Oorspronkelijk gepost op Serverless op 2 juli 2019

Het ontsluiten van een eenvoudige database via een GraphQL API vereist veel aangepaste code en infrastructuur:waar of niet waar?
Voor degenen die 'waar' hebben geantwoord, zijn we hier om u te laten zien dat het bouwen van GraphQL-API's eigenlijk vrij eenvoudig is, met enkele concrete voorbeelden om te illustreren waarom en hoe.
(Als u al weet hoe eenvoudig het is om GraphQL API's te bouwen met Serverless, staat er ook genoeg voor u in dit artikel.)
GraphQL is een querytaal voor web-API's. Er is een belangrijk verschil tussen een conventionele REST API en API's op basis van GraphQL:met GraphQL kun je één verzoek gebruiken om meerdere entiteiten tegelijk op te halen. Dit resulteert in sneller laden van pagina's en maakt een eenvoudigere structuur voor uw frontend-apps mogelijk, wat resulteert in een betere webervaring voor iedereen. Als je GraphQL nog nooit eerder hebt gebruikt, raden we je aan deze GraphQL-zelfstudie te bekijken voor een snelle introductie.
Het Serverless-framework past uitstekend bij GraphQL API's:met Serverless hoeft u zich geen zorgen te maken over het uitvoeren, beheren en schalen van uw eigen API-servers in de cloud, en hoeft u geen scripts voor infrastructuurautomatisering te schrijven. Lees hier meer over Serverless. Bovendien biedt Serverless een uitstekende leverancieronafhankelijke ontwikkelaarservaring en een robuuste community om u te helpen bij het bouwen van uw GraphQL-applicaties.
Veel applicaties in onze dagelijkse ervaring bevatten functies voor sociale netwerken, en dat soort functionaliteit kan echt profiteren van de implementatie van GraphQL in plaats van het REST-model, waar het moeilijk is om structuren bloot te leggen met geneste entiteiten, zoals gebruikers en hun Twitter-berichten. Met GraphQL kun je een uniform API-eindpunt bouwen waarmee je alle entiteiten die je nodig hebt kunt opvragen, schrijven en bewerken met een enkel API-verzoek.
In dit artikel bekijken we hoe u een eenvoudige GraphQL-API kunt bouwen met behulp van het Serverless-framework, Node.js en een van de verschillende gehoste database-oplossingen die beschikbaar zijn via Amazon RDS:MySQL, PostgreSQL en de MySQL-werkachtige Amazon Aurora.
Volg deze voorbeeldrepository op GitHub en laten we erin duiken!
Een GraphQL API bouwen met een relationele DB-backend
In ons voorbeeldproject hebben we besloten om alle drie de databases (MySQL, PostgreSQL en Aurora) in dezelfde codebase te gebruiken. We weten dat dat zelfs voor een productie-app overdreven is, maar we wilden je wegblazen met hoe we op webschaal bouwen.
Maar serieus, we hebben het project te vol gezet om er zeker van te zijn dat u een relevant voorbeeld zou vinden dat van toepassing is op uw favoriete database. Als je voorbeelden met andere databases wilt zien, laat het ons dan weten in de comments.
Het GraphQL-schema definiëren
Laten we beginnen met het definiëren van het schema van de GraphQL API die we willen maken, wat we doen in het schema.gql-bestand in de hoofdmap van ons project met behulp van de GraphQL-syntaxis. Als u niet bekend bent met deze syntaxis, bekijk dan de voorbeelden op deze GraphQL-documentatiepagina.
Om te beginnen voegen we de eerste twee items toe aan het schema:een gebruikersentiteit en een post-entiteit, waarbij we ze als volgt definiëren, zodat aan elke gebruiker meerdere post-entiteiten kunnen worden gekoppeld:
typ Gebruiker {
UUID:tekenreeks
Naam:String
Berichten:[Post]
}
typ Bericht {
UUID:tekenreeks
Tekst:Tekenreeks
}
We kunnen nu zien hoe de entiteiten User en Post eruitzien. Later zorgen we ervoor dat deze velden direct in onze databases kunnen worden opgeslagen.
Laten we vervolgens definiëren hoe gebruikers van de API deze entiteiten zullen opvragen. Hoewel we de twee GraphQL-typen User en Post rechtstreeks in onze GraphQL-query's kunnen gebruiken, is het het beste om in plaats daarvan invoertypen te maken om het schema eenvoudig te houden. Dus we gaan door en voegen twee van deze invoertypes toe, één voor de berichten en één voor de gebruikers:
invoer UserInput {
Naam:String
Berichten:[PostInput]
}
invoer PostInput {
Tekst:Tekenreeks
}
Laten we nu de mutaties definiëren - de bewerkingen die de gegevens wijzigen die zijn opgeslagen in onze databases via onze GraphQL API. Hiervoor maken we een Mutatietype aan. De enige mutatie die we voor nu zullen gebruiken is createUser. Omdat we drie verschillende databases gebruiken, voegen we een mutatie toe voor elk databasetype. Elk van de mutaties accepteert de invoer UserInput en retourneert een gebruikersentiteit:
We willen ook een manier bieden om de gebruikers te bevragen, dus we creëren een Query-type met één query per databasetype. Elke query accepteert een tekenreeks die de UUID van de gebruiker is, en retourneert de gebruikersentiteit die zijn naam, UUID, en een verzameling van elke bijbehorende Pos``t bevat:
Ten slotte definiëren we het schema en verwijzen we naar de typen Query en Mutatie:
schema { query: Query mutation: Mutation }
We hebben nu een volledige beschrijving voor onze nieuwe GraphQL API! Je kunt het hele bestand hier bekijken.
Behandelaars definiëren voor de GraphQL API
Nu we een beschrijving hebben van onze GraphQL API, kunnen we de code schrijven die we nodig hebben voor elke query en mutatie. We beginnen met het maken van een handler.js-bestand in de hoofdmap van het project, direct naast het schema.gql-bestand dat we eerder hebben gemaakt.
De eerste taak van handler.js is om het schema te lezen:
De constante typeDefs bevat nu de definities voor onze GraphQL-entiteiten. Vervolgens specificeren we waar de code voor onze functies gaat leven. Om het overzichtelijk te houden, maken we voor elke zoekopdracht en mutatie een apart bestand aan:
De resolvers-constante bevat nu de definities voor al onze API-functies. Onze volgende stap is het maken van de GraphQL-server. Herinner je je de graphql-yoga-bibliotheek die we hierboven nodig hadden? We gebruiken die bibliotheek hier om eenvoudig en snel een werkende GraphQL-server te maken:
Ten slotte exporteren we de GraphQL-handler samen met de GraphQL Playground-handler (waardoor we onze GraphQL-API in een webbrowser kunnen uitproberen):
Oké, we zijn voorlopig klaar met het handler.js-bestand. Volgende:code schrijven voor alle functies die toegang hebben tot de databases.
Schrijfcode voor de queries en de mutaties
We hebben nu code nodig om toegang te krijgen tot de databases en om onze GraphQL API aan te sturen. In de hoofdmap van ons project creëren we de volgende structuur voor onze MySQL-resolverfuncties, en de andere databases zullen volgen:
Veelvoorkomende vragen
In de map Common vullen we het mysql.js-bestand met wat we nodig hebben voor de createUser-mutatie en de getUser-query:een init-query, om tabellen te maken voor gebruikers en posts als ze nog niet bestaan; en een gebruikersquery, om de gegevens van een gebruiker te retourneren bij het maken en opvragen van een gebruiker. We gebruiken dit in zowel de mutatie als de zoekopdracht.
De init-query maakt als volgt zowel de tabellen Users als de Posts:
De getUser-query retourneert de gebruiker en hun berichten:
Beide functies worden geëxporteerd; we kunnen ze dan openen in het bestand handler.js.
De mutatie schrijven
Tijd om de code te schrijven voor de createUser-mutatie, die de naam van de nieuwe gebruiker moet accepteren, evenals een lijst met alle berichten die bij hen horen. Om dit te doen, maken we het bestand resolver/Mutation/mysql_createUser.js met een enkele geëxporteerde func-functie voor de mutatie:
De mutatiefunctie moet de volgende dingen doen, in volgorde:
-
Maak verbinding met de database met behulp van de inloggegevens in de omgevingsvariabelen van de toepassing.
-
Voeg de gebruiker toe aan de database met behulp van de gebruikersnaam die is opgegeven als invoer voor de mutatie.
-
Voeg ook eventuele berichten toe die aan de gebruiker zijn gekoppeld en die als invoer voor de mutatie zijn opgegeven.
-
Retourneer de aangemaakte gebruikersgegevens.
Hier is hoe we dat in code bereiken:
U kunt het volledige bestand dat de mutatie definieert hier bekijken.
De vraag schrijven
De getUser-query heeft een structuur die lijkt op de mutatie die we zojuist hebben geschreven, maar deze is nog eenvoudiger. Nu de functie getUser zich in de Common namespace bevindt, hebben we geen aangepaste SQL meer nodig in de query. Dus maken we het bestand resolver/Query/mysql_getUser.js als volgt:
U kunt de volledige query in dit bestand zien.
Alles samenbrengen in het bestand serverless.yml
Laten we een stap terug doen. We hebben momenteel het volgende:
-
Een GraphQL API-schema.
-
Een handler.js-bestand.
-
Een bestand voor veelvoorkomende databasequery's.
-
Een bestand voor elke mutatie en query.
De laatste stap is om dit alles met elkaar te verbinden via het bestand serverless.yml. We creëren een lege serverless.yml aan de basis van het project en beginnen met het definiëren van de provider, de regio en de runtime. We passen ook de LambdaRole IAM-rol (die we later hier definiëren) toe op ons project:
Vervolgens definiëren we de omgevingsvariabelen voor de databasereferenties:
Merk op dat alle variabelen verwijzen naar de aangepaste sectie, die hierna komt en de werkelijke waarden voor de variabelen bevat. Merk op dat wachtwoord een verschrikkelijk wachtwoord is voor uw database en moet worden gewijzigd in iets veiligers (misschien p@ssw0rd 😃):
Wat zijn die verwijzingen na Fn::GettAtt, vraag je? Die verwijzen naar databasebronnen:
Het bestand resource/MySqlRDSInstance.yml definieert alle kenmerken van de MySQL-instantie. De volledige inhoud vind je hier.
Ten slotte definiëren we in het bestand serverless.yml twee functies, graphql en playground. De graphql-functie zal alle API-verzoeken afhandelen en het eindpunt van de speeltuin zal een instantie van GraphQL Playground voor ons maken, wat een geweldige manier is om onze GraphQL API in een webbrowser uit te proberen:
Nu is MySQL-ondersteuning voor onze applicatie compleet!
Je kunt de volledige inhoud van het serverless.yml-bestand hier vinden.
Aurora- en PostgreSQL-ondersteuning toevoegen
We hebben al de structuur gecreëerd die we nodig hebben om andere databases in dit project te ondersteunen. Om ondersteuning voor Aurora en Postgres toe te voegen, hoeven we alleen de code voor hun mutaties en zoekopdrachten te definiëren, wat we als volgt doen:
-
Voeg een Common Query-bestand toe voor Aurora en voor Postgres.
-
Voeg de createUser-mutatie toe voor beide databases.
-
Voeg de getUser-query toe voor beide databases.
-
Voeg configuratie toe aan het bestand serverless.yml voor alle omgevingsvariabelen en bronnen die nodig zijn voor beide databases.
Op dit moment hebben we alles wat we nodig hebben om onze GraphQL API te implementeren, mogelijk gemaakt door MySQL, Aurora en PostgreSQL.
De GraphQL API implementeren en testen
De implementatie van onze GraphQL API is eenvoudig.
-
Eerst voeren we npm install uit om onze afhankelijkheden op hun plaats te zetten.
-
Vervolgens voeren we npm run deploy uit, waarmee al onze omgevingsvariabelen worden ingesteld en de implementatie wordt uitgevoerd.
-
Onder de motorkap voert deze opdracht serverless deploy uit met de juiste omgeving.
Dat is het! In de uitvoer van de implementatiestap zien we het URL-eindpunt voor onze geïmplementeerde toepassing. We kunnen POST-verzoeken naar onze GraphQL API sturen met behulp van deze URL, en onze Playground (waar we zo mee spelen) is beschikbaar met GET tegen dezelfde URL.
De API uitproberen in de GraphQL Playground
De GraphQL Playground, die je ziet als je die URL in de browser bezoekt, is een geweldige manier om onze API uit te proberen.
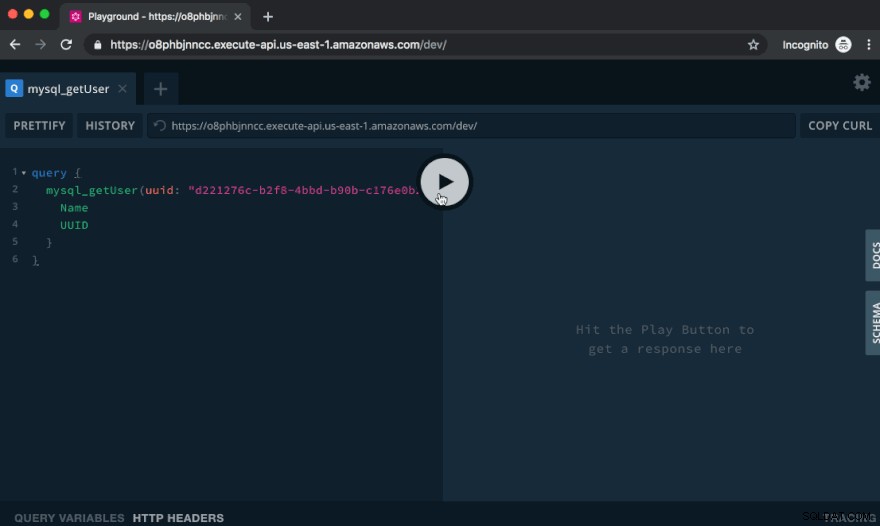
Laten we een gebruiker aanmaken door de volgende mutatie uit te voeren:
mutation { mysql_createUser( input: { Name: "Cicero" Posts: [ { Text: "Lorem ipsum dolor sit amet, consectetur adipiscing elit." } { Text: "Proin consequat mauris orci, ut consequat purus efficitur vel." } ] } ) { Name UUID } }
In deze mutatie noemen we de mysql_createUser API, leveren we de tekst van de berichten van de nieuwe gebruiker en geven we aan dat we de gebruikersnaam en de UUID terug willen krijgen als antwoord.
Plak de bovenstaande tekst in de linkerkant van de Playground en klik op de Play-knop. Aan de rechterkant ziet u de uitvoer van de query:
Laten we nu een vraag stellen voor deze gebruiker:
query { mysql_getUser(uuid: "f5593682-6bf1-466a-967d-98c7e9da844b") { Name UUID } }
Dit geeft ons de naam en de UUID terug van de gebruiker die we zojuist hebben gemaakt. Keurig!
We kunnen hetzelfde doen met de andere backends, PostgreSQL en Aurora. Daarvoor hoeven we alleen de namen van de mutatie te vervangen door postgres_createUser of aurora_createUser, en queries door postgres_getUser of aurora_getUser. Probeer het zelf! (Houd er rekening mee dat de gebruikers niet worden gesynchroniseerd tussen de databases, dus u kunt alleen zoeken naar gebruikers die u in elke specifieke database heeft gemaakt.)
De MySQL-, PostgreSQL- en Aurora-implementaties vergelijken
Om te beginnen zien mutaties en queries er precies hetzelfde uit op Aurora en MySQL, aangezien Aurora MySQL-compatibel is. En er zijn slechts minimale codeverschillen tussen die twee en de Postgres-implementatie.
Voor eenvoudige gebruikssituaties is het grootste verschil tussen onze drie databases zelfs dat Aurora alleen als cluster beschikbaar is. De kleinst beschikbare Aurora-configuratie bevat nog steeds een alleen-lezen- en een schrijfreplica, dus we hebben zelfs voor deze standaard Aurora-implementatie een geclusterde configuratie nodig.
Aurora biedt snellere prestaties dan MySQL en PostgreSQL, voornamelijk dankzij de SSD-optimalisaties die Amazon aan de database-engine heeft aangebracht. Naarmate uw project groeit, zult u waarschijnlijk merken dat Aurora verbeterde databaseschaalbaarheid, eenvoudiger onderhoud en betere betrouwbaarheid biedt in vergelijking met de standaard MySQL- en PostgreSQL-configuraties. Maar u kunt enkele van deze verbeteringen ook aanbrengen in MySQL en PostgreSQL als u uw databases afstemt en replicatie toevoegt.
Voor testprojecten en speeltuinen raden we MySQL of PostgreSQL aan. Deze kunnen worden uitgevoerd op db.t2.micro RDS-instanties, die deel uitmaken van de gratis laag van AWS. Aurora biedt momenteel geen db.t2.micro-instanties, dus u betaalt wat meer om Aurora voor dit testproject te gebruiken.
Een laatste belangrijke opmerking
Vergeet niet om uw serverloze implementatie te verwijderen zodra u klaar bent met het uitproberen van de GraphQL API, zodat u niet blijft betalen voor databasebronnen die u niet meer gebruikt.
U kunt de in dit voorbeeld gemaakte stapel verwijderen door npm run remove in de hoofdmap van het project uit te voeren.
Veel plezier met experimenteren!
Samenvatting
In dit artikel hebben we u begeleid bij het maken van een eenvoudige GraphQL API, waarbij u drie verschillende databases tegelijk gebruikt; hoewel dit in werkelijkheid niet iets is dat u ooit zou doen, stelde het ons in staat om eenvoudige implementaties van de Aurora-, MySQL- en PostgreSQL-databases te vergelijken. We hebben gezien dat de implementatie voor alle drie de databases in ons eenvoudige geval ongeveer hetzelfde is, met uitzondering van kleine verschillen in de syntaxis en de implementatieconfiguraties.
Je kunt het volledige voorbeeldproject dat we hebben gebruikt in deze GitHub-repo vinden. De eenvoudigste manier om met het project te experimenteren, is door de opslagplaats te klonen en deze vanaf uw computer te implementeren met npm run deploy.
Voor meer GraphQL API-voorbeelden die Serverless gebruiken, bekijk de serverless-graphql repo.
Als u meer wilt weten over het op grote schaal uitvoeren van serverloze GraphQL-API's, kunt u genieten van onze artikelreeks "Een schaalbaar en betrouwbaar GraphQL-eindpunt uitvoeren met serverloos"
Misschien is GraphQL gewoon niet jouw probleem en implementeert u liever een REST API? We hebben je gedekt:bekijk deze blogpost voor enkele voorbeelden.
Vragen? Reageer op dit bericht of maak een discussie op ons forum.
Oorspronkelijk gepubliceerd op https://www.serverless.com.