Het maakt niet uit aan welke kant van de vergelijking je staat, soms is het moeilijk om een gekwalificeerd persoon te vinden voor een specifieke baan. In dit bericht kijken we naar een datamodel om recruiters en HR-afdelingen te helpen georganiseerd te blijven tijdens het wervingsproces.
De meesten van ons zijn betrokken geweest bij het wervingsproces, meestal als sollicitant. We kunnen echter ook betrokken raken aan de wervingskant, misschien door de technische kennis van de sollicitant te testen. Het wervingsproces kost een bepaalde hoeveelheid tijd en de groep sollicitanten wordt steeds kleiner naarmate we dichter bij de definitieve beslissing komen. Het resultaat zou de selectie van de beste persoon voor de baan moeten zijn.
Werven op zich is behoorlijk ingewikkeld, dus we zullen een vrij uitgebreid datamodel bespreken om alle aspecten van het proces te dekken. Leun achterover in uw stoel en geniet van het artikel van vandaag!
Hoe het wervingsproces werkt
De meeste onderdelen van het wervingsproces zijn algemeen bekend, maar we zullen precies bespreken hoe het werkt voordat we verder gaan met het datamodel.
-
Een behoefte detecteren
Dit is een absolute must in het recruitmentproces; er vindt geen proces plaats als het management niet op de hoogte is van de noodzaak om een nieuwe medewerker in dienst te nemen. Die behoefte kan het gevolg zijn van het starten van een nieuw bedrijf, groei in een bestaand bedrijf of het vertrek van een huidige medewerker.
Tenzij een bedrijf strikt gedefinieerde functies heeft (bijvoorbeeld banken), is het niet altijd gemakkelijk om te bepalen wanneer een nieuwe medewerker moet worden aangenomen. Praten met werknemers en veel overuren zien, kan een nieuwe aanwerving stimuleren. Interne of externe regelgeving kan ook vereisen dat bepaalde functies alleen worden gegeven aan mensen met een specifieke vaardigheden en relevante werkervaring (bijvoorbeeld interne revisor).
-
De functie en de vereiste vaardigheden schetsen
Om een idee te krijgen van deze stap, denk aan een echt goed geschreven functiebeschrijving. Het bevat:
- Een lijst met alle taken die verband houden met de baan
- Minimale opleidings- en werkervaringskwalificaties
- Specifieke vaardigheden die essentieel zijn voor functies
- Aanvullende of geprefereerde vaardigheden
- Een samenvatting van wat de werkgever van de sollicitant verwacht en wat de sollicitant van deze baan mag verwachten
- Een salarisbereik en misschien een pakket voordelen
Deze informatie is belangrijk voor zowel recruiters als sollicitanten. Het heeft geen zin om tien kandidaten uit te nodigen voor het selectieproces als geen van hen tevreden zal zijn met het financiële aanbod. En hoe gedetailleerder de functiebeschrijving, hoe gemakkelijker het zal zijn om gekwalificeerde kandidaten aan te trekken.
-
Bepalen wie het proces zal beheren en wanneer elke taak moet plaatsvinden
De volgende stap is het definiëren van specifieke datums waarop elk onderdeel van het proces zal plaatsvinden. Bedrijven kunnen ook werknemers aan elke stap toewijzen. Als het bedrijf een afdeling Human Resources heeft, zal deze waarschijnlijk elk onderdeel van het wervingsproces beheren, hoewel andere werknemers indien nodig hun specifieke kennis kunnen inbrengen (als we bijvoorbeeld een IT-specialist inhuren, moet de manager van de IT-afdeling kandidaten beoordelen ' technische vaardigheden).
Als er geen HR-afdeling is, kunnen we verwachten dat leidinggevend personeel het proces zal leiden. In kleine en middelgrote bedrijven is dit niet alleen nodig, maar ook gewenst.
-
De vacature plaatsen
Nu zijn we klaar om een functiebeschrijving op onze site, op vacaturesites of aggregators of in een krant te plaatsen. De vacaturetekst moet de opsommingstekens bevatten die in stap 2 worden genoemd. Dit zal potentiële kandidaten helpen beslissen of ze willen solliciteren op de functie. Het is essentieel om de functiebeschrijving nauwkeurig te maken; we hebben allemaal onze tijd verspild aan sollicitatiegesprekken voor een baan die niet voldeed aan de beschrijving of onze verwachtingen.
-
Kandidaten selecteren, testen en interviewen
Na afloop van de sollicitatieperiode worden de sollicitanten met de meest relevante vaardigheden en ervaring uitgenodigd voor een eerste evaluatiefase (meestal een gesprek of test). De andere sollicitanten worden geïnformeerd dat ze niet zijn geselecteerd voor de functie. Een groot bedrijf moet een vooraf bepaald minimumaantal kandidaten uitnodigen voor de eerste evaluatie. Dit scheelt tijd voor zowel de sollicitant als het bedrijf.
Kleine en middelgrote bedrijven kunnen besluiten het proces voort te zetten totdat ze de beste match hebben gevonden. In dergelijke gevallen blijft de sollicitatieperiode open totdat de juiste kandidaat is gevonden en worden alle andere data gaandeweg bepaald.
Het interview- en testproces is afhankelijk van de bedrijfsgrootte en organisatie. In grote bedrijven met HR-afdelingen zal er waarschijnlijk een reeks tests zijn om de beroepsvaardigheden van sollicitanten te controleren. Andere tests kunnen psychologische en persoonlijkheidskenmerken meten om de match tussen sollicitant, sollicitant en bedrijf of zelfs het gezond verstand van de sollicitant te bepalen.
Deze tests zullen meestal in verschillende stappen worden verdeeld en elke stap zal het aantal aanvragers verminderen.
-
Het laatste interview
Deze stap zal waarschijnlijk een interview zijn met de beste sollicitanten. Het is de belangrijkste stap in het proces omdat de sollicitanten voor zichzelf kunnen spreken, hun bekwaamheid en persoonlijkheid kunnen aantonen en kunnen bepalen of het bedrijf en de functie goed bij hen passen. Na deze stap ontvangt de beste sollicitant een offerte. Als ze accepteren, is het wervingsproces voor die functie voorbij. Als de sollicitant de jobaanbieding weigert, zal het bedrijf een aanbod doen voor de volgende keuze.
-
Zijn er verschillen in het wervingsproces voor kleine, middelgrote en grote bedrijven? Hoe gaan we ze oplossen in ons model?
Er zullen bepaalde verschillen zijn in de wervingsprocessen van kleine, middelgrote en grote bedrijven. Bovendien zal het proces variëren afhankelijk van de posities die worden aangeworven. Bedenk hoe verschillend de vereiste vaardigheden en ervaringen zijn voor een contentmanager, een ornitholoog en een kapitein van een cruiseschip. Sommige banen hebben meer tests en interviews, andere hebben er misschien maar een paar. Maar uiteindelijk komt het allemaal neer op het krijgen van de juiste antwoorden en het rangschikken van sollicitanten.
In dit model behandel ik alle tests en interviews op dezelfde manier. We slaan de antwoorden van elke sollicitant op, koppelen deze aan de relevante vraag en slaan de score van de sollicitant op voor elke stap van het proces.
-
Wie kan dit datamodel gebruiken?
Dit model is zeer specifiek en mag alleen worden gebruikt voor het wervingsproces. Maar het is niet beperkt tot HR-afdelingen; je zou dit model ook kunnen gebruiken om een professionele wervingsservice te runnen.
-
Het gegevensmodel
Het datamodel bestaat uit vijf hoofdonderwerpen:
JobsApplicants, Recruiters and DocumentsApplicationsTest detailsApplication tests
Ik zal elk onderwerp afzonderlijk beschrijven, in dezelfde volgorde waarin ze worden vermeld.
Sectie 1:Banen
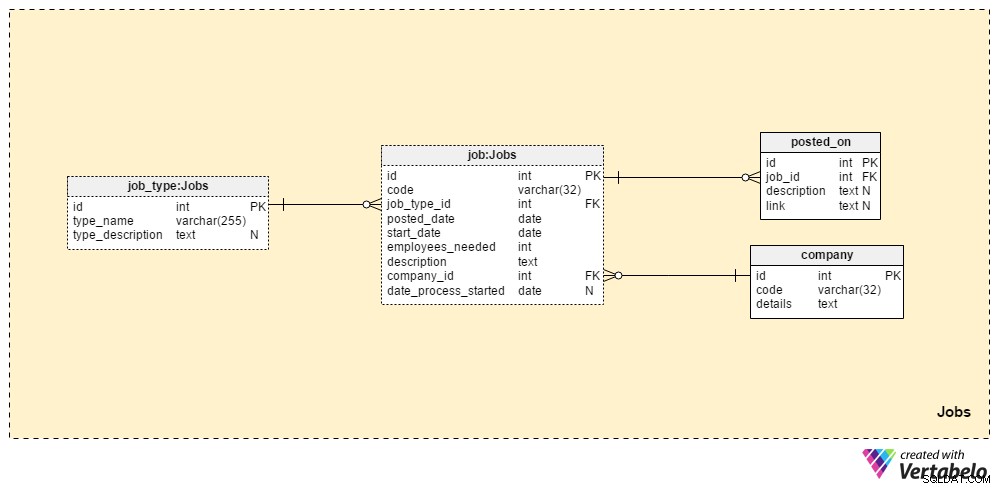
De Jobs sectie zal alle details opslaan voor alle posities die we ooit hebben gepost. De twee woordenboektabellen, het company tabel en de job_type tabel, maken deel uit van de initiële setup. De overige twee tabellen, job en posted_on , bevatten "echte" gegevens met betrekking tot vacatures.
De job_type woordenboek bevat een lijst met verschillende en UNIEKE jobtypes. We kunnen waarden verwachten als “senior database administrator” of 'IT-journalist' op te slaan in de type_name attribuut. De type_description attribuut kan een meer gedetailleerde beschrijving van de taak opslaan.
Het company woordenboek bevat een lijst van alle bedrijven waarmee we samenwerken. Als we alleen werknemers voor ons bedrijf aannemen, zal dit woordenboek alleen onze bedrijfsnaam bevatten. Als we een wervingsbureau zijn, slaat het de namen op van elk bedrijf dat ons heeft aangenomen.
Een lijst van alle vacatures die we ooit hebben geplaatst, wordt opgeslagen in de tabel "vacature". De kenmerken in deze tabel zijn:
code– Onze interne UNIEKE ID werd gebruikt om een baan aan te duiden.job_type_id– Verwijst naar het gerelateerde taaktype.posted_date– De datum waarop deze vacature is geplaatst.start_date– De verwachte startdatum (eerste werkdag) voor die baan.employees_needed– Het aantal medewerkers dat we willen aannemen tijdens dit wervingsproces. Meestal heeft dit een waarde van "1", maar in sommige gevallen - b.v. bij het starten van een nieuw bedrijf of het opzetten van een nieuwe afdeling - we kunnen grotere waarden verwachten.description– Een gedetailleerde beschrijving van die functie. Dit is de plaats waar we alle vereiste, geprefereerde en gewenste beroepsvaardigheden zullen opsommen.company_id– Verwijst naar de ID van het bedrijf dat ons heeft ingehuurd. Als we een wervingsbureau zijn, verwijst dit naar een bedrijfsnaam die is opgeslagen in hetcompanytafel. Anders wordt het de ID van ons eigen bedrijf.date_process_started– De startdatum van het wervingsproces. Dit kan NULL zijn als we toekomstige stappen en acties met betrekking tot deze taak moeten definiëren.
De laatste tabel in dit onderwerpgebied is de posted_on tafel. Voor elke job_id , slaan we een link op naar de vacature en de bijbehorende description . We kunnen deze gegevens gebruiken om erachter te komen waar de sollicitanten onze vacatures vinden.
Sectie 2:Sollicitanten, recruiters en documenten
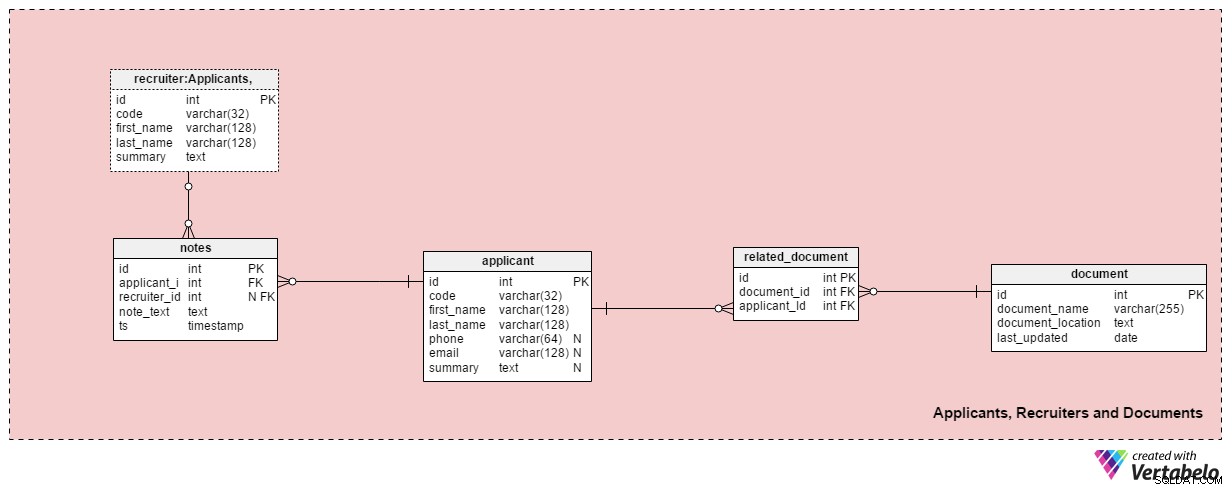
Dit onderwerpgebied bevat alle tabellen die nodig zijn om informatie over recruiters, sollicitanten en hun gerelateerde documenten op te slaan.
De applicant tabel bevat alle sollicitanten waarmee we ooit contact hebben gehad. Elke aanvrager is UNIEK gedefinieerd in ons systeem met een "code". Daarnaast bewaren we de voor- en achternaam van elke sollicitant, phone nummer, email adres, en hun summary . Deze tafel kan worden aangepast voor specifieke behoeften, b.v. extra telefoonnummers, e-mails of fysieke adressen toevoegen.
We zullen sollicitanten in verband brengen met beschikbare documenten. Een lijst van alle beschikbare documenten (cv of cv, diploma's of diploma's, transcripties, certificeringen, enz.) wordt opgeslagen in het document tafel. Voor elk document slaan we de naam op in het systeem, de locatie en het tijdstip van de meest recente update.
We koppelen aanvragers aan documenten met behulp van het related_document tafel. Het bevat slechts twee externe sleutels, die de document_id . vormen – applicant_id UNIEK paar.
De recruiter tabel geeft een overzicht van de werknemers die kunnen worden toegewezen aan een sollicitatie of die aantekeningen maken met betrekking tot een sollicitant. Elke recruiter wordt UNIEK gedefinieerd door haar of zijn code . We slaan alleen basisgegevens op, zoals first_name , last_name en de summary . van de recruiter .
De laatste tabel in dit onderwerpgebied zijn de notes tafel. Hier slaan we alle notities op die betrekking hebben op een sollicitant. We kunnen notities opslaan zoals 'Aanvrager heeft de vergadering gemist' of 'Sollicitant deed het uitstekend tijdens het eerste gesprek' . Voor elke notitie slaan we de ID op van de recruiter die die notitie heeft gemaakt, de ID van de gerelateerde sollicitant, de note_text , en het tijdstempel waarop de notitie is gemaakt.
Sectie 3:Testdetails
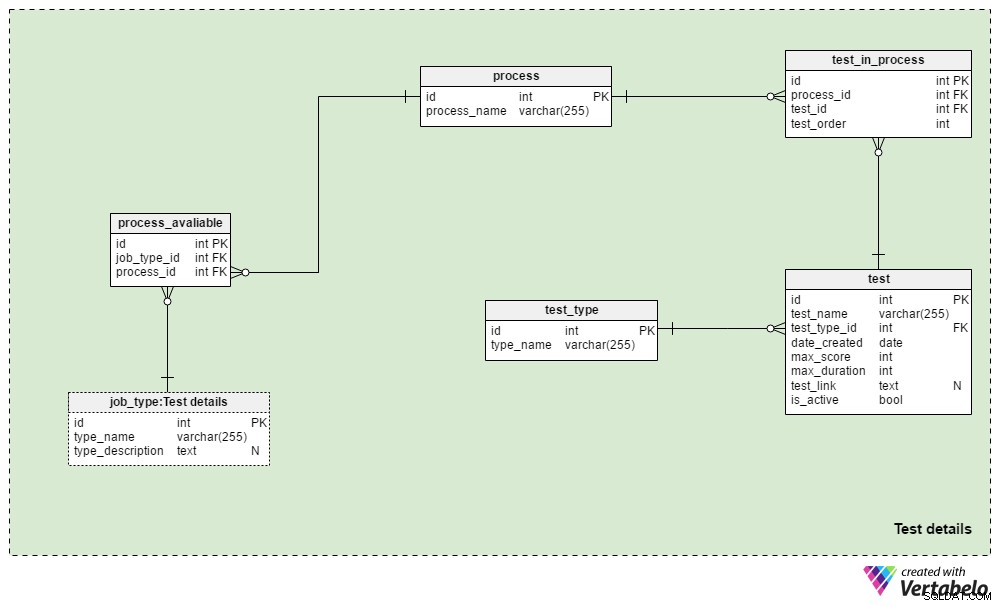
De Test details onderwerpgebied bevat de tabellen die worden gebruikt om wervingsprocessen te definiëren en de tests die tijdens deze processen worden gebruikt. Over het algemeen gebruiken we altijd hetzelfde selectieproces voor hetzelfde type functie:wijzigingen worden alleen aangebracht als de zakelijke omstandigheden dat vereisen. We zouden een paar verschillende processen voor elk taaktype kunnen gebruiken, en we zullen vrijwel zeker hetzelfde proces gebruiken voor verschillende taaktypen.
Het process tabel is een eenvoudig woordenboek met alleen een UNIEKE process_name attribuut. Het geeft een overzicht van alle wervingsprocessen die we ooit hebben gebruikt en momenteel gebruiken.
We brengen processen in verband met verschillende soorten banen. We slaan deze relaties op in de process_available tafel. De enige attributen zijn het UNIEKE paar job_type_id – process_id . Als er meerdere processen beschikbaar zijn voor een functietype, kan de recruiter er een kiezen.
De test_in_process tabel wordt gebruikt om de volgorde van tests tijdens dat proces te definiëren. De kenmerken in deze tabel zijn:
process_identest_id– Verwijst naar het gerelateerde proces en de test.test_order– Het volgnummer van die test of stap in het proces. Samen metprocess_id, dit vormt de UNIEKE sleutel van de tabel. We kunnen tijdens het proces maar één stap tegelijk uitvoeren.
De test tabel bevat alle tests die momenteel en eerder zijn gebruikt in het wervingsproces. We zullen cv-reviews en interviews ook als tests beschouwen. Hoewel ze geen vragen en antwoorden hoeven te definiëren, maken ze deel uit van een evaluatie. Voor elke test slaan we op:
test_name– Een UNIEKE aanduiding voor elke test.test_type_id– Verwijst naar hettest_typewoordenboek.date_created– De datum waarop we deze test in ons systeem hebben gemaakt.max_score– De maximaal haalbare score voor deze test. Deze waarde is de som van alle juiste antwoorden op deze test of het hoogste cijfer dat recruiters kunnen geven aan een cv of interview.max_duration– Hoe lang (in minuten) de kandidaat heeft om de test te voltooien.test_link– Bevat een link naar de testlocatie. Deze waarde kan NULL zijn als we geen test gebruiken in het proces.is_active– Geeft aan of we deze test momenteel gebruiken.
We hebben het test_type woordenboek. Het bevat alle UNIEKE testnamen op formaat, b.v. “CV-beoordeling” , “online vaardigheidstest” , "papieren vaardigheidstest" en “interview” .
Dit model bevat niet de structuur die nodig is om toetsvragen en antwoorden op te slaan. Het slaat eerder een link op naar de locaties die deze informatie bevatten. Hetzelfde ontwerp wordt gebruikt in de Applications gebied.
Sectie 4:Toepassingen
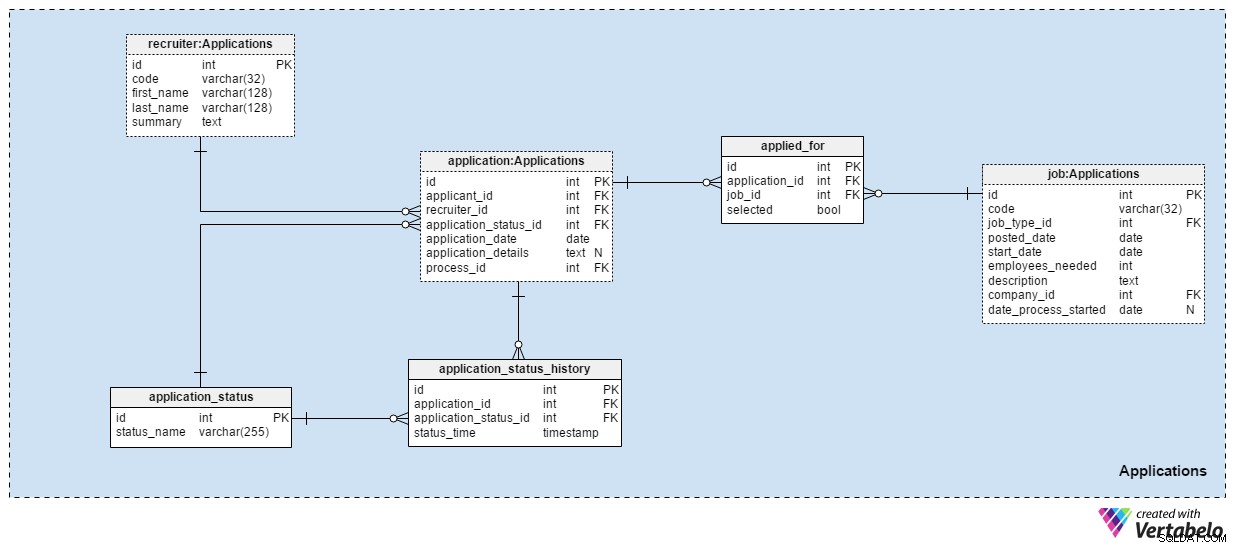
De Applications vakgebied is waarschijnlijk het belangrijkste in dit datamodel. Alle andere tot nu toe genoemde vakgebieden beschreven toepassingen. Deze bewaart de echte dingen.
Elke aanvraag die we ooit hebben ontvangen, wordt vastgelegd in de application tafel. Voor elke sollicitatie slaan we de gerelateerde ID van de sollicitant, de ID van de recruiter en een verwijzing naar de huidige status van die sollicitatie op. We werken deze status bij op hetzelfde moment dat we een nieuwe invoer maken in de application_status_history tafel. De application_date attribuut wordt gebruikt om de relevante datum op te slaan, terwijl alle aanvullende details in tekstformaat worden opgeslagen. De process_id attribuut slaat een verwijzing op naar het proces dat voor die toepassing is geselecteerd.
Aanvragen veranderen in de loop van de tijd van status. Een lijst met alle applicatiestatussen wordt opgeslagen in de application_status woordenboek. Het enige kenmerk is status_name en het kan alleen UNIEKE waarden bevatten. Verwachte waarden zijn:"toegepast" , "CV beoordeeld" , "gekozen voor de test" , "afgewezen na CV beoordeling" , "geslaagd voor de test" , "uitgenodigd voor een interview" en "beëindigd door sollicitant" .
We slaan alle aanvraagstatussen op in de application_status_history tafel. Deze tabel bevat verwijzingen naar de application tabel en de application_status woordenboek. We bewaren ook de exacte status_time wanneer deze status aan de applicatie is toegekend. De application_id – status_time paar vormt de UNIEKE sleutel van deze tabel.
In de meeste gevallen solliciteert een sollicitant voor slechts één functie met één sollicitatie. Het is mogelijk dat een sollicitant voor meer dan één functie solliciteert en wij zullen tijdens het selectieproces de meest geschikte rol voor hem kiezen. In de applied_for tabel, slaan we het UNIEKE paar application_id op – job_id . We registreren ook of de aanvrager die bij die aanvraag betrokken was, selected was voor die functie. We kunnen verwachten dat alle selected waarden worden ingesteld op “False” aan het begin van het selectieproces en dat we er slechts één per elke vacature bijwerken naar “True” .
Sectie 5:Toepassingstests
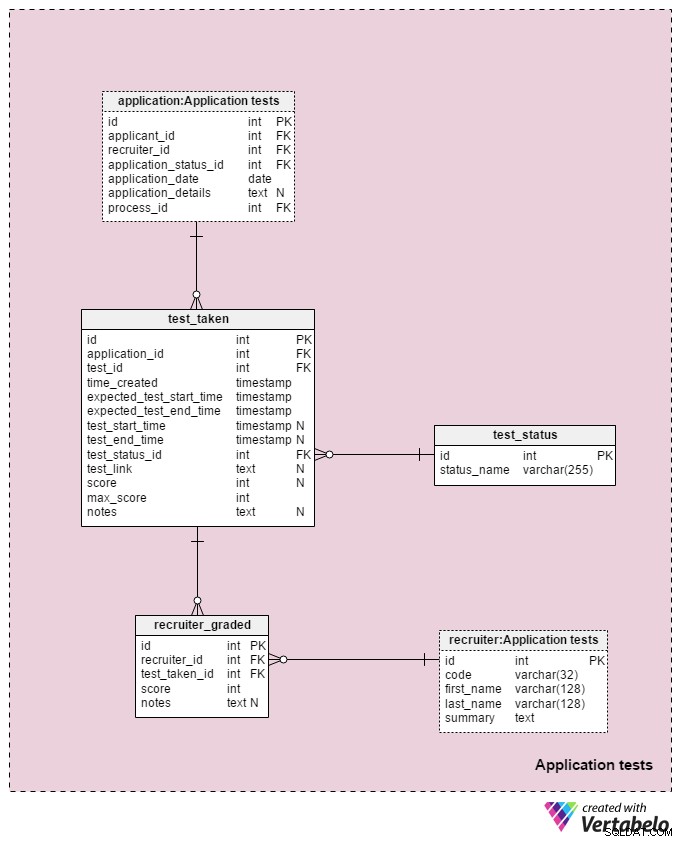
Het laatste vakgebied in ons model zal worden gebruikt om de resultaten van elke test die tijdens het selectieproces is afgenomen, op te slaan. Twee tabellen die in dit onderwerpgebied worden gebruikt, zijn kopieën uit andere onderwerpgebieden:application en recruiter . Ze worden hier gebruikt om het model te vereenvoudigen.
Alle details met betrekking tot elke test worden opgeslagen in de test_taken tafel. Deze tabel bevat ook alle andere stappen in het proces die kunnen worden beoordeeld, zoals een cv-beoordeling. De kenmerken in deze tabel zijn:
application_id– Verwijst naar deapplicationtafel. Dit betreft een toets met de sollicitant die die toets heeft gemaakt.test_id– Verwijst naar detestcatalogus. We kunnen ook verwijzen naar detest_in_processtabel hier, die ons meer informatie zou geven over de afgelegde test. Ik heb besloten dat niet te doen omdat deze structuur ons meer flexibiliteit geeft. (Bijvoorbeeld als we kandidaten willen toestaan om een test twee keer of buiten de gebruikelijke tijden af te leggen).time_created– De werkelijke tijd dat we deze test in ons systeem hebben ingevoerd.expected_test_start_timeenexpected_test_end_time– De start- en eindtijden, zoals besproken met de aanvrager. We kunnen deze waarden wijzigen voor het geval de sollicitant of de recruiter de test moet uitstellen.test_start_timeentest_end_time–De werkelijke start- en eindtijden voor de test. Deze zullen NULL-waarden bevatten wanneer de test wordt gemaakt; waarden worden bijgewerkt wanneer de aanvrager deze test start en beëindigt.test_status_id– Verwijst naar detest_statuswoordenboek.test_link– Links naar de toets met de antwoorden van de sollicitant. Het wordt bijgewerkt wanneer de aanvrager de test indient.score– de score van de aanvrager op die test. Dit wordt ofwel handmatig bepaald door een recruiter (bijvoorbeeld voor een cv-review) of automatisch (de som van alle testitemscores). Het kan ook een NULL-waarde bevatten voor tests die niet worden gescoord of beoordeeld op een vooraf gedefinieerde schaal. Bovendien kan een test die is gepland maar nog niet is voltooid een NULL-waarde hebben.max_score– De maximaal haalbare score van de test. Dit is hetzelfde als de waarde die is opgeslagen in detest.”max_scoreattribuut. Ik wil die waarde behouden omdat de recruiter de test kan wijzigen terwijl deze wordt gegeven en daardoor de maximale score die kan worden behaald, kan wijzigen.notes– Eventuele aanvullende opmerkingen of opmerkingen die door recruiters zijn ingevoerd met betrekking tot die specifieke test.
De combinatie van de test_id – application_id – expected_test_start_time attributen vormt de UNIEKE sleutel van deze tabel. Voordat we een nieuwe testsessie toevoegen, moeten we nog steeds controleren op overlappende testintervallen voor de gerelateerde sollicitant en alle gerelateerde recruiters.
De test_status woordenboek bevat een lijst van elke UNIEKE status_name die aan een test kunnen worden toegewezen. Enkele verwachte waarden zijn:"niet gestart" , "in uitvoering" , "voltooid" , "niet succesvol voltooid" , "uitgesteld" , "geannuleerd" en "aanvrager geannuleerd" .
De laatste tabel in ons model is de recruiter_graded tabel, waarin alle cijfers zijn opgeslagen die recruiters hebben gegeven bij het beoordelen van elke test. Daarom slaan we referenties op naar de recruiter en test_taken tafels. We slaan ook de score op behaald evenals alle notes . Deze informatie is erg belangrijk, vooral wanneer we tests handmatig beoordelen (d.w.z. voor cv-reviews en interviews).
Vandaag hebben we een datamodel besproken dat bijna elke situatie in het selectie- en wervingsproces kan dekken, inclusief ongebruikelijke uitzonderingen.
De meesten van ons hebben enige expertise met dit onderwerp. Deel je ervaring in de rol van recruiter of aan de andere kant van het bureau. Dekt dit model de situaties waarmee u te maken kreeg? Zo niet, welke wijzigingen zou u voorstellen?