Inleiding
Onlangs kwamen we een interessant prestatieprobleem tegen op een van onze SQL Server-databases die transacties in een serieus tempo verwerken. De transactietabel die werd gebruikt om deze transacties vast te leggen, werd een hot table. Als gevolg hiervan verscheen het probleem in de applicatielaag. Het was een onderbroken time-out van de sessie om transacties te posten.
Dit gebeurde omdat een sessie normaal gesproken de tafel zou 'vasthouden' en een reeks valse vergrendelingen in de database zou veroorzaken.
De eerste reactie van een typische databasebeheerder zou zijn om de primaire blokkerende sessie te identificeren en deze veilig te beëindigen. Dit was veilig omdat het meestal een SELECT-instructie of een inactieve sessie was.
Er waren ook andere pogingen om het probleem op te lossen:
- De tafel opruimen. Verwacht werd dat dit goede prestaties zou opleveren, zelfs als de query een volledige tabel moest scannen.
- Het isolatieniveau READ COMMITTED SNAPSHOT inschakelen om de impact van het blokkeren van sessies te verminderen.
In dit artikel zullen we proberen een simplistische versie van het scenario na te bootsen en het gebruiken om te laten zien hoe eenvoudig indexeren dit soort situaties kan aanpakken als het goed wordt gedaan.
Twee gerelateerde tabellen
Kijk eens naar Listing 1 en Listing 2. Ze tonen de vereenvoudigde versies van tabellen die betrokken zijn bij het betreffende scenario.
-- Listing 1: Create TranLog Table
use DB2
go
create table TranLog (
TranID INT IDENTITY(1,1)
,CustomerID char(4)
,ProductCount INT
,TotalPrice Money
,TranTime Timestamp
)
-- Listing 2: Create TranDetails Table
use DB2
go
create table TranDetails (
TranDetailsID INT IDENTITY(1,1)
,TranID INT
,ProductCode uniqueidentifier
,UnitCost Money
,ProductCount INT
,TotalPrice Money
)
Lijst 3 toont een trigger die vier rijen invoegt in de TranDetails tabel voor elke rij ingevoegd in de TranLog tafel.
-- Listing 3: Create Trigger
CREATE TRIGGER dbo.GenerateDetails
ON dbo.TranLog
AFTER INSERT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
END
GO
Deelnemen aan zoekopdracht
Het is typisch om transactietabellen te vinden die worden ondersteund door grote tabellen. Het doel is om veel oudere transacties te bewaren of om de details van records die in de eerste tabel zijn samengevat, op te slaan. Zie dit als bestellingen en besteldetails tabellen die typisch zijn in SQL Server-voorbeelddatabases. In ons geval overwegen we de TranLog en TranDetails tabellen.
Onder normale omstandigheden vullen transacties deze twee tabellen in de loop van de tijd. In termen van rapportage of eenvoudige query's, voert de query een join uit op deze twee tabellen. Deze join maakt gebruik van een gemeenschappelijke kolom tussen de tabellen.
Eerst vullen we de tabel met behulp van de query in Listing 4.
-- Listing 4: Insert Rows in TranLog
use DB2
go
insert into TranLog values ('CU01', 5, '50.45', DEFAULT);
insert into TranLog values ('CU02', 7, '42.35', DEFAULT);
insert into TranLog values ('CU03', 15, '39.55', DEFAULT);
insert into TranLog values ('CU04', 9, '33.50', DEFAULT);
insert into TranLog values ('CU05', 2, '105.45', DEFAULT);
go 1000
use DB2
go
select * from TranLog;
select * from TranDetails;
In ons voorbeeld is de algemene kolom die door de join wordt gebruikt de TranID kolom:
-- Listing 5 Join Query
-- 5a
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.CustomerID='CU03';
-- 5b
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.TranID=30;
U kunt de twee eenvoudige voorbeeldquery's zien die een join gebruiken om records op te halen uit TranLog en TranDetails .
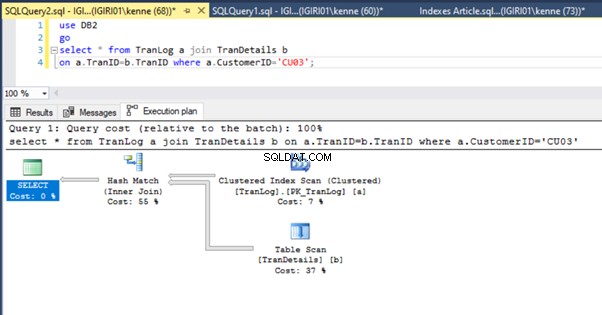
Wanneer we de query's in Listing 5 uitvoeren, moeten we in beide gevallen een volledige tabelscan uitvoeren op beide tabellen (zie afbeeldingen 1 en 2). Het dominante onderdeel van elke query zijn de fysieke bewerkingen. Beide zijn inner joins. Listing 5a gebruikt echter een Hash Match join, terwijl listing 5b gebruik maakt van een geneste lus meedoen. Opmerking:listing 5a retourneert 4000 rijen terwijl listing 4b 4 rijen retourneert.
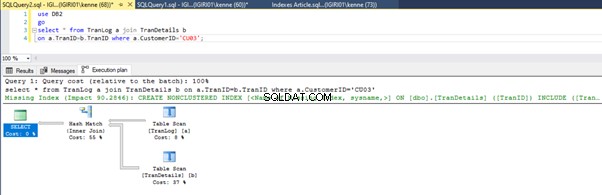
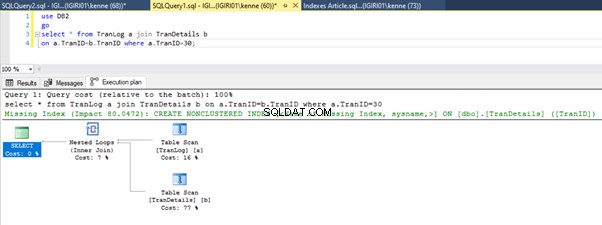
Drie prestatie-afstemmingsstappen
De eerste optimalisatie die we doen is het introduceren van een index (een primaire sleutel, om precies te zijn) op de TranID kolom van de TranLog tafel:
-- Listing 6: Create Primary Key
alter table TranLog add constraint PK_TranLog primary key clustered (TranID);
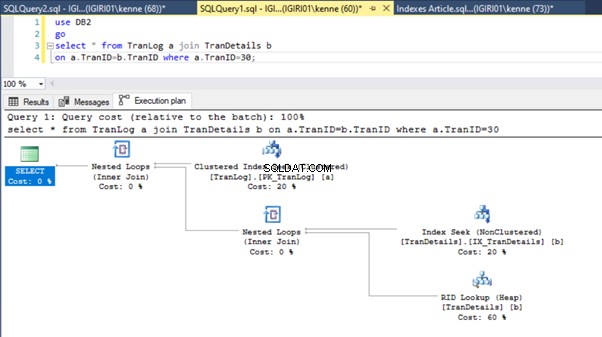
Figuren 3 en 4 laten zien dat SQL Server deze index gebruikt in beide zoekopdrachten, waarbij een scan wordt uitgevoerd in Listing 5a en een zoekopdracht in Listing 5b.
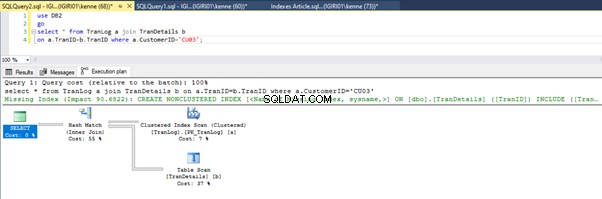
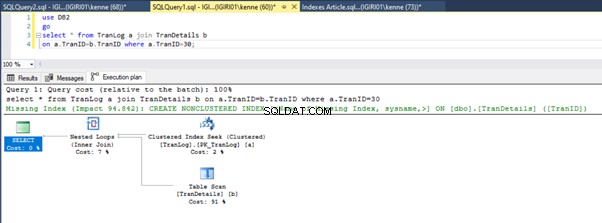
We hebben een indexzoekopdracht in listing 5b. Het gebeurt vanwege de kolom die betrokken is bij het WHERE-clausulepredikaat - TranID. Het is die kolom waarop we een index hebben toegepast.
Vervolgens introduceren we een externe sleutel op de TranID kolom van de TranDetails tafel (Lijst 7).
-- Listing 7: Create Foreign Key
alter table TranDetails add constraint FK_TranDetails foreign key (TranID) references TranLog (TranID);
In het uitvoeringsplan verandert dit niet veel. De situatie is nagenoeg hetzelfde als eerder getoond in figuren 3 en 4.
Vervolgens introduceren we een index op de externe sleutelkolom:
-- Listing 8: Create Index on Foreign Key
create index IX_TranDetails on TranDetails (TranID);
Deze actie verandert het uitvoeringsplan van listing 5b ingrijpend (zie figuur 6). We zien dat er meer indexpogingen gebeuren. Let ook op de RID-lookup in Afbeelding 6.
RID-zoekopdrachten op heaps gebeuren meestal in afwezigheid van een primaire sleutel. Een heap is een tabel zonder primaire sleutel.
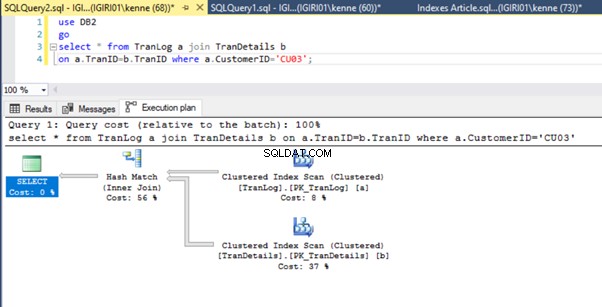
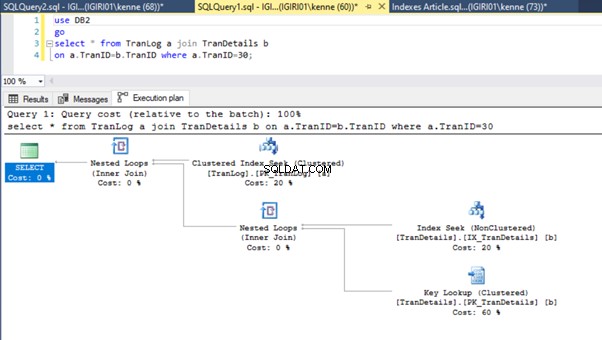
Ten slotte voegen we een primaire sleutel toe aan de TranDetails tafel. Hierdoor worden de tabelscan en RID-heap-lookup in respectievelijk lijst 5a en 5b verwijderd (zie afbeeldingen 7 en 8).
-- Listing 9: Create Primary Key on TranDetailsID
alter table TranDetails add constraint PK_TranDetails primary key clustered (TranDetailsID);
Conclusie
De prestatieverbetering die door indexen wordt geïntroduceerd, is zelfs bij beginnende DBA bekend. We willen u er echter op wijzen dat u goed moet kijken naar hoe zoekopdrachten indexen gebruiken.
Verder is het de bedoeling om de oplossing te vinden in het specifieke geval waarin we de join-query's hebben tussen Transactielogboek tabellen en Transactiedetails tabellen.
Het is over het algemeen logisch om de relatie tussen dergelijke tabellen af te dwingen met behulp van een sleutel en indexen te introduceren in de primaire en externe sleutelkolommen.
Bij het ontwikkelen van applicaties die een dergelijk ontwerp gebruiken, moeten ontwikkelaars rekening houden met de vereiste indexen en relaties in de ontwerpfase. Moderne tools voor SQL Server-specialisten maken het veel gemakkelijker om aan deze vereisten te voldoen. U kunt uw zoekopdrachten profileren met behulp van de gespecialiseerde tool Query Profiler. Het maakt deel uit van de veelzijdige professionele oplossing dbForge Studio voor SQL Server, ontwikkeld door Devart om het leven van DBA eenvoudiger te maken.