Afgelopen oktober hebben we ons PyBites-publiek uitgedaagd om een webapp te maken om beter door de Daily Python Tip-feed te navigeren. In dit artikel deel ik wat ik onderweg heb gebouwd en geleerd.
In dit artikel leer je:
- Hoe de projectrepo te klonen en de app in te stellen.
- Hoe de Twitter API te gebruiken via de Tweepy-module om de tweets in te laden.
- Hoe SQLAlchemy te gebruiken om de gegevens op te slaan en te beheren (tips en hashtags).
- Een eenvoudige web-app bouwen met Bottle, een micro-webframework vergelijkbaar met Flask.
- Hoe het pytest-framework te gebruiken om tests toe te voegen.
- Hoe de richtlijnen van Better Code Hub hebben geleid tot beter onderhoudbare code.
Als je mee wilt doen en de code in detail wilt lezen (en mogelijk een bijdrage wilt leveren), raad ik je aan de repo af te splitsen. Laten we beginnen.
Projectconfiguratie
Ten eerste, Naamruimten zijn een geweldig idee om toe te toeren dus laten we ons werk doen in een virtuele omgeving. Met Anaconda maak ik het als volgt:
$ virtualenv -p <path-to-python-to-use> ~/virtualenvs/pytip
Maak een productie- en een testdatabase in Postgres:
$ psql
psql (9.6.5, server 9.6.2)
Type "help" for help.
# create database pytip;
CREATE DATABASE
# create database pytip_test;
CREATE DATABASE
We hebben inloggegevens nodig om verbinding te maken met de database en de Twitter API (maak eerst een nieuwe app). Volgens best practice moet de configuratie worden opgeslagen in de omgeving, niet in de code. Zet de volgende env-variabelen aan het einde van ~/virtualenvs/pytip/bin/activate , het script dat de activering / deactivering van uw virtuele omgeving afhandelt, waarbij u ervoor zorgt dat de variabelen voor uw omgeving worden bijgewerkt:
export DATABASE_URL='postgres://postgres:password@localhost:5432/pytip'
# twitter
export CONSUMER_KEY='xyz'
export CONSUMER_SECRET='xyz'
export ACCESS_TOKEN='xyz'
export ACCESS_SECRET='xyz'
# if deploying it set this to 'heroku'
export APP_LOCATION=local
In de deactiveringsfunctie van hetzelfde script zet ik ze uit zodat we dingen buiten de shell-scope houden bij het deactiveren (verlaten) van de virtuele omgeving:
unset DATABASE_URL
unset CONSUMER_KEY
unset CONSUMER_SECRET
unset ACCESS_TOKEN
unset ACCESS_SECRET
unset APP_LOCATION
Dit is een goed moment om de virtuele omgeving te activeren:
$ source ~/virtualenvs/pytip/bin/activate
Kloon de repo en, met de virtuele omgeving ingeschakeld, installeer de vereisten:
$ git clone https://github.com/pybites/pytip && cd pytip
$ pip install -r requirements.txt
Vervolgens importeren we de verzameling tweets met:
$ python tasks/import_tweets.py
Controleer vervolgens of de tabellen zijn gemaakt en de tweets zijn toegevoegd:
$ psql
\c pytip
pytip=# \dt
List of relations
Schema | Name | Type | Owner
--------+----------+-------+----------
public | hashtags | table | postgres
public | tips | table | postgres
(2 rows)
pytip=# select count(*) from tips;
count
-------
222
(1 row)
pytip=# select count(*) from hashtags;
count
-------
27
(1 row)
pytip=# \q
Laten we nu de tests uitvoeren:
$ pytest
========================== test session starts ==========================
platform darwin -- Python 3.6.2, pytest-3.2.3, py-1.4.34, pluggy-0.4.0
rootdir: realpython/pytip, inifile:
collected 5 items
tests/test_tasks.py .
tests/test_tips.py ....
========================== 5 passed in 0.61 seconds ==========================
En als laatste voer je de Bottle-app uit met:
$ python app.py
Blader naar https://localhost:8080 en voilà:je zou de tips moeten zien gesorteerd op populariteit. Door op een hashtag-link aan de linkerkant te klikken of door het zoekvak te gebruiken, kunt u ze eenvoudig filteren. Hier zien we de panda's tips bijvoorbeeld:
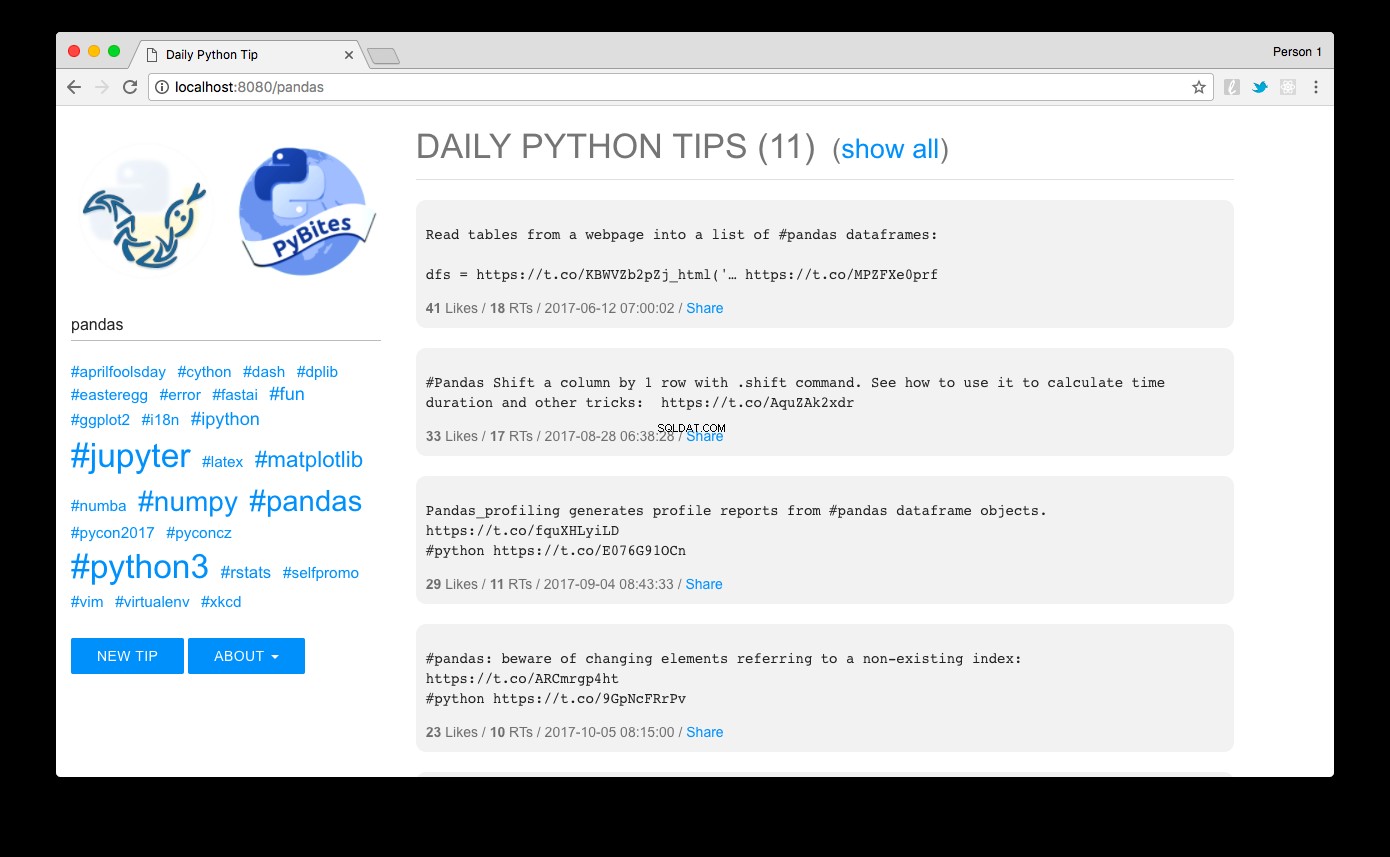
Het ontwerp dat ik heb gemaakt met MUI - een lichtgewicht CSS-framework dat de richtlijnen voor materiaalontwerp van Google volgt.
Implementatiedetails
De DB en SQLAlchemy
Ik gebruikte SQLAlchemy om te communiceren met de DB om te voorkomen dat ik veel (redundante) SQL moest schrijven.
In tips/models.py , we definiëren onze modellen - Hashtag en Tip - dat SQLAlchemy zal toewijzen aan DB-tabellen:
from sqlalchemy import Column, Sequence, Integer, String, DateTime
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Hashtag(Base):
__tablename__ = 'hashtags'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
name = Column(String(20))
count = Column(Integer)
def __repr__(self):
return "<Hashtag('%s', '%d')>" % (self.name, self.count)
class Tip(Base):
__tablename__ = 'tips'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
tweetid = Column(String(22))
text = Column(String(300))
created = Column(DateTime)
likes = Column(Integer)
retweets = Column(Integer)
def __repr__(self):
return "<Tip('%d', '%s')>" % (self.id, self.text)
In tips/db.py , we importeren deze modellen, en nu is het gemakkelijk om met de DB te werken, bijvoorbeeld om te communiceren met de Hashtag model:
def get_hashtags():
return session.query(Hashtag).order_by(Hashtag.name.asc()).all()
En:
def add_hashtags(hashtags_cnt):
for tag, count in hashtags_cnt.items():
session.add(Hashtag(name=tag, count=count))
session.commit()
Bezoek de Twitter-API
We moeten de gegevens ophalen van Twitter. Daarvoor heb ik tasks/import_tweets.py . gemaakt . Ik heb dit verpakt onder taken omdat het in een dagelijkse cronjob moet worden uitgevoerd om naar nieuwe tips te zoeken en statistieken (aantal vind-ik-leuks en retweets) op bestaande tweets bij te werken. Voor de eenvoud laat ik de tabellen dagelijks opnieuw maken. Als we beginnen te vertrouwen op FK-relaties met andere tabellen, moeten we zeker update-statements kiezen boven delete+add.
We hebben dit script gebruikt in de Project Setup. Laten we eens kijken wat het in meer detail doet.
Eerst maken we een API-sessieobject dat we doorgeven aan tweepy.Cursor. Deze functie van de API is echt leuk:het gaat over paginering, iteratie door de tijdlijn. Voor het aantal fooien - 222 op het moment dat ik dit schrijf - is het echt snel. De exclude_replies=True en include_rts=False argumenten zijn handig omdat we alleen de eigen tweets van Daily Python Tip willen (geen re-tweets).
Voor het extraheren van hashtags uit de tips is heel weinig code nodig.
Eerst definieerde ik een regex voor een tag:
TAG = re.compile(r'#([a-z0-9]{3,})')
Daarna gebruikte ik findall om alle tags te krijgen.
Ik heb ze doorgegeven aan collecties. Teller die een dictaat-achtig object retourneert met de tags als sleutels, en telt als waarden, in aflopende volgorde gerangschikt op waarden (meest gebruikelijk). Ik heb de te algemene python-tag uitgesloten die de resultaten zou vertekenen.
def get_hashtag_counter(tips):
blob = ' '.join(t.text.lower() for t in tips)
cnt = Counter(TAG.findall(blob))
if EXCLUDE_PYTHON_HASHTAG:
cnt.pop('python', None)
return cnt
Ten slotte, de import_* functies in tasks/import_tweets.py voer de daadwerkelijke import van de tweets en hashtags uit door add_* . aan te roepen DB-methoden van de tips directory/pakket.
Maak een eenvoudige web-app met Bottle
Nu dit voorwerk is gedaan, is het maken van een web-app verrassend eenvoudig (of niet zo verrassend als je Flask eerder hebt gebruikt).
Maak eerst kennis met Bottle:
Bottle is een snel, eenvoudig en lichtgewicht WSGI micro-webframework voor Python. Het wordt gedistribueerd als een enkele bestandsmodule en heeft geen andere afhankelijkheden dan de Python Standard Library.
Leuk. De resulterende web-app bestaat uit <30 LOC en is te vinden in app.py.
Voor deze eenvoudige app is een enkele methode met een optioneel tagargument voldoende. Net als bij Flask wordt de routing afgehandeld door decorateurs. Als het wordt aangeroepen met een tag, worden de tips op de tag gefilterd, anders worden ze allemaal weergegeven. De weergave-decorateur definieert de te gebruiken sjabloon. Net als Flask (en Django) retourneren we een dictaat voor gebruik in de sjabloon.
@route('/')
@route('/<tag>')
@view('index')
def index(tag=None):
tag = tag or request.query.get('tag') or None
tags = get_hashtags()
tips = get_tips(tag)
return {'search_tag': tag or '',
'tags': tags,
'tips': tips}
Volgens de documentatie, om met statische bestanden te werken, voegt u dit fragment bovenaan toe, na de import:
@route('/static/<filename:path>')
def send_static(filename):
return static_file(filename, root='static')
Ten slotte willen we ervoor zorgen dat we alleen in debug-modus werken op localhost, vandaar de APP_LOCATION env variabele die we hebben gedefinieerd in Project Setup:
if os.environ.get('APP_LOCATION') == 'heroku':
run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))
else:
run(host='localhost', port=8080, debug=True, reloader=True)
Flessensjablonen
Bottle wordt geleverd met een snelle, krachtige en gemakkelijk te leren ingebouwde template-engine genaamd SimpleTemplate.
In de views subdirectory definieerde ik een header.tpl , index.tpl , en footer.tpl . Voor de tagcloud heb ik een aantal eenvoudige inline CSS gebruikt die de taggrootte per aantal vergroot, zie header.tpl :
% for tag in tags:
<a style="font-size: {{ tag.count/10 + 1 }}em;" href="/{{ tag.name }}">#{{ tag.name }}</a>
% end
In index.tpl we doorlopen de tips:
% for tip in tips:
<div class='tip'>
<pre>{{ !tip.text }}</pre>
<div class="mui--text-dark-secondary"><strong>{{ tip.likes }}</strong> Likes / <strong>{{ tip.retweets }}</strong> RTs / {{ tip.created }} / <a href="https://twitter.com/python_tip/status/{{ tip.tweetid }}" target="_blank">Share</a></div>
</div>
% end
Als je bekend bent met Flask en Jinja2 zou dit er heel bekend uit moeten zien. Python insluiten is nog eenvoudiger, met minder typen—(% ... vs {% ... %} ).
Alle css, afbeeldingen (en JS als we die zouden gebruiken) gaan naar de statische submap.
En dat is alles wat er is om een eenvoudige web-app te maken met Bottle. Als je de gegevenslaag eenmaal goed hebt gedefinieerd, is het vrij eenvoudig.
Tests toevoegen met pytest
Laten we dit project nu wat robuuster maken door enkele tests toe te voegen. Het testen van de DB vereiste wat meer graven in het pytest-framework, maar uiteindelijk gebruikte ik de pytest.fixture-decorator om een database op te zetten en af te breken met enkele test-tweets.
In plaats van de Twitter-API aan te roepen, heb ik enkele statische gegevens gebruikt die in tweets.json staan .En, in plaats van de live DB te gebruiken, in tips/db.py , controleer ik of pytest de beller is (sys.argv[0] ). Als dat zo is, gebruik ik de test-DB. Ik zal dit waarschijnlijk refactoren, omdat Bottle het werken met configuratiebestanden ondersteunt.
Het hashtag-gedeelte was gemakkelijker te testen (test_get_hashtag_counter ) omdat ik gewoon wat hashtags aan een reeks met meerdere regels kon toevoegen. Geen armaturen nodig.
Codekwaliteit is belangrijk - Better Code Hub
Better Code Hub begeleidt u bij het schrijven van, nou ja, betere code. Voor het schrijven van de tests scoorde het project een 7:
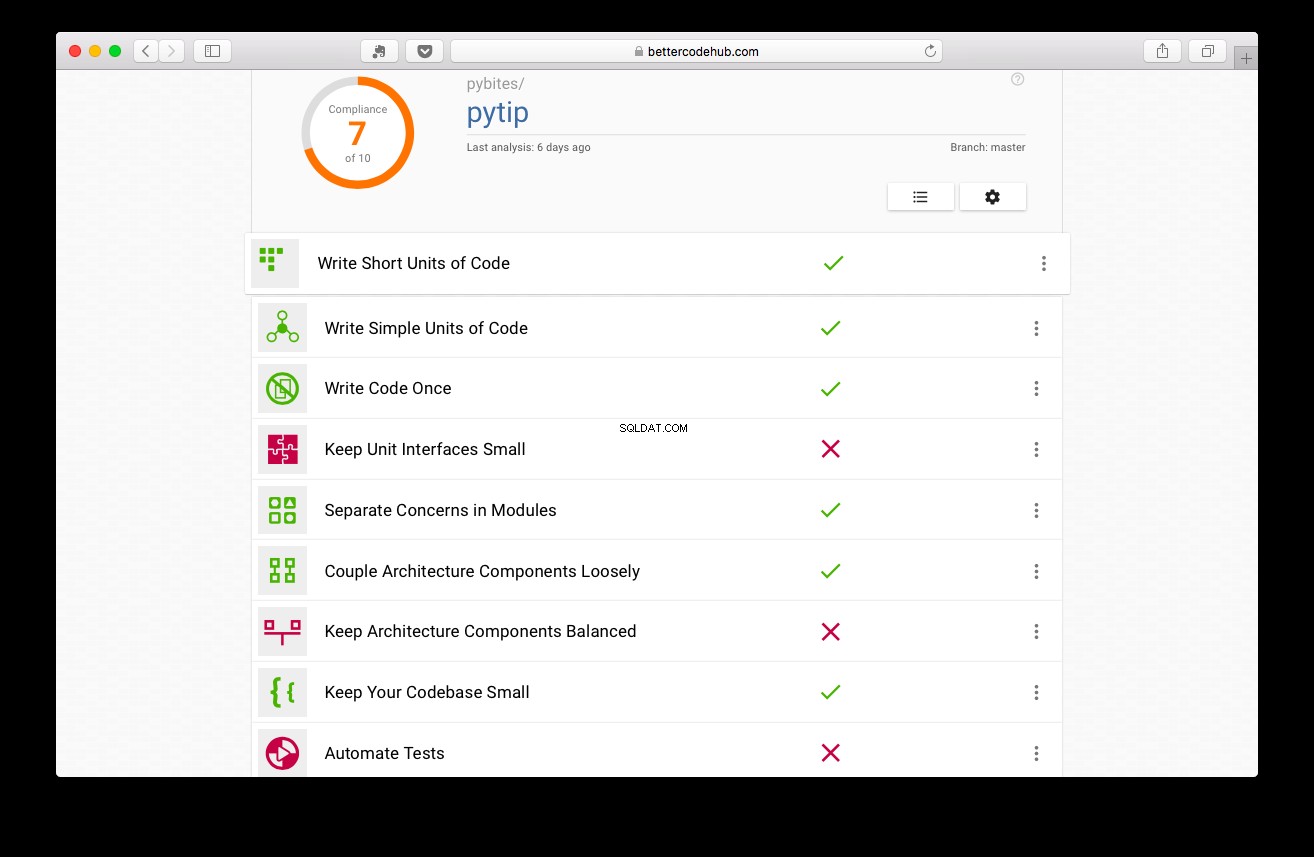
Niet slecht, maar het kan beter:
-
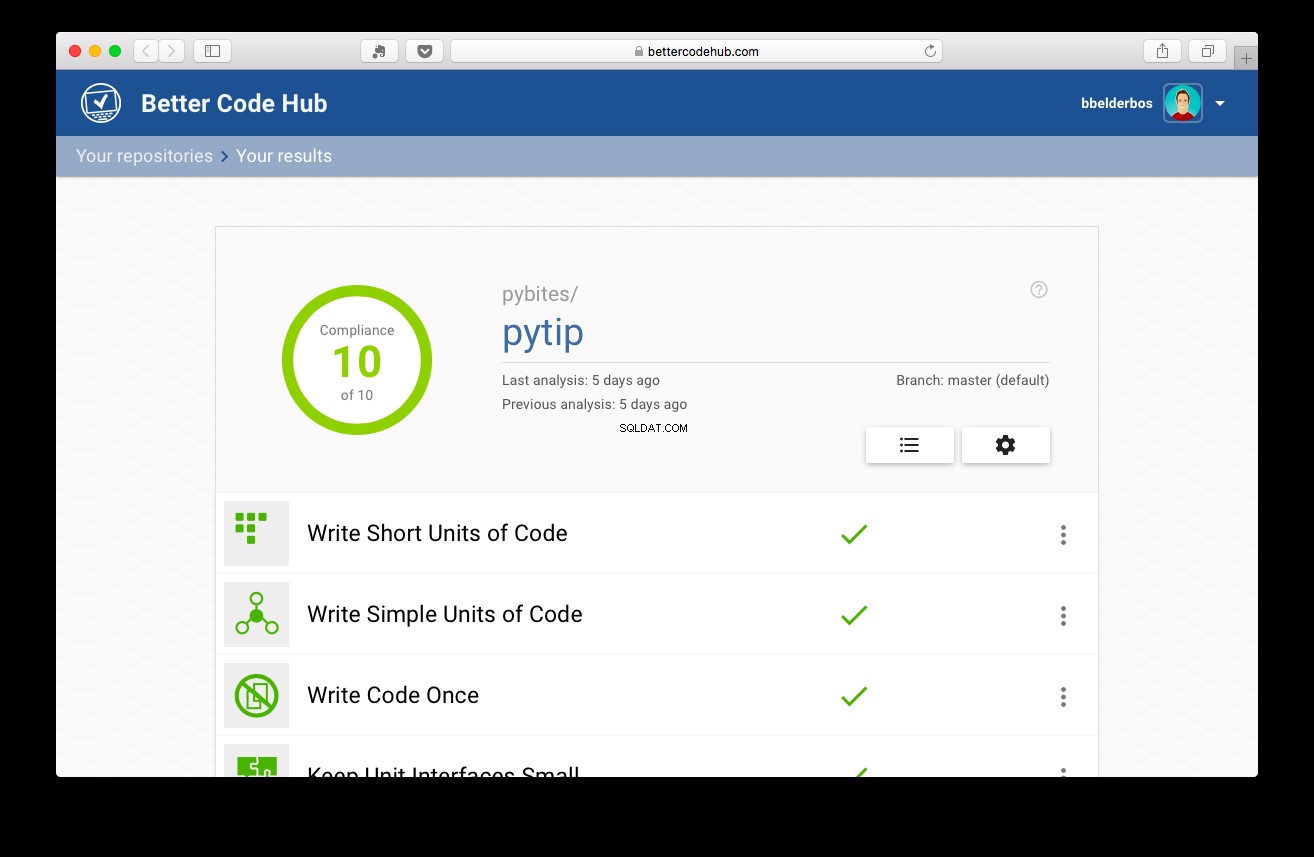
Ik heb het naar een 9 gestoten door de code meer modulair te maken, de DB-logica uit de app.py (webapp) te halen en in de map met tips/pakket te plaatsen (refactoring 1 en 2)
-
Toen de tests waren uitgevoerd, scoorde het project een 10:
Conclusie en leren
Onze Code Challenge #40 bood een aantal goede praktijken:
- Ik heb een handige app gebouwd die kan worden uitgebreid (ik wil een API toevoegen).
- Ik heb een aantal coole modules gebruikt die het ontdekken waard zijn:Tweepy, SQLAlchemy en Bottle.
- Ik heb nog wat pytest geleerd omdat ik fixtures nodig had om de interactie met de DB te testen.
- Bovenal, omdat de code testbaar moest worden gemaakt, werd de app modulairder, waardoor hij gemakkelijker te onderhouden was. Better Code Hub was een grote hulp in dit proces.
- Ik heb de app in Heroku geïmplementeerd met behulp van onze stapsgewijze handleiding.
We dagen je uit
De beste manier om uw codeervaardigheden te leren en te verbeteren, is door te oefenen. Bij PyBites hebben we dit concept verstevigd door Python-code-uitdagingen te organiseren. Bekijk onze groeiende collectie, fork de repo en begin met coderen!
Laat het ons weten als je iets gaafs hebt gebouwd door een Pull Request te maken van je werk. We hebben gezien dat mensen zich door deze uitdagingen echt uitsloofden, en wij ook.
Veel plezier met coderen!