In deel 1 van deze serie heb je Flask en Connexion gebruikt om een REST API te maken die CRUD-bewerkingen levert aan een eenvoudige in-memory structuur genaamd PEOPLE . Dat werkte om te demonstreren hoe de Connexion-module je helpt bij het bouwen van een mooie REST API samen met interactieve documentatie.
Zoals sommigen opmerkten in de opmerkingen voor deel 1, de PEOPLE structuur wordt elke keer dat de toepassing opnieuw wordt gestart opnieuw geïnitialiseerd. In dit artikel leer je hoe je de PEOPLE . opslaat structuur, en de acties die de API biedt, aan een database met behulp van SQLAlchemy en Marshmallow.
SQLAlchemy biedt een Object Relational Model (ORM), dat Python-objecten opslaat in een databaserepresentatie van de gegevens van het object. Dat kan je helpen om op een Pythonische manier te blijven denken en je niet bezig te houden met hoe de objectgegevens in een database worden weergegeven.
Marshmallow biedt functionaliteit om Python-objecten te serialiseren en te deserialiseren terwijl ze uit en in onze op JSON gebaseerde REST API stromen. Marshmallow converteert instanties van Python-klassen naar objecten die kunnen worden geconverteerd naar JSON.
Je kunt de Python-code voor dit artikel hier vinden.
Gratis bonus: Klik hier om een exemplaar van de gids "REST API-voorbeelden" te downloaden en een praktische introductie te krijgen tot Python + REST API-principes met bruikbare voorbeelden.
Voor wie is dit artikel bedoeld
Als je deel 1 van deze serie leuk vond, breidt dit artikel je gereedschapsriem nog verder uit. Je zult SQLAlchemy gebruiken om toegang te krijgen tot een database op een meer Pythonische manier dan gewone SQL. Je gebruikt Marshmallow ook om de gegevens die worden beheerd door de REST API te serialiseren en deserialiseren. Om dit te doen, maak je gebruik van de basisfuncties van Object Oriented Programming die beschikbaar zijn in Python.
Je zult SQLAlchemy ook gebruiken om een database te maken en ermee te werken. Dit is nodig om de REST API in gebruik te nemen met de PEOPLE gegevens gebruikt in deel 1.
De webtoepassing die in deel 1 wordt gepresenteerd, zal zijn HTML- en JavaScript-bestanden op kleine manieren hebben gewijzigd om de wijzigingen ook te ondersteunen. Je kunt de definitieve versie van de code uit deel 1 hier bekijken.
Aanvullende afhankelijkheden
Voordat u aan de slag gaat met het bouwen van deze nieuwe functionaliteit, moet u de virtualenv die u hebt gemaakt bijwerken om de Deel 1-code uit te voeren, of een nieuwe maken voor dit project. De eenvoudigste manier om dat te doen nadat u uw virtualenv hebt geactiveerd, is door deze opdracht uit te voeren:
$ pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
Dit voegt meer functionaliteit toe aan uw virtualenv:
-
Flask-SQLAlchemyvoegt SQLAlchemy toe, samen met enkele koppelingen aan Flask, waardoor programma's toegang krijgen tot databases. -
flask-marshmallowvoegt de Flask-onderdelen van Marshmallow toe, waarmee programma's Python-objecten van en naar serialiseerbare structuren kunnen converteren. -
marshmallow-sqlalchemyvoegt enkele Marshmallow-haken toe aan SQLAlchemy zodat programma's Python-objecten kunnen serialiseren en deserialiseren die zijn gegenereerd door SQLAlchemy. -
marshmallowvoegt het grootste deel van de Marshmallow-functionaliteit toe.
Persoonsgegevens
Zoals hierboven vermeld, de PEOPLE datastructuur in het vorige artikel is een in-memory Python-woordenboek. In dat woordenboek gebruikte je de achternaam van de persoon als opzoeksleutel. De datastructuur zag er in de code als volgt uit:
# Data to serve with our API
PEOPLE = {
"Farrell": {
"fname": "Doug",
"lname": "Farrell",
"timestamp": get_timestamp()
},
"Brockman": {
"fname": "Kent",
"lname": "Brockman",
"timestamp": get_timestamp()
},
"Easter": {
"fname": "Bunny",
"lname": "Easter",
"timestamp": get_timestamp()
}
}
De wijzigingen die u in het programma aanbrengt, verplaatsen alle gegevens naar een databasetabel. Dit betekent dat de gegevens op uw schijf worden opgeslagen en tussen runs van de server.py . zullen bestaan programma.
Omdat de achternaam de woordenboeksleutel was, beperkte de code het wijzigen van de achternaam van een persoon:alleen de voornaam kon worden gewijzigd. Als u naar een database gaat, kunt u bovendien de achternaam wijzigen, omdat deze niet langer wordt gebruikt als zoeksleutel voor een persoon.
Conceptueel kan een databasetabel worden gezien als een tweedimensionale array waarbij de rijen records zijn en de kolommen velden in die records.
Databasetabellen hebben meestal een automatisch oplopende integerwaarde als opzoeksleutel voor rijen. Dit wordt de primaire sleutel genoemd. Elke record in de tabel heeft een primaire sleutel waarvan de waarde uniek is in de hele tabel. Als u een primaire sleutel heeft die onafhankelijk is van de gegevens die in de tabel zijn opgeslagen, kunt u elk ander veld in de rij wijzigen.
Opmerking:
De automatisch oplopende primaire sleutel betekent dat de database zorgt voor:
- Het grootste bestaande primaire-sleutelveld verhogen telkens wanneer een nieuw record in de tabel wordt ingevoegd
- Die waarde gebruiken als de primaire sleutel voor de nieuw ingevoegde gegevens
Dit garandeert een unieke primaire sleutel naarmate de tabel groeit.
Je gaat een database-conventie volgen om de tabel als enkelvoud te benoemen, dus de tabel zal person heten . Onze PEOPLE vertalen structuur hierboven in een databasetabel met de naam person geeft je dit:
| person_id | naam | fname | tijdstempel |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Pasen | Konijn | 2018-08-08 21:16:01.886834 |
Elke kolom in de tabel heeft de volgende veldnaam:
person_id: primair sleutelveld voor elke persoonlname: achternaam van de persoonfname: voornaam van de persoontimestamp: tijdstempel gekoppeld aan acties voor invoegen/bijwerken
Database-interactie
Je gaat SQLite gebruiken als de database-engine om de PEOPLE . op te slaan gegevens. SQLite is de meest wijdverbreide database ter wereld en wordt gratis geleverd met Python. Het is snel, voert al zijn werk uit met behulp van bestanden en is geschikt voor een groot aantal projecten. Het is een compleet RDBMS (Relationeel Database Management Systeem) dat SQL bevat, de taal van veel databasesystemen.
Stel je voor het moment de person voor tabel bestaat al in een SQLite-database. Als u enige ervaring heeft met RDBMS, kent u waarschijnlijk SQL, de Structured Query Language die de meeste RDBMS'en gebruiken voor interactie met de database.
In tegenstelling tot programmeertalen zoals Python, definieert SQL niet hoe om de gegevens te krijgen:het beschrijft wat gegevens zijn gewenst, waarbij de hoe tot aan de database-engine.
Een SQL-query die alle gegevens in onze person . ophaalt tabel, gesorteerd op achternaam, ziet er als volgt uit:
SELECT * FROM person ORDER BY 'lname';
Deze query vertelt de database-engine om alle velden uit de persoonstabel te halen en ze in de standaard, oplopende volgorde te sorteren met behulp van de lname veld.
Als u deze query zou uitvoeren op een SQLite-database met de person tabel, zouden de resultaten een reeks records zijn die alle rijen in de tabel bevatten, waarbij elke rij de gegevens bevat van alle velden die een rij vormen. Hieronder ziet u een voorbeeld van het gebruik van de SQLite-opdrachtregeltool die de bovenstaande query uitvoert op de person databasetabel:
sqlite> SELECT * FROM person ORDER BY lname;
2|Brockman|Kent|2018-08-08 21:16:01.888444
3|Easter|Bunny|2018-08-08 21:16:01.889060
1|Farrell|Doug|2018-08-08 21:16:01.886834
De uitvoer hierboven is een lijst van alle rijen in de person databasetabel met pipe-tekens ('|') die de velden in de rij scheiden, wat wordt gedaan voor weergavedoeleinden door SQLite.
Python is volledig in staat om met veel database-engines te communiceren en de bovenstaande SQL-query uit te voeren. De resultaten zouden hoogstwaarschijnlijk een lijst met tuples zijn. De buitenste lijst bevat alle records in de person tafel. Elke individuele innerlijke tupel zou alle gegevens bevatten die elk veld vertegenwoordigen dat is gedefinieerd voor een tabelrij.
Het op deze manier verkrijgen van gegevens is niet erg Pythonisch. De lijst met records is oké, maar elk afzonderlijk record is slechts een tupel met gegevens. Het is aan het programma om de index van elk veld te kennen om een bepaald veld op te halen. De volgende Python-code gebruikt SQLite om te demonstreren hoe de bovenstaande query moet worden uitgevoerd en hoe de gegevens moeten worden weergegeven:
1import sqlite3
2
3conn = sqlite3.connect('people.db')
4cur = conn.cursor()
5cur.execute('SELECT * FROM person ORDER BY lname')
6people = cur.fetchall()
7for person in people:
8 print(f'{person[2]} {person[1]}')
Het bovenstaande programma doet het volgende:
-
Lijn 1 importeert de
sqlite3module. -
Lijn 3 maakt een verbinding met het databasebestand.
-
Lijn 4 maakt een cursor van de verbinding.
-
Lijn 5 gebruikt de cursor om een
SQL. uit te voeren zoekopdracht uitgedrukt als een tekenreeks. -
Lijn 6 krijgt alle records geretourneerd door de
SQLquery en wijst ze toe aan depeoplevariabel. -
Lijn 7 en 8 herhaal de
peoplelijstvariabele en print de voor- en achternaam van elke persoon.
De people variabele uit Regel 6 hierboven zou er zo uitzien in Python:
people = [
(2, 'Brockman', 'Kent', '2018-08-08 21:16:01.888444'),
(3, 'Easter', 'Bunny', '2018-08-08 21:16:01.889060'),
(1, 'Farrell', 'Doug', '2018-08-08 21:16:01.886834')
]
De uitvoer van het bovenstaande programma ziet er als volgt uit:
Kent Brockman
Bunny Easter
Doug Farrell
In het bovenstaande programma moet je weten dat de voornaam van een persoon op index 2 . staat , en de achternaam van een persoon staat op index 1 . Erger nog, de interne structuur van person moet ook bekend zijn wanneer u de iteratievariabele person doorgeeft als parameter voor een functie of methode.
Het zou veel beter zijn als wat je terugkreeg voor person was een Python-object, waarbij elk van de velden een attribuut van het object is. Dit is een van de dingen die SQLAlchemy doet.
Kleine Bobby-tafels
In het bovenstaande programma is de SQL-instructie een eenvoudige tekenreeks die rechtstreeks aan de database wordt doorgegeven om uit te voeren. In dit geval is dat geen probleem omdat de SQL een letterlijke tekenreeks is die volledig onder controle van het programma staat. De use case voor uw REST API neemt echter gebruikersinvoer van de webtoepassing en gebruikt deze om SQL-query's te maken. Dit kan uw toepassing openen voor aanvallen.
U herinnert zich uit deel 1 dat de REST API een enkele person van de PEOPLE gegevens zagen er als volgt uit:
GET /api/people/{lname}
Dit betekent dat uw API een variabele verwacht, lname , in het URL-eindpuntpad, dat wordt gebruikt om een enkele person te vinden . Het wijzigen van de Python SQLite-code van bovenaf om dit te doen zou er ongeveer zo uitzien:
1lname = 'Farrell'
2cur.execute('SELECT * FROM person WHERE lname = \'{}\''.format(lname))
Het bovenstaande codefragment doet het volgende:
-
Lijn 1 stelt de
lnamein variabele naar'Farrell'. Dit zou afkomstig zijn van het REST API URL-eindpuntpad. -
Lijn 2 gebruikt Python-tekenreeksopmaak om een SQL-tekenreeks te maken en uit te voeren.
Om het simpel te houden, stelt de bovenstaande code de lname . in variabele naar een constante, maar in werkelijkheid zou het afkomstig zijn van het API-URL-eindpuntpad en alles kunnen zijn dat door de gebruiker wordt geleverd. De SQL gegenereerd door de tekenreeksopmaak ziet er als volgt uit:
SELECT * FROM person WHERE lname = 'Farrell'
Wanneer deze SQL wordt uitgevoerd door de database, doorzoekt het de person tabel voor een record waarbij de achternaam gelijk is aan 'Farrell' . Dit is de bedoeling, maar elk programma dat gebruikersinvoer accepteert, staat ook open voor kwaadwillende gebruikers. In het programma hierboven, waar de lname variabele wordt ingesteld door door de gebruiker geleverde invoer, dit opent uw programma voor wat een SQL-injectie-aanval wordt genoemd. Dit is wat liefkozend bekend staat als Little Bobby Tables:
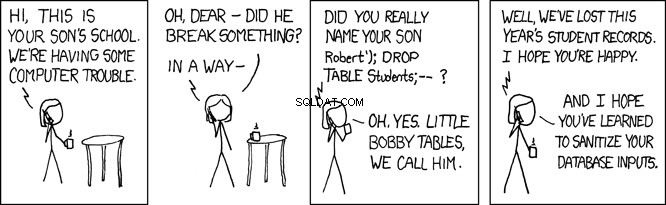
Stel je bijvoorbeeld een kwaadwillende gebruiker voor die je REST API op deze manier noemt:
GET /api/people/Farrell');DROP TABLE person;
Het bovenstaande REST API-verzoek stelt de lname . in variabele naar 'Farrell');DROP TABLE person;' , die in de bovenstaande code deze SQL-instructie zou genereren:
SELECT * FROM person WHERE lname = 'Farrell');DROP TABLE person;
De bovenstaande SQL-instructie is geldig, en wanneer uitgevoerd door de database zal het één record vinden waar lname komt overeen met 'Farrell' . Dan zal het het SQL-instructie scheidingsteken ; en zal doorgaan en de hele tafel laten vallen. Dit zou in wezen je aanvraag verpesten.
U kunt uw programma beschermen door alle gegevens die u van gebruikers van uw toepassing krijgt op te schonen. Het opschonen van gegevens in deze context betekent dat uw programma de door de gebruiker geleverde gegevens moet onderzoeken en ervoor moet zorgen dat deze niets gevaarlijks voor het programma bevatten. Dit kan lastig zijn om goed te doen en zou overal moeten worden gedaan waar gebruikersgegevens interactie hebben met de database.
Er is een andere manier die veel eenvoudiger is:gebruik SQLAlchemy. Het zal gebruikersgegevens voor u opschonen voordat SQL-instructies worden gemaakt. Het is nog een groot voordeel en reden om SQLAlchemy te gebruiken bij het werken met databases.
Gegevens modelleren met SQLAlchemy
SQLAlchemy is een groot project en biedt veel functionaliteit om te werken met databases met Python. Een van de dingen die het biedt, is een ORM, of Object Relational Mapper, en dit is wat je gaat gebruiken om de person te maken en ermee te werken database tabel. Hiermee kunt u een rij velden uit de databasetabel toewijzen aan een Python-object.
Met Object Oriented Programming kun je data verbinden met gedrag, de functies die op die data werken. Door SQLAlchemy-klassen te maken, kunt u de velden uit de databasetabelrijen koppelen aan gedrag, zodat u met de gegevens kunt communiceren. Hier is de SQLAlchemy-klassedefinitie voor de gegevens in de person databasetabel:
class Person(db.Model):
__tablename__ = 'person'
person_id = db.Column(db.Integer,
primary_key=True)
lname = db.Column(db.String)
fname = db.Column(db.String)
timestamp = db.Column(db.DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow)
De klas Person erft van db.Model , die u te zien krijgt wanneer u begint met het bouwen van de programmacode. Voor nu betekent dit dat je erft van een basisklasse genaamd Model , wat kenmerken en functionaliteit biedt die gemeenschappelijk zijn voor alle klassen die ervan zijn afgeleid.
De rest van de definities zijn attributen op klasseniveau die als volgt zijn gedefinieerd:
-
__tablename__ = 'person'verbindt de klassedefinitie met depersondatabasetabel. -
person_id = db.Column(db.Integer, primary_key=True)maakt een databasekolom met een geheel getal dat fungeert als de primaire sleutel voor de tabel. Dit vertelt de database ook datperson_idzal een automatisch oplopende gehele waarde zijn. -
lname = db.Column(db.String)creëert het achternaamveld, een databasekolom met een tekenreekswaarde. -
fname = db.Column(db.String)maakt het veld voor de voornaam, een databasekolom met een tekenreekswaarde. -
timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)creëert een tijdstempelveld, een databasekolom met een datum/tijd-waarde. Dedefault=datetime.utcnowparameter zet de tijdstempelwaarde standaard op de huidigeutcnowwaarde wanneer een record wordt gemaakt. Deonupdate=datetime.utcnowparameter werkt de tijdstempel bij met de huidigeutcnowwaarde wanneer de record wordt bijgewerkt.
Opmerking:UTC-tijdstempels
U vraagt zich misschien af waarom de tijdstempel in de bovenstaande klasse standaard is ingesteld op en wordt bijgewerkt door de datetime.utcnow() methode, die een UTC of Coordinated Universal Time retourneert. Dit is een manier om de bron van je tijdstempel te standaardiseren.
De bron, of nultijd, is een lijn die noord en zuid loopt van de noordpool naar de zuidpool van de aarde door het VK. Dit is de nultijdzone van waaruit alle andere tijdzones worden verschoven. Door dit te gebruiken als de nultijdbron, zijn uw tijdstempels offsets van dit standaardreferentiepunt.
Als uw toepassing vanuit verschillende tijdzones wordt geopend, heeft u een manier om datum-/tijdberekeningen uit te voeren. Het enige dat u nodig hebt, is een UTC-tijdstempel en de tijdzone van de bestemming.
Als u lokale tijdzones als tijdstempelbron zou gebruiken, dan zou u geen datum-/tijdberekeningen kunnen uitvoeren zonder informatie over de lokale tijdzones die zijn verschoven ten opzichte van nultijd. Zonder de broninformatie van de tijdstempel zou je helemaal geen datum/tijd-vergelijkingen of wiskunde kunnen doen.
Werken met tijdstempels op basis van UTC is een goede standaard om te volgen. Hier is een toolkit-site om mee te werken en ze beter te begrijpen.
Waar ga je heen met deze Person klasse definitie? Het einddoel is om een query uit te voeren met SQLAlchemy en een lijst met instanties van de Person terug te krijgen. klas. Laten we als voorbeeld eens kijken naar de vorige SQL-instructie:
SELECT * FROM people ORDER BY lname;
Toon hetzelfde kleine voorbeeldprogramma van hierboven, maar nu met SQLAlchemy:
1from models import Person
2
3people = Person.query.order_by(Person.lname).all()
4for person in people:
5 print(f'{person.fname} {person.lname}')
Voor het moment negerend regel 1, wat je wilt is de person records in oplopende volgorde gesorteerd op lname veld. Wat je terugkrijgt van de SQLAlchemy-instructies Person.query.order_by(Person.lname).all() is een lijst van Person objecten voor alle records in de person databasetabel in die volgorde. In het bovenstaande programma, de people variabele bevat de lijst van Person objecten.
Het programma herhaalt de people variabele, waarbij elke person op zijn beurt en het afdrukken van de voor- en achternaam van de persoon uit de database. Merk op dat het programma geen indexen hoeft te gebruiken om de fname . te krijgen of lname waarden:het gebruikt de attributen gedefinieerd op de Person voorwerp.
Door SQLAlchemy te gebruiken, kunt u denken in termen van objecten met gedrag in plaats van onbewerkte SQL . Dit wordt nog voordeliger wanneer uw databasetabellen groter worden en de interacties complexer.
Serialiseren/deserialiseren van gemodelleerde gegevens
Werken met door SQLAlchemy gemodelleerde gegevens in uw programma's is erg handig. Het is vooral handig in programma's die de gegevens manipuleren, bijvoorbeeld berekeningen maken of gebruiken om presentaties op het scherm te maken. Uw toepassing is een REST-API die in wezen CRUD-bewerkingen op de gegevens biedt en als zodanig niet veel gegevensmanipulatie uitvoert.
De REST API werkt met JSON-gegevens en hier kun je een probleem tegenkomen met het SQLAlchemy-model. Omdat de gegevens die door SQLAlchemy worden geretourneerd, Python-klasse-instanties zijn, kan Connexion deze klasse-instanties niet serialiseren naar JSON-geformatteerde gegevens. Onthoud uit deel 1 dat Connexion de tool is die je hebt gebruikt om de REST API te ontwerpen en te configureren met behulp van een YAML-bestand, en om daar Python-methoden aan te koppelen.
In deze context betekent serialiseren dat Python-objecten, die andere Python-objecten en complexe gegevenstypen kunnen bevatten, worden omgezet in eenvoudigere gegevensstructuren die kunnen worden geparseerd in JSON-gegevenstypen, die hier worden vermeld:
string: een tekenreekstypenumber: getallen ondersteund door Python (integers, floats, longs)object: een JSON-object, dat ongeveer gelijk is aan een Python-woordenboekarray: ongeveer gelijk aan een Python-lijstboolean: weergegeven in JSON alstrueoffalse, maar in Python alsTrueofFalsenull: in wezen eenNonein Python
Als voorbeeld, uw Person class bevat een tijdstempel, dat is een Python DateTime . Er is geen datum/tijd-definitie in JSON, dus de tijdstempel moet worden geconverteerd naar een tekenreeks om in een JSON-structuur te bestaan.
Uw Person class is eenvoudig genoeg, dus het zou niet erg moeilijk zijn om de data-attributen eruit te halen en handmatig een woordenboek te maken om terug te keren van onze REST URL-eindpunten. In een complexere applicatie met veel grotere SQLAlchemy-modellen zou dit niet het geval zijn. Een betere oplossing is om een module genaamd Marshmallow te gebruiken om het werk voor je te doen.
Marshmallow helpt je bij het maken van een PersonSchema klasse, die lijkt op de SQLAlchemy Person klasse die we hebben gemaakt. Hier echter, in plaats van databasetabellen en veldnamen toe te wijzen aan de klasse en zijn attributen, wordt het PersonSchema class definieert hoe de attributen van een klasse worden geconverteerd naar JSON-vriendelijke formaten. Hier is de Marshmallow-klassedefinitie voor de gegevens in onze person tafel:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
De klasse PersonSchema erft van ma.ModelSchema , die u te zien krijgt wanneer u begint met het bouwen van de programmacode. Voorlopig betekent dit PersonSchema erft van een Marshmallow-basisklasse genaamd ModelSchema , wat kenmerken en functionaliteit biedt die gemeenschappelijk zijn voor alle klassen die ervan zijn afgeleid.
De rest van de definitie is als volgt:
-
class Metadefinieert een klasse met de naamMetabinnen je klas. HetModelSchemaklasse dat hetPersonSchemaklasse erft van looks voor deze interneMetaclass en gebruikt het om het SQLAlchemy-modelPerson. te vinden en dedb.session. Dit is hoe Marshmallow attributen vindt in dePersonclass en het type van die attributen, zodat het weet hoe ze te serialiseren/deserialiseren. -
modelvertelt de klas welk SQLAlchemy-model moet worden gebruikt om gegevens van en naar te serialiseren/deserialiseren. -
db.sessionvertelt de klas welke databasesessie moet worden gebruikt voor introspectie en het bepalen van attribuutgegevenstypes.
Waar ga je heen met deze klassendefinitie? U wilt een instantie van een Person . kunnen serialiseren class in JSON-gegevens, en om JSON-gegevens te deserialiseren en een Person te maken klasse-instanties ervan.
Maak de geïnitialiseerde database
SQLAlchemy verwerkt veel van de interacties die specifiek zijn voor bepaalde databases en laat u zich concentreren op de gegevensmodellen en hoe u ze kunt gebruiken.
Nu je daadwerkelijk een database gaat maken, zoals eerder vermeld, ga je SQLite gebruiken. Je doet dit om een aantal redenen. Het wordt geleverd met Python en hoeft niet als een afzonderlijke module te worden geïnstalleerd. Het slaat alle database-informatie op in een enkel bestand en is daarom eenvoudig in te stellen en te gebruiken.
Het installeren van een aparte databaseserver zoals MySQL of PostgreSQL zou prima werken, maar zou die systemen moeten installeren en aan de gang krijgen, wat buiten het bestek van dit artikel valt.
Omdat SQLAlchemy de database afhandelt, maakt het in veel opzichten niet uit wat de onderliggende database is.
Je gaat een nieuw hulpprogramma maken genaamd build_database.py om de SQLite people.db te maken en te initialiseren databasebestand met uw person database tabel. Onderweg maak je twee Python-modules, config.py en models.py , die zal worden gebruikt door build_database.py en de gewijzigde server.py uit deel 1.
Hier vindt u de broncode voor de modules die u gaat maken, die hier worden geïntroduceerd:
-
config.pykrijgt de benodigde modules geïmporteerd in het programma en geconfigureerd. Dit omvat Flask, Connexion, SQLAlchemy en Marshmallow. Omdat het zal worden gebruikt door zowelbuild_database.pyenserver.py, zijn sommige delen van de configuratie alleen van toepassing op deserver.pyapplicatie. -
models.pyis de module waarin u dePerson. aanmaakt SQLAlchemy enPersonSchemaMarshmallow-klassedefinities hierboven beschreven. Deze module is afhankelijk vanconfig.pyvoor sommige van de objecten die daar zijn gemaakt en geconfigureerd.
Config-module
De config.py module, zoals de naam al aangeeft, is waar alle configuratie-informatie wordt gemaakt en geïnitialiseerd. We gaan deze module gebruiken voor zowel onze build_database.py programmabestand en de binnenkort te updaten server.py bestand uit het deel 1 artikel. Dit betekent dat we Flask, Connexion, SQLAlchemy en Marshmallow hier gaan configureren.
Hoewel de build_database.py programma maakt geen gebruik van Flask, Connexion of Marshmallow, het gebruikt SQLAlchemy om onze verbinding met de SQLite-database tot stand te brengen. Hier is de code voor de config.py module:
1import os
2import connexion
3from flask_sqlalchemy import SQLAlchemy
4from flask_marshmallow import Marshmallow
5
6basedir = os.path.abspath(os.path.dirname(__file__))
7
8# Create the Connexion application instance
9connex_app = connexion.App(__name__, specification_dir=basedir)
10
11# Get the underlying Flask app instance
12app = connex_app.app
13
14# Configure the SQLAlchemy part of the app instance
15app.config['SQLALCHEMY_ECHO'] = True
16app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////' + os.path.join(basedir, 'people.db')
17app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
18
19# Create the SQLAlchemy db instance
20db = SQLAlchemy(app)
21
22# Initialize Marshmallow
23ma = Marshmallow(app)
Dit is wat de bovenstaande code doet:
-
Lijnen 2 – 4 importeer Connexion zoals u deed in de
server.pyprogramma uit deel 1. Het importeert ookSQLAlchemyuit deflask_sqlalchemymodule. Dit geeft uw programmadatabase toegang. Ten slotte importeert hetMarshmallowvan deflask_marshamllowmodule. -
Lijn 6 creëert de variabele
basedirwijzend naar de map waarin het programma draait. -
Lijn 9 gebruikt de
basedirvariabele om de Connexion-app-instantie te maken en deze het pad naar deswagger.ymlte geven bestand. -
Lijn 12 maakt een variabele
app, de Flask-instantie die door Connexion is geïnitialiseerd. -
Lijnen 15 gebruikt de
appvariabele om waarden te configureren die worden gebruikt door SQLAlchemy. Eerst wordtSQLALCHEMY_ECHO. ingesteld naarTrue. Dit zorgt ervoor dat SQLAlchemy de SQL-instructies die het uitvoert naar de console echo. Dit is erg handig om problemen op te lossen bij het bouwen van databaseprogramma's. Stel dit in opFalsevoor productieomgevingen. -
Lijn 16 stelt
SQLALCHEMY_DATABASE_URIin naarsqlite:////' + os.path.join(basedir, 'people.db'). Dit vertelt SQLAlchemy om SQLite als database te gebruiken, en een bestand met de naampeople.dbin de huidige map als het databasebestand. Verschillende database-engines, zoals MySQL en PostgreSQL, hebben verschillendeSQLALCHEMY_DATABASE_URIstrings om ze te configureren. -
Lijn 17 stelt
SQLALCHEMY_TRACK_MODIFICATIONSin naarFalse, het uitschakelen van het SQLAlchemy-gebeurtenissysteem, dat standaard is ingeschakeld. Het gebeurtenissysteem genereert gebeurtenissen die nuttig zijn in gebeurtenisgestuurde programma's, maar voegt aanzienlijke overhead toe. Aangezien je geen evenementgestuurd programma maakt, moet je deze functie uitschakelen. -
Lijn 19 maakt de
dbvariabele doorSQLAlchemy(app). aan te roepen . Dit initialiseert SQLAlchemy door deapp. door te geven configuratie-informatie zojuist ingesteld. Dedbvariabele is wat wordt geïmporteerd in debuild_database.pyprogramma om het toegang te geven tot SQLAlchemy en de database. Het heeft hetzelfde doel in deserver.pyprogramma enpeople.pymodule. -
Lijn 23 maakt de
mavariabele doorMarshmallow(app). aan te roepen . Hiermee wordt Marshmallow geïnitialiseerd en kan het de SQLAlchemy-componenten die aan de app zijn gekoppeld, introspecteren. Dit is de reden waarom Marshmallow wordt geïnitialiseerd na SQLAlchemy.
Module Modellen
De models.py module is gemaakt om de Person en PersonSchema klassen precies zoals beschreven in de secties hierboven over het modelleren en serialiseren van de gegevens. Hier is de code voor die module:
1from datetime import datetime
2from config import db, ma
3
4class Person(db.Model):
5 __tablename__ = 'person'
6 person_id = db.Column(db.Integer, primary_key=True)
7 lname = db.Column(db.String(32), index=True)
8 fname = db.Column(db.String(32))
9 timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
10
11class PersonSchema(ma.ModelSchema):
12 class Meta:
13 model = Person
14 sqla_session = db.session
Dit is wat de bovenstaande code doet:
-
Lijn 1 importeert de
datetimeobject van dedatetimemodule die bij Python wordt geleverd. Dit geeft je een manier om een tijdstempel te maken in dePersonklasse. -
Lijn 2 importeert de
dbenmainstantievariabelen gedefinieerd in deconfig.pymodule. Dit geeft de module toegang tot SQLAlchemy-attributen en -methoden die zijn gekoppeld aan dedbvariabele, en de Marshmallow-attributen en -methoden die zijn gekoppeld aan demavariabel. -
Lijnen 4 – 9 definieer de
Personklasse zoals besproken in het gedeelte over gegevensmodellering hierboven, maar nu weet u waar dedb.Modelwaarvan de klasse erft, afkomstig is. Dit geeft dePersonclass SQLAlchemy-functies, zoals een verbinding met de database en toegang tot de tabellen. -
Lijnen 11 – 14 definieer het
PersonSchemaclass as was discussed in the data serialzation section above. This class inherits fromma.ModelSchemaand gives thePersonSchemaclass Marshmallow features, like introspecting thePersonclass to help serialize/deserialize instances of that class.
Creating the Database
You’ve seen how database tables can be mapped to SQLAlchemy classes. Now use what you’ve learned to create the database and populate it with data. You’re going to build a small utility program to create and build the database with the People data. Here’s the build_database.py program:
1import os
2from config import db
3from models import Person
4
5# Data to initialize database with
6PEOPLE = [
7 {'fname': 'Doug', 'lname': 'Farrell'},
8 {'fname': 'Kent', 'lname': 'Brockman'},
9 {'fname': 'Bunny','lname': 'Easter'}
10]
11
12# Delete database file if it exists currently
13if os.path.exists('people.db'):
14 os.remove('people.db')
15
16# Create the database
17db.create_all()
18
19# Iterate over the PEOPLE structure and populate the database
20for person in PEOPLE:
21 p = Person(lname=person['lname'], fname=person['fname'])
22 db.session.add(p)
23
24db.session.commit()
Here’s what the above code is doing:
-
Line 2 imports the
dbinstance from theconfig.pymodule. -
Line 3 imports the
Personclass definition from themodels.pymodule. -
Lines 6 – 10 create the
PEOPLEdata structure, which is a list of dictionaries containing your data. The structure has been condensed to save presentation space. -
Lines 13 &14 perform some simple housekeeping to delete the
people.dbfile, if it exists. This file is where the SQLite database is maintained. If you ever have to re-initialize the database to get a clean start, this makes sure you’re starting from scratch when you build the database. -
Line 17 creates the database with the
db.create_all()call. This creates the database by using thedbinstance imported from theconfigmodule. Thedbinstance is our connection to the database. -
Lines 20 – 22 iterate over the
PEOPLElist and use the dictionaries within to instantiate aPersonclass. After it is instantiated, you call thedb.session.add(p)functie. This uses the database connection instancedbto access thesessionvoorwerp. The session is what manages the database actions, which are recorded in the session. In this case, you are executing theadd(p)method to add the newPersoninstance to thesessionvoorwerp. -
Line 24 calls
db.session.commit()to actually save all the person objects created to the database.
Opmerking: At Line 22, no data has been added to the database. Everything is being saved within the session voorwerp. Only when you execute the db.session.commit() call at Line 24 does the session interact with the database and commit the actions to it.
In SQLAlchemy, the session is an important object. It acts as the conduit between the database and the SQLAlchemy Python objects created in a program. The session helps maintain the consistency between data in the program and the same data as it exists in the database. It saves all database actions and will update the underlying database accordingly by both explicit and implicit actions taken by the program.
Now you’re ready to run the build_database.py program to create and initialize the new database. You do so with the following command, with your Python virtual environment active:
python build_database.py
When the program runs, it will print SQLAlchemy log messages to the console. These are the result of setting SQLALCHEMY_ECHO to True in the config.py het dossier. Much of what’s being logged by SQLAlchemy is the SQL commands it’s generating to create and build the people.db SQLite database file. Here’s an example of what’s printed out when the program is run:
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
CREATE TABLE person (
person_id INTEGER NOT NULL,
lname VARCHAR,
fname VARCHAR,
timestamp DATETIME,
PRIMARY KEY (person_id)
)
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
Using the Database
Once the database has been created, you can modify the existing code from Part 1 to make use of it. All of the modifications necessary are due to creating the person_id primary key value in our database as the unique identifier rather than the lname waarde.
Update the REST API
None of the changes are very dramatic, and you’ll start by re-defining the REST API. The list below shows the API definition from Part 1 but is updated to use the person_id variable in the URL path:
| Action | HTTP Verb | URL Path | Beschrijving |
|---|---|---|---|
| Create | POST | /api/people | Defines a unique URL to create a new person |
| Read | GET | /api/people | Defines a unique URL to read a collection of people |
| Read | GET | /api/people/{person_id} | Defines a unique URL to read a particular person by person_id |
| Update | PUT | /api/people/{person_id} | Defines a unique URL to update an existing person by person_id |
| Delete | DELETE | /api/orders/{person_id} | Defines a unique URL to delete an existing person by person_id |
Where the URL definitions required an lname value, they now require the person_id (primary key) for the person record in the people tafel. This allows you to remove the code in the previous app that artificially restricted users from editing a person’s last name.
In order for you to implement these changes, the swagger.yml file from Part 1 will have to be edited. For the most part, any lname parameter value will be changed to person_id , and person_id will be added to the POST and PUT responses. You can check out the updated swagger.yml file.
Update the REST API Handlers
With the swagger.yml file updated to support the use of the person_id identifier, you’ll also need to update the handlers in the people.py file to support these changes. In the same way that the swagger.yml file was updated, you need to change the people.py file to use the person_id value rather than lname .
Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people :
1from flask import (
2 make_response,
3 abort,
4)
5from config import db
6from models import (
7 Person,
8 PersonSchema,
9)
10
11def read_all():
12 """
13 This function responds to a request for /api/people
14 with the complete lists of people
15
16 :return: json string of list of people
17 """
18 # Create the list of people from our data
19 people = Person.query \
20 .order_by(Person.lname) \
21 .all()
22
23 # Serialize the data for the response
24 person_schema = PersonSchema(many=True)
25 return person_schema.dump(people).data
Here’s what the above code is doing:
-
Lines 1 – 9 import some Flask modules to create the REST API responses, as well as importing the
dbinstance from theconfig.pymodule. In addition, it imports the SQLAlchemyPersonand MarshmallowPersonSchemaclasses to access thepersondatabase table and serialize the results. -
Line 11 starts the definition of
read_all()that responds to the REST API URL endpointGET /api/peopleand returns all the records in thepersondatabase table sorted in ascending order by last name. -
Lines 19 – 22 tell SQLAlchemy to query the
persondatabase table for all the records, sort them in ascending order (the default sorting order), and return a list ofPersonPython objects as the variablepeople. -
Line 24 is where the Marshmallow
PersonSchemaclass definition becomes valuable. You create an instance of thePersonSchema, passing it the parametermany=True. This tellsPersonSchemato expect an interable to serialize, which is what thepeoplevariable is. -
Line 25 uses the
PersonSchemainstance variable (person_schema), calling itsdump()method with thepeoplelist. The result is an object having adataattribute, an object containing apeoplelist that can be converted to JSON. This is returned and converted by Connexion to JSON as the response to the REST API call.
Opmerking: The people list variable created on Line 24 above can’t be returned directly because Connexion won’t know how to convert the timestamp field into JSON. Returning the list of people without processing it with Marshmallow results in a long error traceback and finally this Exception:
TypeError: Object of type Person is not JSON serializable
Here’s another part of the person.py module that makes a request for a single person from the person databank. Here, read_one(person_id) function receives a person_id from the REST URL path, indicating the user is looking for a specific person. Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people/{person_id} :
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: ID of person to find
7 :return: person matching ID
8 """
9 # Get the person requested
10 person = Person.query \
11 .filter(Person.person_id == person_id) \
12 .one_or_none()
13
14 # Did we find a person?
15 if person is not None:
16
17 # Serialize the data for the response
18 person_schema = PersonSchema()
19 return person_schema.dump(person).data
20
21 # Otherwise, nope, didn't find that person
22 else:
23 abort(404, 'Person not found for Id: {person_id}'.format(person_id=person_id))
Here’s what the above code is doing:
-
Lines 10 – 12 use the
person_idparameter in a SQLAlchemy query using thefiltermethod of the query object to search for a person with aperson_idattribute matching the passed-inperson_id. Rather than using theall()query method, use theone_or_none()method to get one person, or returnNoneif no match is found. -
Line 15 determines whether a
personwas found or not. -
Line 17 shows that, if
personwas notNone(a matchingpersonwas found), then serializing the data is a little different. You don’t pass themany=Trueparameter to the creation of thePersonSchema()instance. Instead, you passmany=Falsebecause only a single object is passed in to serialize. -
Line 18 is where the
dumpmethod ofperson_schemais called, and thedataattribute of the resulting object is returned. -
Line 23 shows that, if
personwasNone(a matching person wasn’t found), then the Flaskabort()method is called to return an error.
Another modification to person.py is creating a new person in the database. This gives you an opportunity to use the Marshmallow PersonSchema to deserialize a JSON structure sent with the HTTP request to create a SQLAlchemy Person voorwerp. Here’s part of the updated person.py module showing the handler for the REST URL endpoint POST /api/people :
1def create(person):
2 """
3 This function creates a new person in the people structure
4 based on the passed-in person data
5
6 :param person: person to create in people structure
7 :return: 201 on success, 406 on person exists
8 """
9 fname = person.get('fname')
10 lname = person.get('lname')
11
12 existing_person = Person.query \
13 .filter(Person.fname == fname) \
14 .filter(Person.lname == lname) \
15 .one_or_none()
16
17 # Can we insert this person?
18 if existing_person is None:
19
20 # Create a person instance using the schema and the passed-in person
21 schema = PersonSchema()
22 new_person = schema.load(person, session=db.session).data
23
24 # Add the person to the database
25 db.session.add(new_person)
26 db.session.commit()
27
28 # Serialize and return the newly created person in the response
29 return schema.dump(new_person).data, 201
30
31 # Otherwise, nope, person exists already
32 else:
33 abort(409, f'Person {fname} {lname} exists already')
Here’s what the above code is doing:
-
Line 9 &10 set the
fnameandlnamevariables based on thePersondata structure sent as thePOSTbody of the HTTP request. -
Lines 12 – 15 use the SQLAlchemy
Personclass to query the database for the existence of a person with the samefnameandlnameas the passed-inperson. -
Line 18 addresses whether
existing_personisNone. (existing_personwas not found.) -
Line 21 creates a
PersonSchema()instance calledschema. -
Line 22 uses the
schemavariable to load the data contained in thepersonparameter variable and create a new SQLAlchemyPersoninstance variable callednew_person. -
Line 25 adds the
new_personinstance to thedb.session. -
Line 26 commits the
new_personinstance to the database, which also assigns it a new primary key value (based on the auto-incrementing integer) and a UTC-based timestamp. -
Line 33 shows that, if
existing_personis notNone(a matching person was found), then the Flaskabort()method is called to return an error.
Update the Swagger UI
With the above changes in place, your REST API is now functional. The changes you’ve made are also reflected in an updated swagger UI interface and can be interacted with in the same manner. Below is a screenshot of the updated swagger UI opened to the GET /people/{person_id} section. This section of the UI gets a single person from the database and looks like this:
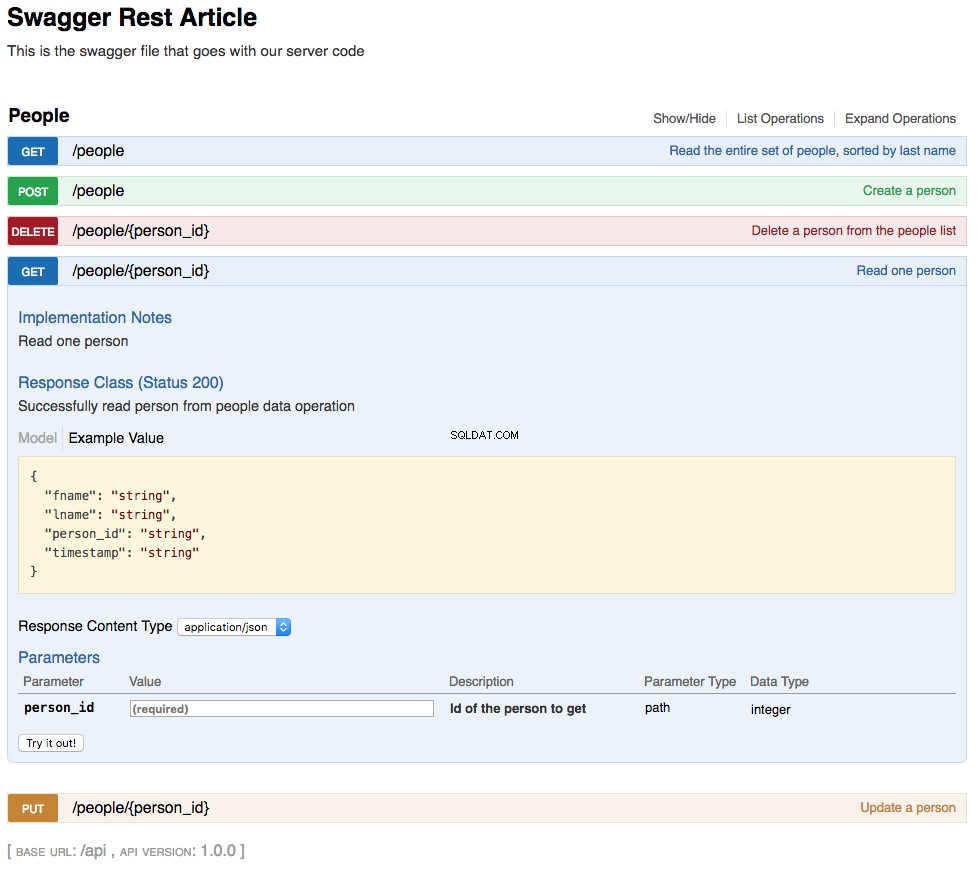
As shown in the above screenshot, the path parameter lname has been replaced by person_id , which is the primary key for a person in the REST API. The changes to the UI are a combined result of changing the swagger.yml file and the code changes made to support that.
Update the Web Application
The REST API is running, and CRUD operations are being persisted to the database. So that it is possible to view the demonstration web application, the JavaScript code has to be updated.
The updates are again related to using person_id instead of lname as the primary key for person data. In addition, the person_id is attached to the rows of the display table as HTML data attributes named data-person-id , so the value can be retrieved and used by the JavaScript code.
This article focused on the database and making your REST API use it, which is why there’s just a link to the updated JavaScript source and not much discussion of what it does.
Example Code
All of the example code for this article is available here. There’s one version of the code containing all the files, including the build_database.py utility program and the server.py modified example program from Part 1.
Conclusie
Congratulations, you’ve covered a lot of new material in this article and added useful tools to your arsenal!
You’ve learned how to save Python objects to a database using SQLAlchemy. You’ve also learned how to use Marshmallow to serialize and deserialize SQLAlchemy objects and use them with a JSON REST API. The things you’ve learned have certainly been a step up in complexity from the simple REST API of Part 1, but that step has given you two very powerful tools to use when creating more complex applications.
SQLAlchemy and Marshmallow are amazing tools in their own right. Using them together gives you a great leg up to create your own web applications backed by a database.
In Part 3 of this series, you’ll focus on the R part of RDBMS :relationships, which provide even more power when you are using a database.