Bruiloften gaan vaak gepaard met vrolijkheid en feest, met tal van gasten, eten, drinken, muziek en dans. Maar dit alles kan niet gebeuren zonder de juiste voorbereiding en coördinatie. Laten we eens nader bekijken hoe gegevensmodellering ons kan helpen een bruiloft beter te organiseren, zodat alles soepel verloopt.
Voorlopige achtergrond
Hoewel we ons meestal allemaal bewust zijn van hoe een typische huwelijksceremonie eruit ziet, kan het geen kwaad om kort stil te staan bij enkele aspecten die mogelijk van invloed kunnen zijn op ons datamodel.
Trouwpartners
Hoewel de meeste traditionele culturen ceremonies hebben tussen een man en een vrouw, vinden homohuwelijken ook plaats in andere samenlevingen. Ons datamodel moet zo ontworpen zijn dat het alle mogelijkheden accommodeert.
Schaal en complexiteit
Huwelijksceremonies variëren sterk in grootte, duur en complexiteit. Sommige zijn kleine, bescheiden gelegenheden, maar andere zijn grootse vieringen. In Kroatië kunt u bijvoorbeeld een eenvoudige huwelijksceremonie houden waarbij een stel in het gemeentehuis trouwt, hun ringen en geloften uitwisselt voor hun gasten, en ofwel een diner na de ceremonie bijwonen of naar huis gaan. In andere landen kunnen bruiloften behoorlijk uitgebreid zijn:het kan gaan om vrijgezellenfeesten, onderhandelingen, diners, meerdere ceremonies, enzovoort. In sommige gevallen kunnen deze ceremonies meerdere dagen duren en op een paar verschillende locaties plaatsvinden! Nogmaals, ons datamodel moet voorbereid zijn om met deze situaties om te gaan.
Eindresultaat en kosten
In de meeste gevallen trouwt het stel na de viering en ontvangt een factuur voor alle kosten (huur, eten en drinken, band, etc). Ze kunnen besluiten een bureau in te huren om al deze kosten voor hen te dragen, of ze kunnen ervoor kiezen om het allemaal zelf te doen. Hoe dan ook, we moeten rekening houden met deze situaties.
Het gegevensmodel:overzicht
Ons gegevensmodel voor dit artikel bestaat uit vijf secties:
- Locaties
- Partners, producten en diensten
- Bruiloften
- Deelnemers
- Facturen
We zullen elk van deze gebieden grondig bespreken in de volgorde waarin ze hierboven worden vermeld. Terwijl we werken aan het ontwikkelen van ons datamodel, nemen we de rol op ons van het bureau dat de bruiloft organiseert.
Sectie 1:Locaties
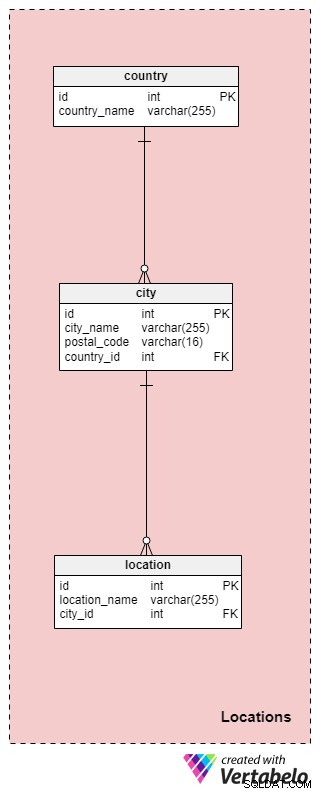
De Locations sectie bevat universele tabellen die in veel andere gegevensmodellen kunnen worden gebruikt. Zoals we eerder opmerkten, kan de hele huwelijksceremonie op slechts één locatie plaatsvinden, of mogelijk meerdere locaties omvatten. Laten we de tabellen van deze sectie in meer detail bespreken.
Het country table bevat informatie over het land waar de bruiloft plaatsvindt. In de meeste gevallen zal dit land overeenkomen met de locatie van ons bureau, maar dat kan niet het geval zijn als we internationaal opereren. Elk land in deze tabel is uniek gedefinieerd door zijn country_name .
Vervolgens moeten we de lijst opslaan van alle steden en/of dorpen waar de bruiloft zal worden georganiseerd. Deze informatie wordt opgeslagen in de city tafel. Voor elke stad slaan we de naam en postcode op, evenals het land waarin het zich bevindt.
De laatste tabel in dit onderwerpgebied is location . Locaties zijn specifieker, zoals gemeentehuizen, kerken, parken, enzovoort. Voor elke locatie slaan we de naam op en een verwijzing naar de ID van de stad waarin deze zich bevindt. De combinatie van deze twee kenmerken vormt de unieke sleutel voor deze tabel.
Houd er voor locaties rekening mee dat we hier een conservatieve benadering hebben gevolgd om te voorkomen dat de ongebruikelijke gevallen worden behandeld waarin de ceremonie plaatsvindt in bijvoorbeeld een trein of een vliegtuig (in welk geval de "locatie" meerdere steden kan omvatten). Als we deze gevallen willen behandelen, moeten we enkele wijzigingen in ons model aanbrengen.
Sectie 2:Partners, producten en services

Voordat we verder gaan met het centrale deel van ons datamodel, moeten we de lijst opslaan van alle partners waarmee we samenwerken, evenals de producten en diensten die ze aanbieden. Om dit te bereiken, gebruiken we vijf tabellen.
Ten eerste wordt de lijst met alle partners waarmee we werken opgeslagen in de partner woordenboek. Voor elke partner slaan we hun unieke partner_code op en partner_name .
Natuurlijk zullen onze partners huwelijksgerelateerde diensten verlenen, waaronder catering, het organiseren van bands, het opzetten van audio- en videoapparatuur, het bieden van huurondersteuning en nog veel meer. In wezen kan alles wat u maar kunt bedenken op de een of andere manier verband houden met een bruiloft. We slaan deze lijst met services op in de service woordenboek. Voor elke service slaan we op:
service_code– een waarde die we intern gebruiken om een bepaalde service op unieke wijze aan te duiden.service_name– naam van de dienst. Houd er rekening mee dat verschillende services dezelfde naam kunnen hebben. Dit zou gebeuren als twee van onze partners dezelfde service aanbieden, wat zeer waarschijnlijk is. Het zou zelfs wenselijk zijn als ze dezelfde naam gebruiken voor hetzelfde type service, omdat dat het vergelijken van prijzen voor dezelfde services veel gemakkelijker zou maken.description– een optionele tekstuele beschrijving van de dienst.picture– een link naar de locatie waar de bijbehorende servicefoto is opgeslagen.price– de huidige prijs voor deze dienst. Het kan de waarde NULL bevatten als de prijs niet kan worden bepaald zonder eerst verschillende factoren te evalueren, zoals hoeveel mensen van plan zijn de ceremonie bij te wonen.
De provides_service tabel relateert partners aan de lijst met diensten die zij leveren. Voor elke unieke combinatie van partner_id en service_id , slaan we een gedetailleerde tekstuele beschrijving op van de aard van de service die door de partner wordt geleverd en of de service momenteel beschikbaar is.
We hebben ook tabellen nodig voor het opslaan van informatie over producten en hun relaties met partners. Het product tabel volgt dezelfde logica als de service tafel, behalve dat deze, zoals de naam al doet vermoeden, specifiek is voor producten. In deze tabel slaan we alle mogelijke producten op die essentieel zijn voor de meeste huwelijksceremonies, zoals ringen, outfits, decoraties, bloemen, meubels en meer.
De laatste tabel in deze sectie is de provides_product tafel. Het werkt net als de provides_service tabel, behalve dat deze specifiek is voor producten in tegenstelling tot services. Het geeft aan welke van onze partners het product in kwestie aanbiedt.
Sectie 3:Bruiloften
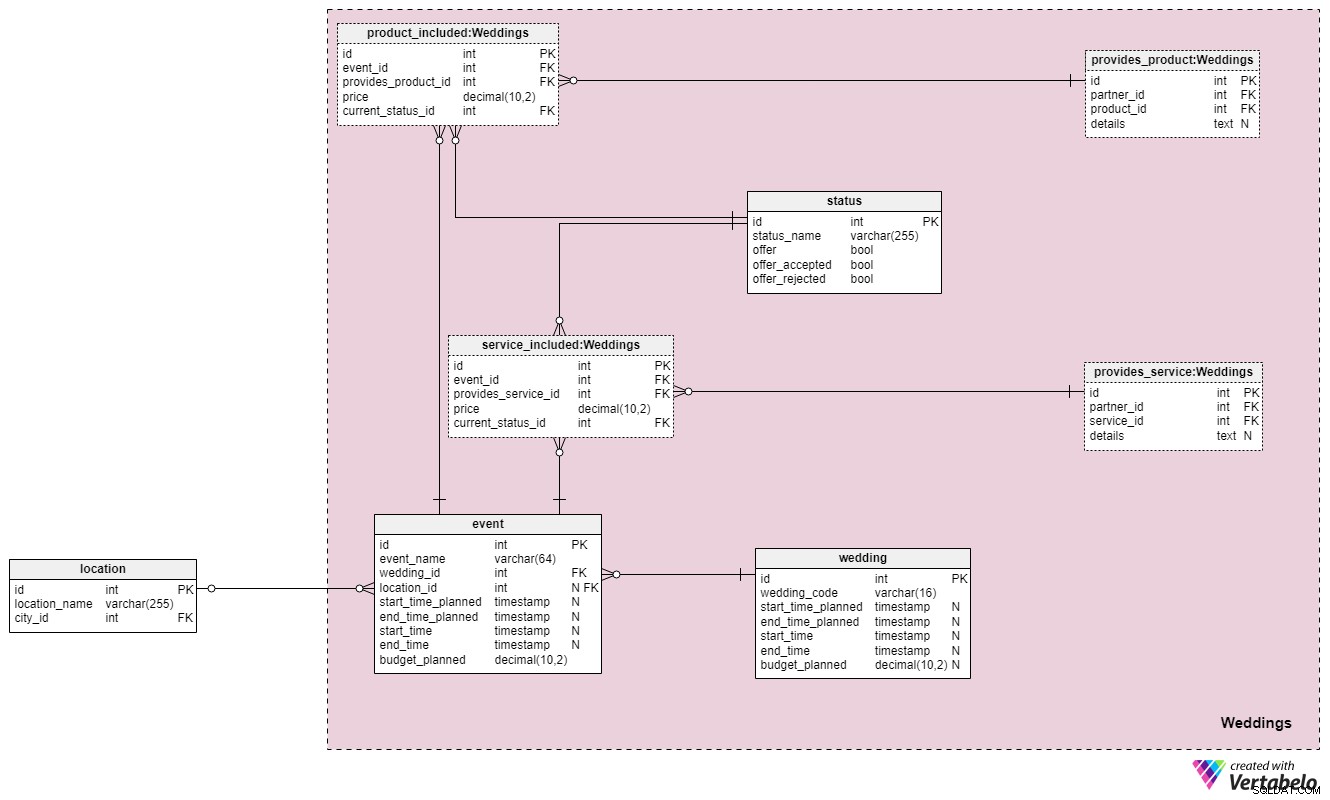
We zijn eindelijk aangekomen bij het hart van ons datamodel:de Weddings sectie. Het bevat vijf nieuwe tabellen die verwijzen naar de tabellen van andere secties. Merk op dat er ook naar de eigen tabellen van deze sectie zal worden verwezen in toekomstige delen van ons model.
In de wedding tabel, slaan we de volledige lijst op van alle bruiloften die we hebben/waren bij het organiseren. Elke bruiloft krijgt zijn eigen unieke wedding_code . We slaan ook de geplande start- en eindtijden voor de hele ceremonie op, en we werken de echte start- en eindtijden bij zodra deze informatie beschikbaar is. Daarnaast bewaren we de budget_planned waarde, dus we hebben in ieder geval een schatting van hoeveel dit allemaal gaat kosten. Alle andere details met betrekking tot de bruiloft worden opgeslagen in andere delen van het gegevensmodel, dus dit is alles wat we nu echt nodig hebben.
Het idee hier is om elke bruiloft te behandelen als een reeks gebeurtenissen. Evenementen hebben op hun beurt betrekking op aanbiedingen voor gewenste producten/diensten, afgewezen en geaccepteerde aanbiedingen en andere relevante details. Om je een beter idee te geven van hoe dit allemaal werkt, kunnen we de hele bruiloft opsplitsen in de volgende evenementen:planningsfase, vrijgezellenfeesten, ceremonie en afterparty/diner. Dit zijn natuurlijk slechts enkele van de meest voorkomende huwelijksgebeurtenissen. Alle bruiloftsgebeurtenissen worden opgeslagen in de evenemententabel. Een event zal een unieke id hebben.
Elk evenement is gekoppeld aan een enkele bruiloft en het is gerelateerd aan één locatie of geen enkele. Het laatste geval doet zich voor als de gebeurtenis meer conceptueel is , zoals de planfase (aangezien er niet één locatie is waar het moet plaatsvinden). Net als bij de eigenlijke huwelijksceremonie zelf, heeft een evenement geplande en echte begin- en eindtijden, evenals een gepland budget. Merk op dat we het hier eenvoudig hebben gehouden met betrekking tot locaties. Als evenementen meerdere locaties betreffen, moeten we ons datamodel aanpassen.
Verderop willen we alle diensten en producten opslaan die te maken hebben met een evenement. Om dit te doen, gebruiken we drie tabellen:status , product_included , en service_included .
De status table is een woordenboek dat alle statussen bijhoudt met betrekking tot producten en diensten voor een bepaald evenement. Het bevat vlagvariabelen die aangeven of een product/dienst is aangeboden, geaccepteerd of afgewezen. Voor elk record in deze tabel slaan we een unieke status_name op .
De overige twee tabellen in deze sectie, getiteld product_included en service_included , lijken structureel en conceptueel op elkaar. Voor elk evenement slaan we de lijst op met producten en diensten die werden aangeboden en veranderen hun status als ze worden geaccepteerd of afgewezen. Voor elk record in deze twee tabellen slaan we de volgende algemene kenmerken op:
event_id– een verwijzing naar de gerelateerde gebeurtenis.provides_product_id/provides_service_id– verwijzingen naar de tabellen met producten/diensten die onze partners aanbieden.price– voorgestelde prijs voor het product/de dienst. Deze prijs kan afwijken van de standaardprijs die we in ons bestand hebben als we een speciale aanbieding doen.current_status_id– een verwijzing naar destatuswoordenboek dat aangeeft of dit record is aangeboden, geaccepteerd of afgewezen.
Sectie 4:Deelnemers
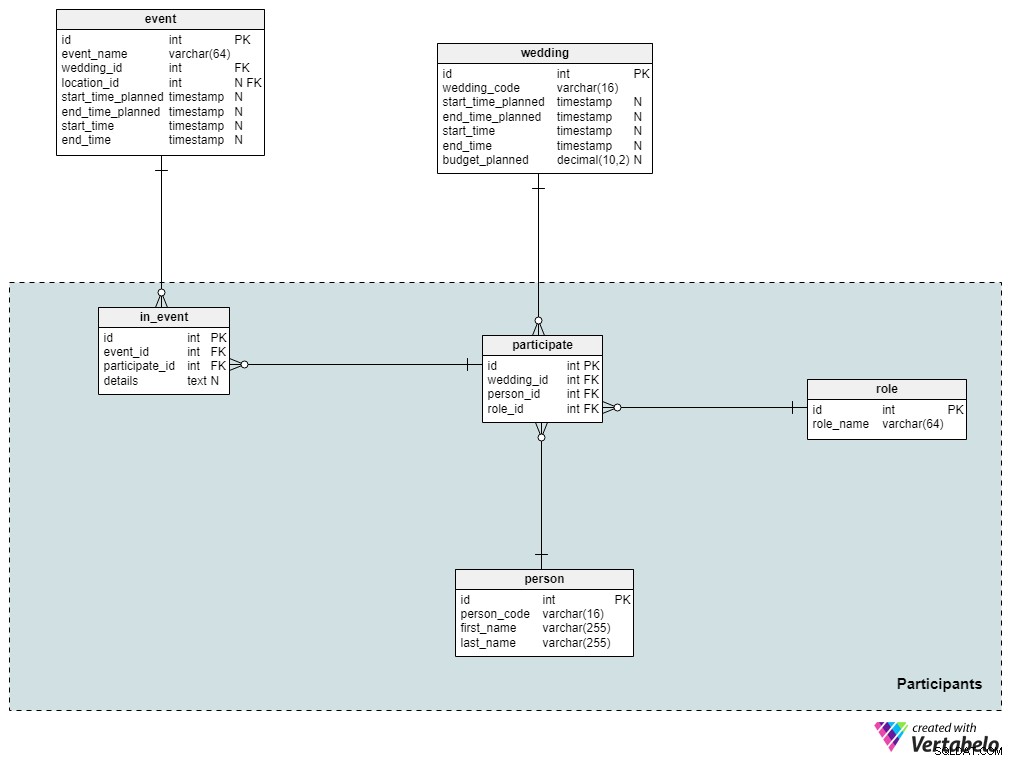
Als je een grote bruiloft organiseert, is de kans groot dat je de meeste gasten kent die van plan zijn om aanwezig te zijn. Natuurlijk zullen de gasten die je uitnodigt - of het nu je vrienden of familieleden zijn - waarschijnlijk andere mensen meenemen die je niet persoonlijk kent, zoals hun vrienden of collega's. In deze sectie bewaren we de volledige lijst van gasten die zijn uitgenodigd voor de bruiloft, evenals hun rollen.
De person tabel bevat een lijst van alle personen die deel uitmaken van de bruiloft. Voor elk individu slaan we hun unieke person_code op en voor- en achternaam. We kunnen natuurlijk meer details toevoegen als we dat willen.
Vervolgens definiëren we alle mogelijke rollen die men zou kunnen aannemen tijdens een bruiloft. Deze rollen omvatten "gast", "getuige", "bruidegom", "bruidsmeisje", "bruid", "bruidegom", enzovoort. Voor elke rol slaan we alleen de unieke role_name op in deze tabel. Een persoon kan maar één rol op zich nemen voor een bepaalde bruiloft.
Vervolgens brengen we bruiloften in verband met hun deelnemers. Merk op dat de participate tabel bevat alleen verwijzingen naar de tabellen wedding , person , en role . De combinatie van wedding_id en person_id dient als alternatieve sleutel voor deze tabel.
De bruiloft zal uit meerdere evenementen bestaan, maar niet alle deelnemers zullen hierbij betrokken zijn. Daarom moeten we deze informatie apart opslaan. In de in_event tabel, slaan we unieke paren externe sleutels op die verwijzen naar de tabellen event en participate . Alle aanvullende informatie wordt opgeslagen in de details tekst toegeschreven.
Sectie 5:Facturen
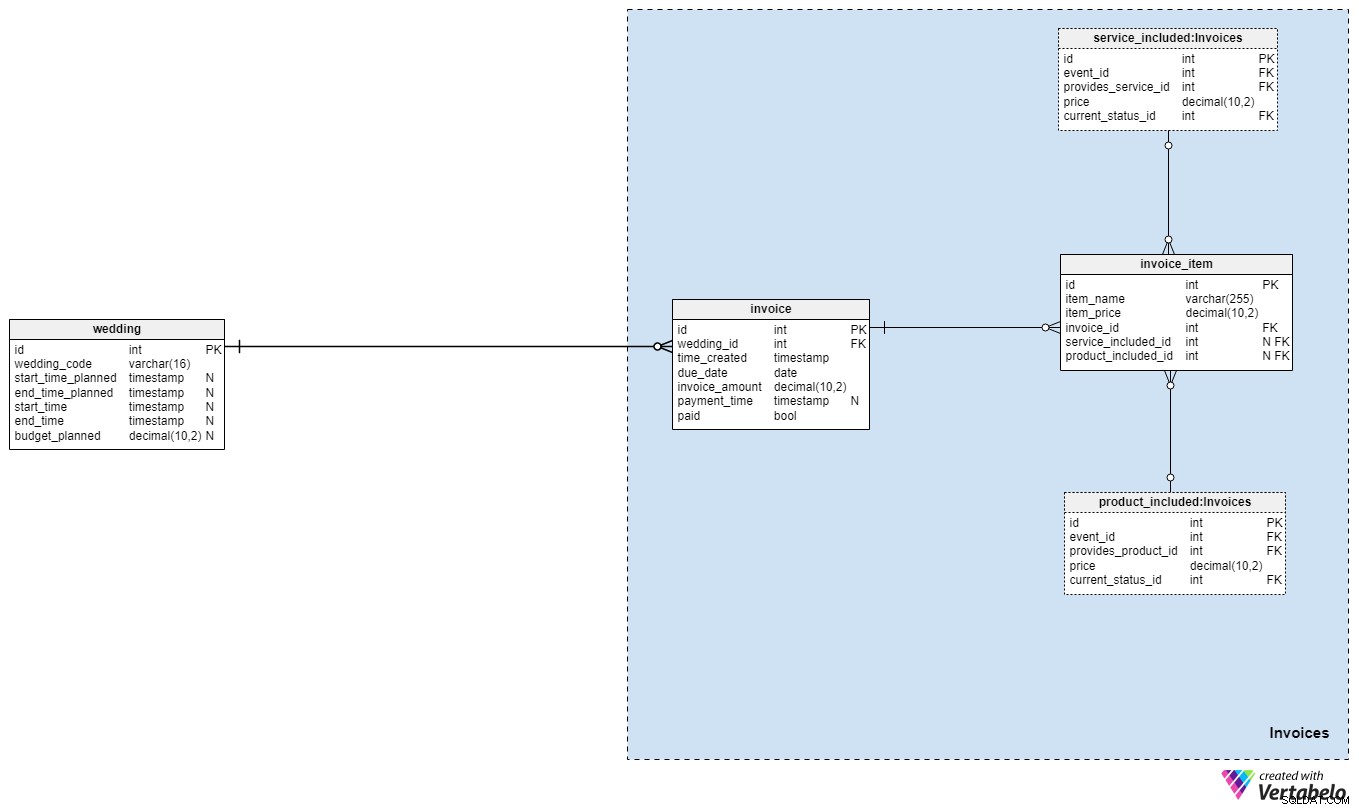
We zijn bijna klaar! Het laatste deel van ons gegevensmodel stelt ons in staat om de kosten van de bruiloft bij te houden. Spannend, toch?
We genereren meestal één invoice per bruiloft, maar we kunnen ook meer genereren als dat nodig is. Hopelijk zal het totale bedrag dat we het paar factureren nauw aansluiten bij ons geplande budget, maar dat is misschien niet altijd het geval. Voor elke factuur slaan we de volgende informatie op:
wedding_id– een verwijzing naar de bruiloft waarvoor de factuur is opgesteld.time_created– het tijdstempel voor wanneer de factuur is gegenereerd.due_date– de datum waarop de factuur betaald moet zijn.invoice_amount– het totale bedrag dat betaald moet worden.payment_time– het tijdstempel van wanneer de betaling daadwerkelijk is uitgevoerd. Natuurlijk bevat dit kenmerk de waarde NULL totdat de betaling is gedaan.paid– een vlag die aangeeft of de factuur is betaald. Dit kenmerk wordt ingesteld op 'True' zodra depayment_timeis bijgewerkt.
De laatste tabel in ons model betreft de gefactureerde artikelen zelf. We slaan deze op in de invoice_item tafel. Voor elk record slaan we de volgende gegevens op:
item_name– onze gekozen naam voor het specifieke item.item_price– de prijs die gerelateerd is aan dat specifieke artikel.invoice_id– de id van de gerelateerde factuur.service_included_id– de id van de dienst waarop het factuuritem betrekking heeft. Dit kenmerk kan worden ingesteld op NULL als het artikel in kwestie niet echt gerelateerd is aan een service of als het slechts een extra toeslag is die we op de factuur hebben toegepast.product_included_id– de id van het product waarop het factuuritem betrekking heeft. Dit kenmerk kan worden ingesteld op NULL als het artikel in kwestie niet echt gerelateerd is aan een product of als het slechts een extra toeslag is die we op de factuur hebben toegepast.
Samenvatting
Dat vat het ongeveer samen voor dit datamodel! Nogmaals, we zien hoe nuttig datamodellering is bij het organiseren van de informatie van een bedrijf.
Zoals we hebben opgemerkt, zijn er veel dingen die we omwille van de eenvoud uit ons datamodel hebben weggelaten. Ons model zou bijvoorbeeld idealiter de geschiedenis van aanbiedingen, financiële details en meer moeten volgen.
Laat het ons hieronder weten als je suggesties hebt. We horen graag uw mening!