Een proxylaag kan erg handig zijn om de beschikbaarheid van uw databaselaag te vergroten. Het kan de hoeveelheid code aan de toepassingskant verminderen om databasefouten en wijzigingen in de replicatietopologie te verwerken. In deze blogpost bespreken we hoe je een HAProxy instelt om bovenop PostgreSQL te werken.
Allereerst - HAProxy werkt met databases als een netwerklaagproxy. Er is geen begrip van de onderliggende, soms complexe, topologie. Het enige dat HAProxy doet, is pakketten op round-robin-manier naar gedefinieerde backends sturen. Het inspecteert geen pakketten, noch begrijpt het protocol waarin applicaties met PostgreSQL praten. Als gevolg hiervan is er geen manier voor de HAProxy om lees-/schrijfsplitsing op een enkele poort te implementeren - het zou parseren van query's vereisen. Zolang uw toepassing leesbewerkingen van schrijfbewerkingen kan splitsen en naar verschillende IP's of poorten kan sturen, kunt u R/W-splitsing implementeren met behulp van twee backends. Laten we eens kijken hoe het kan.
HAProxy-configuratie
Hieronder vindt u een voorbeeld van twee PostgreSQL-backends die zijn geconfigureerd in HAProxy.
listen haproxy_10.0.0.101_3307_rw
bind *:3307
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 check
listen haproxy_10.0.0.101_3308_ro
bind *:3308
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running.
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 checkZoals we kunnen zien, gebruiken ze poorten 3307 voor schrijven en 3308 voor lezen. In deze opstelling zijn er drie servers - een actieve en twee standby-replica's. Wat belangrijk is, tcp-check wordt gebruikt om de gezondheid van de knooppunten te volgen. HAProxy maakt verbinding met poort 9201 en verwacht dat er een string wordt geretourneerd. Gezonde leden van de backend zullen de verwachte inhoud retourneren, degenen die de string niet retourneren, worden gemarkeerd als niet beschikbaar.
Xinetd-configuratie
Omdat HAProxy poort 9201 controleert, moet er iets op luisteren. We kunnen xinetd gebruiken om daar te luisteren en enkele scripts voor ons uit te voeren. Voorbeeldconfiguratie van een dergelijke service kan er als volgt uitzien:
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}Je moet ervoor zorgen dat je de volgende regel toevoegt:
postgreschk 9201/tcpnaar de /etc/services.
Xinetd start een postgreschk-script, dat inhoud heeft zoals hieronder:
#!/bin/bash
#
# This script checks if a PostgreSQL server is healthy running on localhost. It will
# return:
# "HTTP/1.x 200 OK\r" (if postgres is running smoothly)
# - OR -
# "HTTP/1.x 500 Internal Server Error\r" (else)
#
# The purpose of this script is make haproxy capable of monitoring PostgreSQL properly
#
export PGHOST='10.0.0.101'
export PGUSER='someuser'
export PGPASSWORD='somepassword'
export PGPORT='5432'
export PGDATABASE='postgres'
export PGCONNECT_TIMEOUT=10
FORCE_FAIL="/dev/shm/proxyoff"
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"
return_ok()
{
echo -e "HTTP/1.1 200 OK\r\n"
echo -e "Content-Type: text/html\r\n"
if [ "$1x" == "masterx" ]; then
echo -e "Content-Length: 56\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL master is running.</body></html>\r\n"
elif [ "$1x" == "slavex" ]; then
echo -e "Content-Length: 55\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL slave is running.</body></html>\r\n"
else
echo -e "Content-Length: 49\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is running.</body></html>\r\n"
fi
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 0
}
return_fail()
{
echo -e "HTTP/1.1 503 Service Unavailable\r\n"
echo -e "Content-Type: text/html\r\n"
echo -e "Content-Length: 48\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is *down*.</body></html>\r\n"
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 1
}
if [ -f "$FORCE_FAIL" ]; then
return_fail;
fi
# check if in recovery mode (that means it is a 'slave')
SLAVE=$(psql -qt -c "$SLAVE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $SLAVE | egrep -i "(t|true|on|1)" 2>/dev/null >/dev/null; then
return_ok "slave"
fi
# check if writable (then we consider it as a 'master')
READONLY=$(psql -qt -c "$WRITABLE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $READONLY | egrep -i "(f|false|off|0)" 2>/dev/null >/dev/null; then
return_ok "master"
fi
return_ok "none";De logica van het script gaat als volgt. Er zijn twee zoekopdrachten die worden gebruikt om de status van het knooppunt te detecteren.
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"De eerste controleert of PostgreSQL in herstel is - het is 'false' voor de actieve server en 'true' voor standby-servers. De tweede controleert of PostgreSQL in de alleen-lezen modus staat. De actieve server keert terug naar 'uit' terwijl standby-servers terugkeren naar 'aan'. Op basis van de resultaten roept het script de functie return_ok() aan met een juiste parameter ('master' of 'slave', afhankelijk van wat er is gedetecteerd). Als de query's zijn mislukt, wordt een 'return_fail'-functie uitgevoerd.
De functie Return_ok retourneert een tekenreeks op basis van het argument dat eraan is doorgegeven. Als de host een actieve server is, retourneert het script "PostgreSQL-master wordt uitgevoerd". Als het een stand-by is, is de geretourneerde tekenreeks:"PostgreSQL-slave wordt uitgevoerd". Als de status niet duidelijk is, wordt geretourneerd:"PostgreSQL is actief". Hier eindigt de lus. HAProxy controleert de status door verbinding te maken met xinetd. De laatste start een script, dat vervolgens een tekenreeks retourneert die door HAProxy wordt geparseerd.
Zoals je je misschien herinnert, verwacht HAProxy de volgende strings:
tcp-check expect string master\ is\ runningvoor de schrijf-backend en
tcp-check expect string is\ running.voor de alleen-lezen backend. Dit maakt de actieve server de enige host die beschikbaar is in de schrijf-backend, terwijl op de lees-backend zowel actieve als standby-servers kunnen worden gebruikt.
PostgreSQL en HAProxy in ClusterControl
De bovenstaande setup is niet ingewikkeld, maar het kost wel wat tijd om het op te zetten. ClusterControl kan worden gebruikt om dit allemaal voor u in te stellen.
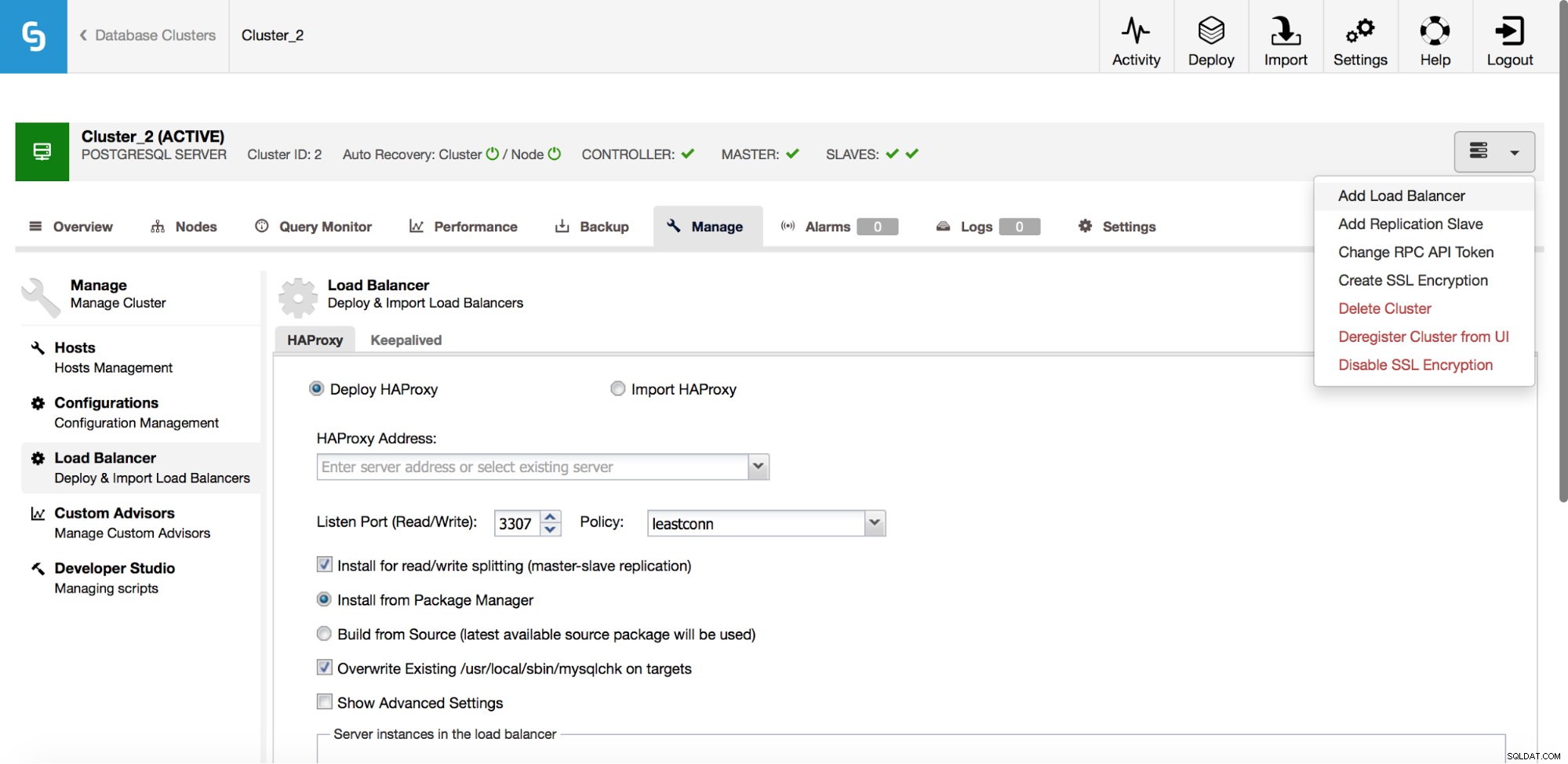
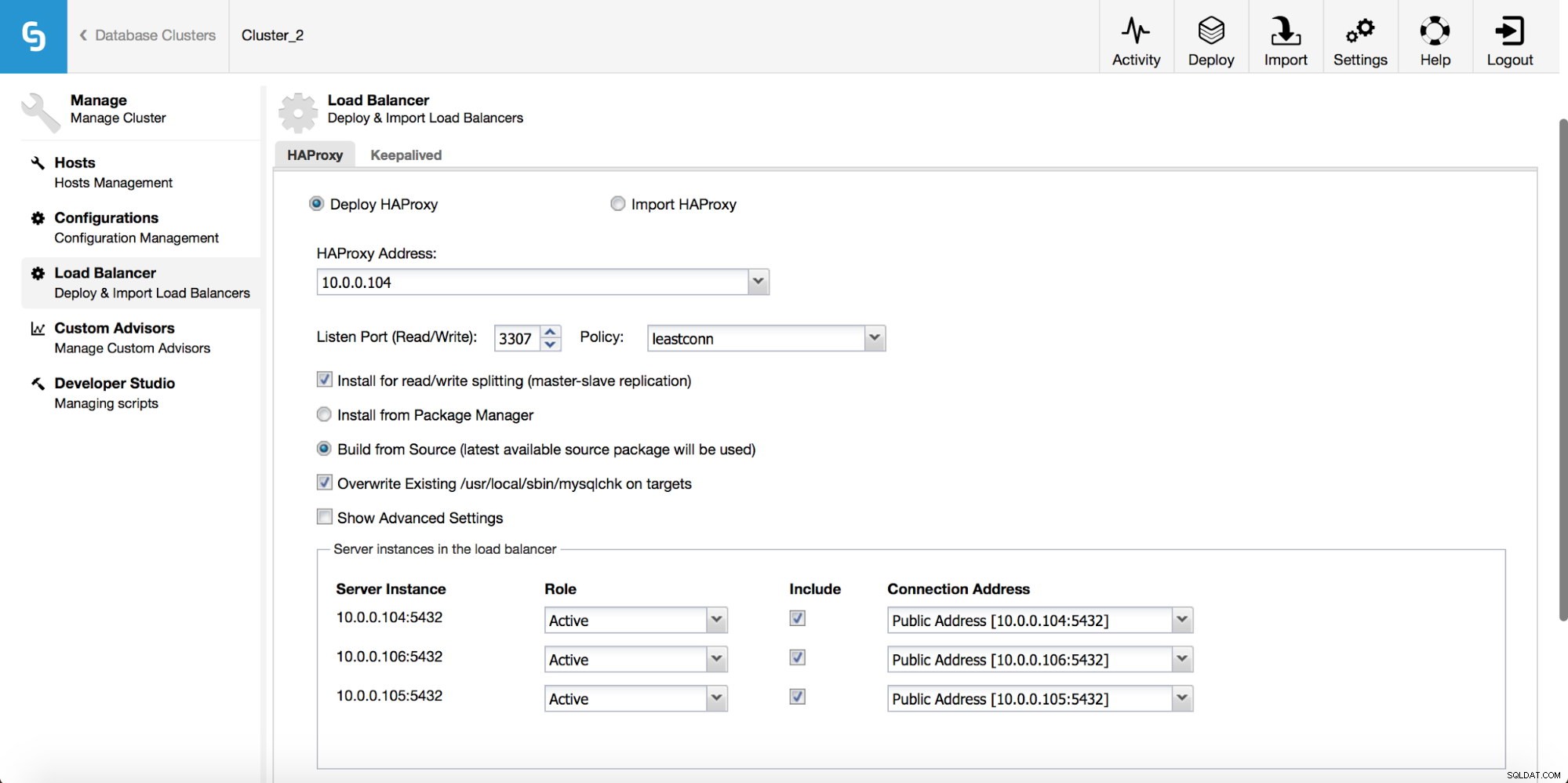
In het vervolgkeuzemenu clustertaak hebt u een optie om een load balancer toe te voegen. Dan verschijnt er een optie om HAProxy te implementeren. Je moet invullen waar je het wilt installeren en een aantal beslissingen nemen:vanuit de repositories die je hebt geconfigureerd op de host of de nieuwste versie, samengesteld uit de broncode. U moet ook configureren welke nodes in het cluster u aan HAProxy wilt toevoegen.
Zodra de HAProxy-instantie is geïmplementeerd, hebt u toegang tot enkele statistieken op het tabblad "Nodes":
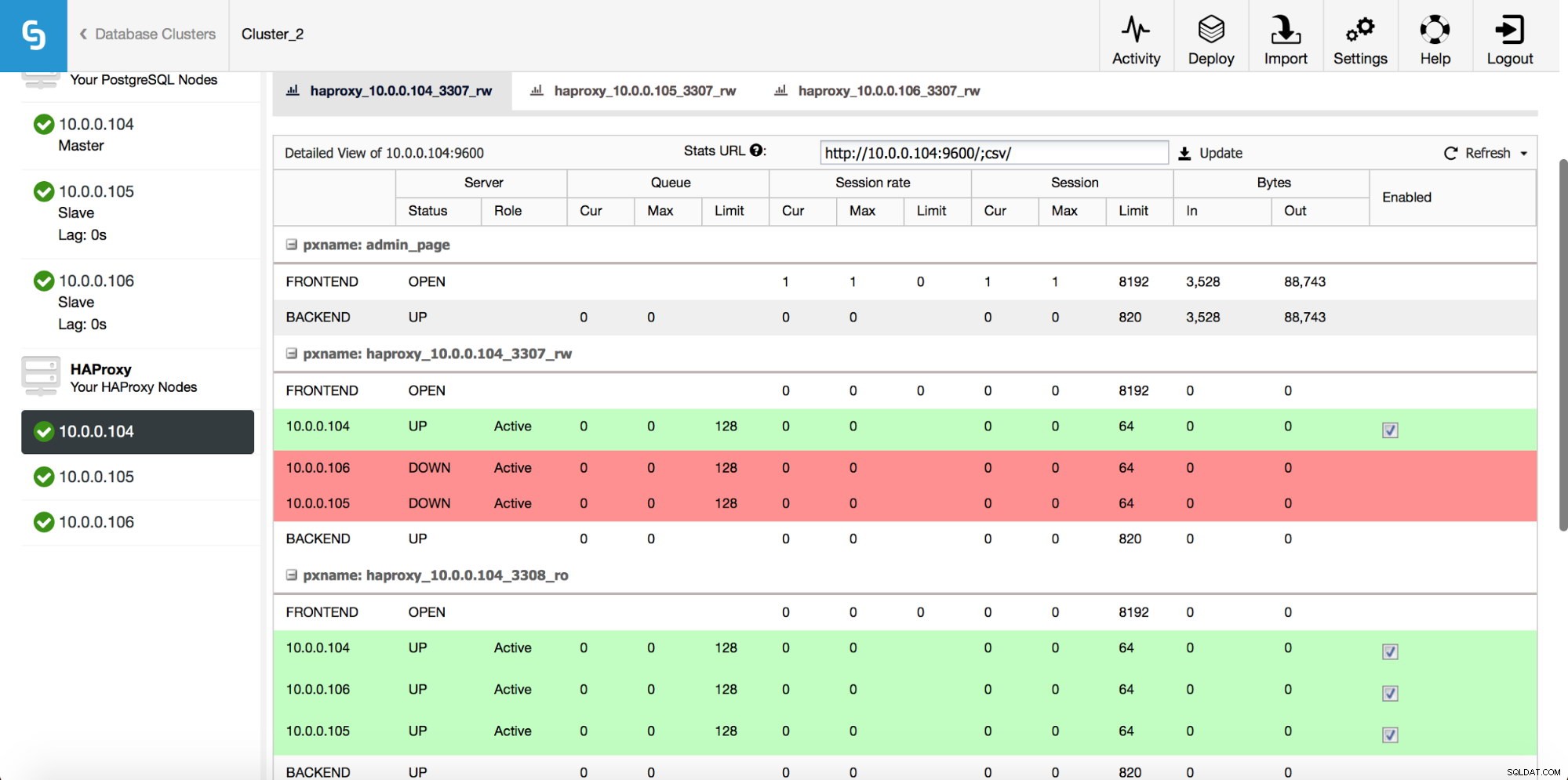
Zoals we kunnen zien, is voor de R/W-backend slechts één host (actieve server) gemarkeerd als up. Voor de alleen-lezen backend zijn alle nodes in gebruik.
Download de whitepaper vandaag PostgreSQL-beheer en -automatisering met ClusterControlLees wat u moet weten om PostgreSQL te implementeren, bewaken, beheren en schalenDownload de whitepaperBewaardeerd
HAProxy zal tussen uw applicaties en database-instances zitten, dus het zal een centrale rol spelen. Het kan helaas ook een single point of failure worden, mocht het mislukken, dan is er geen route naar de databases. Om een dergelijke situatie te voorkomen, kunt u meerdere HAProxy-instanties implementeren. Maar dan is de vraag - hoe te beslissen met welke proxy-host verbinding moet worden gemaakt. Als je HAProxy van ClusterControl hebt geïmplementeerd, is het net zo eenvoudig als het uitvoeren van een andere taak "Load Balancer toevoegen", dit keer met Keepalived.
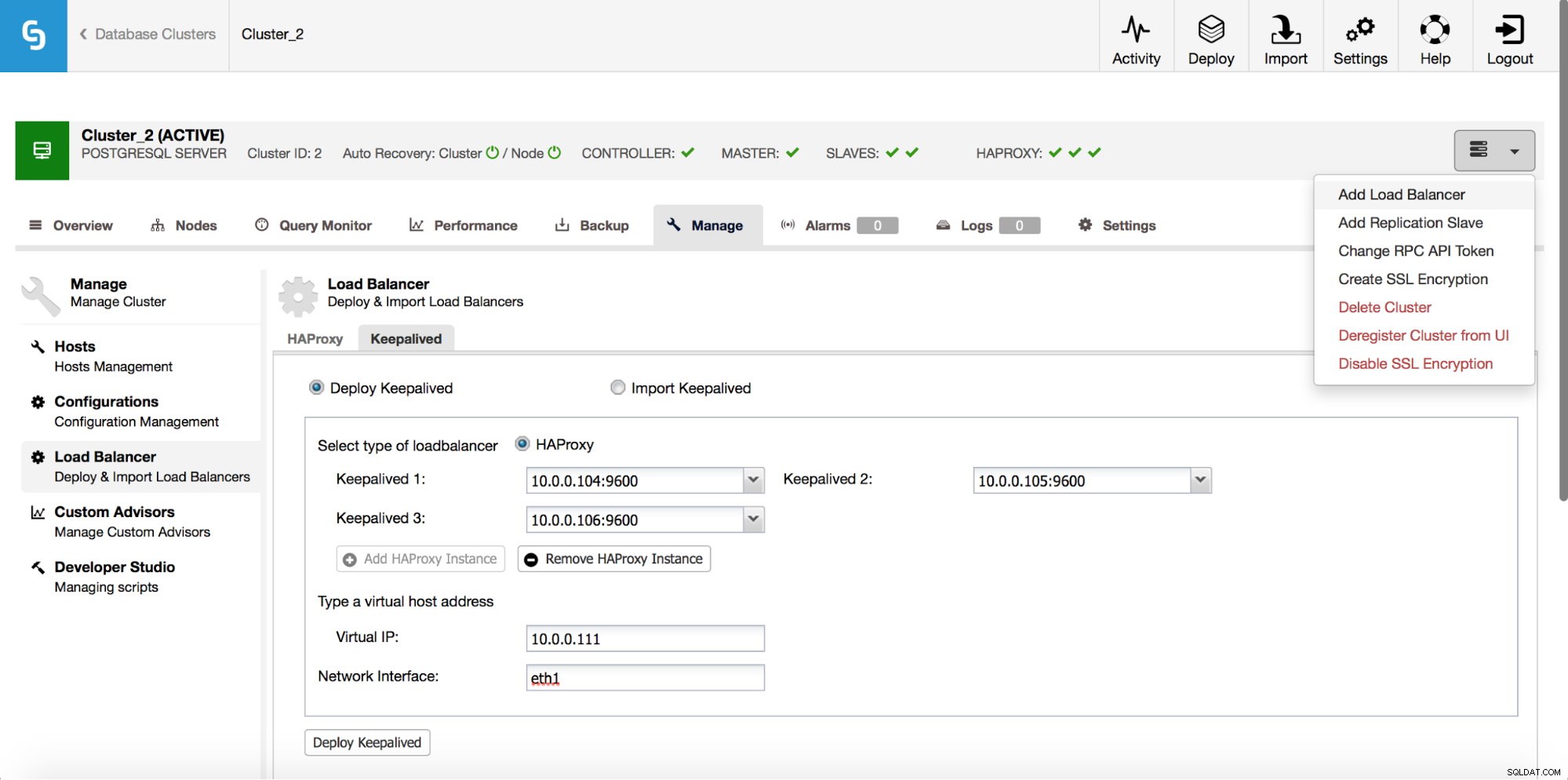
Zoals we in de bovenstaande schermafbeelding kunnen zien, kun je maximaal drie HAProxy-hosts oppikken en Keepalive zal bovenop hen worden geïmplementeerd, waarbij hun status wordt gecontroleerd. Een van hen krijgt een virtueel IP-adres (VIP) toegewezen. Uw toepassing moet deze VIP gebruiken om verbinding te maken met de database. Als de "actieve" HAProxy niet meer beschikbaar is, wordt de VIP verplaatst naar een andere host.
Zoals we hebben gezien, is het vrij eenvoudig om een volledige stapel met hoge beschikbaarheid voor PostgreSQL te implementeren. Probeer het eens en laat het ons weten als je feedback hebt.