Voordat we het prestatieprobleem met doorgestuurde records doornemen en oplossen, moeten we de structuur van de SQL Server-tabellen bekijken.
Overzicht tabelstructuur
In SQL Server is de fundamentele eenheid van de gegevensopslag de 8-KB-pagina's . Elke pagina begint met een kop van 96 bytes waarin de systeeminformatie over die pagina is opgeslagen. Vervolgens worden de tabelrijen serieel na de koptekst op de gegevenspagina's opgeslagen. Aan het einde van de pagina wordt de rij-offsettabel, die één item voor elke rij bevat, opgeslagen tegengesteld aan de volgorde van de rijen op de pagina. Deze invoer voor rijverschuiving laat zien hoe ver de eerste byte van die rij zich vanaf het begin van de pagina bevindt.
SQL Server biedt ons twee soorten tabellen, gebaseerd op de structuur van die tabel. De geclusterde tabel slaat de gegevens op de gegevenspagina's op en sorteert ze op basis van de vooraf gedefinieerde waarden van de geclusterde indexsleutelkolom of -kolommen. Bovendien worden de gegevenspagina's binnen de geclusterde tabel gesorteerd en aan elkaar gekoppeld in een gekoppelde lijst op basis van de geclusterde indexsleutelwaarden. De B-boom structuur van de geclusterde index biedt een snelle methode voor gegevenstoegang op basis van de sleutelwaarden van de geclusterde index. Als een nieuwe rij wordt ingevoegd of een bestaande sleutelwaarde wordt bijgewerkt in de geclusterde tabel, zal SQL Server de nieuwe waarde opslaan op de juiste logische positie die past bij de ingevoegde rijgrootte zonder de volgordecriteria te overtreden. Als de ingevoegde of bijgewerkte waarde groter is dan de beschikbare ruimte op de gegevenspagina, wordt de pagina in twee pagina's gesplitst om op de nieuwe waarde te passen.
Het tweede type tabellen is de Heap tabel, waarin de gegevens niet in een willekeurige volgorde binnen de gegevenspagina's zijn gesorteerd en de pagina's niet aan elkaar zijn gekoppeld, omdat er geen geclusterde index voor die tabel is gedefinieerd om sorteercriteria af te dwingen. Het bijhouden van de pagina's die niet zijn gesorteerd in een bestelcriterium of aan elkaar zijn gekoppeld in de heaptabel, is geen gemakkelijke missie. Om het trackingproces van de paginatoewijzing binnen de heaptabel te vereenvoudigen, gebruikt SQL Server de Index Allocation Map (IAM), de enige logische verbinding tussen de gegevenspagina's in de heaptabel, door voor elke gegevenspagina in de tabel of de index in de IAM-tabel een vermelding te houden. Om gegevens uit de heaptabel op te halen, scant SQL Server Engine de IAM om de omvang te lokaliseren, die 8 pagina's vormt die de gevraagde gegevens opslaan.
Probleem doorgestuurde records
Als een nieuwe rij in de heaptabel wordt ingevoegd, scant SQL Server Engine de Page Free Space (PFS)-pagina's om de toewijzingsstatus en het ruimtegebruik op elke gegevenspagina bij te houden om de eerste beschikbare locatie op de gegevenspagina's te vinden die past bij de ingevoegde rijgrootte. Vervolgens wordt de rij toegevoegd aan de geselecteerde pagina. Als de ingevoegde waarde groter is dan de beschikbare ruimte op de gegevenspagina's, wordt er een nieuwe pagina aan die tabel toegevoegd om de nieuwe waarde in te kunnen voegen.
Aan de andere kant, als de bestaande gegevens in de heaptabel worden gewijzigd, bijvoorbeeld een tekenreeks met variabele lengte met een grotere gegevensomvang hebben bijgewerkt en de huidige ruimte niet past bij de nieuwe gegevens, worden de gegevens verplaatst naar een andere fysieke locatie en het Doorgestuurde record worden ingevoegd in de heaptabel op de oorspronkelijke gegevenslocatie, om te verwijzen naar de nieuwe locatie van die gegevens en om de locatie van de trackinggegevens te vereenvoudigen. De nieuwe datalocatie bevat ook een pointer die naar de forwarding pointer wijst om deze up-to-date te houden in het geval van het verplaatsen van de data van de nieuwe locatie en om de lange forwarding pointer keten te voorkomen of te verwijderen. Dit kan ook leiden tot het verwijderen van het doorstuurrecord.
Hoewel de omleidingsmethode voor doorgestuurde records de noodzaak vermindert voor het opnieuw opbouwen van de resource-intensieve tabel en niet-geclusterde indexen om de gegevensadressen bij te werken telkens wanneer de locatie van de gegevens wordt gewijzigd, verdubbelt het ook het aantal leesbewerkingen dat nodig is om de gegevens op te halen. SQL Server zal eerst de oude locatie bezoeken, waar het het doorgestuurde record vindt dat het omleidt naar de nieuwe gegevenslocatie. Vervolgens leest het de gevraagde gegevens en voert de leesbewerking twee keer uit. Bovendien leidt het probleem met doorgestuurde records ertoe dat de sequentiële gelezen gegevens worden gewijzigd in willekeurige gegevens die de prestaties van het ophalen van gegevens in de loop van de tijd negatief beïnvloeden.
Laten we de volgende ForwardRecordDemo hoop maken tabel met behulp van de onderstaande CREATE TABLE T-SQL-instructie:
CREATE TABLE ForwardRecordDemo ( ID INT IDENTITY (1,1), Emp_Name NVARCHAR (50), Emp_BirthDate DATETIME, Emp_Salary INT )
Vul vervolgens die tabel met 3K-records voor testdoeleinden, met behulp van de onderstaande instructie INSERT INTO T-SQL:
INSERT INTO ForwardRecordDemo VALUES ('John','2000-05-05',500)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Zaid','1999-01-07',700)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Frank','1988-07-04',900)
GO 1000 Het probleem met doorgestuurde records identificeren
De informatie over het tabeltype en het aantal gebruikte pagina's tijdens het opslaan van de tabelgegevens, evenals het indexfragmentatiepercentage en het aantal doorgestuurde records voor een specifieke tabel kunnen worden bekeken door de sys.dm_db_index_physical_stats systeem dynamische beheerfunctie en door door te gaan naar de DETAILED om het aantal doorstuurrecords te retourneren. Gebruik hiervoor het onderstaande T-SQL-script:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Zoals u aan het queryresultaat kunt zien, is de vorige tabel de heaptabel waarop geen geclusterde index is gemaakt om de gegevens op de pagina's te sorteren en de pagina's met elkaar te verbinden. De rijen van 3K die in de tabel zijn ingevoegd, worden toegewezen aan 15 gegevenspagina's, zonder doorgestuurde records en nul fragmentatiepercentage, zoals weergegeven in het onderstaande resultaat:

Wanneer u het gegevenstype van een kolom definieert als VARCHAR of NVARCHAR, is de waarde die is opgegeven in de definitie van het gegevenstype de maximaal toegestane grootte voor die tekenreeks, zonder dat bedrag volledig te reserveren terwijl de waarden op de gegevenspagina's worden opgeslagen. Bijvoorbeeld de John de naam van de werknemer die in die tabel wordt ingevoegd, reserveert slechts 8 bytes van de maximale 100 bytes voor die kolom, rekening houdend met het feit dat het opslaan van de NVARCHAR-tekenreeks de vereiste bytes voor de VARCHAR-kolom verdubbelt, zoals weergegeven in de DATALENGTH functie resultaat hieronder:
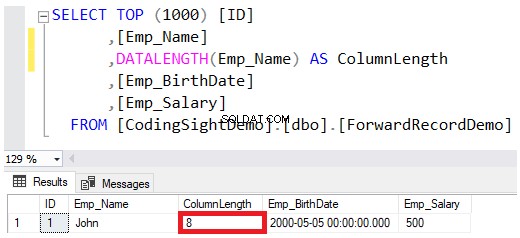
Als u de waarde van de Emp_Name-kolom wilt bijwerken om de volledige naam van de John-werknemer op te nemen, gebruikt u de onderstaande UPDATE-verklaring:
UPDATE ForwardRecordDemo SET Emp_Name='John David Micheal' WHERE Emp_Name='John'
Controleer de lengte van de bijgewerkte kolom met behulp van de DATALENGTH functie. U zult zien dat de lengte van de kolom Emp_Name in de bijgewerkte rijen is uitgebreid met 28 bytes per elke kolom, wat ongeveer 3,5 . is aanvullende gegevenspagina's aan die tabel, zoals weergegeven in het onderstaande resultaat:
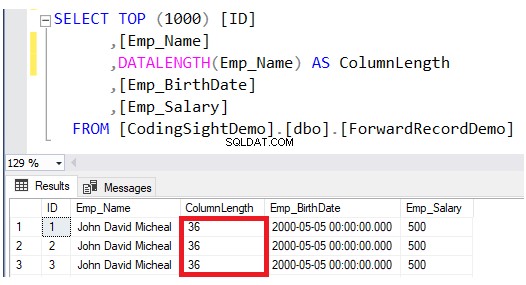
Controleer vervolgens het aantal doorgestuurde records na de update door de dynamische systeembeheerfunctie sys.dm_db_index_physical_stats op te vragen. Gebruik hiervoor het onderstaande T-SQL-script:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Zoals u kunt zien, zal het bijwerken van de kolom Emp_Name op 1K-records met grotere tekenreekswaarden, zonder een nieuw record toe te voegen, de extra 5 toewijzen pagina's naar die tabel, in plaats van 3,5 pagina's zoals eerder verwacht. Dit gebeurt door het genereren van 484 doorgestuurde records om te verwijzen naar de nieuwe locaties van de verplaatste gegevens. Dit kan ertoe leiden dat de tabel 33% . is gefragmenteerd, zoals hieronder duidelijk wordt weergegeven:

Nogmaals, als het je lukt om de waarde van de Emp_Name-kolom bij te werken met de volledige naam van de Zaid-medewerker, gebruik dan de UPDATE-verklaring hieronder:
UPDATE ForwardRecordDemo SET Emp_Name='Zaid Fuad Zreeq' WHERE Emp_Name='Zaid'
Controleer de lengte van de bijgewerkte kolom met behulp van de DATALENGTH functie. U zult zien dat de lengte van de kolom Emp_Name in de bijgewerkte rijen is uitgebreid met 22 bytes per elke kolom, wat ongeveer 2,7 . is extra gegevenspagina's toegevoegd aan die tabel, zoals weergegeven in het onderstaande resultaat:
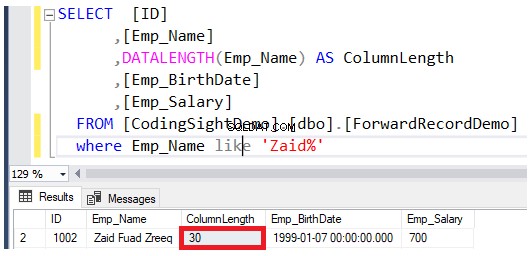
Controleer het aantal doorgestuurde records na het uitvoeren van de updatebewerking. U kunt dit doen door de functie sys.dm_db_index_physical_stats systeem dynamisch beheer op te vragen met hetzelfde T-SQL-script hieronder:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Het resultaat laat zien dat het bijwerken van de Emp_Name-kolom op de andere 1K-records met grotere tekenreekswaarden zonder een nieuwe rij in te voegen een andere 4 zal toewijzen pagina's naar die tabel, in plaats van 2,7 pagina's zoals verwacht. Dit zal gebeuren door het genereren van extra 417 doorgestuurde records om te verwijzen naar de nieuwe locaties van de verplaatste gegevens en met behoud van dezelfde 33% fragmentatiepercentage, zoals hieronder weergegeven:

Het probleem met doorgestuurde records oplossen
De eenvoudigste manier om het probleem met doorgestuurde records op te lossen, is door een schatting te maken van de maximale lengte van de tekenreeks die in de kolom wordt opgeslagen en deze toe te wijzen met behulp van de vaste lengte gegevenstype voor die kolom in plaats van het gegevenstype met variabele lengte te gebruiken. De optimale permanente manier om het probleem met doorgestuurde records op te lossen, is door de geclusterde index toe te voegen naar die tafel. Op deze manier wordt de tabel volledig geconverteerd naar een geclusterde tabel, die wordt gesorteerd op basis van de geclusterde indexsleutelwaarden. Het bepaalt de volgorde van de bestaande gegevens, de nieuw ingevoegde en bijgewerkte gegevens die niet passen in de huidige beschikbare ruimte op de gegevenspagina, zoals eerder beschreven in de inleiding van dit artikel.
Als het toevoegen van de geclusterde index aan die tabel geen optie is voor specifieke vereisten, zoals de staging-tabellen of de ETL-tabellen, kunt u het probleem met doorgestuurde records tijdelijk oplossen door de doorgestuurde records te controleren en de heaptabel opnieuw op te bouwen om deze te verwijderen. update ook alle niet-geclusterde indexen op die heaptabel. De functionaliteit van het opnieuw opbouwen van de heaptabel is geïntroduceerd in SQL Server 2008, met behulp van de ALTER TABLE...REBUILD T-SQL-opdracht.
Om de prestatie-impact van de doorgestuurde records op de gegevensophaalquery's te zien, laten we de SELECT-query uitvoeren die de zoekopdracht uitvoert op basis van de Emp_Name-kolomwaarden. Voordat u de query uitvoert, moet u echter de TIME- en IO-statistieken inschakelen:
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
Als resultaat ziet u dat 925 logische leesbewerkingen worden uitgevoerd om de gevraagde gegevens op te halen binnen 84ms zoals hieronder weergegeven:

Gebruik de opdracht ALTER TABLE...REBUILD om de heaptabel opnieuw te bouwen om alle doorgestuurde records te verwijderen:
ALTER TABLE ForwardRecordDemo REBUILD;
Voer dezelfde SELECT-instructie nogmaals uit:
SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
De TIME- en IO-statistieken laten zien dat slechts 21 logische leesbewerkingen vergeleken met de 925 logische leesbewerkingen met de doorgestuurde records inbegrepen, worden uitgevoerd om de gevraagde gegevens binnen 79ms op te halen :

Om het aantal doorgestuurde records te controleren na het opnieuw opbouwen van de heaptabel, voert u de systeemdynamisch beheerfunctie sys.dm_db_index_physical_stats uit en gebruikt u hetzelfde T-SQL-script hieronder:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Je zult zien dat alleen 21 pagina's, met de vorige 3 pagina's die worden gebruikt voor de doorgestuurde records, worden toegewezen aan die tabel om de gegevens op te slaan, wat vergelijkbaar is met het geschatte resultaat dat we hebben gekregen tijdens de bewerkingen voor het invoegen en bijwerken van gegevens (15+3.5+2.7). Nadat de heaptabel opnieuw is opgebouwd, worden alle doorgestuurde records nu verwijderd. Als resultaat hebben we een tabel zonder fragmentatie:

Het probleem met doorgestuurde records is een belangrijk prestatieprobleem waarmee databasebeheerders rekening moeten houden bij het plannen van de heap tafel onderhoud. De eerdere resultaten worden opgehaald uit onze testtabel die alleen 3K-records bevat. U kunt zich het aantal pagina's voorstellen dat zal worden verspild door de doorgestuurde records en de verslechtering van de I/O-prestaties als gevolg van het lezen van een groot aantal doorgestuurde records bij het lezen van enorme tabellen!
Referenties:
- Pages and Extents Architecture Guide
- dm_db_index_physical_stats (Transact-SQL)
- WIJZIG TABEL (Transact-SQL)
- Weten over 'doorgestuurde records' kan helpen bij het diagnosticeren van moeilijk te vinden prestatieproblemen