Zoals elke programmeertaal heeft T-SQL een aantal veelvoorkomende bugs en valkuilen, waarvan sommige onjuiste resultaten veroorzaken en andere prestatieproblemen veroorzaken. In veel van die gevallen zijn er best practices die u kunnen helpen voorkomen dat u in de problemen komt. Ik heb mede-Microsoft Data Platform MVP's ondervraagd en gevraagd naar de bugs en valkuilen die ze vaak zien of die ze gewoon bijzonder interessant vinden, en de best practices die ze gebruiken om die te vermijden. Ik heb veel interessante gevallen.
Veel dank aan Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser en Chan Ming Man voor het delen van uw kennis en ervaring!
Dit artikel is het eerste in een reeks over dit onderwerp. Elk artikel richt zich op een bepaald thema. Deze maand focus ik op bugs, valkuilen en best practices die te maken hebben met determinisme. Een deterministische berekening is een berekening die gegarandeerd herhaalbare resultaten oplevert bij dezelfde invoer. Er zijn veel bugs en valkuilen die het gevolg zijn van het gebruik van niet-deterministische berekeningen. In dit artikel behandel ik de implicaties van het gebruik van niet-deterministische volgorde, niet-deterministische functies, meerdere verwijzingen naar tabeluitdrukkingen met niet-deterministische berekeningen, en het gebruik van CASE-expressies en de NULLIF-functie met niet-deterministische berekeningen.
Ik gebruik de voorbeelddatabase TSQLV5 in veel van de voorbeelden in deze serie.
Niet-deterministische volgorde
Een veelvoorkomende bron voor bugs in T-SQL is het gebruik van niet-deterministische volgorde. Dat wil zeggen, wanneer uw volgorde op lijst een rij niet uniek identificeert. Het kan een presentatiebestelling, TOP/OFFSET-FETCH-bestelling of raambestelling zijn.
Neem bijvoorbeeld een klassiek pagingscenario met het OFFSET-FETCH-filter. U moet de tabel Sales.Orders doorzoeken en één pagina van 10 rijen tegelijk retourneren, gerangschikt op besteldatum, aflopend (meest recente eerst). Ik zal voor de eenvoud constanten gebruiken voor de offset- en fetch-elementen, maar meestal zijn het uitdrukkingen die zijn gebaseerd op invoerparameters.
De volgende zoekopdracht (noem het Query 1) retourneert de eerste pagina van 10 meest recente bestellingen:
USE TSQLV5; SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
Het plan voor Query 1 wordt getoond in figuur 1.
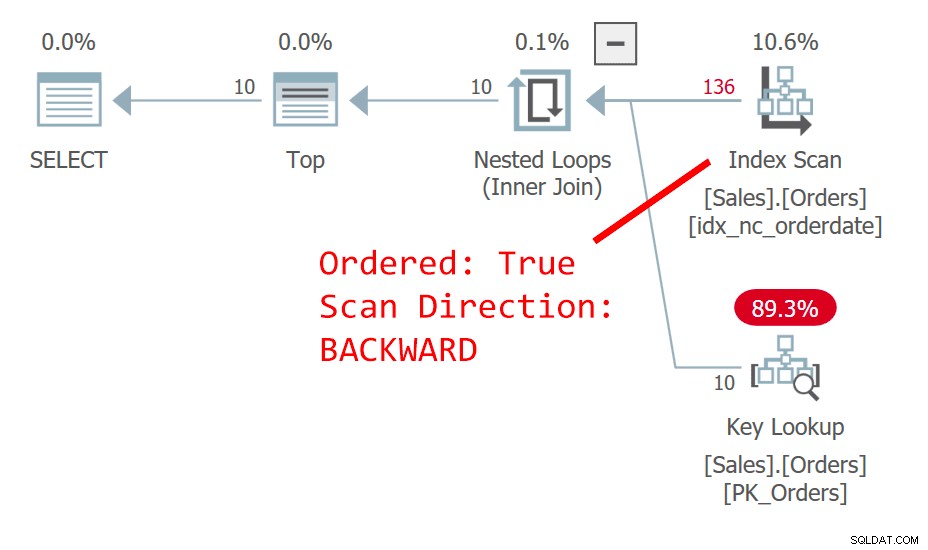 Figuur 1:Plan voor query 1
Figuur 1:Plan voor query 1
De query ordent de rijen op orderdatum, aflopend. De kolom orderdatum identificeert een rij niet uniek. Deze niet-deterministische volgorde betekent dat er conceptueel geen voorkeur is tussen de rijen met dezelfde datum. In het geval van gelijken, bepaalt welke rij SQL Server de voorkeur geeft, zaken als plankeuzes en fysieke gegevenslay-out - niet iets waarop u kunt vertrouwen als herhaalbaar. Het plan in figuur 1 scant de index op besteldatum achteruit geordend. Het gebeurt zo dat deze tabel een geclusterde index heeft op orderid, en in een geclusterde tabel wordt de geclusterde indexsleutel gebruikt als rij-locator in niet-geclusterde indexen. Het wordt eigenlijk impliciet gepositioneerd als het laatste sleutelelement in alle niet-geclusterde indexen, ook al zou SQL Server het in theorie als een opgenomen kolom in de index hebben kunnen plaatsen. Dus impliciet is de niet-geclusterde index op orderdatum feitelijk gedefinieerd op (orderdate, orderid). Bijgevolg wordt in onze geordende achterwaartse scan van de index, tussen gekoppelde rijen op basis van orderdatum, een rij met een hogere orderid-waarde geopend vóór een rij met een lagere orderid-waarde. Deze query genereert de volgende uitvoer:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 *** 11068 2019-05-04 62
Gebruik vervolgens de volgende query (noem het Query 2) om de tweede pagina van 10 rijen te krijgen:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
Het plan voor Query wordt getoond in figuur 2.
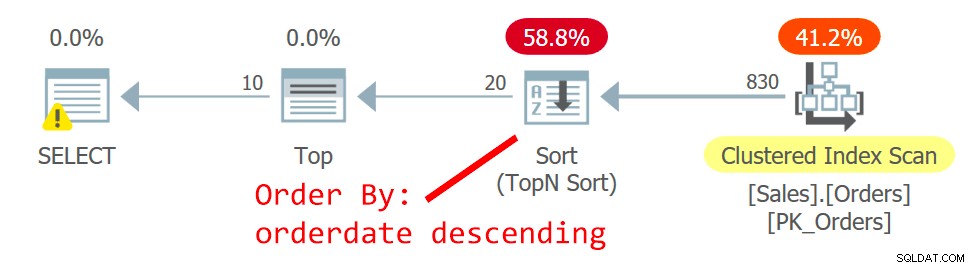
Figuur 2:Plan voor query 2
De optimizer kiest een ander plan:het ene scant de geclusterde index op een ongeordende manier en gebruikt een TopN Sort om het verzoek van de Top-operator te ondersteunen om het offset-ophaalfilter af te handelen. De reden voor de wijziging is dat het plan in figuur 1 een niet-geclusterde niet-dekkende index gebruikt, en hoe verder de pagina die u zoekt, hoe meer zoekacties nodig zijn. Met het tweede paginaverzoek overschreed je het omslagpunt dat het gebruik van de niet-dekkende index rechtvaardigt.
Hoewel de scan van de geclusterde index, die is gedefinieerd met orderid als sleutel, ongeordend is, gebruikt de opslagengine intern een indexorderscan. Dit heeft te maken met de grootte van de index. Tot 64 pagina's geeft de opslagengine over het algemeen de voorkeur aan scans van indexvolgorden boven scans van toewijzingsvolgorden. Zelfs als de index groter was, onder het read-commit-isolatieniveau en gegevens die niet zijn gemarkeerd als alleen-lezen, gebruikt de opslagengine een indexvolgordescan om dubbel lezen en het overslaan van rijen te voorkomen als gevolg van paginasplitsingen die optreden tijdens de scannen. Onder de gegeven omstandigheden, in de praktijk, tussen rijen met dezelfde datum, heeft dit plan toegang tot een rij met een lagere orderid voor een rij met een hogere orderid.
Deze query genereert de volgende uitvoer:
orderid orderdate custid ----------- ---------- ----------- 11069 2019-05-04 80 *** 11064 2019-05-01 71 11065 2019-05-01 46 11066 2019-05-01 89 11060 2019-04-30 27 11061 2019-04-30 32 11062 2019-04-30 66 11063 2019-04-30 37 11057 2019-04-29 53 11058 2019-04-29 6
Merk op dat, hoewel de onderliggende gegevens niet zijn gewijzigd, u uiteindelijk dezelfde bestelling (met bestel-ID 11069) terugkrijgt op zowel de eerste als de tweede pagina!
Hopelijk is de beste praktijk hier duidelijk. Voeg een tiebreaker toe aan je lijst met volgordes om een deterministische volgorde te krijgen. Sorteer bijvoorbeeld op orderdatum aflopend, orderid aflopend.
Probeer opnieuw om de eerste pagina te vragen, dit keer met een deterministische volgorde:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
U krijgt gegarandeerd de volgende output:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 11068 2019-05-04 62
Vraag naar de tweede pagina:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
U krijgt gegarandeerd de volgende output:
orderid orderdate custid ----------- ---------- ----------- 11067 2019-05-04 17 11066 2019-05-01 89 11065 2019-05-01 46 11064 2019-05-01 71 11063 2019-04-30 37 11062 2019-04-30 66 11061 2019-04-30 32 11060 2019-04-30 27 11059 2019-04-29 67 11058 2019-04-29 6
Zolang er geen wijzigingen zijn in de onderliggende gegevens, krijgt u gegarandeerd opeenvolgende pagina's zonder herhalingen of overslaan van rijen tussen de pagina's.
Op een vergelijkbare manier kunt u, door vensterfuncties zoals ROW_NUMBER met niet-deterministische volgorde te gebruiken, verschillende resultaten krijgen voor dezelfde query, afhankelijk van de vorm van het plan en de daadwerkelijke toegangsvolgorde tussen banden. Overweeg de volgende query (noem het Query 3), waarbij het verzoek om de eerste pagina wordt geïmplementeerd met behulp van rijnummers (waardoor het gebruik van de index op besteldatum voor illustratiedoeleinden wordt geforceerd):
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders WITH (INDEX(idx_nc_orderdate))
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10; Het plan voor deze zoekopdracht wordt weergegeven in Afbeelding 3:
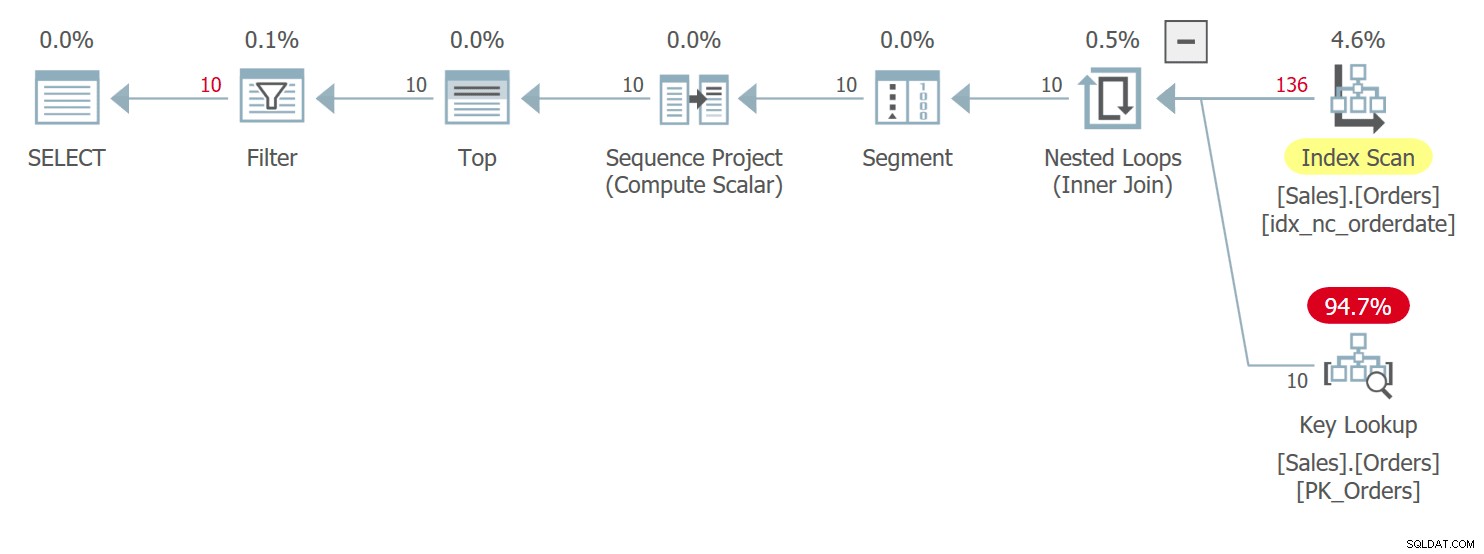
Figuur 3:Plan voor query 3
U heeft hier zeer vergelijkbare voorwaarden als die ik eerder heb beschreven voor Query 1 met zijn plan dat eerder in figuur 1 werd getoond. Tussen rijen met banden in de orderdatumwaarden, heeft dit plan toegang tot een rij met een hogere orderid-waarde vóór een met een lagere orderid waarde. Deze query genereert de volgende uitvoer:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 *** 11068 2019-05-04 62
Voer vervolgens de query opnieuw uit (noem het Query 4) en vraag de eerste pagina op, maar forceer deze keer het gebruik van de geclusterde index PK_Orders:
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders WITH (INDEX(PK_Orders))
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10; Het plan voor deze zoekopdracht wordt getoond in figuur 4.

Figuur 4:Plan voor query 4
Deze keer heb je zeer vergelijkbare voorwaarden als degene die ik eerder heb beschreven voor Query 2 met zijn plan dat eerder in figuur 2 werd getoond. Tussen rijen met banden in de orderdatumwaarden, heeft dit plan toegang tot een rij met een lagere orderid-waarde vóór een met een hogere orderid waarde. Deze query genereert de volgende uitvoer:
orderid orderdate custid ----------- ---------- ----------- 11074 2019-05-06 73 11075 2019-05-06 68 11076 2019-05-06 9 11077 2019-05-06 65 11070 2019-05-05 44 11071 2019-05-05 46 11072 2019-05-05 20 11073 2019-05-05 58 11067 2019-05-04 17 *** 11068 2019-05-04 62
Merk op dat de twee uitvoeringen verschillende resultaten opleverden, ook al veranderde er niets in de onderliggende gegevens.
Nogmaals, de beste werkwijze hier is eenvoudig:gebruik deterministische volgorde door een tiebreak toe te voegen, zoals:
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n
FROM Sales.Orders
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10; Deze query genereert de volgende uitvoer:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 11068 2019-05-04 62
De geretourneerde set is gegarandeerd herhaalbaar, ongeacht de vorm van het plan.
Het is waarschijnlijk de moeite waard om te vermelden dat, aangezien deze query geen presentatievolgorde per clausule in de buitenste query heeft, er hier geen gegarandeerde presentatievolgorde is. Als je zo'n garantie nodig hebt, moet je een aanbiedingsvolgorde per clausule toevoegen, zoals:
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n
FROM Sales.Orders
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10
ORDER BY n; Niet-deterministische functies
Een niet-deterministische functie is een functie die, gegeven dezelfde invoer, verschillende resultaten kan retourneren in verschillende uitvoeringen van de functie. Klassieke voorbeelden zijn SYSDATETIME, NEWID en RAND (indien aangeroepen zonder invoer seed). Het gedrag van niet-deterministische functies in T-SQL kan voor sommigen verrassend zijn en kan in sommige gevallen leiden tot bugs en valkuilen.
Veel mensen gaan ervan uit dat wanneer u een niet-deterministische functie aanroept als onderdeel van een query, de functie afzonderlijk per rij wordt geëvalueerd. In de praktijk worden de meeste niet-deterministische functies eenmaal per referentie in de query geëvalueerd. Beschouw de volgende vraag als voorbeeld:
SELECT orderid, SYSDATETIME() AS dt, RAND() AS rnd FROM Sales.Orders;
Aangezien er slechts één verwijzing is naar elk van de niet-deterministische functies SYSDATETIME en RAND in de query, wordt elk van deze functies slechts één keer geëvalueerd en wordt het resultaat herhaald over alle resultaatrijen. Ik kreeg de volgende uitvoer bij het uitvoeren van deze query:
orderid dt rnd ----------- --------------------------- ---------------------- 11008 2019-02-04 17:03:07.9229177 0.962042872007464 11019 2019-02-04 17:03:07.9229177 0.962042872007464 11039 2019-02-04 17:03:07.9229177 0.962042872007464 11040 2019-02-04 17:03:07.9229177 0.962042872007464 11045 2019-02-04 17:03:07.9229177 0.962042872007464 11051 2019-02-04 17:03:07.9229177 0.962042872007464 11054 2019-02-04 17:03:07.9229177 0.962042872007464 11058 2019-02-04 17:03:07.9229177 0.962042872007464 11059 2019-02-04 17:03:07.9229177 0.962042872007464 11061 2019-02-04 17:03:07.9229177 0.962042872007464 ...
Als voorbeeld waarbij het niet begrijpen van dit gedrag kan resulteren in een bug, stel dat u een query moet schrijven die drie willekeurige bestellingen uit de tabel Sales.Orders retourneert. Een gebruikelijke eerste poging is om een TOP-query te gebruiken met een volgorde op basis van de RAND-functie, in de veronderstelling dat de functie afzonderlijk per rij zou worden geëvalueerd, zoals:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY RAND();
In de praktijk wordt de functie slechts één keer geëvalueerd voor de hele query; daarom krijgen alle rijen hetzelfde resultaat en wordt de volgorde niet beïnvloed. Als u het plan voor deze zoekopdracht controleert, ziet u zelfs geen sorteeroperator. Toen ik deze zoekopdracht meerdere keren uitvoerde, kreeg ik steeds hetzelfde resultaat:
orderid ----------- 11008 11019 11039
De query is eigenlijk gelijk aan een query zonder een ORDER BY-clausule, waarbij de volgorde van de presentatie niet is gegarandeerd. Dus technisch gezien is de volgorde niet-deterministisch, en theoretisch verschillende uitvoeringen kunnen resulteren in een andere volgorde, en dus in een andere selectie van de bovenste 3 rijen. De kans hierop is echter klein en u kunt deze oplossing niet beschouwen als het produceren van drie willekeurige rijen in elke uitvoering.
Een uitzondering op de regel dat een niet-deterministische functie eenmaal per verwijzing in de query wordt aangeroepen, is de functie NEWID, die een GUID (Globally Unique Identifier) retourneert. Bij gebruik in een zoekopdracht is deze functie is afzonderlijk per rij aangeroepen. De volgende zoekopdracht toont dit aan:
SELECT orderid, NEWID() AS mynewid FROM Sales.Orders;
Deze query genereerde de volgende uitvoer:
orderid mynewid ----------- ------------------------------------ 11008 D6417542-C78A-4A2D-9517-7BB0FCF3B932 11019 E2E46BF1-4FA6-4EF2-8328-18B86259AD5D 11039 2917D923-AC60-44F5-92D7-FF84E52250CC 11040 B6287B49-DAE7-4C6C-98A8-7DB8A879581C 11045 2E14D8F7-21E5-4039-BF7E-0A27D1A0E186 11051 FA0B7B3E-BA41-4D80-8581-782EB88836C0 11054 1E6146BB-FEE7-4FF4-A4A2-3243AA2CBF78 11058 49302EA9-0243-4502-B9D2-46D751E6EFA9 11059 F5BB7CB2-3B17-4D01-ABD2-04F3C5115FCF 11061 09E406CA-0251-423B-8DF5-564E1257F93E ...
De waarde van NEWID zelf is vrij willekeurig. Als je de functie CHECKSUM er bovenop toepast, krijg je een geheel getal met een nog betere willekeurige verdeling. Dus een manier om drie willekeurige bestellingen te krijgen, is door een TOP-query te gebruiken met volgorde op basis van CHECKSUM(NEWID()), zoals:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY CHECKSUM(NEWID());
Voer deze query herhaaldelijk uit en merk op dat u elke keer een andere set van drie willekeurige bestellingen krijgt. Ik kreeg de volgende uitvoer in één uitvoering:
orderid ----------- 11031 10330 10962
En de volgende uitvoer in een andere uitvoering:
orderid ----------- 10308 10885 10444
Behalve NEWID, wat als u een niet-deterministische functie zoals SYSDATETIME in een query moet gebruiken, en u wilt dat deze afzonderlijk per rij wordt geëvalueerd? Een manier om dit te bereiken is door een door de gebruiker gedefinieerde functie (UDF) te gebruiken die de niet-deterministische functie aanroept, zoals:
CREATE OR ALTER FUNCTION dbo.MySysDateTime() RETURNS DATETIME2
AS
BEGIN
RETURN SYSDATETIME();
END;
GO Je roept dan de UDF aan in de query als volgt (noem het Query 5):
SELECT orderid, dbo.MySysDateTime() AS mydt FROM Sales.Orders;
De UDF wordt deze keer wel per rij uitgevoerd. U moet er echter rekening mee houden dat er een behoorlijk scherpe prestatiestraf is verbonden aan de uitvoering per rij van de UDF. Bovendien is het aanroepen van een scalaire T-SQL UDF een parallellisme-remmer.
Het plan voor deze zoekopdracht wordt getoond in figuur 5.
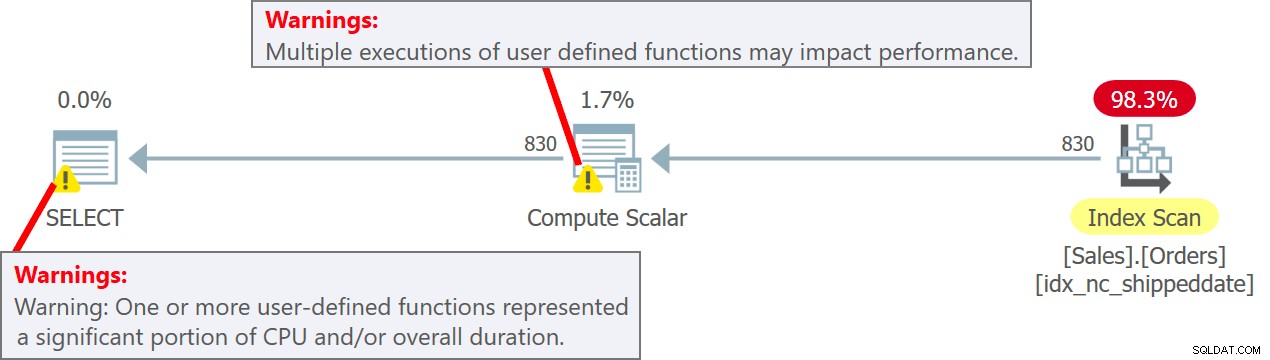
Figuur 5:Plan voor query 5
Merk in het plan op dat de UDF inderdaad wordt aangeroepen per bronrij in de Compute Scalar-operator. Merk ook op dat SentryOne Plan Explorer u waarschuwt voor de mogelijke prestatievermindering die gepaard gaat met het gebruik van de UDF, zowel in de Compute Scalar-operator als in het hoofdknooppunt van het plan.
Ik kreeg de volgende uitvoer van de uitvoering van deze query:
orderid mydt ----------- --------------------------- 11008 2019-02-04 17:07:03.7221339 11019 2019-02-04 17:07:03.7221339 11039 2019-02-04 17:07:03.7221339 ... 10251 2019-02-04 17:07:03.7231315 10255 2019-02-04 17:07:03.7231315 10248 2019-02-04 17:07:03.7231315 ... 10416 2019-02-04 17:07:03.7241304 10420 2019-02-04 17:07:03.7241304 10421 2019-02-04 17:07:03.7241304 ...
Merk op dat de uitvoerrijen meerdere verschillende datum- en tijdwaarden hebben in de mydt-kolom.
U hebt misschien gehoord dat SQL Server 2019 het veelvoorkomende prestatieprobleem verhelpt dat wordt veroorzaakt door scalaire T-SQL UDF's door dergelijke functies in te lijnen. De UDF moet echter aan een lijst met vereisten voldoen om inlineable te zijn. Een van de vereisten is dat de UDF geen niet-deterministische intrinsieke functie zoals SYSDATETIME aanroept. De redenering voor deze vereiste is dat u de UDF misschien precies hebt gemaakt om een uitvoering per rij te krijgen. Als de UDF inline zou worden, zou de onderliggende niet-deterministische functie slechts één keer worden uitgevoerd voor de hele query. In feite is het plan in afbeelding 5 gegenereerd in SQL Server 2019 en je kunt duidelijk zien dat de UDF niet inline is geworden. Dat komt door het gebruik van de niet-deterministische functie SYSDATETIME. U kunt controleren of een UDF inlineable is in SQL Server 2019 door het kenmerk is_inlineable in de weergave sys.sql_modules op te vragen, zoals:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id = OBJECT_ID(N'dbo.MySysDateTime');
Deze code genereert de volgende uitvoer die u vertelt dat de UDF MySysDateTime niet inlineeerbaar is:
is_inlineable ------------- 0
Om een UDF te demonstreren die inlineable is, volgt hier de definitie van een UDF genaamd EndOfyear die een invoerdatum accepteert en de respectieve eindejaarsdatum retourneert:
CREATE OR ALTER FUNCTION dbo.EndOfYear(@dt AS DATE) RETURNS DATE
AS
BEGIN
RETURN DATEADD(year, DATEDIFF(year, '18991231', @dt), '18991231');
END;
GO Er wordt hier geen gebruik gemaakt van niet-deterministische functies en de code voldoet ook aan de andere vereisten voor inlining. U kunt controleren of de UDF inlineable is door de volgende code te gebruiken:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id = OBJECT_ID(N'dbo.EndOfYear');
Deze code genereert de volgende uitvoer:
is_inlineable ------------- 1
De volgende query (noem het Query 6) gebruikt de UDF EndOfYear om bestellingen te filteren die op een eindejaarsdatum zijn geplaatst:
SELECT orderid FROM Sales.Orders WHERE orderdate = dbo.EndOfYear(orderdate);
Het plan voor deze query wordt getoond in figuur 6.
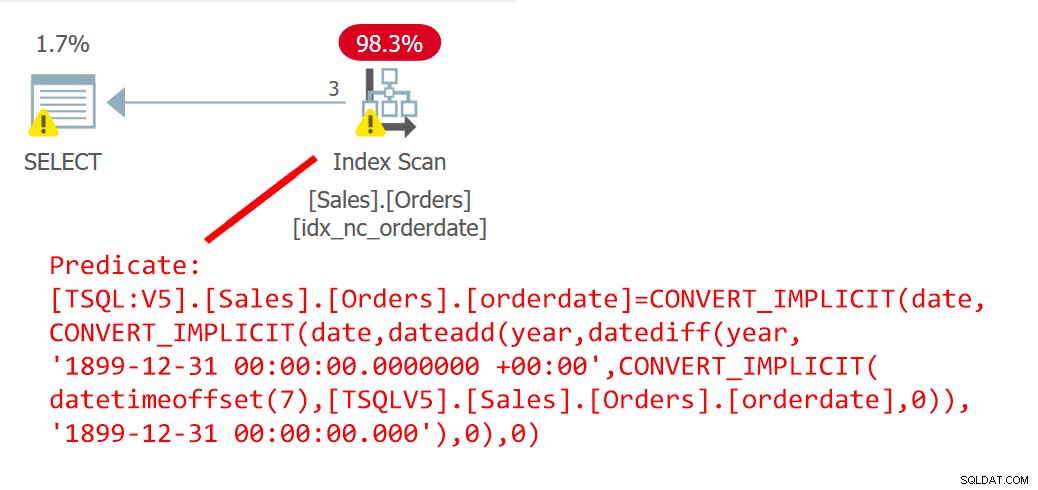
Figuur 6:Plan voor query 6
Het plan laat duidelijk zien dat de UDF inline is geraakt.
Tabeluitdrukkingen, niet-determinisme en meerdere verwijzingen
Zoals vermeld, worden niet-deterministische functies zoals SYSDATETIME eenmaal per referentie in een query aangeroepen. Maar wat als u een keer naar een dergelijke functie verwijst in een query in een tabelexpressie zoals een CTE, en vervolgens een buitenste query hebt met meerdere verwijzingen naar de CTE? Veel mensen realiseren zich niet dat elke verwijzing naar de tabeluitdrukking afzonderlijk wordt uitgebreid en dat de inline-code resulteert in meerdere verwijzingen naar de onderliggende niet-deterministische functie. Met een functie als SYSDATETIME, afhankelijk van de exacte timing van elk van de uitvoeringen, zou je uiteindelijk voor elk een ander resultaat kunnen krijgen. Sommige mensen vinden dit gedrag verrassend.
Dit kan worden geïllustreerd met de volgende code:
DECLARE @i AS INT = 1, @rc AS INT = NULL;
WHILE 1 = 1
BEGIN;
WITH C1 AS
(
SELECT SYSDATETIME() AS dt
),
C2 AS
(
SELECT dt FROM C1
UNION
SELECT dt FROM C1
)
SELECT @rc = COUNT(*) FROM C2;
IF @rc > 1 BREAK;
SET @i += 1;
END;
SELECT @rc AS distinctvalues, @i AS iterations; Als beide verwijzingen naar C1 in de query in C2 hetzelfde voorstelden, zou deze code in een oneindige lus hebben geresulteerd. Omdat de twee verwijzingen echter afzonderlijk worden uitgebreid, wanneer de timing zodanig is dat elke aanroep plaatsvindt in een ander interval van 100 nanoseconden (de precisie van de resultaatwaarde), resulteert de unie in twee rijen en moet de code breken met de lus. Voer deze code uit en ontdek het zelf. Inderdaad, na enkele iteraties breekt het. Ik kreeg het volgende resultaat in een van de executies:
distinctvalues iterations -------------- ----------- 2 448
Het beste is om het gebruik van tabelexpressies zoals CTE's en views te vermijden, wanneer de inner query niet-deterministische berekeningen gebruikt en de outer query meerdere keren naar de tabelexpressie verwijst. Dat is natuurlijk tenzij je de implicaties begrijpt en je het goed vindt. Alternatieve opties kunnen zijn om het resultaat van de innerlijke query te behouden, bijvoorbeeld in een tijdelijke tabel, en vervolgens de tijdelijke tabel zo vaak als nodig is te doorzoeken.
Om voorbeelden te demonstreren waarbij het niet volgen van de beste werkwijze u in de problemen kan brengen, stelt u zich voor dat u een query moet schrijven die werknemers willekeurig uit de tabel HR.Employees koppelt. Je bedenkt de volgende vraag (noem het vraag 7) om de taak uit te voeren:
WITH C AS
(
SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n
FROM HR.Employees
)
SELECT
C1.empid AS empid1, C1.firstname AS firstname1, C1.lastname AS lastname1,
C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2
FROM C AS C1
INNER JOIN C AS C2
ON C1.n = C2.n + 1; Het plan voor deze query wordt getoond in figuur 7.
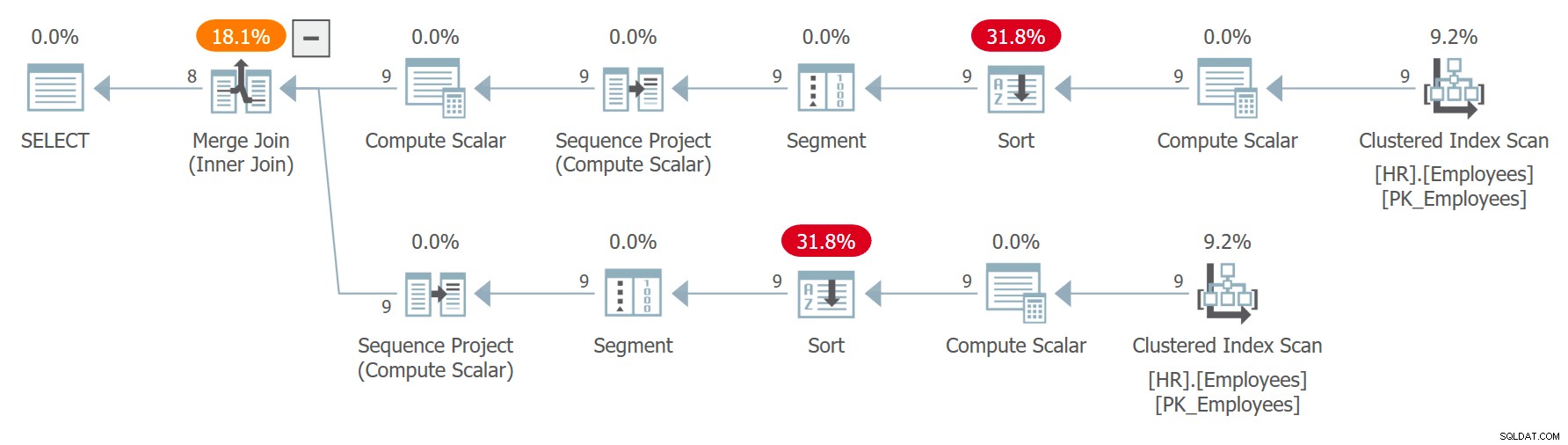
Figuur 7:Plan voor Query 7
Merk op dat de twee verwijzingen naar C afzonderlijk worden uitgebreid en dat de rijnummers onafhankelijk worden berekend voor elke verwijzing, geordend door onafhankelijke aanroepen van de expressie CHECKSUM(NEWID()). Dit betekent dat dezelfde werknemer niet gegarandeerd hetzelfde rijnummer krijgt in de twee uitgebreide verwijzingen. Als een medewerker rijnummer x in C1 en rijnummer x – 1 in C2 krijgt, zal de zoekopdracht de medewerker aan zichzelf koppelen. Ik kreeg bijvoorbeeld het volgende resultaat in een van de executies:
empid1 firstname1 lastname1 empid2 firstname2 lastname2 ----------- ---------- -------------------- ----------- ---------- -------------------- 3 Judy Lew 6 Paul Suurs 9 Patricia Doyle *** 9 Patricia Doyle *** 5 Sven Mortensen 4 Yael Peled 6 Paul Suurs 8 Maria Cameron 8 Maria Cameron 5 Sven Mortensen 2 Don Funk *** 2 Don Funk *** 4 Yael Peled 3 Judy Lew 7 Russell King *** 7 Russell King ***
Merk op dat er hier drie gevallen van zelfparen zijn. Dit is gemakkelijker te zien door een filter toe te voegen aan de buitenste zoekopdracht die specifiek naar zelfparen zoekt, zoals:
WITH C AS
(
SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n
FROM HR.Employees
)
SELECT
C1.empid AS empid1, C1.firstname AS firstname1, C1.lastname AS lastname1,
C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2
FROM C AS C1
INNER JOIN C AS C2
ON C1.n = C2.n + 1
WHERE C1.empid = C2.empid; Mogelijk moet u deze query een aantal keren uitvoeren om het probleem te zien. Hier is een voorbeeld van het resultaat dat ik kreeg in een van de executies:
empid1 firstname1 lastname1 empid2 firstname2 lastname2 ----------- ---------- -------------------- ----------- ---------- -------------------- 5 Sven Mortensen 5 Sven Mortensen 2 Don Funk 2 Don Funk
Volgens de best practice is een manier om dit probleem op te lossen, het resultaat van de interne query in een tijdelijke tabel te bewaren en vervolgens indien nodig meerdere exemplaren van de tijdelijke tabel op te vragen.
Een ander voorbeeld illustreert bugs die het gevolg kunnen zijn van het gebruik van niet-deterministische volgorde en meerdere verwijzingen naar een tabeluitdrukking. Stel dat u de tabel Sales.Orders moet doorzoeken en om trendanalyses uit te voeren, wilt u elke bestelling koppelen aan de volgende op basis van de besteldatum. Uw oplossing moet compatibel zijn met pre-SQL Server 2012-systemen, wat betekent dat u de voor de hand liggende LAG/LEAD-functies niet kunt gebruiken. U besluit een CTE te gebruiken die rijnummers berekent om rijen te positioneren op basis van volgorde van orderdatum, en vervolgens twee instanties van de CTE samen te voegen, waarbij orders worden gekoppeld op basis van een offset van 1 tussen de rijnummers, zoals zo (noem deze Query 8):
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders
)
SELECT
C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1,
C2.orderid AS orderid2, C2.orderdate AS orderdate2
FROM C AS C1
LEFT OUTER JOIN C AS C2
ON C1.n = C2.n + 1; Het plan voor deze zoekopdracht wordt getoond in figuur 8.
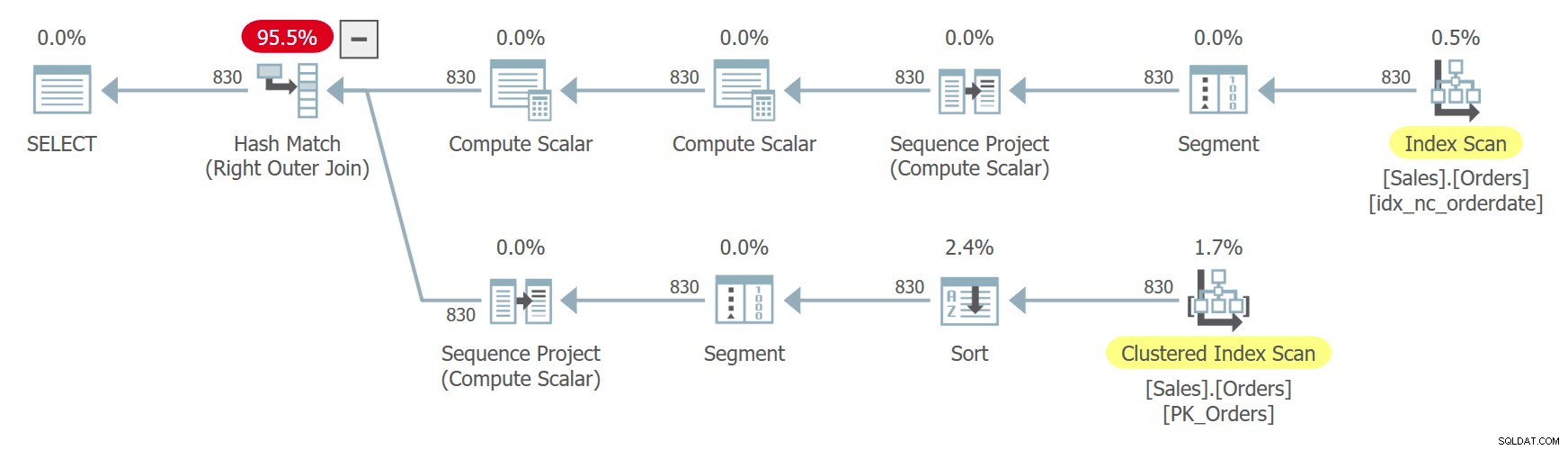 Figuur 8:Plan voor Query 8
Figuur 8:Plan voor Query 8
De volgorde van het rijnummer is niet bepalend, aangezien de besteldatum niet uniek is. Merk op dat de twee verwijzingen naar de CTE afzonderlijk worden uitgebreid. Vreemd genoeg, aangezien de query zoekt naar een andere subset van kolommen van elk van de instanties, besluit de optimizer om in elk geval een andere index te gebruiken. In één geval gebruikt het een geordende achterwaartse scan van de index op orderdatum, waardoor effectief rijen met dezelfde datum worden gescand op basis van orderid aflopende volgorde. In het andere geval scant het de geclusterde index, geordend op onwaar en sorteert het, maar effectief tussen rijen met dezelfde datum, benadert het de rijen in oplopende volgorde. Dat komt door een soortgelijke redenering die ik eerder in het gedeelte over niet-deterministische volgorde heb gegeven. Dit kan ertoe leiden dat dezelfde rij rijnummer x krijgt in het ene geval en rijnummer x – 1 in het andere geval. In zo'n geval zal de join uiteindelijk een bestelling met zichzelf matchen in plaats van met de volgende zoals het hoort.
Ik kreeg het volgende resultaat bij het uitvoeren van deze query:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ----------- ---------- 11074 2019-05-06 73 NULL NULL 11075 2019-05-06 68 11077 2019-05-06 11076 2019-05-06 9 11076 2019-05-06 *** 11077 2019-05-06 65 11075 2019-05-06 11070 2019-05-05 44 11074 2019-05-06 11071 2019-05-05 46 11073 2019-05-05 11072 2019-05-05 20 11072 2019-05-05 *** ...
Let op de zelf-matches in het resultaat. Nogmaals, het probleem kan gemakkelijker worden geïdentificeerd door een filter toe te voegen dat op zoek is naar zelf-overeenkomsten, zoals:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders
)
SELECT
C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1,
C2.orderid AS orderid2, C2.orderdate AS orderdate2
FROM C AS C1
LEFT OUTER JOIN C AS C2
ON C1.n = C2.n + 1
WHERE C1.orderid = C2.orderid; Ik kreeg de volgende output van deze vraag:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ----------- ---------- 11076 2019-05-06 9 11076 2019-05-06 11072 2019-05-05 20 11072 2019-05-05 11062 2019-04-30 66 11062 2019-04-30 11052 2019-04-27 34 11052 2019-04-27 11042 2019-04-22 15 11042 2019-04-22 ...
De beste werkwijze hier is om ervoor te zorgen dat u een unieke volgorde gebruikt om determinisme te garanderen door een tiebreaker zoals orderid toe te voegen aan de venstervolgorde-clausule. Dus ook al heb je meerdere verwijzingen naar dezelfde CTE, de rijnummers zullen in beide hetzelfde zijn. Als u herhaling van de berekeningen wilt vermijden, kunt u ook overwegen om het resultaat van de interne zoekopdracht te behouden, maar dan moet u wel rekening houden met de extra kosten van dergelijk werk.
CASE/NULLIF en niet-deterministische functies
Wanneer u meerdere verwijzingen naar een niet-deterministische functie in een query hebt, wordt elke verwijzing afzonderlijk geëvalueerd. Wat verrassend kan zijn en zelfs tot bugs kan leiden, is dat je soms één referentie schrijft, maar impliciet wordt deze omgezet in meerdere referenties. Such is the situation with some uses of the CASE expression and IIF function.
Consider the following example:
SELECT CASE ABS(CHECKSUM(NEWID())) % 2 WHEN 0 THEN 'Even' WHEN 1 THEN 'Odd' END;
Here the outcome of the tested expression is a nonnegative integer value, so clearly it has to be either even or odd. It cannot be neither even nor odd. However, if you run this code enough times, you will sometimes get a NULL indicating that the implied ELSE NULL clause of the CASE expression was activated. The reason for this is that the above expression translates to the following:
SELECT
CASE
WHEN ABS(CHECKSUM(NEWID())) % 2 = 0 THEN 'Even'
WHEN ABS(CHECKSUM(NEWID())) % 2 = 1 THEN 'Odd'
ELSE NULL
END; In the converted expression there are two separate references to the tested expression that generates a random nonnegative value, and each gets evaluated separately. One possible path is that the first evaluation produces an odd number, the second produces an even number, and then the ELSE NULL clause is activated.
Here’s a very similar situation with the NULLIF function:
SELECT NULLIF(ABS(CHECKSUM(NEWID())) % 2, 0);
This expression generates a random nonnegative value, and is supposed to return 1 when it’s odd, and NULL otherwise. It’s never supposed to return 0 since in such a case the 0 is supposed to be replaced with a NULL. Run it a few times and you will see that in some cases you get a 0. The reason for this is that the above expression internally translates to the following one:
SELECT
CASE
WHEN ABS(CHECKSUM(NEWID())) % 2 = 0 THEN NULL
ELSE ABS(CHECKSUM(NEWID())) % 2
END; A possible path is that the first WHEN clause generates a random odd value, so the ELSE clause is activated, and the ELSE clause generates a random even value so the % 2 calculation results in a 0.
In both cases this behavior is standard, so the bug is more in the eyes of the beholder based on your expectations and your choice of how to write the code. The best practice in both cases is to persist the result of the original calculation and then interact with the persisted result. If it’s a single value, store the result in a variable first. If you’re querying tables, first persist the result of the nondeterministic calculation in a column in a temporary table, and then apply the CASE/IIF logic in the query against the temporary table.
Conclusie
This article is the first in a series about T-SQL bugs, pitfalls and best practices, and is the result of discussions with fellow Microsoft Data Platform MVPs who shared their experiences. This time I focused on bugs and pitfalls that resulted from using nondeterministic order and nondeterministic calculations. In future articles I’ll continue with other themes. If you have bugs and pitfalls that you often stumble into, or that you find as particularly interesting, please do share!