Heb je het moeilijk met SQL UNION? Het gebeurt als de resultaten die je hebt gecombineerd je SQL Server tot stilstand brengen. Of een rapport dat eerder werkte, verschijnt in een vak met een rood X-pictogram. Er treedt een "Operand type clash"-fout op die verwijst naar een regel met UNION. Het "vuur" begint. Klinkt dat bekend?
Of je SQL UNION nu al een tijdje gebruikt of net begint, een spiekbriefje of een beknopte set aantekeningen kan geen kwaad. Dit krijg je vandaag in dit bericht. Deze lijst biedt 10 handige tips voor zowel beginners als veteranen. Er zullen ook voorbeelden zijn en enkele geavanceerde discussies.

[sendpulse-form id=”11900″]
Maar voordat we ingaan op het eerste punt, laten we de voorwaarden verduidelijken.
UNION is een van de set-operators in SQL die 2 of meer resultaatsets combineert. Het kan van pas komen wanneer u namen, maandelijkse statistieken en meer uit verschillende bronnen moet combineren. En of u nu SQL Server, MySQL of Oracle gebruikt, het doel, het gedrag en de syntaxis zullen zeer vergelijkbaar zijn. Maar hoe werkt het?
1. Gebruik SQL UNION om Uniek te combineren Records
Door UNION te gebruiken om resultatensets te combineren, worden duplicaten verwijderd.
Waarom is dit belangrijk?
Meestal wilt u geen resultaten met duplicaten. Een rapport met dubbele regels verspilt inkt en papier in hardcopy's. En dit zal uw gebruikers boos maken.
Hoe het te gebruiken
Je combineert de resultaten van de SELECT-statements met daartussen UNION.
Laten we, voordat we met het voorbeeld beginnen, onze voorbeeldgegevens voorbereiden.
USE AdventureWorks
GO
IF OBJECT_ID ('dbo.Customer1', 'U') IS NOT NULL
DROP TABLE dbo.Customer1;
GO
IF OBJECT_ID ('dbo.Customer2', 'U') IS NOT NULL
DROP TABLE dbo.Customer2;
GO
IF OBJECT_ID ('dbo.Customer3', 'U') IS NOT NULL
DROP TABLE dbo.Customer3;
GO
-- Get 3 customer names with Andersen lastname
SELECT TOP 3
p.LastName
, p.FirstName
, c.AccountNumber
INTO dbo.Customer1
FROM Person.Person AS p
INNER JOIN Sales.Customer c
ON c.PersonID = p.BusinessEntityID
WHERE p.LastName = 'Andersen';
-- Make sure we have a duplicate in another table
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer2
FROM Customer1 c
-- Seems it's not enough. Let's have a 3rd copy
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer3
FROM Customer1 c
We gebruiken de gegevens die door de bovenstaande code zijn gegenereerd tot de derde tip. Nu we klaar zijn, volgt hieronder het voorbeeld:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
We hebben 3 exemplaren van dezelfde klantennamen en verwachten dat unieke records zullen verdwijnen. Bekijk de resultaten:
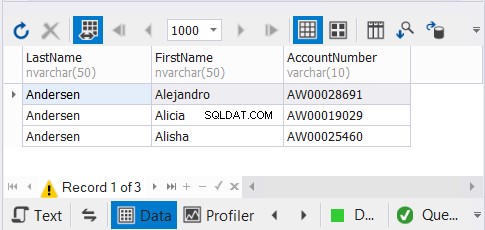
De dbForge Studio voor SQL Server-oplossing die we voor onze voorbeelden gebruiken, toont slechts 3 records. Het hadden er 9 kunnen zijn. Door UNION toe te passen, hebben we de duplicaten verwijderd.
Hoe werkt het?
Het plandiagram in dbForge Studio laat zien hoe SQL Server het resultaat produceert dat wordt weergegeven in figuur 1. Kijk eens:
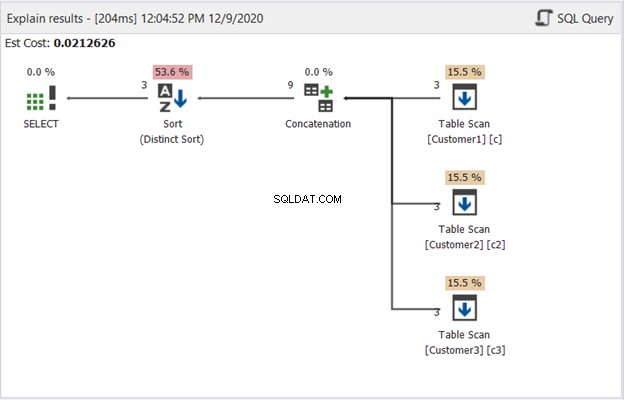
Begin van rechts naar links om figuur 2 te interpreteren:
- We hebben 3 records opgehaald van elke Table Scan-operator. Dat zijn de 3 SELECT-statements uit het bovenstaande voorbeeld. Elke regel die eruit gaat, toont '3', wat betekent dat er elk 3 records zijn.
- De aaneenschakelingsoperator doet het combineren van resultaten. De regel die eruit gaat, toont '9' - een uitvoer van 9 records uit het combineren van resultaten.
- De operator Distinct Sort zorgt ervoor dat unieke records de uiteindelijke uitvoer zijn. De regel die eruit gaat, toont '3', wat consistent is met het aantal records in figuur 1.
Het bovenstaande diagram laat zien hoe UNION wordt verwerkt door SQL Server. Het aantal en type gebruikte operators kan verschillen, afhankelijk van de query en de onderliggende gegevensbron. Maar samengevat werkt een UNIE als volgt:
- Haal de resultaten van elke SELECT-instructie op.
- Combineer de resultaten met een samenvoegingsoperator.
- Als de gecombineerde resultaten niet uniek zijn, filtert SQL Server de duplicaten weg.
Alle succesvolle voorbeelden met UNION volgen deze basisstappen.
2. Gebruik SQL UNION ALL om records met duplicaten te combineren
Door UNION ALL te gebruiken, worden resultatensets gecombineerd met duplicaten.
Waarom is dit belangrijk?
Misschien wilt u resultatensets combineren en de records vervolgens met duplicaten ophalen om later te verwerken. Deze taak is handig voor het opschonen van uw gegevens.
Hoe het te gebruiken
Je combineert de resultaten van de SELECT-statements met daartussen UNION ALL. Bekijk het voorbeeld:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION ALL
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
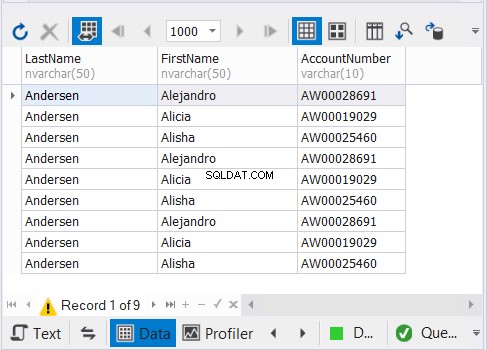
De bovenstaande code voert 9 records uit zoals weergegeven in Afbeelding 3:
Hoe werkt het?
Zoals eerder gebruiken we het Plan-diagram om te weten hoe dit werkt:
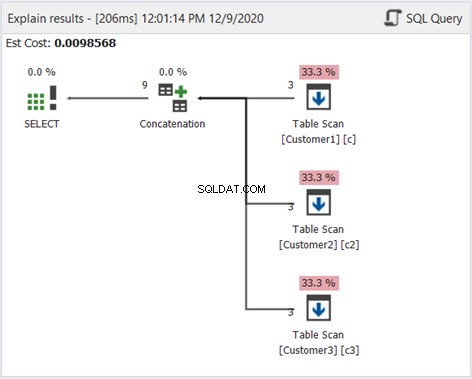
Behalve de Sort Distinct in figuur 2, is het bovenstaande diagram hetzelfde. Dat is passend omdat we de duplicaten niet willen filteren.
Het bovenstaande diagram laat zien hoe UNION ALL werkt. Samengevat zijn dit de stappen die SQL Server zal volgen:
- Haal de resultaten van elke SELECT-instructie op.
- Combineer vervolgens de resultaten met een Concatenatie-operator.
Succesvolle voorbeelden met UNION ALL volgen dit patroon.
3. U kunt SQL UNION en UNION ALL mengen, maar ze groeperen met haakjes
U kunt het gebruik van UNION en UNION ALL combineren in ten minste drie SELECT-instructies.
Hoe het te gebruiken?
U combineert resultaten van de SELECT-instructies met daartussen UNION of UNION ALL. Haakjes groeperen de resultaten die bij elkaar komen. Laten we dezelfde gegevens gebruiken voor het volgende voorbeeld:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
(
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
)
Het bovenstaande voorbeeld combineert de resultaten van de laatste twee SELECT-instructies zonder duplicaten. Vervolgens combineert het dat met het resultaat van de eerste SELECT-instructie. Het resultaat staat in Afbeelding 5 hieronder:
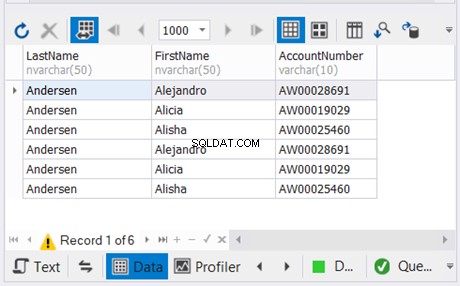
4. Kolommen van elke SELECT-instructie moeten compatibele gegevenstypen hebben
Kolommen in elke SELECT-instructie die UNION gebruikt, kunnen verschillende gegevenstypen hebben. Het is acceptabel zolang ze compatibel zijn en impliciete conversie erover toestaan. Het uiteindelijke gegevenstype van de gecombineerde resultaten zal het gegevenstype met de hoogste prioriteit gebruiken. De basis van de uiteindelijke gegevensomvang zijn ook de gegevens met de grootste omvang. In het geval van strings gebruikt het de data met het grootste aantal karakters.
Waarom is dit belangrijk?
Als u het resultaat van UNION's in een tabel moet invoegen, zal het uiteindelijke gegevenstype en de grootte bepalen of het in de doeltabelkolom past of niet. Zo niet, dan treedt er een fout op. Een van de kolommen in de UNION heeft bijvoorbeeld het laatste type NVARCHAR(50). Als de doeltabelkolom VARCHAR(50) is, kunt u deze niet in de tabel invoegen.
Hoe werkt het?
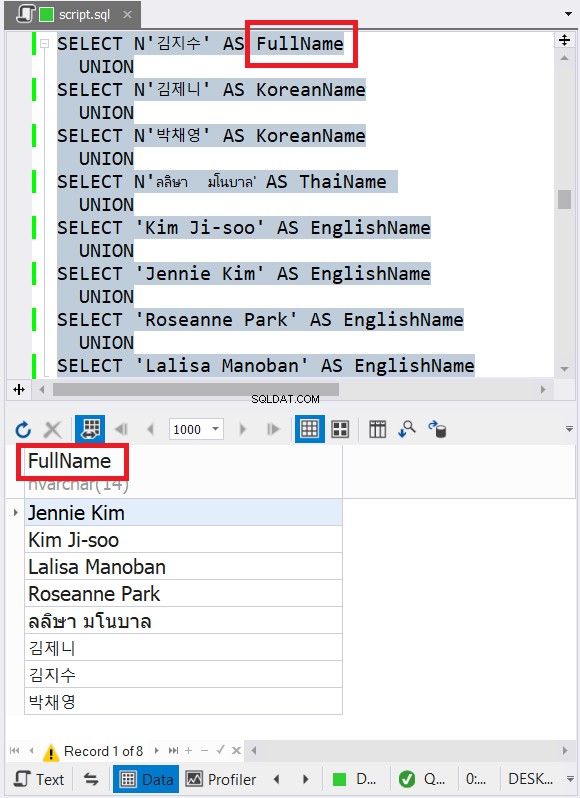
Er is geen betere manier om het uit te leggen dan een voorbeeld:
SELECT N'김지수' AS FullName
UNION
SELECT N'김제니' AS KoreanName
UNION
SELECT N'박채영' AS KoreanName
UNION
SELECT N'ลลิษา มโนบาล' AS ThaiName
UNION
SELECT 'Kim Ji-soo' AS EnglishName
UNION
SELECT 'Jennie Kim' AS EnglishName
UNION
SELECT 'Roseanne Park' AS EnglishName
UNION
SELECT 'Lalisa Manoban' AS EnglishName
Het bovenstaande voorbeeld bevat gegevens met Engelse, Koreaanse en Thaise tekennamen. Thais en Koreaans zijn Unicode-tekens. Engelse karakters zijn dat niet. Dus, wat denkt u dat het uiteindelijke gegevenstype en -grootte zal zijn? dbForge Studio toont het in de resultatenset:
Heb je het laatste gegevenstype in figuur 6 opgemerkt? Het kan geen VARCHAR zijn vanwege de Unicode-tekens. Het moet dus NVARCHAR zijn. Ondertussen kan de grootte niet kleiner zijn dan 14 omdat de gegevens met het grootste aantal tekens 14 tekens hebben. Zie de rode bijschriften in Afbeelding 6. Het is goed om het gegevenstype en de grootte op te nemen in de kolomkop in dbForge Studio.
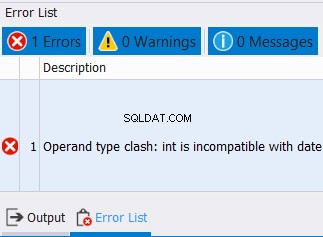
Dit is niet alleen het geval voor string-gegevenstypen. Dit geldt ook voor getallen en datums. Als u ondertussen gegevens probeert te combineren met incompatibele gegevenstypen, treedt er een fout op. Zie onderstaand voorbeeld:
SELECT CAST('12/25/2020' AS DATE) AS col1
UNION
SELECT CAST('10' AS INT) AS col1
We kunnen datums en gehele getallen niet combineren in één kolom. Verwacht dus een fout zoals hieronder:
5. De kolomnamen van de gecombineerde resultaten zullen de kolomnamen van de eerste SELECT-instructie gebruiken
Dit probleem heeft betrekking op de vorige tip. Let op de kolomnamen in de code in Tip #4. Er zijn verschillende kolomnamen in elke SELECT-instructie. We zagen de laatste kolomnaam echter eerder in het gecombineerde resultaat in figuur 6. De basis is dus de kolomnaam van het eerste SELECT-statement.
Waarom is dit belangrijk?
Dit kan handig zijn wanneer u het resultaat van de UNION in een tijdelijke tabel moet dumpen. Als u in de volgende instructies naar de kolomnamen moet verwijzen, moet u zeker zijn van de namen. Tenzij u een geavanceerde code-editor met IntelliSense gebruikt, staat u voor een nieuwe fout in uw T-SQL-code.
Hoe werkt het?
Zie Afbeelding 8 voor duidelijkere resultaten van het gebruik van dbForge Studio:
6. Voeg ORDER BY toe in de Last SELECT-instructie met SQL UNION om de resultaten te sorteren
U moet de gecombineerde resultaten sorteren. In een reeks SELECT-instructies met UNION ertussen, kunt u dit doen met de ORDER BY-component in de laatste SELECT-instructie.
Waarom is dit belangrijk?
Gebruikers willen de gegevens sorteren zoals ze dat willen in apps, webpagina's, rapporten, spreadsheets en meer.
Hoe het te gebruiken
Gebruik ORDER BY in de laatste SELECT-instructie. Hier is een voorbeeld:
SELECT
e.BusinessEntityID
,p.FirstName
,p.MiddleName
,p.LastName
,'Employee' AS PersonType
FROM HumanResources.Employee e
INNER JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID
UNION
SELECT
c.PersonID
,p.FirstName
,p.MiddleName
,p.LastName
,'Customer' AS PersonType
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
ORDER BY p.LastName, p.FirstName
In het bovenstaande voorbeeld lijkt het alsof de sortering alleen plaatsvindt in de laatste SELECT-instructie. Maar dat is het niet. Het zal werken voor het gecombineerde resultaat. U krijgt problemen als u het in elke SELECT-instructie plaatst. Bekijk het resultaat:
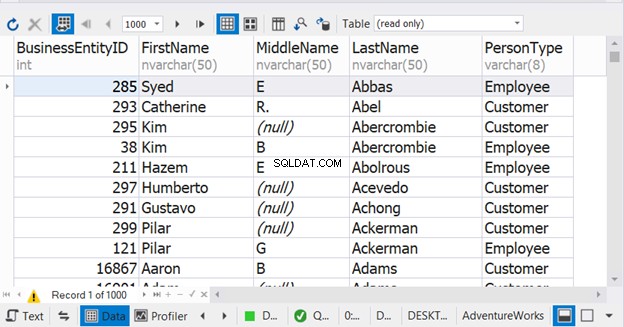
Zonder ORDER BY heeft de resultaatset alle Employee PersonType eerst gevolgd door alle Klant Persoonstype . Afbeelding 9 laat echter zien dat namen de sorteervolgorde van het gecombineerde resultaat worden.
Als u ORDER BY in elke SELECT-instructie probeert te plaatsen om te sorteren, gebeurt het volgende:
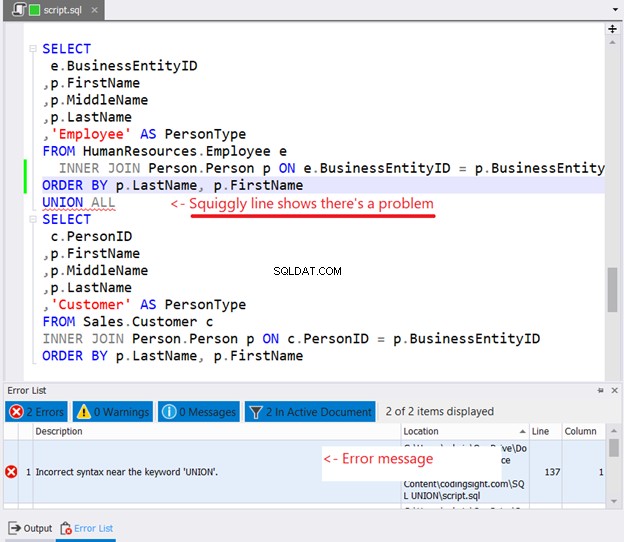
Heb je de kronkelende lijn in figuur 10 gezien? Het is een waarschuwing. Als je het niet hebt opgemerkt en verder bent gegaan, verschijnt er een fout in het foutenlijstvenster van dbForge Studio.
7. WHERE en GROUP BY-clausules kunnen worden gebruikt in elke SELECT-instructie met SQL UNION
ORDER BY-component werkt niet in elke SELECT-instructie met UNION ertussen. De WHERE- en GROUP BY-clausules werken echter.
Waarom is dit belangrijk?
Misschien wilt u de resultaten van verschillende query's combineren die gegevens filteren, tellen of samenvatten. U kunt dit bijvoorbeeld doen om de totale verkooporders voor januari 2012 te krijgen en deze te vergelijken met januari 2013, januari 2014, enzovoort.
Hoe het te gebruiken
Plaats de WHERE- en/of GROUP BY-clausules in elke SELECT-instructie. Bekijk het onderstaande voorbeeld:
USE AdventureWorks
GO
-- Get the number of orders for January 2012, 2013, 2014 for comparison
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
De bovenstaande code combineert het aantal bestellingen in januari voor drie opeenvolgende jaren. Controleer nu de uitvoer:
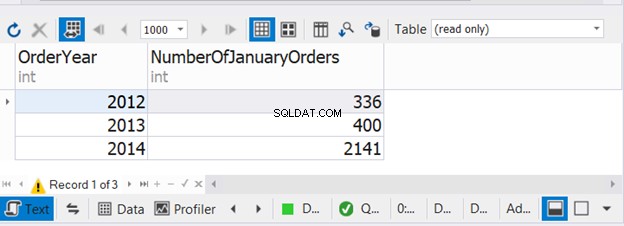
Dit voorbeeld laat zien dat het mogelijk is om WHERE en GROUP BY te gebruiken in elk van de drie SELECT-instructies met UNION.
8. SELECTEER IN Werkt met SQL UNION
Wanneer u de resultaten van een query met SQL UNION in een tabel moet invoegen, kunt u dit doen met SELECT INTO.
Waarom is dit belangrijk?
Er zullen momenten zijn dat u de resultaten van een zoekopdracht met UNION in een tabel moet zetten voor verdere verwerking.
Hoe het te gebruiken
Plaats de INTO-component in de eerste SELECT-instructie. Hier is een voorbeeld:
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
INTO JanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
Vergeet niet om slechts één INTO-component in de eerste SELECT-instructie te plaatsen.
Hoe werkt het
SQL Server volgt het verwerkingspatroon UNION. Vervolgens wordt het resultaat ingevoegd in de tabel die is gespecificeerd in de INTO-component.
9. Onderscheid SQL UNION van SQL JOIN
Zowel SQL UNION als SQL JOIN combineren de tabelgegevens, maar het verschil in syntaxis en resultaten is als dag en nacht.
Waarom is dit belangrijk?
Als je rapport of een vereiste een JOIN nodig heeft, maar je hebt een UNION gedaan, dan is de output verkeerd.
Hoe SQL UNION en SQL JOIN worden gebruikt
Het is SQL UNION versus JOIN. Dit is een van de gerelateerde zoekopdrachten en vragen die een newbie in Google stelt bij het leren over SQL UNION. Hier is de tabel met verschillen:
| SQL UNION | SQL JOIN | |
| Wat wordt gecombineerd | Rijen | Kolommen (met een sleutel) |
| Aantal kolommen per tabel | Hetzelfde voor alle tabellen | Variabele (nul voor alle kolommen/tabel) |
In alle projecten waar ik mee ben geweest, is SQL JOIN meestal van toepassing. Ik had maar een paar gevallen waarin SQL UNION werd gebruikt. Maar zoals je tot nu toe hebt gezien, is de SQL UNION verre van nutteloos.
10. SQL UNION ALL is sneller dan UNION
De Plandiagrammen in Figuur 2 en Figuur 4 eerder suggereren dat UNION een extra operator nodig heeft om unieke resultaten te garanderen. Daarom is UNION ALL sneller.
Waarom is dit belangrijk?
Jij, je gebruikers, je klanten, je baas, ze willen allemaal snelle resultaten. Als u weet dat UNION ALL sneller is dan UNION, vraagt u zich af wat u moet doen als u unieke gecombineerde resultaten nodig heeft. Er is één oplossing, zoals je later zult zien.
SQL UNION ALL vs. UNION-prestaties
In figuur 2 en figuur 4 heb je al een idee wat sneller is. Maar de gebruikte codevoorbeelden zijn eenvoudig met een kleine resultatenset. Laten we wat meer vergelijkingen toevoegen met miljoenen records om het aantrekkelijk te maken.
Laten we om te beginnen de gegevens voorbereiden:
SELECT TOP (2000000)
val = ROW_NUMBER() OVER (ORDER BY sod.SalesOrderDetailID)
INTO dbo.TestNumbers
FROM AdventureWorks.Sales.SalesOrderDetail sod
CROSS JOIN AdventureWorks.Sales.SalesOrderDetail sod2
Dat zijn 2 miljoen records. Ik hoop dat dat overtuigend genoeg is. Laten we nu de volgende twee voorbeelden van zoekopdrachten hieronder bekijken.
-- Using UNION ALL
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
-- Using UNION
SELECT
val
FROM TestNumbers tn
UNION
SELECT
val
FROM TestNumbers tn
Laten we eens kijken naar de processen die betrokken zijn bij deze zoekopdrachten, te beginnen met de snellere.
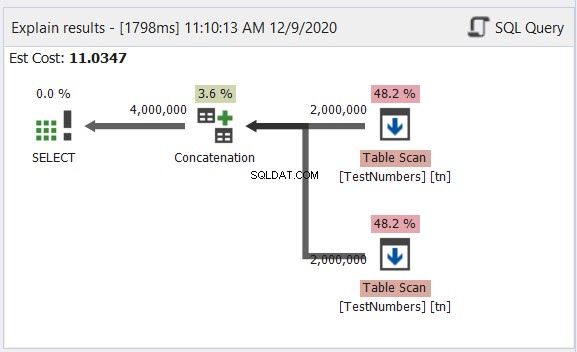
Plandiagramanalyse
Het diagram in figuur 12 ziet er typisch uit voor een UNION ALL-proces. Het resultaat is echter 4 miljoen gecombineerde resultaten. Zie de pijl die uit de aaneenschakelingsoperator gaat. Toch is het meestal omdat het niet omgaat met de duplicaten.
Laten we nu het diagram van de UNION-query in Afbeelding 13 bekijken:
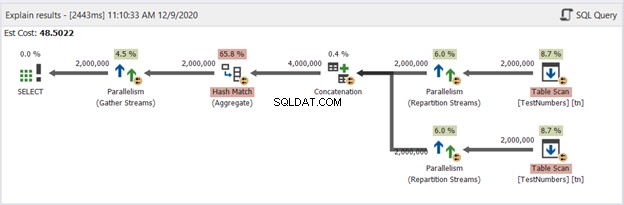
Deze is niet meer typisch. Het plan wordt een parallel queryplan om de verwijdering van duplicaten in vier miljoen rijen aan te pakken. Het parallelle queryplan betekent dat SQL Server het proces moet delen door het aantal beschikbare processorcores.
Laten we het interpreteren, beginnend bij de juiste operatoren die naar links gaan:
- Omdat we een tabel met zichzelf combineren, moet SQL Server deze twee keer ophalen. Bekijk de twee tabelscans met elk twee miljoen records.
- Repartition Stream-operators bepalen de distributie van elke rij naar de volgende beschikbare thread.
- Aaneenschakeling verdubbelt het resultaat tot vier miljoen. Dit is nog steeds rekening houdend met het aantal processorkernen.
- Er is een Hash Match van toepassing om de duplicaten te verwijderen. Dit is een duur proces met een operatorkost van 65,8%. Als gevolg hiervan werden twee miljoen records weggegooid.
- Verzamel Streams combineren de resultaten die in elke processorkern of thread zijn gedaan in één.
Dat is te veel werk, ook al is het proces verdeeld in meerdere threads. Daarom zult u concluderen dat het langzamer zal werken. Maar wat als er een oplossing is om unieke records te krijgen met UNION ALL, maar sneller dan dit?
Unieke resultaten maar snellere oplossing met UNION ALL – hoe?
Ik laat je niet wachten. Hier is de code:
SELECT DISTINCT
val
FROM
(
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
) AS uniqtn
Dit kan een flauwe oplossing zijn. Maar bekijk het Plan Diagram in Afbeelding 14:
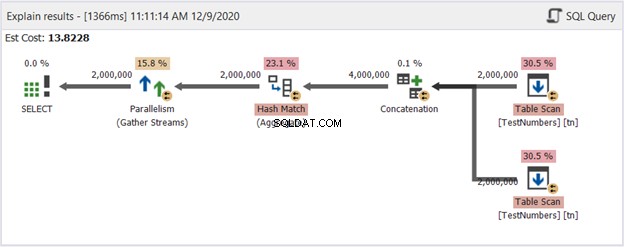
Dus, wat maakte het beter? Als je het vergelijkt met figuur 13, zie je dat de operators voor de herverdelingsstroom zijn verdwenen. Het gebruikt echter nog steeds meerdere threads om de klus te klaren. Aan de andere kant houdt het in dat de query-optimizer dit proces eenvoudiger vindt dan de query met UNION.
Kunnen we veilig concluderen dat we het gebruik van UNION moeten vermijden en in plaats daarvan deze benadering moeten gebruiken? Helemaal niet! Controleer altijd het uitvoeringsplandiagram! Het hangt altijd af van wat u wilt dat SQL Server u geeft. Deze laat alleen zien dat als je tegen een prestatiemuur aanloopt, je je vraagbenadering moet veranderen.
Hoe zit het met I/O-statistieken?
We kunnen niet ontkennen hoeveel resources SQL Server nodig heeft om onze queryvoorbeelden te verwerken. Daarom moeten we ook hun STATISTICS IO onderzoeken. Als we de drie bovenstaande vragen vergelijken, krijgen we de logische waarden hieronder:
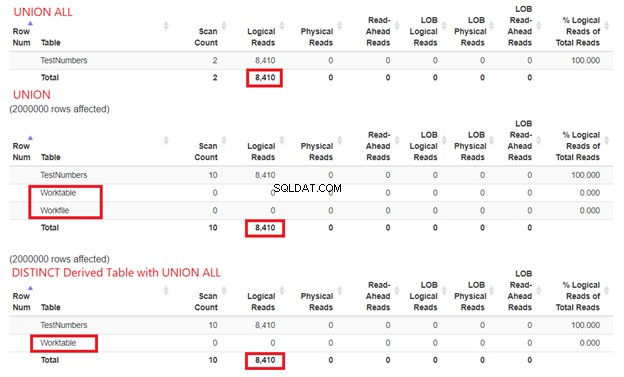
Uit figuur 15 kunnen we nog steeds concluderen dat UNION ALL sneller is dan UNION, hoewel de logische uitlezingen hetzelfde zijn. De aanwezigheid van Werktafel en Werkbestand toont met behulp van tempdb om de klus te klaren. Als we ondertussen SELECT DISTINCT gebruiken uit een afgeleide tabel met UNION ALL, wordt de tempdb het gebruik is minder in vergelijking met UNION. Dit bevestigt verder dat onze analyse van de eerder gemaakte Plandiagrammen correct is.
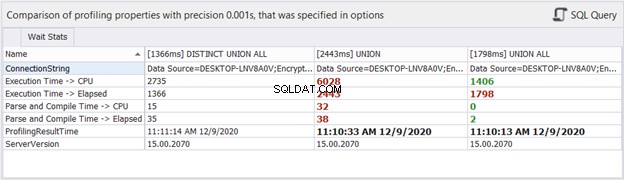
Hoe zit het met tijdstatistieken?
Hoewel de verstreken tijd kan veranderen bij elke uitvoering die we op dezelfde vragen uitvoeren, kan het ons een idee geven en meer bewijs toevoegen aan onze analyse. dbForge Studio toont de tijdsverschillen van de drie bovenstaande queries. Deze vergelijking is consistent met de vorige analyse die we hebben gedaan.
Conclusie
We hebben veel achtergrondinformatie behandeld om te bieden wat u nodig hebt om SQL UNION en UNION ALL te gebruiken. Je herinnert je misschien niet alles meer na het lezen van dit bericht, dus zorg ervoor dat je een bladwijzer maakt voor deze pagina.
Als je het bericht leuk vindt, deel het dan gerust op sociale media.