Uw verantwoordelijkheden als DBA (of DBCC CHECKDB . U kunt een eind komen door een eenvoudig onderhoudsplan te maken met een "Controleer database-integriteitstaak" - maar in mijn gedachten is dit slechts het aanvinken van een selectievakje.
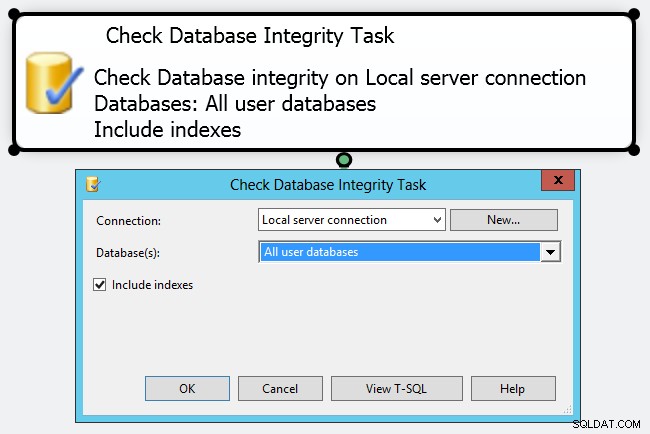
Als je beter kijkt, kun je heel weinig doen om te bepalen hoe de taak werkt. Zelfs het vrij uitgebreide Properties-paneel onthult een heleboel instellingen voor het onderhoudssubplan, maar vrijwel niets over de DBCC opdrachten die het zal uitvoeren. Persoonlijk denk ik dat je een veel proactievere en meer gecontroleerde aanpak moet hanteren bij het uitvoeren van je CHECKDB bewerkingen in productieomgevingen, door uw eigen jobs te creëren en handmatig uw DBCC . te maken commando's. U kunt uw planning of de opdrachten zelf aanpassen aan verschillende databases - de ASP.NET-lidmaatschapsdatabase is bijvoorbeeld waarschijnlijk niet zo cruciaal als uw verkoopdatabase en kan minder frequente en/of minder grondige controles tolereren.
Maar voor uw cruciale databases, dacht ik dat ik een bericht zou samenstellen om enkele van de dingen te beschrijven die ik zou onderzoeken om de verstoring te minimaliseren DBCC commando's kunnen veroorzaken - en voor welke mythen en marketingheuvel je op je hoede moet zijn. En ik wil Paul "Mr. DBCC" Randal (@PaulRandal) bedanken voor het leveren van waardevolle input - niet alleen voor dit specifieke bericht, maar ook voor het eindeloze advies dat hij geeft op zijn blog, #sqlhelp en in SQLskills Immersion-training.
Neem al deze ideeën met een korreltje zout en doe uw best om adequate tests uit te voeren in uw omgeving - niet al deze suggesties zullen in alle omgevingen betere prestaties opleveren. Maar u bent het aan uzelf, uw gebruikers en uw belanghebbenden verplicht om op zijn minst rekening te houden met de impact die uw CHECKDB operaties zou kunnen hebben, en maatregelen nemen om die effecten waar mogelijk te verminderen - zonder onnodige risico's te introduceren door niet de juiste dingen te controleren.
Verminder de ruis en consumeer alle fouten
Het maakt niet uit waar u CHECKDB uitvoert , gebruik altijd de WITH NO_INFOMSGS optie. Dit onderdrukt eenvoudig alle irrelevante uitvoer die u alleen vertelt hoeveel rijen er in elke tabel zijn; als u geïnteresseerd bent in die informatie, kunt u deze verkrijgen via eenvoudige zoekopdrachten tegen DMV's en niet terwijl DBCC is aan het rennen. Door de uitvoer te onderdrukken, is de kans veel kleiner dat u een kritieke boodschap mist die begraven ligt in al die vrolijke uitvoer.
Evenzo moet u altijd de WITH ALL_ERRORMSGS . gebruiken optie, maar vooral als u SQL Server 2008 RTM of SQL Server 2005 gebruikt (in die gevallen ziet u mogelijk de lijst met fouten per object afgekapt tot 200). Voor elke CHECKDB andere bewerkingen dan snelle ad-hoccontroles, kunt u overwegen de uitvoer naar een bestand te sturen. Management Studio is beperkt tot 1000 regels uitvoer van DBCC CHECKDB , dus u kunt enkele fouten mislopen als u dit cijfer overschrijdt.
Hoewel het niet strikt een prestatieprobleem is, zal het gebruik van deze opties voorkomen dat u het proces opnieuw moet uitvoeren. Dit is met name van cruciaal belang als u zich midden in een noodherstel bevindt.
Los logische controles waar mogelijk uit
In de meeste gevallen, CHECKDB besteedt het grootste deel van zijn tijd aan het uitvoeren van logische controles van de gegevens. Als u de mogelijkheid heeft om deze controles uit te voeren op een echte kopie van de gegevens kunt u uw inspanningen concentreren op de fysieke structuur van uw productiesystemen en de secundaire server gebruiken om alle logische controles uit te voeren en de belasting van de primaire te verlichten. Door secundaire server , ik bedoel alleen het volgende:
- De plaats waar u uw volledige herstelbewerkingen test, omdat u uw herstelbewerkingen test, toch?
Andere mensen (met name de gigantische marketingmacht die Microsoft is) hebben je misschien overtuigd dat andere vormen van secundaire servers geschikt zijn voor DBCC cheques. Bijvoorbeeld:
- een AlwaysOn-beschikbaarheidsgroep leesbaar secundair;
- een momentopname van een gespiegelde database;
- een log verzonden secundair;
- SAN-mirroring;
- of andere variaties...
Helaas is dit niet het geval, en geen van deze secondaries zijn geldige, betrouwbare plaatsen om uw controles uit te voeren als alternatief voor de primaire. Alleen een één-op-één back-up kan dienen als een echte kopie; al het andere dat afhankelijk is van zaken als de toepassing van logback-ups om een consistente status te krijgen, zal geen betrouwbare afspiegeling zijn van integriteitsproblemen op de primaire.
Dus in plaats van te proberen uw logische controles over te hevelen naar een secundaire en ze nooit op de primaire uit te voeren, raad ik u het volgende aan:
- Zorg ervoor dat u regelmatig de herstelbewerkingen van uw volledige back-ups test. En nee, dit omvat niet
COPY_ONLYback-ups van een secundaire AG, om dezelfde redenen als hierboven - dat zou alleen geldig zijn in het geval dat u zojuist de secundaire hebt gestart met een volledig herstel. - Voer
DBCC CHECKDBuit vaak tegen de volledige herstellen, voordat u iets anders doet. Nogmaals, het opnieuw afspelen van logrecords op dit punt zal deze database ongeldig maken als een echte kopie van de bron. - Voer
DBCC CHECKDBuit tegen je primaire, misschien opgesplitst op manieren die Paul Randal suggereert, en/of op een minder frequent schema, en/of met behulp vanPHYSICAL_ONLYvaak. Dit kan afhangen van hoe vaak en betrouwbaar u presteert (2). - Ga er nooit vanuit dat controles tegen de secundaire voldoende zijn. Zelfs met een exacte replica van uw primaire database, zijn er nog steeds fysieke problemen die kunnen optreden op het I/O-subsysteem van uw primaire die zich nooit zullen verspreiden naar de secundaire.
- Analyseer altijd
DBCCuitvoer. Gewoon uitvoeren en negeren, om het van een lijst af te strepen, is net zo nuttig als het maken van back-ups en het claimen van succes zonder ooit te testen of je die back-up daadwerkelijk kunt herstellen wanneer dat nodig is.
Experimenteer met traceervlaggen 2549, 2562 en 2566
Ik heb grondig getest met twee traceringsvlaggen (2549 en 2562) en heb ontdekt dat ze aanzienlijke prestatieverbeteringen kunnen opleveren, maar Lonny meldt dat ze niet langer nodig of nuttig zijn. Als je 2016 of nieuwer bent, sla dit hele gedeelte over . Als u een oudere versie gebruikt, worden deze twee traceringsvlaggen veel gedetailleerder beschreven in KB #2634571, maar in wezen:
- Vlag 2549 traceren
- Dit optimaliseert het checkdb-proces door elk afzonderlijk databasebestand te behandelen alsof het zich op een unieke onderliggende schijf bevindt. Dit is prima te gebruiken als uw database een enkel gegevensbestand heeft, of als u weet dat elk databasebestand zich in feite op een aparte schijf bevindt. Als uw database meerdere bestanden heeft en ze delen een enkele, direct aangesloten spindel, moet u op uw hoede zijn voor deze traceringsvlag, omdat deze meer kwaad dan goed kan doen.
BELANGRIJK :sql.sasquatch meldt een regressie in dit traceervlaggedrag in SQL Server 2014.
- Dit optimaliseert het checkdb-proces door elk afzonderlijk databasebestand te behandelen alsof het zich op een unieke onderliggende schijf bevindt. Dit is prima te gebruiken als uw database een enkel gegevensbestand heeft, of als u weet dat elk databasebestand zich in feite op een aparte schijf bevindt. Als uw database meerdere bestanden heeft en ze delen een enkele, direct aangesloten spindel, moet u op uw hoede zijn voor deze traceringsvlag, omdat deze meer kwaad dan goed kan doen.
- Vlag 2562 traceren
- Deze vlag behandelt het hele checkdb-proces als een enkele batch, ten koste van een hoger tempdb-gebruik (tot 5% van de databasegrootte).
- Gebruikt een beter algoritme om te bepalen hoe pagina's uit de database moeten worden gelezen, waardoor vergrendelingsconflicten worden verminderd (specifiek voor
DBCC_MULTIOBJECT_SCANNER). Houd er rekening mee dat deze specifieke verbetering in het codepad van SQL Server 2012 zit, dus u profiteert er zelfs van zonder de traceringsvlag. Dit kan fouten voorkomen zoals:
Er is een time-out opgetreden tijdens het wachten op vergrendeling:class 'DBCC_MULTIOBJECT_SCANNER'.
- De bovenstaande twee traceervlaggen zijn beschikbaar in de volgende versies:
- SQL Server 2008 Service Pack 2 cumulatieve update 9+
(10.00.4330 -> 10.00.5499)SQL Server 2008 Service Pack 3 cumulatieve update 4+
(10.00.5775+)SQL Server 2008 R2 RTM cumulatieve update 11+
(10.50.1809 -> 10.50.2424)SQL Server 2008 R2 Service Pack 1 cumulatieve update 4+
(10.50.2796 -> 10.50.3999)SQL Server 2008 R2 Service Pack 2
(10.50.4.000+)SQL Server 2012, alle versies
(11.00.2100+) - Vlag 2566 traceren
- Als u nog steeds SQL Server 2005 gebruikt, probeert deze traceringsvlag, geïntroduceerd in 2005 SP2 CU#9 (9.00.3282) (hoewel niet gedocumenteerd in het Knowledge Base-artikel van de cumulatieve update, KB #953752), slechte prestaties te corrigeren van
DATA_PURITYcontroles op x64-gebaseerde systemen. Op een gegeven moment kon je meer details zien in KB #945770, maar het lijkt erop dat dat artikel van zowel de ondersteuningssite van Microsoft als de WayBack-machine is verwijderd. Deze traceringsvlag zou niet nodig moeten zijn in modernere versies van SQL Server, aangezien het probleem in de queryprocessor is opgelost.
- Als u nog steeds SQL Server 2005 gebruikt, probeert deze traceringsvlag, geïntroduceerd in 2005 SP2 CU#9 (9.00.3282) (hoewel niet gedocumenteerd in het Knowledge Base-artikel van de cumulatieve update, KB #953752), slechte prestaties te corrigeren van
Als je een van deze traceervlaggen gaat gebruiken, raad ik je ten zeerste aan om ze op sessieniveau in te stellen met DBCC TRACEON in plaats van als een opstarttraceervlag. U kunt ze niet alleen uitschakelen zonder SQL Server te hoeven doorlopen, maar u kunt ze ook alleen implementeren bij het uitvoeren van bepaalde CHECKDB commando's, in tegenstelling tot bewerkingen die elk type reparatie gebruiken.
Verminder I/O-impact:optimaliseer tempdb
DBCC CHECKDB kan intensief gebruik maken van tempdb, dus zorg ervoor dat u het gebruik van resources daar plant. Dit is in ieder geval meestal een goede zaak. Voor CHECKDB u wilt op de juiste manier ruimte toewijzen aan tempdb; het laatste wat je wilt is voor CHECKDB progress (en alle andere gelijktijdige bewerkingen) om te moeten wachten op een autogrow. U kunt een idee krijgen van de vereisten met behulp van WITH ESTIMATEONLY , zoals Paulus hier uitlegt. Houd er rekening mee dat de schatting vrij laag kan zijn vanwege een bug in SQL Server 2008 R2. Als u traceringsvlag 2562 gebruikt, moet u ook rekening houden met de extra ruimtevereisten.
En natuurlijk is al het typische advies voor het optimaliseren van tempdb op zowat elk systeem ook hier van toepassing:zorg ervoor dat tempdb op zijn eigen set van fast staat spindels, zorg ervoor dat het formaat geschikt is voor alle andere gelijktijdige activiteiten zonder dat het hoeft te groeien, zorg ervoor dat u een optimaal aantal gegevensbestanden gebruikt, enz. Een paar andere bronnen die u zou kunnen overwegen:
- Temdb-prestaties optimaliseren (MSDN)
- Capaciteitsplanning voor tempdb (MSDN)
- Een SQL Server DBA-mythe per dag:(30/12) tempdb zou altijd één gegevensbestand per processorkern moeten hebben
Verminder I/O-impact:beheer de snapshot
Om CHECKDB . uit te voeren , zullen moderne versies van SQL Server proberen een verborgen momentopname van uw database op dezelfde schijf te maken (of op alle schijven als uw gegevensbestanden meerdere schijven beslaan). U kunt dit mechanisme niet controleren, maar als u wilt bepalen waar CHECKDB werkt, maakt u eerst uw eigen snapshot (Enterprise Edition vereist) op elke gewenste schijf en voert u de DBCC uit commando tegen de momentopname. In beide gevallen wilt u deze bewerking uitvoeren tijdens een relatieve uitvaltijd, om de kopieer-op-schrijfactiviteit die door de momentopname gaat, te minimaliseren. En u wilt niet dat dit schema in strijd is met zware schrijfbewerkingen, zoals indexonderhoud of ETL.
Je hebt misschien suggesties gezien om CHECKDB . te forceren om in offline modus te werken met de WITH TABLOCK optie. Ik raad deze aanpak ten zeerste af. Als uw database actief wordt gebruikt, zal het kiezen van deze optie de gebruikers alleen maar frustreren. En als de database niet actief wordt gebruikt, bespaart u geen schijfruimte door een momentopname te vermijden, aangezien er geen kopieer-op-schrijfactiviteit is om op te slaan.
Verminder I/O-impact:vermijd 665 / 1450 / 1452 fouten
In sommige gevallen ziet u mogelijk een van de volgende fouten:
Het besturingssysteem heeft fout 1450 geretourneerd (Er zijn onvoldoende systeembronnen om de gevraagde service te voltooien.) naar SQL Server tijdens een schrijfbewerking op offset 0x[…] in bestand met handle 0x[…]. Dit is meestal een tijdelijke toestand en de SQL Server blijft de bewerking opnieuw proberen. Als de toestand aanhoudt, moet er onmiddellijk actie worden ondernomen om het te corrigeren.
Het besturingssysteem heeft fout 665 geretourneerd (de gevraagde bewerking kon niet worden voltooid vanwege een beperking van het bestandssysteem) naar SQL Server tijdens een schrijfbewerking op offset 0x[…] in bestand '[bestand]'
Er zijn hier enkele tips om het risico op deze fouten te verkleinen tijdens CHECKDB bewerkingen en het verminderen van hun impact in het algemeen - met verschillende beschikbare fixes, afhankelijk van uw besturingssysteem en SQL Server-versie:
- Sparse bestandsfouten:1450 of 665 als gevolg van bestandsfragmentatie:oplossingen en tijdelijke oplossingen
- SQL Server meldt besturingssysteemfout 1450 of 1452 of 665 (opnieuw proberen)
Verminder CPU-impact
DBCC CHECKDB is standaard multi-threaded (maar alleen in Enterprise Edition). Als uw systeem CPU-gebonden is, of u wilt gewoon CHECKDB om minder CPU te gebruiken ten koste van een langere werking, kunt u overwegen om het parallellisme op een aantal verschillende manieren te verminderen:
- Gebruik Resource Governor in 2008 en hoger, zolang u Enterprise Edition gebruikt. Om alleen DBCC-opdrachten voor een bepaalde resourcepool of werklastgroep te targeten, moet u een classificatiefunctie schrijven die de sessies kan identificeren die dit werk zullen uitvoeren (bijvoorbeeld een specifieke login of een job_id).
- Gebruik traceringsvlag 2528 om parallellisme uit te schakelen voor
DBCC CHECKDB(evenalsCHECKFILEGROUPenCHECKTABLE). Traceervlag 2528 wordt hier beschreven. Dit is natuurlijk alleen geldig in Enterprise Edition, want ondanks wat Books Online momenteel zegt, is de waarheid datCHECKDBgaat niet parallel in Standard Edition. - Terwijl de
DBCCcommando zelf ondersteuntMAXDOPniet (tenminste vóór SQL Server 2014 SP2), het respecteert de globale instellingmax degree of parallelism. Waarschijnlijk niet iets wat ik in productie zou doen, tenzij ik geen andere opties had, maar dit is een overkoepelende manier om bepaaldeDBCCte besturen commando's als je ze niet explicieter kunt targeten.
We hadden gevraagd om betere controle over het aantal CPU's dat DBCC CHECKDB gebruikt, maar ze waren herhaaldelijk geweigerd tot SQL Server 2014 SP2. U kunt nu dus WITH MAXDOP = n . toevoegen naar het commando.
Mijn bevindingen
Ik wilde een paar van deze technieken demonstreren in een omgeving die ik kon controleren. Ik installeerde AdventureWorks2012 en breidde het vervolgens uit met behulp van het AW-vergroterscript geschreven door Jonathan Kehayias (blog | @SQLPoolBoy), waardoor de database groeide tot ongeveer 7 GB. Daarna heb ik een reeks CHECKDB . uitgevoerd beveelt ertegen, en timede ze. Ik gebruikte een gewone vanille DBCC CHECKDB op zichzelf, dan worden alle andere commando's gebruikt WITH NO_INFOMSGS, ALL_ERRORMSGS . Daarna vier tests met (a) geen traceervlaggen, (b) 2549, (c) 2562 en (d) zowel 2549 als 2562. Daarna herhaalde ik die vier tests, maar voegde de PHYSICAL_ONLY toe optie, die alle logische controles omzeilt. De resultaten (gemiddeld over 10 testruns) zijn veelzeggend:
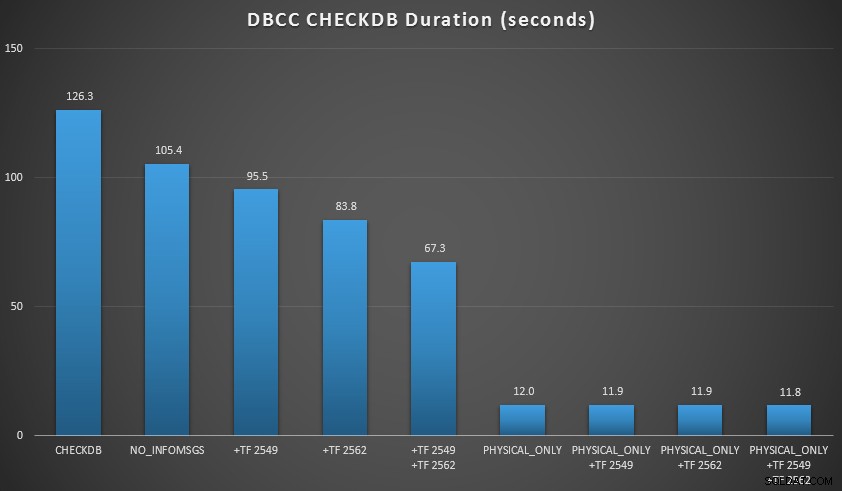
CHECKDB-resultaten vergeleken met 7 GB database
Daarna breidde ik de database nog wat uit, waarbij ik veel kopieën maakte van de twee vergrote tabellen, wat leidde tot een databasegrootte net ten noorden van 70 GB, en voerde de tests opnieuw uit. De resultaten, wederom gemiddeld over 10 testruns:
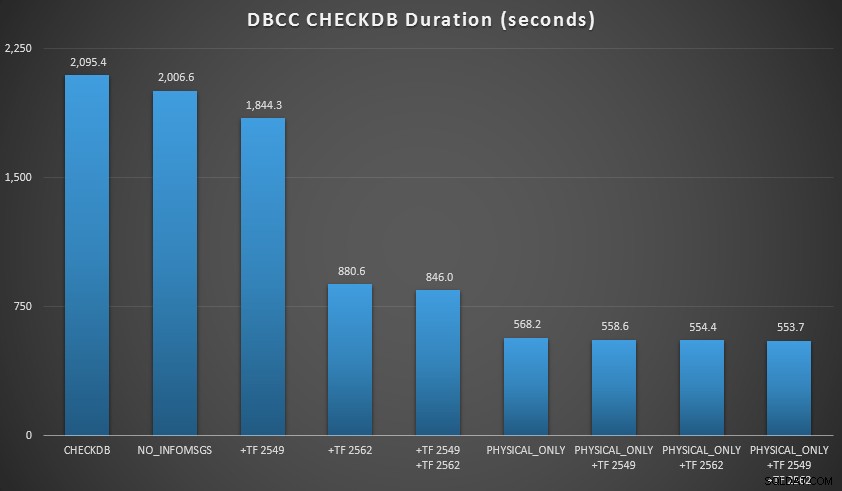
CHECKDB-resultaten vergeleken met een database van 70 GB
In deze twee scenario's heb ik het volgende geleerd (wederom, rekening houdend met het feit dat uw kilometerstand kan variëren en dat u uw eigen tests moet uitvoeren om zinvolle conclusies te trekken):
- Als ik logische controles moet uitvoeren:
- Bij kleine databases is de
NO_INFOMSGSoptie kan de verwerkingstijd aanzienlijk verkorten wanneer de controles worden uitgevoerd in SSMS. Bij grotere databases neemt dit voordeel echter af, omdat de tijd en het werk dat wordt besteed aan het doorgeven van de informatie zo'n onbeduidend deel van de totale duur wordt. 21 seconden van de 2 minuten is aanzienlijk; 88 seconden van de 35 minuten, niet zo veel. - De twee traceervlaggen die ik heb getest, hadden een aanzienlijke invloed op de prestaties – wat neerkomt op een runtime-reductie van 40-60% wanneer beide samen werden gebruikt.
- Bij kleine databases is de
- Als ik logische controles naar een secundaire server kan pushen (nogmaals, ervan uitgaande dat ik elders logische controles uitvoer met een echte kopie ):
- Ik kan de verwerkingstijd op mijn primaire instantie met 70-90% verminderen in vergelijking met een standaard
CHECKDBbellen zonder opties. - In mijn scenario hadden de traceervlaggen weinig invloed op de duur bij het uitvoeren van
PHYSICAL_ONLYcheques.
- Ik kan de verwerkingstijd op mijn primaire instantie met 70-90% verminderen in vergelijking met een standaard
Natuurlijk, en ik kan dit niet genoeg benadrukken, zijn dit relatief kleine databases en worden ze alleen gebruikt om herhaalde, gemeten tests in een redelijke tijd uit te voeren. Deze server had 80 logische CPU's en 128 GB RAM, en ik was de enige gebruiker. Duur en interactie met andere workloads op het systeem kunnen deze resultaten behoorlijk scheeftrekken. Hier is een kort overzicht van typisch CPU-gebruik, met behulp van SQL Sentry, tijdens een van de CHECKDB bewerkingen (en geen van de opties heeft de algehele impact op de CPU echt veranderd, alleen de duur):
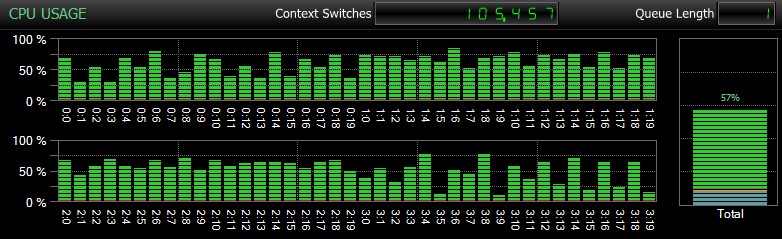
CPU-impact tijdens CHECKDB – voorbeeldmodus
En hier is een andere weergave, die vergelijkbare CPU-profielen toont voor drie verschillende voorbeelden CHECKDB operaties in historische modus (ik heb een beschrijving van de drie tests in dit bereik over elkaar gelegd):
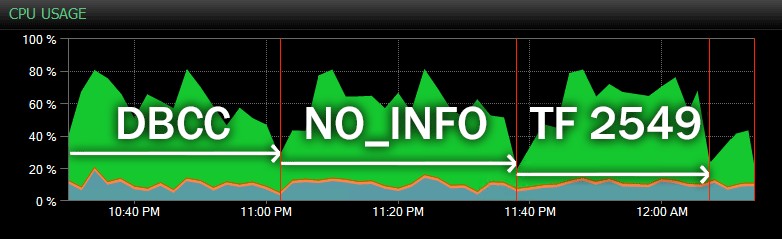
CPU-impact tijdens CHECKDB – historische modus
Op nog grotere databases, gehost op drukkere servers, ziet u mogelijk verschillende effecten, en uw kilometerstand zal waarschijnlijk variëren. Voer dus uw due diligence uit en test deze opties en traceervlaggen tijdens een typische gelijktijdige werkbelasting voordat u beslist hoe u CHECKDB wilt benaderen. .
Conclusie
DBCC CHECKDB is een zeer belangrijk maar vaak ondergewaardeerd onderdeel van uw verantwoordelijkheid als DBA of architect, en cruciaal voor de bescherming van de gegevens van uw bedrijf. Neem deze verantwoordelijkheid niet licht op en doe je best om ervoor te zorgen dat je niets opoffert om de impact op je productie-instanties te verminderen. Het belangrijkste is:kijk verder dan de marketinggegevensbladen om er zeker van te zijn dat u volledig begrijpt hoe geldig die beloften zijn en of u bereid bent de gegevens van uw bedrijf erop te verwedden. Het beknibbelen op sommige cheques of ze overdragen naar ongeldige secundaire locaties kan een ramp zijn die staat te gebeuren.
Overweeg ook om deze PSS-artikelen te lezen:
- Een snellere CHECKDB – Deel I
- Een snellere CHECKDB – Deel II
- Een snellere CHECKDB – Deel III
- Een snellere CHECKDB – Deel IV (SQL CLR UDT's)
En dit bericht van Brent Ozar:
- 3 manieren om DBCC CHECKDB sneller uit te voeren
Tot slot, als u een onopgeloste vraag heeft over DBCC CHECKDB , plaats het in de #sqlhelp-hashtag op Twitter. Paul controleert die tag vaak en aangezien zijn foto in het hoofdartikel van Books Online zou moeten verschijnen, is het waarschijnlijk dat als iemand hem kan beantwoorden, hij het kan. Als het te complex is voor 140 tekens, kun je het hier vragen (en ik zal ervoor zorgen dat Paul het ooit ziet), of posten op een forumsite zoals Database Administrators Stack Exchange.