Primaire en externe sleutels zijn fundamentele kenmerken van relationele databases, zoals oorspronkelijk vermeld in het artikel van E.F. Codd, "A Relational Model of Data for Large Shared Data Banks", gepubliceerd in 1970. Het vaak herhaalde citaat is:"The key, the whole key, en niets anders dan de sleutel, dus help me Codd."
Achtergrond:primaire toetsen
Een primaire sleutel is een beperking in SQL Server, die elke rij in een tabel op unieke wijze identificeert. De sleutel kan worden gedefinieerd als een enkele niet-NULL-kolom of een combinatie van niet-NULL-kolommen die een unieke waarde genereert en wordt gebruikt om entiteitsintegriteit voor een tabel af te dwingen. Een tabel kan slechts één primaire sleutel hebben en wanneer een primaire sleutelbeperking voor een tabel is gedefinieerd, wordt een unieke index gemaakt. Die index is standaard een geclusterde index, tenzij gespecificeerd als een niet-geclusterde index wanneer de primaire sleutelbeperking is gedefinieerd.
Overweeg de Sales.SalesOrderHeader tabel in de AdventureWorks2012 databank. Deze tabel bevat basisinformatie over een verkooporder, inclusief orderdatum en klant-ID, en elke verkoop wordt uniek geïdentificeerd door een SalesOrderID , wat de primaire sleutel voor de tabel is. Elke keer dat een nieuwe rij aan de tabel wordt toegevoegd, wordt de primaire sleutelbeperking (genaamd PK_SalesOrderHeader_SalesOrderID ) wordt gecontroleerd om er zeker van te zijn dat er al geen rij bestaat met dezelfde waarde voor SalesOrderID .
Buitenlandse sleutels
Gescheiden van primaire sleutels, maar zeer verwant, zijn externe sleutels. Een refererende sleutel is een kolom of combinatie van kolommen die hetzelfde is als de primaire sleutel, maar in een andere tabel. Buitenlandse sleutels worden gebruikt om een relatie te definiëren en integriteit tussen twee tabellen af te dwingen.
Om het bovengenoemde voorbeeld te blijven gebruiken, de SalesOrderID kolom bestaat als een externe sleutel in de Sales.SalesOrderDetail tabel, waarin aanvullende informatie over de verkoop wordt opgeslagen, zoals product-ID en prijs. Wanneer een nieuwe verkoop wordt toegevoegd aan de SalesOrderHeader tabel, is het niet verplicht om een rij voor die verkoop toe te voegen aan de SalesOrderDetail tabel Wanneer u echter een rij toevoegt aan de SalesOrderDetail tabel, een corresponderende rij voor de SalesOrderID moet bestaan in de SalesOrderHeader tafel.
Omgekeerd, bij het verwijderen van gegevens, een rij voor een specifieke SalesOrderID kan op elk moment worden verwijderd uit de SalesOrderDetail tabel, maar om een rij te verwijderen uit de SalesOrderHeader tabel, bijbehorende rijen van SalesOrderDetail moet eerst worden verwijderd.
In tegenstelling tot primaire-sleutelbeperkingen, wanneer een externe-sleutelbeperking is gedefinieerd voor een tabel, wordt er standaard geen index gemaakt door SQL Server. Het is echter niet ongebruikelijk dat ontwikkelaars en databasebeheerders ze handmatig toevoegen. De externe sleutel kan deel uitmaken van een samengestelde primaire sleutel voor de tabel, in welk geval er een geclusterde index zou bestaan met de externe sleutel als onderdeel van de clustersleutel. Als alternatief kunnen query's een index vereisen die de externe sleutel en een of meer extra kolommen in de tabel bevat, zodat er een niet-geclusterde index wordt gemaakt om die query's te ondersteunen. Verder kunnen indexen op externe sleutels prestatievoordelen bieden voor tabeljoins waarbij de primaire en externe sleutel betrokken zijn, en ze kunnen van invloed zijn op de prestaties wanneer de primaire sleutelwaarde wordt bijgewerkt of als de rij wordt verwijderd.
In de AdventureWorks2012 database, is er één tabel, SalesOrderDetail , met SalesOrderID als vreemde sleutel. Voor de SalesOrderDetail tabel, SalesOrderID en SalesOrderDetailID combineren om de primaire sleutel te vormen, ondersteund door een geclusterde index. Als de SalesOrderDetail tabel had geen index op de SalesOrderID kolom, en wanneer een rij wordt verwijderd uit SalesOrderHeader , zou SQL Server moeten verifiëren dat er geen rijen zijn voor dezelfde SalesOrderID waarde bestaan. Zonder indexen die de SalesOrderID . bevatten kolom, zou SQL Server een volledige tabelscan moeten uitvoeren van SalesOrderDetail . Zoals je je kunt voorstellen, hoe groter de tabel waarnaar wordt verwezen, hoe langer het verwijderen duurt.
Een voorbeeld
We kunnen dit zien in het volgende voorbeeld, waarin gebruik wordt gemaakt van kopieën van de bovengenoemde tabellen uit de AdventureWorks2012 database die zijn uitgebreid met een script dat hier te vinden is. Het script is ontwikkeld door Jonathan Kehayias (blog | @SQLPoolBoy) en creëert een SalesOrderHeaderEnlarged tabel met 1.258.600 rijen en een SalesOrderDetailEnlarged tafel met 4.852.680 rijen. Nadat het script was uitgevoerd, werd de externe-sleutelbeperking toegevoegd met behulp van de onderstaande instructies. Merk op dat de beperking is gemaakt met de ON DELETE CASCADE optie. Met deze optie, wanneer een update of verwijdering wordt uitgevoerd tegen de SalesOrderHeaderEnlarged tabel, rijen in de corresponderende tabel(len) – in dit geval gewoon SalesOrderDetailEnlarged – worden bijgewerkt of verwijderd.
Bovendien is de standaard, geclusterde index voor SalesOrderDetailEnglarged is verwijderd en opnieuw gemaakt om gewoon SalesOrderDetailID . te hebben als de primaire sleutel, omdat het een typisch ontwerp vertegenwoordigt.
USE [AdventureWorks2012];
GO
/* remove original clustered index */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
DROP CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID];
GO
/* re-create clustered index with SalesOrderDetailID only */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
ADD CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderDetailID] PRIMARY KEY CLUSTERED
(
[SalesOrderDetailID] ASC
)
WITH
(
PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON
) ON [PRIMARY];
GO
/* add foreign key constraint for SalesOrderID */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged] WITH CHECK
ADD CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID]
FOREIGN KEY([SalesOrderID])
REFERENCES [Sales].[SalesOrderHeaderEnlarged] ([SalesOrderID])
ON DELETE CASCADE;
GO
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
CHECK CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID];
GO
Met de externe sleutelbeperking en zonder ondersteunende index, werd een enkele verwijdering uitgevoerd tegen de SalesOrderHeaderEnlarged tabel, wat resulteerde in de verwijdering van één rij uit SalesOrderHeaderEnlarged en 72 rijen van SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 292104;
De statistieken IO en timing informatie toonden het volgende:
SQL Server ontleden en compileren tijd:CPU-tijd =8 ms, verstreken tijd =8 ms.
Tabel 'SalesOrderDetailEnlarged'. Scan count 1, logische leest 50647, fysieke leest 8, read-ahead leest 50667, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Tabel 'Werktafel'. Scantelling 2, logische leest 7, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Tabel 'SalesOrderHeaderEnlarged'. Scantelling 0, logische leest 15, fysieke leest 14, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Uitvoeringstijden SQL Server:
CPU-tijd =1045 ms, verstreken tijd =1898 ms.
Met behulp van SQL Sentry Plan Explorer toont het uitvoeringsplan een geclusterde indexscan tegen SalesOrderDetailEnlarged omdat er geen index is op SalesOrderID :
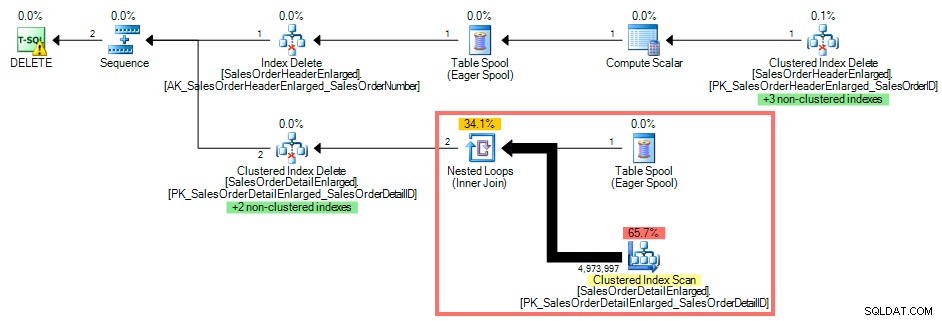
Queryplan zonder index op de externe sleutel
De niet-geclusterde index ter ondersteuning van SalesOrderDetailEnlarged werd vervolgens gemaakt met behulp van de volgende verklaring:
USE [AdventureWorks2012]; GO /* create nonclustered index */ CREATE NONCLUSTERED INDEX [IX_SalesOrderDetailEnlarged_SalesOrderID] ON [Sales].[SalesOrderDetailEnlarged] ( [SalesOrderID] ASC ) WITH ( PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY]; GO
Er is nog een verwijdering uitgevoerd voor een SalesOrderID die van invloed was op één rij in SalesOrderHeaderEnlarged en 72 rijen in SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 697505;
De IO-statistieken en timinginformatie lieten een dramatische verbetering zien:
SQL Server ontleden en compileren tijd:CPU-tijd =0 ms, verstreken tijd =7 ms.
Tabel 'SalesOrderDetailEnlarged'. Scan count 1, logische leest 48, fysieke leest 13, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Tabel 'Werktabel'. Scantelling 2, logische leest 7, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Tabel 'SalesOrderHeaderEnlarged'. Scantelling 0, logische leest 15, fysieke leest 15, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Uitvoeringstijden SQL Server:
CPU-tijd =0 ms, verstreken tijd =27 ms.
En het zoekplan toonde een indexzoekopdracht van de niet-geclusterde index op SalesOrderID , zoals verwacht:
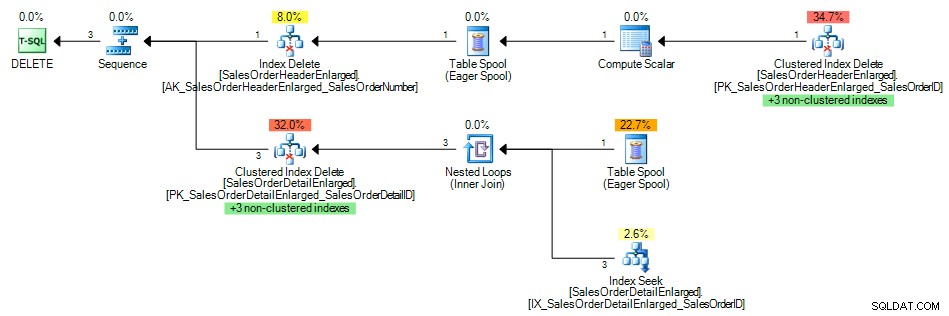
Queryplan met index op de externe sleutel
De uitvoeringstijd van de query daalde van 1898 ms naar 27 ms - een reductie van 98,58%, en leesbewerkingen voor de SalesOrderDetailEnlarged tafel daalde van 50647 naar 48 – een verbetering van 99,9%. Afgezien van de percentages, overweeg dan alleen de I/O die door het verwijderen wordt gegenereerd. De SalesOrderDetailEnlarged tabel is in dit voorbeeld slechts 500 MB, en voor een systeem met 256 GB beschikbaar geheugen lijkt een tabel die 500 MB in beslag neemt in de buffercache geen verschrikkelijke situatie. Maar een tabel van 5 miljoen rijen is relatief klein; de meeste grote OLTP-systemen hebben tabellen met honderden miljoenen rijen. Bovendien is het niet ongebruikelijk dat er meerdere refererende-sleutelverwijzingen bestaan voor een primaire sleutel, waarbij het verwijderen van de primaire sleutel verwijderingen uit meerdere gerelateerde tabellen vereist. In dat geval is het mogelijk om langere duur voor verwijderingen te zien, wat niet alleen een prestatieprobleem is, maar ook een blokkeringsprobleem, afhankelijk van het isolatieniveau.
Conclusie
Het wordt over het algemeen aanbevolen om een index te maken die leidt naar de externe sleutelkolom(men), om niet alleen joins tussen de primaire en externe sleutels te ondersteunen, maar ook updates en verwijderingen. Merk op dat dit een algemene aanbeveling is, aangezien er randscenario's zijn waarbij de extra index op de refererende sleutel niet werd gebruikt vanwege de extreem kleine tabelgrootte, en de extra indexupdates een negatieve invloed hadden op de prestaties. Zoals bij alle schemawijzigingen, moeten indextoevoegingen na implementatie worden getest en gecontroleerd. Het is belangrijk ervoor te zorgen dat de aanvullende indexen de gewenste effecten opleveren en geen negatieve invloed hebben op de prestaties van de oplossing. Het is ook vermeldenswaard hoeveel extra ruimte vereist is door de indexen voor de externe sleutels. Dit is essentieel om te overwegen voordat u de indexen maakt, en als ze een voordeel bieden, moet dit worden overwogen voor toekomstige capaciteitsplanning.