De ROW_NUMBER-vensterfunctie heeft tal van praktische toepassingen, veel verder dan alleen de voor de hand liggende rangschikkingsbehoeften. Meestal, wanneer u rijnummers berekent, moet u ze berekenen op basis van een bepaalde volgorde, en u geeft de gewenste bestelspecificatie op in de venstervolgorde-clausule van de functie. Er zijn echter gevallen waarin u rijnummers in willekeurige volgorde moet berekenen; met andere woorden, gebaseerd op niet-deterministische volgorde. Dit kan het hele queryresultaat zijn, of binnen partities. Voorbeelden zijn het toewijzen van unieke waarden aan resultaatrijen, het ontdubbelen van gegevens en het retourneren van rijen per groep.
Merk op dat het toewijzen van rijnummers op basis van niet-deterministische volgorde iets anders is dan het moeten toewijzen op basis van willekeurige volgorde. Bij de eerste maakt het u gewoon niet uit in welke volgorde ze zijn toegewezen en of herhaalde uitvoeringen van de query dezelfde rijnummers aan dezelfde rijen blijven toewijzen of niet. Bij de laatste verwacht je dat herhaalde uitvoeringen blijven veranderen welke rijen worden toegewezen met welke rijnummers. Dit artikel onderzoekt verschillende technieken voor het berekenen van rijnummers met niet-deterministische volgorde. De hoop is om een techniek te vinden die zowel betrouwbaar als optimaal is.
Speciale dank aan Paul White voor de tip over constant vouwen, voor de runtime-constante-techniek en voor altijd een geweldige bron van informatie te zijn!
Als bestelling belangrijk is
Ik zal beginnen met gevallen waarin de volgorde van het rijnummer er wel toe doet.
Ik gebruik een tabel met de naam T1 in mijn voorbeelden. Gebruik de volgende code om deze tabel te maken en deze te vullen met voorbeeldgegevens:
SET NOCOUNT ON; USE tempdb; DROP TABLE IF EXISTS dbo.T1; GO CREATE TABLE dbo.T1 ( id INT NOT NULL CONSTRAINT PK_T1 PRIMARY KEY, grp VARCHAR(10) NOT NULL, datacol INT NOT NULL ); INSERT INTO dbo.T1(id, grp, datacol) VALUES (11, 'A', 50), ( 3, 'B', 20), ( 5, 'A', 40), ( 7, 'B', 10), ( 2, 'A', 50);
Beschouw de volgende vraag (we noemen het vraag 1):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Hier wilt u dat rijnummers worden toegewezen binnen elke groep die wordt geïdentificeerd door de kolom grp, geordend op de kolom datacol. Toen ik deze query op mijn systeem uitvoerde, kreeg ik de volgende uitvoer:
id grp datacol n --- ---- -------- --- 5 A 40 1 2 A 50 2 11 A 50 3 7 B 10 1 3 B 20 2
Rijnummers worden hier toegewezen in een gedeeltelijk deterministische en gedeeltelijk niet-deterministische volgorde. Wat ik hiermee bedoel, is dat u er zeker van bent dat binnen dezelfde partitie een rij met een hogere datacol-waarde een hogere rijnummerwaarde krijgt. Aangezien datacol echter niet uniek is binnen de grp-partitie, is de volgorde van toewijzing van rijnummers tussen rijen met dezelfde grp- en datacol-waarden niet-deterministisch. Dat is het geval met de rijen met id-waarden 2 en 11. Beide hebben de grp-waarde A en de datacol-waarde 50. Toen ik deze query voor het eerst op mijn systeem uitvoerde, kreeg de rij met id 2 rijnummer 2 en de rij met id 11 kreeg rijnummer 3. Laat staan hoe waarschijnlijk het is dat dit in de praktijk in SQL Server gebeurt; als ik de query opnieuw zou uitvoeren, zou in theorie de rij met id 2 kunnen worden toegewezen aan rijnummer 3 en de rij met id 11 zou kunnen worden toegewezen aan rijnummer 2.
Als u rijnummers moet toewijzen op basis van een volledig deterministische volgorde, waarbij herhaalbare resultaten worden gegarandeerd voor alle uitvoeringen van de query, zolang de onderliggende gegevens niet veranderen, moet de combinatie van elementen in de clausules voor vensterpartitionering en -ordening uniek zijn. Dit zou in ons geval kunnen worden bereikt door de kolom-ID toe te voegen aan de venstervolgordeclausule als een tiebreaker. De OVER-clausule zou dan zijn:
OVER (PARTITION BY grp ORDER BY datacol, id)
In ieder geval, bij het berekenen van rijnummers op basis van een zinvolle bestelspecificatie zoals in Query 1, moet SQL Server de rijen verwerken die zijn geordend door de combinatie van vensterpartitionering en bestelelementen. Dit kan worden bereikt door de vooraf bestelde gegevens uit een index te halen of door de gegevens te sorteren. Op dit moment is er geen index op T1 om de ROW_NUMBER-berekening in Query 1 te ondersteunen, dus SQL Server moet ervoor kiezen om de gegevens te sorteren. Dit is te zien in het plan voor Query 1 in Afbeelding 1.
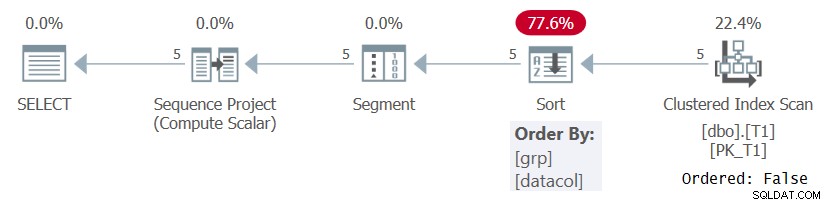 Figuur 1:Plan voor Query 1 zonder een ondersteunende index
Figuur 1:Plan voor Query 1 zonder een ondersteunende index
Merk op dat het plan de gegevens uit de geclusterde index scant met een Ordered:False eigenschap. Dit betekent dat de scan niet de rijen hoeft te retourneren die zijn gerangschikt op de indexsleutel. Dat is het geval omdat de geclusterde index hier wordt gebruikt alleen omdat deze de zoekopdracht dekt en niet vanwege de sleutelvolgorde. Het plan past vervolgens een sortering toe, wat resulteert in extra kosten, N Log N schaling en vertraagde responstijd. De segmentoperator produceert een vlag die aangeeft of de rij de eerste in de partitie is of niet. Ten slotte wijst de Sequence Project-operator rijnummers toe die beginnen met 1 in elke partitie.
Als u de noodzaak tot sorteren wilt vermijden, kunt u een dekkingsindex maken met een sleutellijst die is gebaseerd op de partitionerings- en volgorde-elementen, en een include-lijst die is gebaseerd op de dekkingselementen. Ik zie deze index graag als een POC-index (voor partitionering , bestellen en bedekkend ). Hier is de definitie van de POC die onze vraag ondersteunt:
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
Voer Query 1 opnieuw uit:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Het plan voor deze uitvoering is weergegeven in figuur 2.
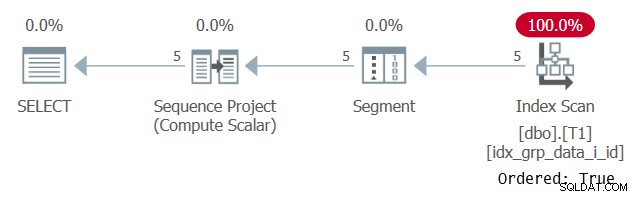 Figuur 2:Plan voor Query 1 met een POC-index
Figuur 2:Plan voor Query 1 met een POC-index
Merk op dat het plan deze keer de POC-index scant met een Ordered:True-eigenschap. Dit betekent dat de scan garandeert dat de rijen worden geretourneerd in de volgorde van de indexsleutel. Omdat de gegevens vooraf uit de index worden gehaald, zoals de vensterfunctie nodig heeft, is expliciet sorteren niet nodig. De schaal van dit plan is lineair en de responstijd is goed.
Als volgorde er niet toe doet
Het wordt een beetje lastig wanneer u rijnummers moet toewijzen met een volledig niet-deterministische volgorde. In een dergelijk geval is het logisch om de functie ROW_NUMBER te gebruiken zonder een venstervolgordeclausule op te geven. Laten we eerst eens kijken of de SQL-standaard dit toelaat. Hier is het relevante deel van de standaard die de syntaxisregels voor vensterfuncties definieert:
Syntaxisregels…
5) Laat WNS de
6) Als
a) Als
…
f) ROW_NUMBER() OVER WNS is gelijk aan de
…
Merk op dat item 6 de functies
Laten we het dus eens proberen en proberen rijnummers te berekenen zonder venstervolgorde in SQL Server:
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
Deze poging resulteert in de volgende fout:
Msg 4112, Level 15, State 1, Line 53De functie 'ROW_NUMBER' moet een OVER-clausule hebben met ORDER BY.
Als u de documentatie van SQL Server over de functie ROW_NUMBER bekijkt, vindt u inderdaad de volgende tekst:
“order_by_clauseDe ORDER BY-component bepaalt de volgorde waarin de rijen hun unieke ROW_NUMBER binnen een opgegeven partitie krijgen toegewezen. Het is verplicht.”
Dus blijkbaar is de venstervolgordeclausule verplicht voor de ROW_NUMBER-functie in SQL Server. Dat is trouwens ook het geval in Oracle.
Ik moet zeggen dat ik niet zeker weet of ik de redenering achter deze eis begrijp. Onthoud dat u rijnummers kunt definiëren op basis van een gedeeltelijk niet-deterministische volgorde, zoals in Query 1. Dus waarom zou u niet-determinisme helemaal toestaan? Misschien is er een reden waar ik niet aan denk. Als je zo'n reden kunt bedenken, deel het dan alsjeblieft.
Je zou in ieder geval kunnen stellen dat als je niet om bestelling geeft, aangezien de raambestellingsclausule verplicht is, je elke bestelling kunt specificeren. Het probleem met deze aanpak is dat als u per kolom uit de opgevraagde tabel(len) bestelt, dit een onnodige prestatievermindering met zich mee kan brengen. Als er geen ondersteunende index is, betaalt u voor expliciete sortering. Als er een ondersteunende index aanwezig is, beperkt u de opslagengine tot een scanstrategie voor indexorders (volgens de gelinkte indexlijst). U staat het niet meer flexibiliteit toe zoals het gewoonlijk heeft wanneer volgorde er niet toe doet bij het kiezen tussen een indexorderscan en een toewijzingsorderscan (gebaseerd op IAM-pagina's).
Een idee dat het proberen waard is, is om een constante, zoals 1, in de venstervolgordeclausule op te geven. Indien ondersteund, zou je hopen dat de optimizer slim genoeg is om te beseffen dat alle rijen dezelfde waarde hebben, dus er is geen echte volgorde-relevantie en daarom is het niet nodig om een sorteer- of indexvolgorde-scan te forceren. Hier is een vraag die deze benadering probeert:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
Helaas ondersteunt SQL Server deze oplossing niet. Het genereert de volgende fout:
Msg 5308, Level 16, State 1, Line 56Vensterfuncties, aggregaten en NEXT VALUE FOR-functies ondersteunen geen integer-indices als ORDER BY-clausuleexpressies.
Blijkbaar gaat SQL Server ervan uit dat als je een integer-constante gebruikt in de window-order-clausule, deze een ordinale positie van een element in de SELECT-lijst vertegenwoordigt, zoals wanneer je een integer opgeeft in de ORDER BY-component van de presentatie. Als dat het geval is, is een andere optie die het proberen waard is, een niet-gehele constante op te geven, zoals:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 'No Order') AS n FROM dbo.T1;
Blijkt dat deze oplossing ook niet wordt ondersteund. SQL Server genereert de volgende fout:
Msg 5309, Level 16, State 1, Line 65Vensterfuncties, aggregaten en NEXT VALUE FOR-functies ondersteunen geen constanten als ORDER BY-componentexpressies.
Blijkbaar ondersteunt de raamvolgorde-clausule geen enkele constante.
Tot dusver hebben we het volgende geleerd over de relevantie van de venstervolgorde van de ROW_NUMBER-functie in SQL Server:
- ORDER BY is vereist.
- Kan niet ordenen op een geheel getalconstante omdat SQL Server denkt dat u een ordinale positie in de SELECT probeert op te geven.
- Kan op geen enkele constante bestellen.
De conclusie is dat je moet ordenen op uitdrukkingen die geen constanten zijn. Vanzelfsprekend kunt u sorteren op een kolomlijst uit de opgevraagde tabel(len). Maar we zijn op zoek naar een efficiënte oplossing waarbij de optimizer kan realiseren dat er geen bestelrelevantie is.
Constant vouwen
De conclusie tot nu toe is dat je geen constanten kunt gebruiken in de venstervolgorde-clausule van ROW_NUMBER, maar hoe zit het met expressies op basis van constanten, zoals in de volgende query:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
Deze poging wordt echter het slachtoffer van een proces dat bekend staat als constant folden, dat normaal gesproken een positieve invloed heeft op de prestaties van query's. Het idee achter deze techniek is om de prestaties van query's te verbeteren door een expressie op basis van constanten in een vroeg stadium van de queryverwerking om te zetten in hun resultaatconstanten. U kunt hier details vinden over welke soorten uitdrukkingen constant kunnen worden gevouwen. Onze uitdrukking 1+0 is gevouwen tot 1, wat resulteert in dezelfde fout die u kreeg bij het rechtstreeks specificeren van de constante 1:
Msg 5308, Level 16, State 1, Line 79Vensterfuncties, aggregaten en NEXT VALUE FOR-functies ondersteunen geen integer-indices als ORDER BY-clausuleexpressies.
U zou met een vergelijkbare situatie te maken krijgen wanneer u probeert om letterlijke tekenreeksen van twee tekens samen te voegen, zoals:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 'No' + ' Order') AS n FROM dbo.T1;
U krijgt dezelfde foutmelding als wanneer u de letterlijke 'Geen bestelling' rechtstreeks opgeeft:
Msg 5309, Level 16, State 1, Line 55Vensterfuncties, aggregaten en NEXT VALUE FOR-functies ondersteunen geen constanten als ORDER BY-componentexpressies.
Bizarro wereld – fouten die fouten voorkomen
Het leven zit vol verrassingen...
Een ding dat constant vouwen verhindert, is wanneer de uitdrukking normaal gesproken in een fout zou resulteren. De uitdrukking 2147483646+1 kan bijvoorbeeld constant worden gevouwen, omdat dit resulteert in een geldige INT-getypte waarde. Bijgevolg mislukt een poging om de volgende query uit te voeren:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 109
Vensterfuncties, aggregaten en NEXT VALUE FOR-functies ondersteunen geen integer-indices als ORDER BY-clausuleexpressies.
De uitdrukking 2147483647+1 kan echter niet constant worden gefold omdat een dergelijke poging zou hebben geleid tot een INT-overloopfout. De implicatie bij het bestellen is best interessant. Probeer de volgende zoekopdracht (we noemen deze Query 2):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
Vreemd genoeg wordt deze query met succes uitgevoerd! Wat er gebeurt, is dat aan de ene kant SQL Server geen constante vouwing toepast, en daarom is de volgorde gebaseerd op een uitdrukking die geen enkele constante is. Aan de andere kant geeft de optimizer aan dat de bestelwaarde hetzelfde is voor alle rijen, dus negeert het de besteluitdrukking helemaal. Dit wordt bevestigd bij het onderzoeken van het plan voor deze vraag, zoals weergegeven in figuur 3.
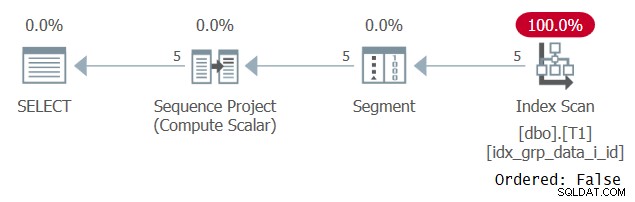 Figuur 3:Plan voor Query 2
Figuur 3:Plan voor Query 2
Merk op dat het plan een dekkingsindex scant met een Ordered:False-eigenschap. Dit was precies ons prestatiedoel.
Op een vergelijkbare manier omvat de volgende query een succesvolle constante fold-poging en mislukt daarom:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 123
Vensterfuncties, aggregaten en NEXT VALUE FOR-functies ondersteunen geen integer-indices als ORDER BY-clausuleexpressies.
De volgende query heeft betrekking op een mislukte constante vouwpoging en slaagt daarom, waardoor het eerder in Afbeelding 3 getoonde plan wordt gegenereerd:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
De volgende query omvat een succesvolle constante fold-poging (VARCHAR letterlijke '1' wordt impliciet geconverteerd naar de INT 1, en vervolgens wordt 1 + 1 gevouwen naar 2) en mislukt daarom:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+'1') AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 134
Vensterfuncties, aggregaten en NEXT VALUE FOR-functies ondersteunen geen integer-indices als ORDER BY-clausuleexpressies.
De volgende query betreft een mislukte constante fold-poging (kan 'A' niet converteren naar INT) en slaagt daarom, waardoor het plan wordt gegenereerd dat eerder in afbeelding 3 is weergegeven:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+'A') AS n FROM dbo.T1;
Om eerlijk te zijn, hoewel deze bizarre techniek ons oorspronkelijke prestatiedoel bereikt, kan ik niet zeggen dat ik het als veilig beschouw en daarom voel ik me er niet zo comfortabel bij om erop te vertrouwen.
Runtime-constanten op basis van functies
Voortzetting van de zoektocht naar een goede oplossing voor het berekenen van rijnummers met niet-deterministische volgorde, zijn er een paar technieken die veiliger lijken dan de laatste eigenzinnige oplossing:runtime-constanten gebruiken op basis van functies, een subquery gebruiken op basis van een constante, een alias-kolom gebruiken op basis van een constante en met behulp van een variabele.
Zoals ik uitleg in T-SQL-bugs, valkuilen en best practices - determinisme, de meeste functies in T-SQL worden slechts één keer per referentie in de query geëvalueerd - niet één keer per rij. Dit is zelfs het geval bij de meeste niet-deterministische functies zoals GETDATE en RAND. Er zijn maar weinig uitzonderingen op deze regel, zoals de functies NEWID en CRYPT_GEN_RANDOM, die één keer per rij worden geëvalueerd. De meeste functies, zoals GETDATE, @@SPID en vele andere, worden één keer geëvalueerd aan het begin van de query en hun waarden worden dan als runtimeconstanten beschouwd. Een verwijzing naar dergelijke functies wordt niet constant gevouwen. Deze kenmerken maken een runtime-constante die is gebaseerd op een functie een goede keuze als het vensterordeningselement, en inderdaad, het lijkt erop dat T-SQL dit ondersteunt. Tegelijkertijd realiseert de optimizer zich dat er in de praktijk geen bestelrelevantie is, waardoor onnodige prestatiestraffen worden vermeden.
Hier is een voorbeeld van het gebruik van de GETDATE-functie:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
Deze query krijgt hetzelfde plan als eerder in Afbeelding 3.
Hier is nog een voorbeeld waarbij de @@SPID-functie wordt gebruikt (waarbij de huidige sessie-ID wordt geretourneerd):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
Hoe zit het met de functie PI? Probeer de volgende zoekopdracht:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
Deze mislukt met de volgende fout:
Msg 5309, Level 16, State 1, Line 153Vensterfuncties, aggregaten en NEXT VALUE FOR-functies ondersteunen geen constanten als ORDER BY-componentexpressies.
Functies zoals GETDATE en @@SPID worden eenmaal per uitvoering van het plan opnieuw geëvalueerd, zodat ze niet constant kunnen worden gevouwen. PI vertegenwoordigt altijd dezelfde constante en wordt daarom constant gevouwen.
Zoals eerder vermeld, zijn er maar heel weinig functies die één keer per rij worden geëvalueerd, zoals NEWID en CRYPT_GEN_RANDOM. Dit maakt ze een slechte keuze als het vensterordeningselement als je een niet-deterministische volgorde nodig hebt - niet om te verwarren met willekeurige volgorde. Waarom een onnodige sorteerboete betalen?
Hier is een voorbeeld waarin de functie NEWID wordt gebruikt:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
Het plan voor deze query wordt getoond in figuur 4, wat bevestigt dat SQL Server expliciete sortering heeft toegevoegd op basis van het resultaat van de functie.
 Figuur 4:Plan voor Query 3
Figuur 4:Plan voor Query 3
Als u wilt dat de rijnummers in willekeurige volgorde worden toegewezen, is dat zeker de techniek die u wilt gebruiken. U moet zich er alleen van bewust zijn dat dit de sorteerkosten met zich meebrengt.
Een subquery gebruiken
U kunt ook een subquery gebruiken op basis van een constante als de uitdrukking voor het bestellen van vensters (bijv. ORDER BY (SELECT 'No Order')). Ook met deze oplossing erkent de optimalisatieprogramma van SQL Server dat er geen relevantie voor bestellen is, en legt daarom geen onnodige sortering op of beperkt de keuzes van de opslagengine niet tot degene die de volgorde moeten garanderen. Probeer de volgende query als voorbeeld uit te voeren:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 'No Order')) AS n FROM dbo.T1;
U krijgt hetzelfde plan als eerder in afbeelding 3.
Een van de grote voordelen van deze techniek is dat u uw eigen persoonlijke touch kunt toevoegen. Misschien hou je echt van NULL's:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
Misschien vind je een bepaald nummer erg leuk:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
Misschien wil je iemand een bericht sturen:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 'Lilach, will you marry me?')) AS n FROM dbo.T1;
Je snapt het punt.
Doelbaar, maar onhandig
Er zijn een paar technieken die werken, maar zijn een beetje onhandig. Een daarvan is om een kolomalias te definiëren voor een uitdrukking op basis van een constante, en dan die kolomalias te gebruiken als het vensterordeningselement. U kunt dit doen met behulp van een tabeluitdrukking of met de CROSS APPLY-operator en een tabelwaardeconstructor. Hier is een voorbeeld voor de laatste:
SELECT id, grp, datacol,
ROW_NUMBER() OVER(ORDER BY [I'm a bit ugly]) AS n
FROM dbo.T1 CROSS APPLY ( VALUES('No Order') ) AS A([I'm a bit ugly]); U krijgt hetzelfde plan als eerder in afbeelding 3.
Een andere optie is om een variabele te gebruiken als het vensterordeningselement:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
Deze query krijgt ook het eerder in figuur 3 getoonde plan.
Wat als ik mijn eigen UDF gebruik?
Je zou kunnen denken dat het gebruik van je eigen UDF die een constante retourneert, een goede keuze zou kunnen zijn als het vensterordeningselement wanneer je een niet-deterministische volgorde wilt, maar dat is het niet. Beschouw de volgende UDF-definitie als voorbeeld:
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis; GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INT AS BEGIN RETURN NULL END; GO
Probeer de UDF te gebruiken als de clausule voor het bestellen van vensters, zoals (we noemen deze Query 4):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
Voorafgaand aan SQL Server 2019 (of parallel compatibiliteitsniveau <150), worden door de gebruiker gedefinieerde functies per rij geëvalueerd. Zelfs als ze een constante retourneren, worden ze niet inline. Aan de ene kant kun je dus zo'n UDF als raambestellingselement gebruiken, maar aan de andere kant levert dit een soortstraf op. Dit wordt bevestigd door het plan voor deze zoekopdracht te bekijken, zoals weergegeven in figuur 5.
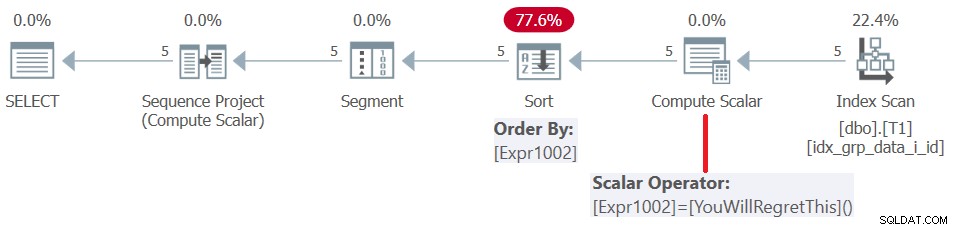 Figuur 5:Plan voor Query 4
Figuur 5:Plan voor Query 4
Beginnend met SQL Server 2019, onder compatibiliteitsniveau>=150, worden dergelijke door de gebruiker gedefinieerde functies inline geplaatst, wat meestal een goede zaak is, maar in ons geval resulteert dit in een fout:
Msg 5309, Level 16, State 1, Line 217Vensterfuncties, aggregaten en NEXT VALUE FOR-functies ondersteunen geen constanten als ORDER BY-componentexpressies.
Dus het gebruik van een UDF op basis van een constante als het venstervolgorde-element dwingt een sortering of een fout af, afhankelijk van de versie van SQL Server die u gebruikt en uw databasecompatibiliteitsniveau. Kortom, doe dit niet.
Gepartitioneerde rijnummers met niet-deterministische volgorde
Een veelvoorkomend gebruik voor gepartitioneerde rijnummers op basis van niet-deterministische volgorde is het retourneren van elke rij per groep. Aangezien er in dit scenario per definitie een scheidingselement bestaat, zou je denken dat een veilige techniek in zo'n geval zou zijn om het vensterscheidingselement ook als raambestellingselement te gebruiken. Als eerste stap bereken je rijnummers als volgt:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
Het plan voor deze query wordt getoond in figuur 6.
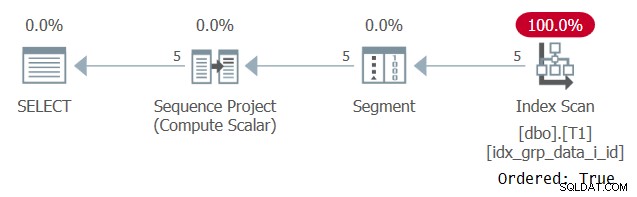 Figuur 6:Plan voor Query 5
Figuur 6:Plan voor Query 5
De reden dat onze ondersteunende index wordt gescand met een Ordered:True-eigenschap is omdat SQL Server de rijen van elke partitie als een enkele eenheid moet verwerken. Dat is het geval voorafgaand aan het filteren. Als je slechts één rij per partitie filtert, heb je zowel op volgorde gebaseerde als op hash gebaseerde algoritmen als opties.
De tweede stap is om de query met de berekening van het rijnummer in een tabeluitdrukking te plaatsen en in de buitenste query de rij met rijnummer 1 in elke partitie te filteren, zoals:
WITH C AS
(
SELECT id, grp, datacol,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n
FROM dbo.T1
)
SELECT id, grp, datacol
FROM C
WHERE n = 1; Theoretisch zou deze techniek veilig zijn, maar Paul White vond een bug die aantoont dat je met deze methode attributen kunt krijgen van verschillende bronrijen in de geretourneerde resultaatrij per partitie. Het gebruik van een runtime-constante op basis van een functie of een subquery op basis van een constante, aangezien het bestelelement zelfs in dit scenario veilig lijkt te zijn, dus zorg ervoor dat u in plaats daarvan een oplossing zoals de volgende gebruikt:
WITH C AS
(
SELECT id, grp, datacol,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY (SELECT 'No Order')) AS n
FROM dbo.T1
)
SELECT id, grp, datacol
FROM C
WHERE n = 1; Niemand komt deze kant op zonder mijn toestemming
Het is een veelvoorkomende behoefte om rijnummers te berekenen op basis van een niet-deterministische volgorde. Het zou leuk geweest zijn als T-SQL eenvoudig de venstervolgorde-clausule optioneel had gemaakt voor de ROW_NUMBER-functie, maar dat doet het niet. Zo niet, dan zou het leuk zijn geweest als het op zijn minst het gebruik van een constante als bestelelement toestond, maar dat is ook geen ondersteunde optie. Maar als je het vriendelijk vraagt, in de vorm van een subquery op basis van een constante of een runtime-constante op basis van een functie, dan staat SQL Server het toe. Dit zijn de twee opties waar ik me het prettigst bij voel. Ik voel me niet echt op mijn gemak met de eigenzinnige foutieve uitdrukkingen die lijken te werken, dus ik kan deze optie niet aanbevelen.