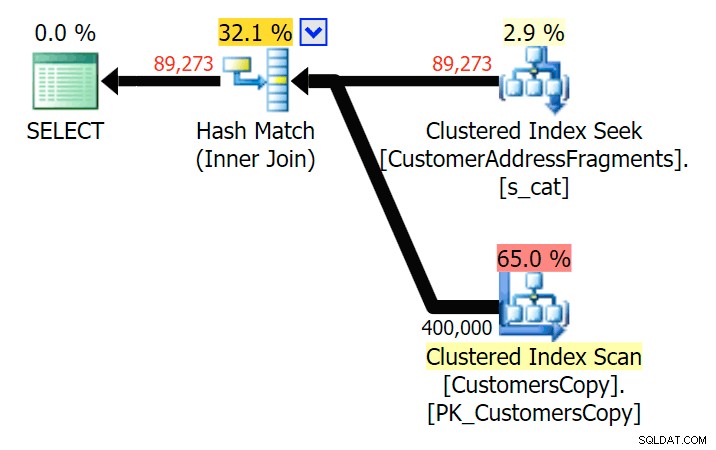 Plan voor de JOIN naar de fragmententabel
Plan voor de JOIN naar de fragmententabel 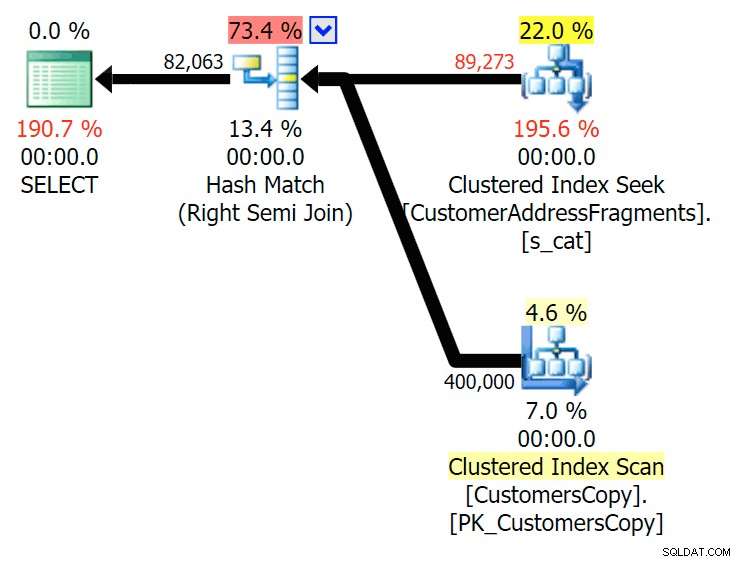 Plan voor de EXISTS tegen de fragmententabel We hoeven niet ver te zoeken. Onthoud dat er een fragment is dat begint met elk volgend teken in het oorspronkelijke adres, wat zoiets betekent als
Plan voor de EXISTS tegen de fragmententabel We hoeven niet ver te zoeken. Onthoud dat er een fragment is dat begint met elk volgend teken in het oorspronkelijke adres, wat zoiets betekent als 899 Valentova Road heeft twee rijen in de fragmententabel die beginnen met va (hoofdlettergevoeligheid terzijde). Je komt dus overeen op beide Fragment = N'Valentova Road' en Fragment = N'va Road' . Ik zal je het zoeken besparen en een enkel voorbeeld geven van de vele: SELECT TOP (2) c.CustomerID, c.DeliveryAddressLine2, f.Fragment FROM Sales.CustomersCopy AS c INNER JOIN Sales.CustomerAddressFragments AS f ON c.CustomerID = f.CustomerID WHERE f.Fragment LIKE N'va%' AND c.DeliveryAddressLine2 = N'899 Valentova Road' AND f.CustomerID = 351; /* CustomerID DeliveryAddressLine2 Fragment ---------- -------------------- -------------- 351 899 Valentova Road va Road 351 899 Valentova Road Valentova Road */
Dit verklaart gemakkelijk waarom de JOIN meer rijen produceert; als u de uitvoer van de oorspronkelijke LIKE-query wilt matchen, moet u EXISTS gebruiken. Het feit dat de juiste resultaten meestal ook op een minder arbeidsintensieve manier kunnen worden verkregen, is slechts een bonus. (Ik zou nerveus zijn als mensen de JOIN zouden kiezen als dat de herhaaldelijk efficiëntere optie zou zijn - je moet altijd de voorkeur geven aan correcte resultaten boven je zorgen maken over de prestaties.)
Samenvatting
Het is duidelijk dat in dit specifieke geval – met een adreskolom van nvarchar(60) en een maximale lengte van 26 tekens – het opsplitsen van elk adres in fragmenten kan enige verlichting brengen bij anders dure "leidende wildcard"-zoekopdrachten. De betere uitbetaling lijkt te gebeuren wanneer het zoekpatroon groter is en als resultaat unieker. Ik heb ook aangetoond waarom EXISTS beter is in scenario's waarin meerdere overeenkomsten mogelijk zijn - met een JOIN krijg je redundante uitvoer, tenzij je een "grootste n per groep"-logica toevoegt.
Voorbehoud
Ik zal de eerste zijn om toe te geven dat deze oplossing onvolmaakt, onvolledig en niet grondig is uitgewerkt:
- Je moet de fragmententabel gesynchroniseerd houden met de basistabel met behulp van triggers - het eenvoudigst zou zijn voor invoegingen en updates, verwijder alle rijen voor die klanten en voeg ze opnieuw toe, en voor verwijderingen verwijder je uiteraard de rijen uit de fragmenten tafel.
- Zoals gezegd werkte deze oplossing beter voor deze specifieke gegevensgrootte, en mogelijk minder goed voor andere stringlengtes. Het zou verdere tests rechtvaardigen om ervoor te zorgen dat het geschikt is voor uw kolomgrootte, gemiddelde waardelengte en typische lengte van de zoekparameter.
- Aangezien we veel kopieën zullen hebben van fragmenten zoals "Crescent" en "Street" (laat staan allemaal dezelfde of vergelijkbare straatnamen en huisnummers), zou het verder kunnen normaliseren door elk uniek fragment op te slaan in een fragmententabel, en dan nog een andere tabel die fungeert als een veel-op-veel-overgangstabel. Dat zou veel omslachtiger zijn om op te zetten, en ik weet niet zeker of er veel te winnen valt.
- Ik heb paginacompressie nog niet volledig onderzocht, het lijkt erop dat dit – althans in theorie – enig voordeel zou kunnen opleveren. Ik heb ook het gevoel dat een columnstore-implementatie in sommige gevallen ook nuttig kan zijn.
Hoe dan ook, dat gezegd hebbende, ik wilde het gewoon delen als een idee in ontwikkeling en om feedback vragen over de bruikbaarheid ervan voor specifieke gebruikssituaties. Ik kan dieper ingaan op meer details voor een toekomstige post als je me kunt laten weten welke aspecten van deze oplossing je interesseren.