De sleutelpopulatie-query nog wat meer analyseren
In deel 3 van onze reeks ODBC-tracering gaan we dieper in op Access-beheersleutels voor gekoppelde ODBC-tabellen en hoe het de SELECT-query's sorteert en groepeert. In het vorige artikel hebben we geleerd hoe een recordset van het type dynaset in feite uit 2 afzonderlijke query's bestaat, waarbij de eerste query alleen de sleutels van de ODBC-gekoppelde tabel ophaalt die vervolgens wordt gebruikt om de gegevens te vullen. In dit artikel zullen we wat meer bestuderen over hoe Access de sleutels beheert en hoe het afleidt wat de sleutel is om te gebruiken voor een ODBC-gekoppelde tabel, met de gevolgen die het heeft. We beginnen met het sorteren.
Een sortering toevoegen aan de zoekopdracht
Je zag in het vorige artikel dat we begonnen met een simpele SELECT zonder een bepaalde bestelling. Je hebt ook gezien hoe Access voor het eerst de CityID . ophaalde en gebruik het resultaat van de eerste query om vervolgens de volgende query's in te vullen om de gebruiker de indruk te geven snel te zijn bij het openen van een grote recordset. Als je ooit een situatie hebt meegemaakt waarin het toevoegen van een sortering of groepering aan een zoekopdracht plotseling langzaam ging, zal dit verklaren waarom.
Laten we een sortering toevoegen aan de StateProvinceID in een Access-query:
SELECT Cities.* FROM Cities ORDER BY Cities.StateProvinceID;Als we nu de ODBC SQL traceren, zouden we de uitvoer moeten zien:
SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" ORDER BY "Application"."Cities"."StateProvinceID" SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? SQLExecute: (GOTO BOOKMARK) SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)Als je het vergelijkt met de trace uit het vorige artikel, kun je zien dat ze hetzelfde zijn, behalve de eerste query. Access plaatst de sortering in de eerste query waar deze wordt gebruikt om de sleutels op te halen. Dat is logisch, want door de sortering af te dwingen op de sleutels die het gebruikt om door de records te lopen, heeft Access gegarandeerd een één-op-één overeenkomst tussen de ordinale positie van een record en hoe deze moet worden gesorteerd. Vervolgens worden de records op precies dezelfde manier ingevuld. Het enige verschil is de volgorde van de toetsen die wordt gebruikt om de andere vragen in te vullen.
Laten we eens kijken wat er gebeurt als we een GROUP BY . toevoegen door de steden per staat te tellen:
SELECT Cities.StateProvinceID ,Count(Cities.CityID) AS CountOfCityID FROM Cities GROUP BY Cities.StateProvinceID;Tracering zou moeten opleveren:
SQLExecDirect:
SELECT
"StateProvinceID"
,COUNT("CityID" )
FROM "Application"."Cities"
GROUP BY "StateProvinceID" Het is je misschien ook opgevallen dat de query nu langzaam wordt geopend, en hoewel deze is ingesteld als een recordset van het type dynaset, heeft Access ervoor gekozen dit te negeren en in feite te behandelen als een recordset van het type snapshot. Dit is logisch omdat de query niet kan worden bijgewerkt en omdat u in een query als deze niet echt naar een willekeurige positie kunt navigeren. U moet dus wachten tot alle rijen zijn opgehaald voordat u vrij kunt bladeren. De StateProvinceID kan niet worden gebruikt om een record te lokaliseren, aangezien er meerdere records in de Cities zouden zijn tafel. Hoewel ik een GROUP BY . gebruikte in dit voorbeeld hoeft het geen groepering te zijn die ervoor zorgt dat Access in plaats daarvan een recordset van het type snapshot gebruikt. DISTINCT gebruiken zou bijvoorbeeld hetzelfde effect hebben. Een handige vuistregel om te voorspellen of Access een recordset van het dynaset-type zal gebruiken, is te vragen of een bepaalde rij in de resulterende recordset teruggaat naar precies één rij in de ODBC-gegevensbron. Als dat niet het geval is, gebruikt Access snapshot-gedrag, zelfs als de query dynaset zou moeten gebruiken. Daarom, alleen omdat de standaard een dynaset-type recordset is, kan dit niet garanderen dat het in feite een dynaset-type recordset zal zijn. Het is slechts een verzoek , geen eis.
De sleutel bepalen die moet worden gebruikt om te selecteren
Je hebt misschien gemerkt in de vorige getraceerde SQL in zowel dit als eerdere artikelen, Access gebruikte de CityID als de sleutel. Die kolom is opgehaald in de eerste query en vervolgens gebruikt in daaropvolgende voorbereide query's. Maar hoe weet Access welke kolom(men) van een gekoppelde tabel het moet gebruiken? De eerste neiging zou zijn om te zeggen dat het controleert op een primaire sleutel en die gebruikt. Dat zou echter onjuist zijn. In feite zal de Access-database-engine gebruik maken van ODBC's SQLStatistics functie tijdens het koppelen of opnieuw koppelen van de tabel om te onderzoeken welke indices beschikbaar zijn. Deze functie retourneert een resultatenset met één rij voor elke kolom die deelneemt aan een index voor alle indices. Deze resultatenset is altijd gesorteerd en volgens afspraak sorteert het altijd geclusterde indices, gehashte indices en vervolgens andere typen indices. Binnen elk indextype worden de indexen alfabetisch op naam gesorteerd. De Access-database-engine selecteert de eerste unieke index die wordt gevonden, zelfs als dit niet de daadwerkelijke primaire sleutel is. Om dit te bewijzen, zullen we een domme tabel maken met enkele vreemde indices:
CREATE TABLE dbo.SillyTable ( ID int CONSTRAINT PK_SillyTable PRIMARY KEY NONCLUSTERED, OtherStuff int CONSTRAINT UQ_SillyTable_OtherStuff UNIQUE CLUSTERED, SomeValue nvarchar(255) );Als we de tabel vervolgens vullen met wat gegevens en ernaar linken in Access en een gegevensbladweergave openen op de gekoppelde tabel, zullen we dit zien in getraceerde ODBC SQL. Kortheidshalve zijn alleen de eerste 2 commando's opgenomen.
SQLExecDirect: SELECT "dbo"."SillyTable"."OtherStuff" FROM "dbo"."SillyTable" SQLPrepare: SELECT "ID" ,"OtherStuff" ,"SomeValue" FROM "dbo"."SillyTable" WHERE "OtherStuff" = ?Omdat de
OtherStuff deelneemt aan een geclusterde index, het kwam vóór de eigenlijke primaire sleutel en werd dus geselecteerd door de Access-database-engine om te worden gebruikt in een dynaset-type recordset voor het selecteren van een individuele rij. Dat is ook ondanks het feit dat de naam van de unieke geclusterde index achter de naam van de primaire index zou zijn gekomen. Een tactiek om de Access-database-engine te dwingen een bepaalde index voor een tabel te selecteren, zou zijn om het type te wijzigen of de naam te hernoemen zodat deze alfabetisch wordt gesorteerd binnen de groep van het indextype. In het geval van SQL Server zijn primaire sleutels meestal geclusterd en kan er maar één geclusterde index zijn, dus het is een gelukkig toeval dat dit meestal de juiste index is voor gebruik van de Access-database-engine. Als de SQL Server-database echter tabellen met niet-geclusterde primaire sleutels bevat en er een geclusterde unieke index is, is dit misschien niet de optimale keuze. In de gevallen waarin er helemaal geen geclusterde indices zijn, kunt u beïnvloeden welke unieke indices worden gebruikt door de index een naam te geven zodat deze voor andere indices wordt gesorteerd. Dat kan handig zijn met andere RDBMS-software waar het maken van een geclusterde index voor de primaire sleutel niet praktisch of mogelijk is. Access-side index voor gekoppelde SQL-view of tabel zonder indexen
Wanneer u een koppeling maakt naar een SQL-view of een SQL-tabel waarvoor geen indexen of primaire sleutel zijn gedefinieerd, zijn er geen indexen beschikbaar die de Access-database-engine kan gebruiken. Als je gekoppelde tabelmanager hebt gebruikt om een tabel of een SQL-weergave zonder indexen te koppelen, heb je mogelijk een dialoogvenster als dit gezien:
 Als we de
Als we de ID selecteren , voltooi de koppeling, open de gekoppelde tabel in de ontwerpweergave en vervolgens het dialoogvenster Indexen, we zouden dit moeten zien:
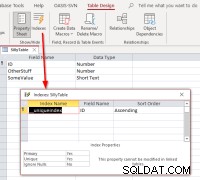 Het laat zien dat de tabel een index heeft met de naam
Het laat zien dat de tabel een index heeft met de naam __uniqueindex maar het bestaat niet in de oorspronkelijke gegevensbron. Wat gebeurd er? Het antwoord is dat Access een Access-side . heeft gemaakt index voor het gebruik ervan om te helpen identificeren welke kan worden gebruikt als record-ID voor dergelijke tabellen of weergaven. Als u de tabellen programmatisch opnieuw koppelt in plaats van de Linked Table Manager te gebruiken, zult u het nodig vinden om het gedrag te repliceren om dergelijke gekoppelde tabellen bijwerkbaar te maken. Dit kan worden gedaan door een Access SQL-opdracht uit te voeren:
CREATE UNIQUE INDEX [__uniqueindex] ON SillyTable (ID);U kunt bijvoorbeeld
CurrentDb.Execute . gebruiken om de Access SQL uit te voeren om de index op de gekoppelde tabel te maken. U moet het echter niet als een pass-through-query uitvoeren, omdat de index niet daadwerkelijk op de server wordt gemaakt. Het is alleen voor de voordelen van Access om updates van die gekoppelde tabel toe te staan. Het is vermeldenswaard dat Access slechts precies één index toestaat voor een dergelijke gekoppelde tabel en alleen als deze nog geen indexen heeft. Desalniettemin kunt u zien dat het gebruik van een SQL-weergave een wenselijke optie kan zijn voor gevallen waarin het databaseontwerp u niet toestaat geclusterde indices te gebruiken en u niet wilt rommelen met de naam van de index om de Access-database-engine over te halen deze index te gebruiken. niet die index. U kunt de index en de kolommen die deze moet bevatten expliciet beheren bij het koppelen van de SQL-weergave.
Conclusies
Uit vorig artikel zagen we dat een recordset van het type dynaset meestal 2 queries afgeeft. De eerste query gaat meestal over het vullen van de gegevens. We hebben nader bekeken hoe Access omgaat met de populatie van sleutels die het zal gebruiken voor een recordset van het type dynaset. We hebben gezien hoe Access elke sortering van de oorspronkelijke Access-query daadwerkelijk zal converteren en die vervolgens zal gebruiken in de sleutelpopulatiequery. We hebben gezien dat de volgorde van de sleutelpopulatiequery rechtstreeks van invloed is op hoe de gegevens in de recordset worden gesorteerd en aan de gebruiker worden gepresenteerd. Hierdoor kan de gebruiker dingen doen zoals naar een willekeurig record springen op basis van de ordinale positie van de lijst.
We zagen toen dat groepering en andere SQL-bewerkingen die een-een-toewijzing tussen de geretourneerde rij en de oorspronkelijke rij voorkomen, ervoor zorgen dat Access de Access-query behandelt alsof het een recordset van het snapshot-type is, ondanks het aanvragen van een recordset van het dynaset-type.
Vervolgens hebben we gekeken hoe Access de sleutel bepaalt die moet worden gebruikt voor het beheren van updates met een ODBC-gekoppelde tabel. In tegenstelling tot wat we zouden verwachten, selecteert het niet noodzakelijk de primaire sleutel van de tabel, maar eerder de eerste unieke index die het vindt, afhankelijk van het type index en de naam van de index. We hebben strategieën besproken om ervoor te zorgen dat Access de juiste unieke index selecteert. We hebben gekeken naar SQL-view die normaal gesproken geen indices heeft en hebben een methode besproken waarmee we Access kunnen informeren over hoe een SQL-view of een tabel zonder primaire sleutel moet worden gesleuteld, waardoor we meer controle hebben over hoe Access de updates voor die ODBC-gekoppelde tabellen.
In het volgende artikel zullen we bekijken hoe Access daadwerkelijk updates van de gegevens uitvoert wanneer gebruikers wijzigingen aanbrengen via de Access-query of recordbron.
Onze toegangsexperts staan voor u klaar. Bel ons op 773-809-5456 of e-mail ons op sales@itimpact.com.