Levensverzekeringen hopen we allemaal niet nodig te hebben, maar zoals we weten, is het leven onvoorspelbaar. In dit artikel richten we ons op het formuleren van een datamodel dat een levensverzekeringsmaatschappij kan gebruiken om zijn informatie op te slaan.
Levensverzekering als concept
Voordat we het eigenlijke datamodel voor een levensverzekeringsmaatschappij gaan bespreken, zullen we onszelf kort herinneren aan wat verzekering is en hoe het werkt, zodat we een beter idee hebben van waar we mee werken.
Verzekeren is een vrij oud concept dat al voor de middeleeuwen dateert, toen veel gilden polissen aanbood om hun leden in onverwachte situaties te beschermen. Zelfs de beroemde astronoom, wiskundige, wetenschapper en uitvinder Edmund Halley hield zich bezig met verzekeringen en werkte aan statistieken en sterftecijfers die de ruggengraat vormden van moderne verzekeringsmodellen.
Waarom zou je moeten betalen voor een verzekering? Het idee is vrij eenvoudig:u betaalt een bepaald bedrag (de premie) in ruil voor de garantie van de verzekeringsmaatschappij dat u of uw gezin financieel wordt gecompenseerd als er iets onverwachts met u of uw eigendom gebeurt. Bij een levensverzekering wijst u een begunstigde aan die bij uw overlijden een geldbedrag (de uitkering) krijgt. Het idee is dat dit geld hen zal helpen te herstellen van hun verlies, vooral als uw overlijden financiële problemen veroorzaakt.
Natuurlijk betalen verzekeringsmaatschappijen doorgaans veel minder aan uitkeringen dan ze verdienen aan premies en aan het beleggen van uw geld in, laten we zeggen, de aandelenmarkt. Anders zouden ze failliet gaan en zou het hele systeem uit elkaar vallen!
Dat is zo'n beetje de kern ervan. Nu we dat uit de weg hebben geruimd, gaan we verder en gaan we kijken naar het datamodel voor een typische levensverzekeringsmaatschappij.
Het gegevensmodel:overzicht
Het datamodel waarmee we gaan werken bestaat uit vijf vakgebieden:
- Werknemers
- Producten
- Klanten
- Aanbiedingen
- Betalingen
We zullen elk van deze secties gedetailleerder behandelen, in de volgorde waarin ze hierboven worden vermeld.
Onderwerpgebied #1:Werknemers
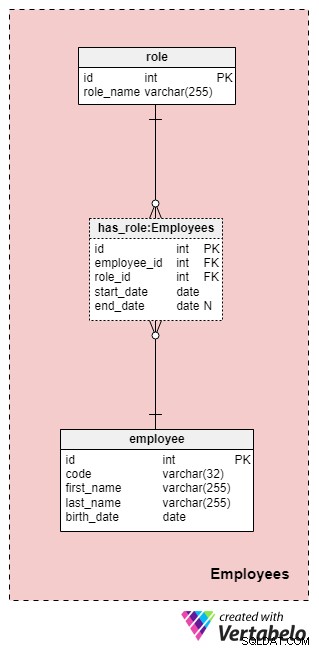
Dit gebied is niet per se specifiek voor dit gegevensmodel, maar is nog steeds erg belangrijk omdat naar de tabellen in dit document wordt verwezen door andere onderwerpgebieden. Voor de doeleinden van ons gegevensmodel voor verzekeringsmaatschappijen moeten we natuurlijk weten wie welke actie heeft uitgevoerd (bijvoorbeeld wie ons bedrijf vertegenwoordigde bij het werken met de klant/klant, wie de polis heeft ondertekend, enzovoort).
De lijst met alle medewerkers van het bedrijf wordt opgeslagen in de employee tafel. Voor elke medewerker slaan we de volgende informatie op:
code— een unieke sleutel die een enkele werknemer identificeert. Aangezien de code zal worden gebruikt als een attribuut in andere tabellen, zal het dienen als een alternatieve sleutel in deze tabel.first_nameenlast_name— respectievelijk de voor- en achternaam van de werknemer.birth_date— de geboortedatum van de werknemer.
Natuurlijk zouden we in deze tabel zeker nog veel andere werknemersgerelateerde attributen kunnen opnemen, maar deze vier zijn voorlopig meer dan genoeg. We zullen dit patroon in het hele artikel volgen en proberen de zaken zo eenvoudig mogelijk te houden, maar houd er rekening mee dat u dit gegevensmodel zeker kunt uitbreiden met aanvullende informatie.
Aangezien werknemers hun rol in ons bedrijf op elk moment kunnen veranderen, hebben we een woordenboektabel nodig om de bedrijfsrollen weer te geven en een tabel om waarden op te slaan. De lijst met alle mogelijke rollen die medewerkers bij onze levensverzekeringsmaatschappij kunnen vervullen, is opgeslagen in de role woordenboek. Het heeft slechts één attribuut genaamd role_name die uniek identificerende waarden bevat.
We koppelen medewerkers en rollen aan de has_role tafel. Naast de externe sleutels employee_id en role_id , slaan we twee waarden op:start_date en end_date . Deze twee waarden geven het bereik aan waarin deze bedrijfsrol voor een bepaalde medewerker actief was. De end_date zal de waarde null bevatten totdat een einddatum voor de rol van deze werknemer is vastgesteld. De alternatieve sleutel voor deze tabel is de combinatie van employee_id , role_id , en start_date . Om te voorkomen dat dezelfde rol voor dezelfde werknemer wordt gedupliceerd, moeten we elke keer dat we een nieuwe record aan de tabel toevoegen of een bestaande bijwerken, programmatisch controleren op eventuele overlappingen.
Onderwerpgebied #2:Producten
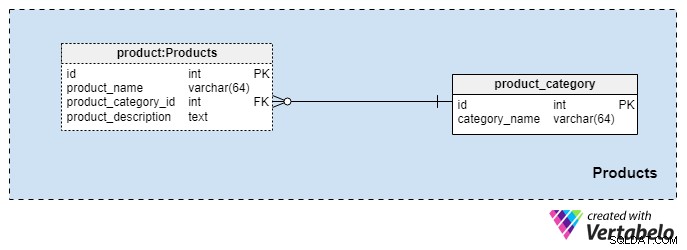
Dit onderwerpgebied is vrij klein en bevat slechts twee tabellen. Waarden uit deze tabellen zijn voorwaarden voor onze andere vakgebieden, dus we zullen deze kort bespreken.
De product_category woordenboek slaat de meest algemene productcategorieën op die we aan onze klanten willen aanbieden. De enige waarde die we in deze tabel opslaan is de unieke category_name om het type verzekering aan te duiden dat we aanbieden, zoals een persoonlijke levensverzekering, een gezinslevensverzekering, enzovoort.
We zullen onze producten nog verder categoriseren met behulp van het product tafel. Deze tabel geeft de daadwerkelijke producten weer die we verkopen en niet hun categorieën. Zoals u zich kunt voorstellen, kunnen we producten groeperen op duur (bijvoorbeeld 10 of 20 jaar, of zelfs een heel leven). Als we ervoor kiezen om dit te doen, hebben we waarschijnlijk producten met dezelfde product_category_id maar verschillende namen en beschrijvingen. Voor elk product slaan we de volgende basisinformatie op:
product_name— de naam van dit product. Het wordt gebruikt als een alternatieve sleutel voor deze tabel in combinatie met deproduct_category_idattribuut. Het is onwaarschijnlijk dat we twee producten met dezelfde naam hebben die tot verschillende categorieën behoren, maar het is niettemin een mogelijkheid.product_category_id— identificeert de categorie waartoe dit product behoort.product_description— tekstuele beschrijving van dit product.
Onderwerpgebied #3:Klanten
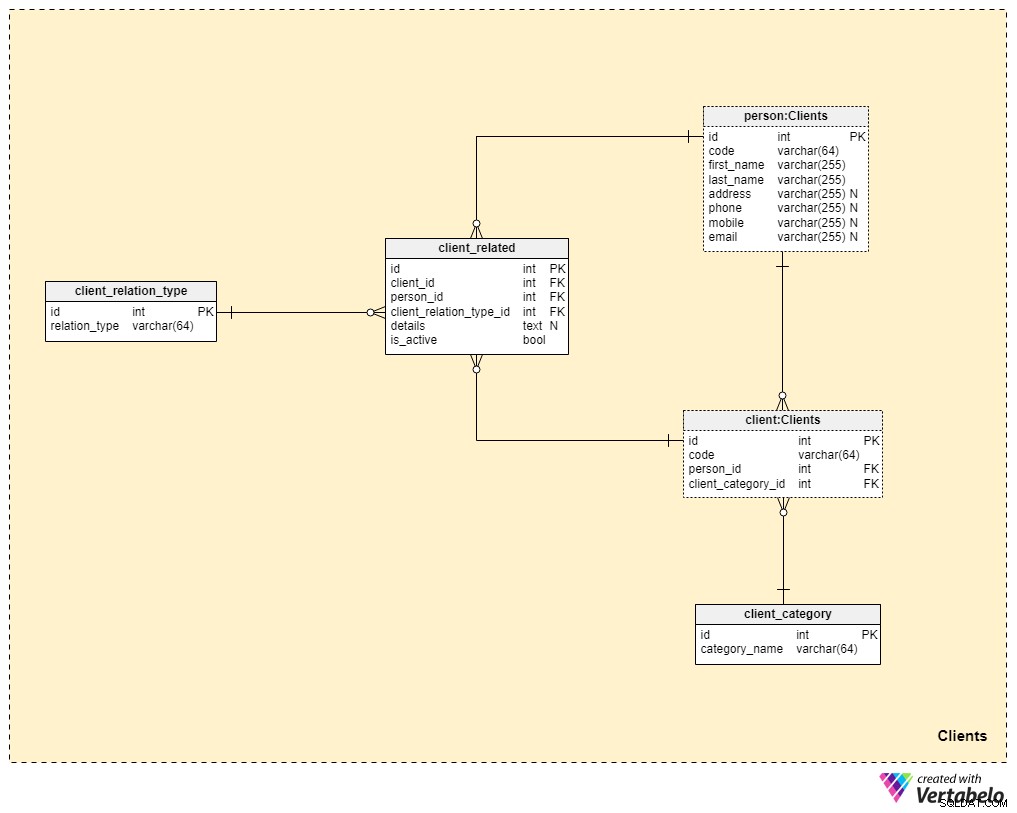
We komen nu veel dichter bij de kern van ons datamodel, maar we zijn er nog niet helemaal. Levensverzekeringen zijn uniek omdat een polis kan worden overgedragen aan een familielid of iemand anders, terwijl polissen voor andere verzekeringen (zoals een zorgverzekering of autoverzekering) aan één klant toebehoren en niet kunnen worden overgedragen. Om deze reden moeten we niet alleen informatie opslaan over de cliënt aan wie de polis toebehoort, maar ook informatie over verwante personen en hun relatie tot de cliënt.
We beginnen met de client tafel. Voor elke klant slaan we de unieke code op die voor die klant is gegenereerd of handmatig ingevoegd, evenals de externe sleutels die verwijzen naar de tabel met hun persoonlijke gegevens (person_id ) en de tabel met onze interne categorisatie (client_category_id ).
De client_category woordenboek stelt ons in staat om klanten te groeperen op basis van hun demografische gegevens en financiële details. De klantcategorieën worden vervolgens gebruikt om te bepalen welke verzekering we aan een bepaalde klant kunnen aanbieden. Hier slaan we alleen een lijst met unieke waarden op die we vervolgens aan klanten toewijzen.
Omdat we het hebben over levensverzekeringen, gaan we ervan uit dat een klant een enkele persoon is. Zoals we eerder vermeldden, kunnen er echter andere mensen zijn die verwant zijn aan de cliënt aan wie de polis kan worden overgedragen of die de polisuitkering kunnen ontvangen bij het overlijden van de cliënt. Om deze reden hebben we een aparte person tafel. Voor elk record in deze tabel slaan we de volgende informatie op:
code— een automatisch gegenereerde of handmatig ingevoegde waarde die wordt gebruikt om de gerelateerde persoon uniek te identificeren.first_nameenlast_name— respectievelijk de voor- en achternaam van de persoon.address,phone,mobileenemail— contactgegevens van deze persoon, die allemaal willekeurige waarden bevatten.
De overige twee tabellen in dit onderwerp zijn nodig om de aard van de relatie tussen cliënten en andere mensen te beschrijven.
De lijst met alle mogelijke relatietypes wordt opgeslagen in de client_relation_type woordenboek. Net als bij andere woordenboeken bevat dit een lijst met unieke namen die we later zullen gebruiken bij het beschrijven van de relatie tussen een bepaalde cliënt en een andere persoon.
Actuele relatiegegevens worden opgeslagen in de client_related tafel. Voor elk record in deze tabel slaan we verwijzingen naar de klant op (client_id ), de gerelateerde persoon (person_id ), de aard van die relatie (client_relation_type_id ), alle toevoegingsdetails (details ), indien aanwezig, en een vlag die aangeeft of de relatie momenteel actief is (is_active ). De alternatieve sleutel in deze tabel wordt gedefinieerd door de combinatie van client_id , person_id , en client_relation_type_id .
Onderwerpgebied #4:Aanbiedingen
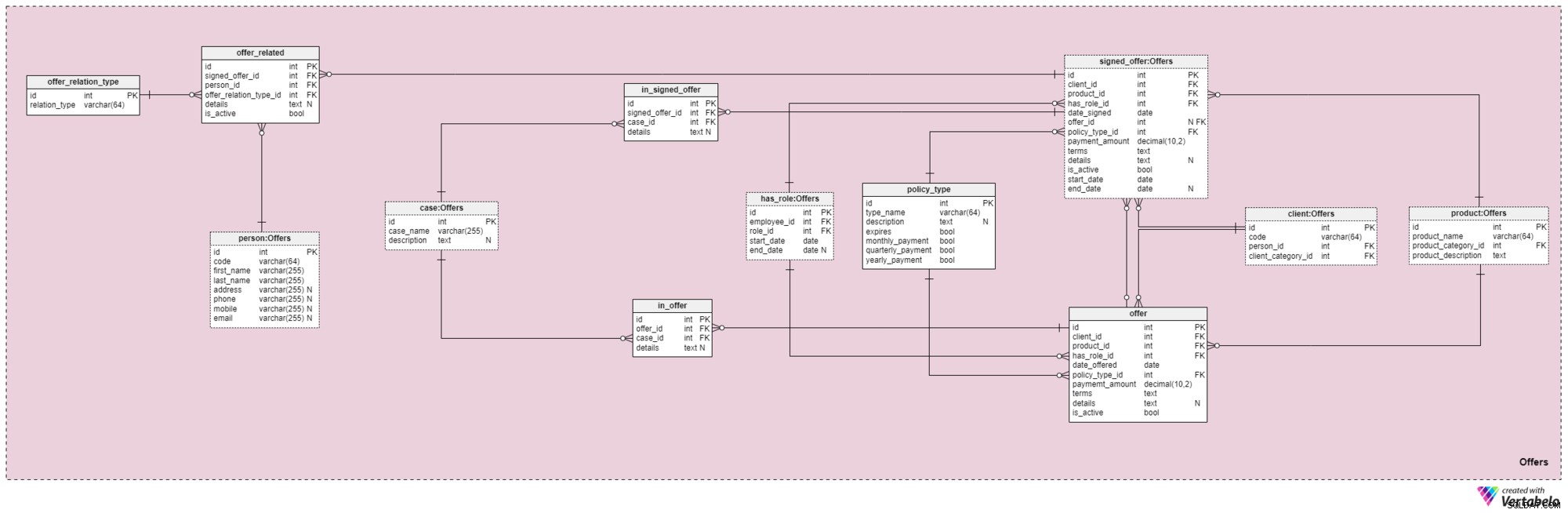
Dit onderwerp en het volgende vormen de kern van dit datamodel. Ze dekken aanbiedingen en ondertekende polissen, evenals betalingen met betrekking tot aanbiedingen. Eerst beschrijven we het onderwerpgebied Aanbiedingen. Het lijkt misschien ingewikkeld omdat het 12 tabellen bevat. Vier van deze 12 (has_role , product , client , en person ) werden beschreven in eerdere onderwerpgebieden, dus we zullen onze discussie hier niet herhalen.
De offer en signed_offer tabellen hebben vergelijkbare structuren omdat ze zullen worden gebruikt om zeer vergelijkbare gegevens in ons model op te slaan. Terwijl offer zal voornamelijk worden gebruikt om alle polissen (en hun details) op te slaan die we aan onze klanten hebben aangeboden, de signed_offer tabel zal strikt worden gebruikt om informatie op te slaan over klanten die daadwerkelijk polissen hebben ondertekend met ons bedrijf. We zullen deze tabellen samen behandelen en eventuele verschillen opmerken waar ze verschijnen. De attributen in deze twee tabellen zijn als volgt:
client_id— verwijzing naar de unieke identificatiecode van de klant die een bepaalde aanbieding heeft ondertekend.product_id— verwijzing naar de unieke identificatiecode van het product dat was opgenomen in de ondertekende aanbieding.has_role_id— verwijzing naar het ID van de werknemer en de rol die deze vervulde op het moment dat het aanbod werd gepresenteerd/ondertekend.date_offeredendate_signed— werkelijke data die aangeven wanneer dit aanbod respectievelijk aan de klant werd gepresenteerd en wanneer het werd ondertekend.offer_id— een verwijzing naar het vorige aanbod voor deze klant. Dit kan de waarde null bevatten, omdat de klant een polis had kunnen ondertekenen zonder een eerdere aanbieding van het bedrijf, bijvoorbeeld als ze ons alleen hadden benaderd. Dit kenmerk hoort strikt bij designed_offertafel.policy_type_id— verwijzing naar het soort polis-woordenboek dat het type polis aangeeft dat we aan de klant hebben aangeboden of hebben laten ondertekenen.payment_amount— het bedrag dat de klant regelmatig voor de polis moet betalen.terms— alle voorwaarden van de overeenkomst, in tekstformaat (XML). Het idee is om alle belangrijke details met betrekking tot het financiële deel van de polis in dit attribuut op te slaan. Voorbeelden van tekst die we kunnen opslaan zijn het totale polisbedrag, het aantal betalingen dat de klant moet doen, enzovoort.details— eventuele aanvullende details, in tekstformaat.is_active— vlag die aangeeft of het record nog steeds actief is.start_dateenend_date— geef het tijdsbestek aan waarin dit beleid actief is/was. Als het beleid voor het leven is ondertekend, bevat end_date de waarde null.
Er is ook de policy_type woordenboek dat we eerder kort noemden. We hebben een zekere mate van flexibiliteit nodig in de manier waarop we hetzelfde product aan verschillende klanten aanbieden, op basis van factoren zoals leeftijd, gezondheid, burgerlijke staat, kredietrisico, enzovoort. Voor elk beleidstype slaan we een type_name op identifier, een aanvullende tekstuele description , een vlag met de naam vervalt om aan te geven of de polis kan verlopen, en een andere vlag die aangeeft of de premies van dit soort polis maandelijks, driemaandelijks of jaarlijks moeten worden betaald. Enkele verwachte soorten polissen zijn:Termijn Leven, Gehele Leven, Universele Levensduur, Gegarandeerde Universele Levensduur, Variabele Levensduur, Variabele Universele Levensduur en Levensverzekering na pensionering.
Verderop, we moeten nu alle gevallen en situaties definiëren die een bepaalde polis kan dekken. We moeten deze gevallen relateren aan specifieke aanbiedingen en ondertekende aanbiedingen.
De lijst met alle mogelijke gevallen die onze polissen dekken, wordt opgeslagen in de case woordenboek. Elk record in deze tabel kan uniek worden geïdentificeerd door zijn case_name en heeft een aanvullende description , als er een nodig is.
De in_offer en in_signed_offer tabellen delen dezelfde structuur omdat ze dezelfde gegevens opslaan. Het enige verschil tussen de twee is dat de eerste gevallen opslaat die gedekt zijn door de polis die alleen aan de klant werd aangeboden, terwijl de tweede gevallen opslaat in de polis die door de klant is ondertekend. Voor elk record in deze twee tabellen slaan we het unieke paar offer_id op /signed_offer_id en case_id , waarvan de laatste het geval of incident aangeeft dat onder de polis valt. Alle andere details worden indien nodig opgeslagen in een tekstueel attribuut.
Zoals we eerder vermeldden, hebben levensverzekeringen bijna altijd niet alleen betrekking op klanten, maar ook op hun familieleden of familieleden. Ook op dit gebied moeten we deze relaties bewaren. Ze worden gedefinieerd op het moment dat een polis wordt ondertekend, maar ze kunnen ook worden gewijzigd gedurende de looptijd van de polis.
Het eerste dat we moeten doen, is een woordenboek maken met alle mogelijke waarden die aan een relatie kunnen worden toegewezen. In ons model is dit de offer_relation_type woordenboek. Afgezien van de primaire sleutel bevat deze tabel slechts één attribuut:het relation_type – die alleen unieke waarden kan bevatten.
We zijn er bijna! De laatste tabel in dit onderwerpgebied is getiteld offer_related . Het betreft een getekende offerte voor iedereen die familie is van de opdrachtgever. Daarom moeten we verwijzingen naar het ondertekende beleid opslaan (signed_offer_id ) en de gerelateerde persoon (person_id ) en specificeer ook de aard van die relatie (offer_relation_type_id ). Daarnaast moeten we details opslaan gerelateerd aan dit record en maak een vlag om te controleren of het nog steeds geldig is in ons systeem.
Onderwerpgebied #5:Betalingen
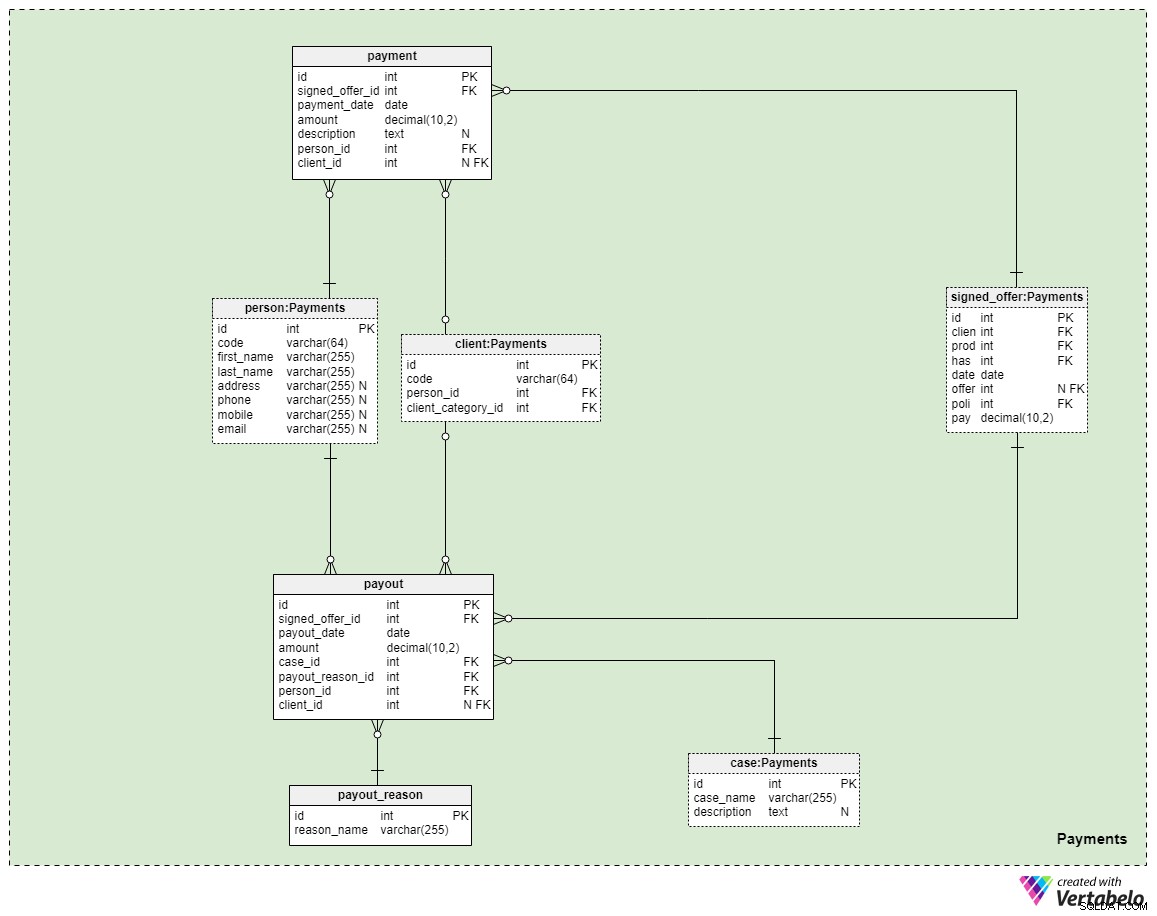
Het laatste onderwerp in ons model betreft betalingen. Hier introduceren we slechts drie nieuwe tabellen:payment , payout_reason , en payout .
Alle betalingen met betrekking tot beleid worden opgeslagen in de payment tafel. We hebben hier alleen de belangrijkste kenmerken opgenomen:
signed_offer_id— verwijzing naar de unieke identificatiecode van de ondertekende aanbieding (beleid).payment_date— de datum waarop deze betaling is gedaan.amount— het daadwerkelijke bedrag dat is betaald.description— een optionele beschrijving van de betaling, in tekstformaat.person_id— verwijzing naar de unieke identificatiecode van de persoon die de betaling heeft gedaan. Merk op dat de klant die de aanbieding heeft ondertekend niet noodzakelijk de enige persoon is die een betaling kan doen.client_id— verwijzing naar de unieke identificatiecode van de cliënt die de betaling heeft gedaan. Dit kenmerk bevat alleen een waarde als de klant zelf de betaling heeft gedaan.
De overige twee tabellen vertegenwoordigen misschien wel de belangrijkste reden waarom we voor levensverzekeringen betalen - dat als er iets met ons zou gebeuren, uitbetalingen zullen worden gedaan aan onze familieleden of levens-/zakenpartners. Hoe dit gebeurt, hangt allemaal af van uw situatie en de voorwaarden van de specifieke polis die u hebt ondertekend. We gebruiken twee eenvoudige tabellen om deze gevallen te behandelen.
De eerste is een woordenboek met de titel payout_reason en heeft een klassieke woordenboekstructuur. Afgezien van het primaire sleutelattribuut, hebben we slechts één attribuut - de reason_name – die een lijst met unieke waarden opslaat die aangeven waarom deze uitbetaling is gedaan.
De laatste tabel in het model is de payout tafel. Het lijkt erg op de payment tabel, maar de belangrijkste verschillen worden hieronder vermeld:
payout_date— de datum waarop de uitbetaling is gedaan.case_id— verwijzing naar de unieke identificatiecode van het gerelateerde geval of incident dat aanleiding gaf tot de betaling. Dit moet overeenkomen met een van de ID's die in het beleid zijn opgenomen.payout_reason_id— verwijzing naar het woordenboek waarin de reden voor de uitbetaling gedetailleerder wordt beschreven. Hoewel de uitbetalingszaak korter en algemener is, biedt de uitbetalingsreden meer specifieke details over wat er is gebeurd.person_idenclient_id— verwijst respectievelijk naar de persoon en de klant die verband houdt met de uitbetaling.
Samenvatting
Geweldig! We hebben met succes ons gegevensmodel voor levensverzekeringen gebouwd. Voordat we onze discussie afronden, is het de moeite waard om op te merken dat er nog veel meer in dit model kan worden behandeld. In dit artikel wilden we vooral de basis van het model behandelen om u een idee te geven van hoe het eruitziet en functioneert. Hier zijn wat meer details die men zou kunnen opnemen in een dergelijk datamodel:
- Aanvullende polis-upgrades vallen niet onder ons huidige model (als u bijvoorbeeld jaarlijkse aanbiedingen wilt doen voor bestaande polissen, kunt u dit niet doen met deze structuur). We zouden nog een paar tabellen moeten toevoegen om alle beleidswijzigingen voor gepresenteerde/ondertekende aanbiedingen op te slaan.
- Al het papierwerk is opzettelijk weggelaten. Natuurlijk komt er nogal wat papierwerk kijken bij een bepaalde levensverzekering, vooral voor het ondertekeningsproces en uitbetalingen. We kunnen documenten bijvoegen die de klantstatus beschrijven op het moment dat de polis werd ondertekend en eventuele wijzigingen onderweg, evenals alle documenten met betrekking tot uitbetalingen.
- Dit model bevat niet de structuur die nodig is voor de berekening van beleidsrisico's. We moeten alle parameters hebben die we moeten testen en alle bereiken die bepalen hoe de waarde van een klant de algehele berekening beïnvloedt. De resultaten van deze berekeningen moeten worden opgeslagen voor elke aanbieding en ondertekende polis.
- De factuurstructuur is in werkelijkheid veel complexer dan wat we hebben behandeld in het onderwerp betalingen. We hebben zelfs nergens in ons model financiële rekeningen genoemd.
Het is duidelijk dat de verzekeringssector vrij complex is. We hebben in dit artikel alleen een datamodel voor levensverzekeringen besproken. Kun je je voorstellen hoe dit datamodel zou evolueren als we een bedrijf zouden runnen dat een aantal verschillende soorten verzekeringen aanbiedt? Het zou zeker veel planning en denkwerk vergen om een georganiseerd datamodel voor zo'n bedrijf te presenteren.
Als je suggesties of ideeën hebt om ons datamodel te verbeteren, laat het ons dan gerust weten in de reacties hieronder!