Er zijn meerdere methoden om slecht presterende query's in SQL Server te bekijken, met name Query Store, Extended Events en dynamische beheerweergaven (DMV's). Elke optie heeft voor- en nadelen. Extended Events biedt gegevens over de individuele uitvoering van query's, terwijl Query Store en de DMV's prestatiegegevens samenvoegen. Om Query Store en Extended Events te gebruiken, moet u ze van tevoren configureren – ofwel Query Store voor uw database(s) inschakelen of een XE-sessie opzetten en starten. DMV-gegevens zijn altijd beschikbaar, dus vaak is dit de gemakkelijkste methode om snel een eerste blik te werpen op de queryprestaties. Dit is waar Glenn's DMV-query's van pas komen - binnen zijn script heeft hij meerdere query's die u kunt gebruiken om de topquery's voor de instantie te vinden op basis van CPU, logische I/O en duur. Het is vaak een goed begin om de zoekopdrachten te targeten die veel resources verbruiken, maar we mogen het scenario 'death by a duizend cuts' niet vergeten - de zoekopdracht of reeks zoekopdrachten die HEEL vaak worden uitgevoerd - misschien honderden of duizenden keren per jaar. minuut. Glenn heeft een query in zijn set met een lijst van topquery's voor een database op basis van het aantal uitvoeringen, maar in mijn ervaring geeft het je geen volledig beeld van je werklast.
De belangrijkste DMV die wordt gebruikt om naar prestatiestatistieken voor query's te kijken, is sys.dm_exec_query_stats. Aanvullende gegevens die specifiek zijn voor opgeslagen procedures (sys.dm_exec_procedure_stats), functies (sys.dm_exec_function_stats) en triggers (sys.dm_exec_trigger_stats) zijn ook beschikbaar, maar houd rekening met een werklast die niet puur uit opgeslagen procedures, functies en triggers bestaat. Overweeg een gemengde werklast met enkele ad-hocvragen, of misschien volledig ad-hoc.
Voorbeeldscenario
Door code te lenen en aan te passen uit een vorige post, De prestatie-impact van een adhoc-werklast onderzoeken, zullen we eerst twee opgeslagen procedures maken. De eerste, dbo.RandomSelects, genereert en voert een ad hoc-statement uit, en de tweede, dbo.SPrandomSelects, genereert en voert een geparametriseerde query uit.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT c.CustomerID, c.AccountOpenedDate, COUNT(ct.CustomerTransactionID)
FROM Sales.Customers c
JOIN Sales.CustomerTransactions ct
ON c.CustomerID = ct.CustomerID
WHERE c.CustomerName = @ConcatString
GROUP BY c.CustomerID, c.AccountOpenedDate;
SELECT @RowLoop = @RowLoop + 1;
END
GO Nu zullen we beide opgeslagen procedures 1000 keer uitvoeren, met dezelfde methode als beschreven in mijn vorige bericht met .cmd-bestanden die .sql-bestanden aanroepen met de volgende instructies:
Inhoud van Adhoc.sql-bestand:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 1000;
Inhoud van het geparametriseerde.sql-bestand:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 1000;
Voorbeeldsyntaxis in .cmd-bestand dat het .sql-bestand aanroept:
sqlcmd -S WIN2016\SQL2017 -i"Adhoc.sql" exit
Als we een variant van Glenn's Top Worker Time-query gebruiken om naar de topquery's te kijken op basis van worker-time (CPU):
-- Get top total worker time queries for entire instance (Query 44) (Top Worker Time Queries) SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.total_worker_time AS [Total Worker Time], qs.execution_count AS [Execution Count], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);
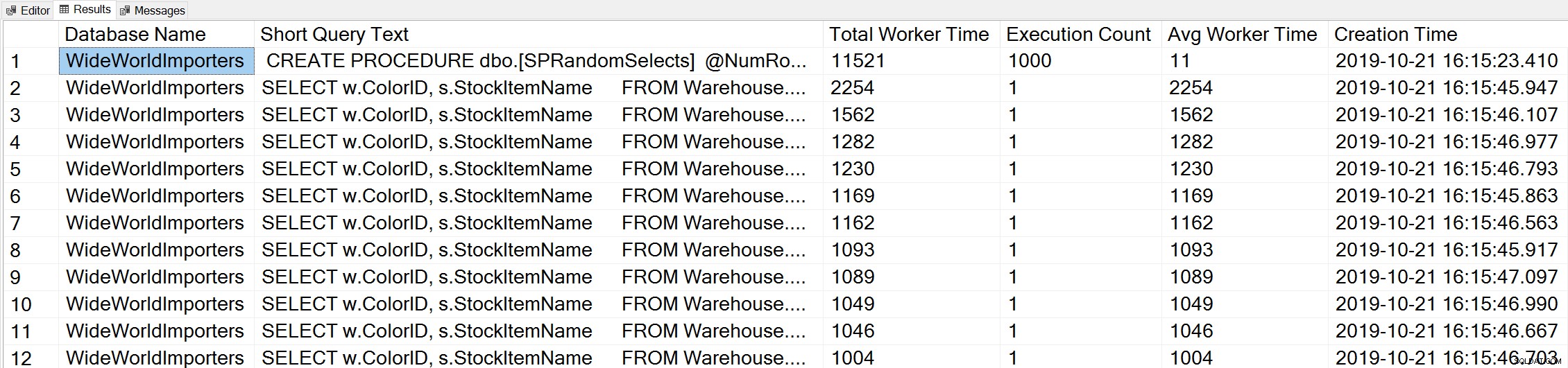
We zien de instructie van onze opgeslagen procedure als de query die wordt uitgevoerd met de hoogste hoeveelheid cumulatieve CPU.
Als we een variatie van Glenn's Query Execution Counts-query uitvoeren op de WideWorldImporters-database:
USE [WideWorldImporters]; GO -- Get most frequently executed queries for this database (Query 57) (Query Execution Counts) SELECT TOP(50) LEFT(t.[text], 50) AS [Short Query Text], qs.execution_count AS [Execution Count], qs.total_logical_reads AS [Total Logical Reads], qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads], qs.total_worker_time AS [Total Worker Time], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.total_elapsed_time AS [Total Elapsed Time], qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp WHERE t.dbid = DB_ID() ORDER BY qs.execution_count DESC OPTION (RECOMPILE);
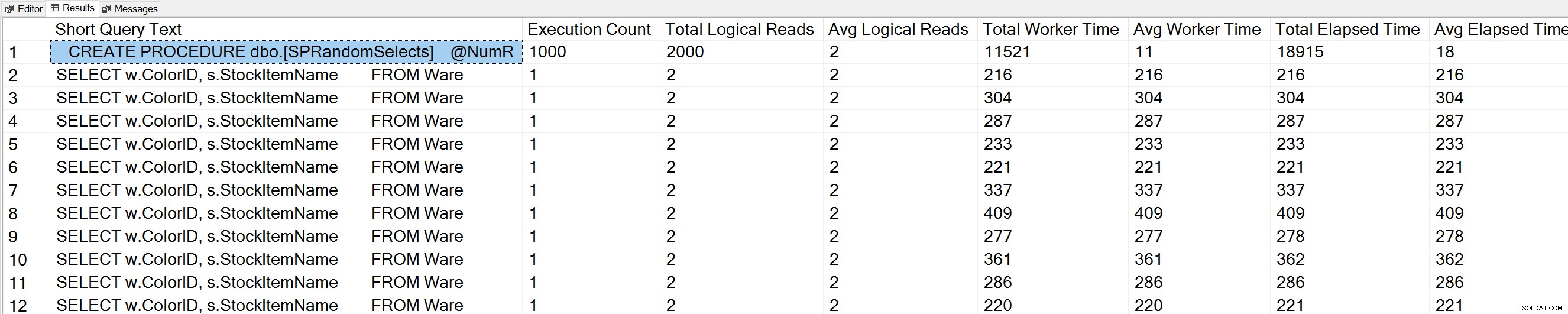
We zien ook onze opgeslagen procedureverklaring bovenaan de lijst.
Maar de ad-hocquery die we uitvoerden, hoewel deze verschillende letterlijke waarden heeft, was in wezen hetzelfde instructie herhaaldelijk uitgevoerd, zoals we kunnen zien door te kijken naar de query_hash:
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.query_hash AS [query_hash], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY [Short Query Text];
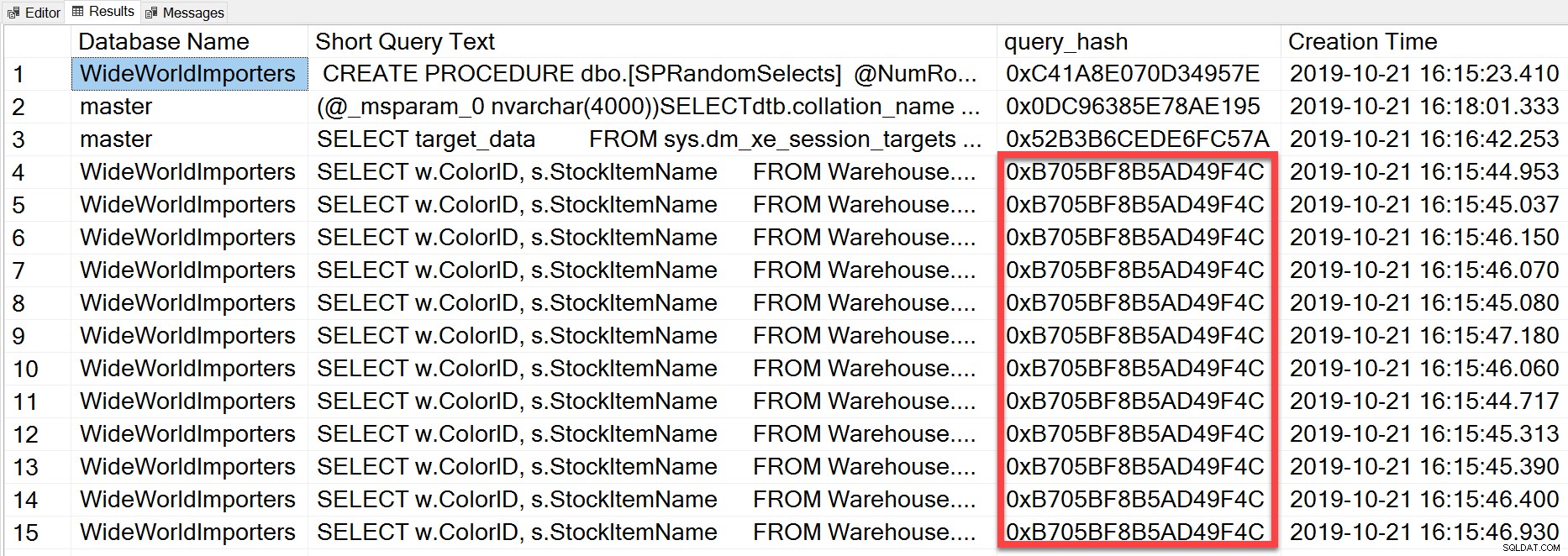
De query_hash is toegevoegd in SQL Server 2008 en is gebaseerd op de boomstructuur van de logische operators die door de Query Optimizer voor de instructietekst worden gegenereerd. Query's met een vergelijkbare instructietekst die dezelfde boom van logische operators genereren, hebben dezelfde query_hash, zelfs als de letterlijke waarden in het querypredikaat anders zijn. Hoewel de letterlijke waarden kunnen verschillen, moeten de objecten en hun aliassen hetzelfde zijn, evenals queryhints en mogelijk de SET-opties. De opgeslagen procedure RandomSelects genereert query's met verschillende letterlijke waarden:
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1005451175198';
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1006416358897'; Maar elke uitvoering heeft exact dezelfde waarde voor de query_hash, 0xB705BF8B5AD49F4C. Om te begrijpen hoe vaak een ad-hocquery – en die welke hetzelfde zijn in termen van query_hash – wordt uitgevoerd, moeten we groeperen op de query_hash-volgorde op die telling, in plaats van te kijken naar uitvoeringsaantal in sys.dm_exec_query_stats (die vaak een waarde van 1).
Als we de context wijzigen in de WideWorldImporters-database en zoeken naar topquery's op basis van het aantal uitvoeringen, waarbij we groeperen op query_hash, kunnen we nu zowel de opgeslagen procedure en zien onze ad-hocvraag:
;WITH qh AS
(
SELECT TOP (25) query_hash, COUNT(*) AS COUNT
FROM sys.dm_exec_query_stats
GROUP BY query_hash
ORDER BY COUNT(*) DESC
),
qs AS
(
SELECT obj = COALESCE(ps.object_id, fs.object_id, ts.object_id),
db = COALESCE(ps.database_id, fs.database_id, ts.database_id),
qs.query_hash, qs.query_plan_hash, qs.execution_count,
qs.sql_handle, qs.plan_handle
FROM sys.dm_exec_query_stats AS qs
INNER JOIN qh ON qs.query_hash = qh.query_hash
LEFT OUTER JOIN sys.dm_exec_procedure_stats AS [ps]
ON [qs].[sql_handle] = [ps].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_function_stats AS [fs]
ON [qs].[sql_handle] = [fs].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_trigger_stats AS [ts]
ON [qs].[sql_handle] = [ts].[sql_handle]
)
SELECT TOP (50)
OBJECT_NAME(qs.obj, qs.db),
query_hash,
query_plan_hash,
SUM([qs].[execution_count]) AS [ExecutionCount],
MAX([st].[text]) AS [QueryText]
FROM qs
CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st]
CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp]
GROUP BY qs.obj, qs.db, qs.query_hash, qs.query_plan_hash
ORDER BY ExecutionCount DESC;

Opmerking:de DMV sys.dm_exec_function_stats is toegevoegd in SQL Server 2016. Als u deze query uitvoert op SQL Server 2014 en eerder, moet de verwijzing naar deze DMV worden verwijderd.
Deze uitvoer biedt een veel uitgebreider begrip van welke query's echt het vaakst worden uitgevoerd, omdat deze wordt geaggregeerd op basis van de query_hash, niet door simpelweg te kijken naar de uitvoeringstelling in sys.dm_exec_query_stats, die meerdere items voor dezelfde query_hash kan hebben wanneer verschillende letterlijke waarden zijn gebruikt. De query-uitvoer bevat ook query_plan_hash, die verschillend kan zijn voor query's met dezelfde query_hash. Deze aanvullende informatie is handig bij het evalueren van de planprestaties voor een query. In het bovenstaande voorbeeld heeft elke query dezelfde query_plan_hash, 0x299275DD475C4B17, wat aantoont dat zelfs met verschillende invoerwaarden, de Query Optimizer hetzelfde plan genereert - het is stabiel. Als er meerdere query_plan_hash-waarden bestaan voor dezelfde query_hash, bestaat er planvariabiliteit. In een scenario waarin dezelfde query, op basis van query_hash, duizenden keren wordt uitgevoerd, is een algemene aanbeveling om de query te parametriseren. Als u kunt controleren of er geen planvariabiliteit bestaat, verwijdert het parametreren van de query de optimalisatie- en compilatietijd voor elke uitvoering en kan de algehele CPU worden verminderd. In sommige scenario's kan het parametriseren van vijf tot tien ad-hocquery's de systeemprestaties als geheel verbeteren.
Samenvatting
Voor elke omgeving is het belangrijk om te begrijpen welke query's het duurst zijn in termen van resourcegebruik en welke query's het vaakst worden uitgevoerd. Bij gebruik van Glenn's DMV-script kan dezelfde reeks zoekopdrachten worden weergegeven voor beide soorten analyse, wat misleidend kan zijn. Daarom is het belangrijk om vast te stellen of de werklast voornamelijk procedureel, meestal ad hoc of een mix is. Hoewel er veel gedocumenteerd is over de voordelen van opgeslagen procedures, vind ik dat gemengde of zeer ad-hocworkloads heel gebruikelijk zijn, vooral bij oplossingen die object-relationele mappers (ORM's) gebruiken, zoals Entity Framework, NHibernate en LINQ to SQL. Als u onduidelijk bent over het type werkbelasting voor een server, is het een goed begin om de bovenstaande query uit te voeren om de meest uitgevoerde query's te bekijken op basis van een query_hash. Naarmate je de werklast begint te begrijpen en wat er bestaat voor zowel de zware slagmensen als de dood door duizend bezuinigingsquery's, kun je verder gaan met het echt begrijpen van het gebruik van bronnen en de impact die deze vragen hebben op de systeemprestaties, en je inspanningen richten op afstemming.