Ik heb kort gezegd dat gegevens in batchmodus genormaliseerd zijn in mijn laatste artikel Batch Mode Bitmaps in SQL Server. Alle gegevens in een batch worden weergegeven door een waarde van acht bytes in dit specifieke genormaliseerde formaat, ongeacht het onderliggende gegevenstype.
Die uitspraak roept ongetwijfeld vragen op, niet in de laatste plaats over hoe gegevens met een lengte die veel groter is dan acht bytes op die manier kunnen worden opgeslagen. Dit artikel onderzoekt de genormaliseerde weergave van batchgegevens, legt uit waarom niet alle gegevenstypen van acht bytes binnen 64 bits passen en laat een voorbeeld zien van hoe dit alles de prestaties in batchmodus beïnvloedt.
Demo
Ik ga beginnen met een voorbeeld dat laat zien dat het batchgegevensformaat een belangrijk verschil maakt voor een uitvoeringsplan. U hebt SQL Server 2016 (of later) en Developer Edition (of equivalent) nodig om de hier getoonde resultaten te reproduceren.
Het eerste dat we nodig hebben, is een tabel van bigint nummers van 1 tot en met 102.400. Deze getallen zullen binnenkort worden gebruikt om een columnstore-tabel te vullen (het aantal rijen is het minimum dat nodig is om een enkel gecomprimeerd segment te verkrijgen).
DROP TABLE IF EXISTS #Numbers;
GO
CREATE TABLE #Numbers (n bigint NOT NULL PRIMARY KEY);
GO
INSERT #Numbers (n)
SELECT
n = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
n
OFFSET 0 ROWS
FETCH FIRST 102400 ROWS ONLY
OPTION (MAXDOP 1); Succesvol geaggregeerde pushdown
Het volgende script gebruikt de getallentabel om een andere tabel te maken met dezelfde getallen, gecompenseerd door een specifieke waarde. Deze tabel gebruikt columnstore voor zijn primaire opslag om later uitvoering in batchmodus te produceren.
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
@Start bigint = CONVERT(bigint, -4611686018427387905);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Voer de volgende testquery's uit op de nieuwe columnstore-tabel:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
De toevoeging binnen de SUM is om overstroming te voorkomen. U kunt de WHERE . overslaan clausules (om een triviaal plan te vermijden) als u SQL Server 2017 gebruikt.
Die vragen hebben allemaal baat bij geaggregeerde pushdown. Het totaal wordt berekend met de Columnstore Index Scan in plaats van de batch-modus Hash Aggregate exploitant. Plannen na uitvoering tonen nul rijen die door de scan worden uitgezonden. Alle 102.400 rijen waren 'lokaal geaggregeerd'.
De SUM plan wordt hieronder als voorbeeld getoond:

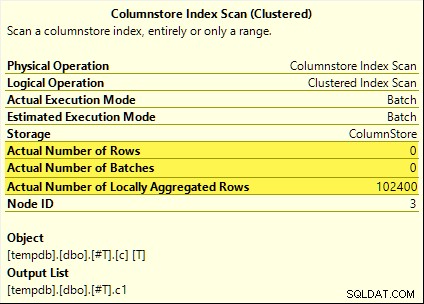
Onsuccesvolle pushdown van aggregaat
Laat nu de kolomopslagtesttabel vallen en maak vervolgens opnieuw met de offset met één verminderd:
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
-- Note this value has decreased by one
@Start bigint = CONVERT(bigint, -4611686018427387906);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Voer exact dezelfde geaggregeerde pushdown-testquery's uit als voorheen:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Deze keer alleen de COUNT_BIG aggregaat bereikt geaggregeerde pushdown (alleen SQL Server 2017). De MAX en SUM aggregaten niet. Hier is de nieuwe SUM plan voor vergelijking met die van de eerste test:

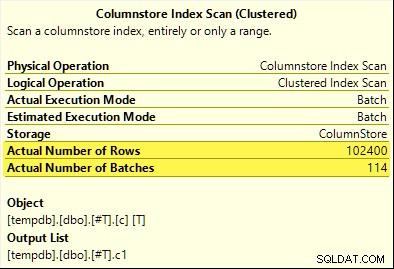
Alle 102.400 rijen (in 114 batches) worden verzonden door de Columnstore Index Scan , verwerkt door de Compute Scalar , en verzonden naar de Hash Aggregate .
Waarom het verschil? Het enige wat we deden was het bereik van getallen die in de columnstore-tabel zijn opgeslagen met één compenseren!
Uitleg
Ik zei in de inleiding dat niet alle datatypes van 8 bytes in 64 bits passen. Dit feit is belangrijk omdat veel prestatie-optimalisaties voor columnstore en batchmodus alleen werken met gegevens van 64 bits. Aggregate pushdown is een van die dingen. Er zijn veel meer prestatiekenmerken (niet allemaal gedocumenteerd) die alleen het beste (of helemaal niet) werken als de gegevens in 64 bits passen.
In ons specifieke voorbeeld is geaggregeerde pushdown uitgeschakeld voor een columnstore-segment wanneer het zelfs één . bevat gegevenswaarde die niet in 64 bits past. SQL Server kan dit bepalen aan de hand van de minimale en maximale metagegevens die aan elk segment zijn gekoppeld zonder alle gegevens te controleren. Elk segment wordt afzonderlijk beoordeeld.
Aggregate pushdown werkt nog steeds voor de COUNT_BIG aggregeer pas in de tweede test. Dit is een optimalisatie die ergens in SQL Server 2017 is toegevoegd (mijn tests zijn uitgevoerd op CU16). Het is logisch om geaggregeerde pushdown niet uit te schakelen wanneer we alleen rijen tellen en niets doen met de specifieke gegevenswaarden. Ik kon geen documentatie vinden voor deze verbetering, maar dat is tegenwoordig niet zo ongebruikelijk.
Als een kanttekening merkte ik op dat SQL Server 2017 CU16 geaggregeerde pushdown mogelijk maakt voor de voorheen niet-ondersteunde gegevenstypen real , float , datetimeoffset , en numeric met een nauwkeurigheid groter dan 18 - wanneer de gegevens in 64 bits passen. Dit is ook niet gedocumenteerd op het moment van schrijven.
Ok, maar waarom?
Je stelt misschien de zeer redelijke vraag:waarom doet één set bigint testwaarden passen blijkbaar in 64 bits, maar de andere niet?
Als je vermoedde dat de reden gerelateerd was aan NULL , geef jezelf een vinkje. Ook al is de testtabelkolom gedefinieerd als NOT NULL , SQL Server gebruikt dezelfde genormaliseerde gegevenslay-out voor bigint of de gegevens nulls toestaan of niet. Daar zijn redenen voor, die ik stukje bij beetje zal uitpakken.
Laat ik beginnen met enkele observaties:
- Elke kolomwaarde in een batch wordt opgeslagen in precies acht bytes (64 bits), ongeacht het onderliggende gegevenstype. Deze lay-out met een vast formaat maakt alles eenvoudiger en sneller. Bij uitvoering in batchmodus draait alles om snelheid.
- Een batch is 64 KB groot en bevat tussen de 64 en 900 rijen, afhankelijk van het aantal kolommen dat wordt geprojecteerd. Dit is logisch, aangezien de grootte van kolomgegevens is vastgesteld op 64 bits. Meer kolommen betekent dat er minder rijen in elke batch van 64 KB passen.
- Niet alle SQL Server-gegevenstypen passen in 64 bits, zelfs niet in principe. Een lange reeks (om een voorbeeld te noemen) past misschien niet eens in een hele batch van 64 KB (als dat was toegestaan), laat staan in een enkele 64-bits invoer.
SQL Server lost dit laatste probleem op door een 8-byte referentie op te slaan naar gegevens groter dan 64 bits. De ‘grote’ datawaarde wordt elders in het geheugen opgeslagen. Je zou deze regeling "off-row" of "out-of-batch" opslag kunnen noemen. Intern wordt er naar verwezen als deep data .
Nu kunnen gegevenstypen van acht bytes niet in 64 bits passen als ze nullable zijn. Neem bigint NULL bijvoorbeeld . Het niet-null-gegevensbereik vereist mogelijk de volledige 64 bits, en we hebben nog een ander bit nodig om null aan te geven of niet.
De problemen oplossen
De creatieve en efficiënte oplossing voor deze uitdagingen is om het laagste significante bit te reserveren (LSB) van de 64-bits waarde als een vlag. De vlag geeft aan in-batch gegevensopslag wanneer de LSB vrij is (ingesteld op nul). Wanneer de LSB is ingesteld (tegen één), kan het twee dingen betekenen:
- De waarde is null; of
- De waarde wordt off-batch opgeslagen (het zijn diepe gegevens).
Deze twee gevallen onderscheiden zich door de toestand van de overige 63 bits. Als ze allemaal nul zijn , de waarde is NULL . Anders is de 'waarde' een verwijzing naar diepe gegevens die elders zijn opgeslagen.
Als de LSB wordt bekeken als een geheel getal, betekent het instellen van de LSB dat verwijzingen naar diepe gegevens altijd oneven zijn nummers. Nullen worden weergegeven door het (oneven) getal 1 (alle andere bits zijn nul). In-batch gegevens worden vertegenwoordigd door even getallen omdat de LSB nul is.
Dit doet niet betekent dat SQL Server alleen even getallen binnen een batch kan opslaan! Het betekent alleen dat de genormaliseerde weergave van de onderliggende kolomwaarden hebben altijd een LSB van nul wanneer ze "in-batch" worden opgeslagen. Dit zal zo meteen logischer zijn.
Batchgegevens normalisatie
Normalisatie wordt op verschillende manieren uitgevoerd, afhankelijk van het onderliggende gegevenstype. Voor bigint het proces is:
- Als de gegevens null zijn , sla de waarde 1 op (alleen LSB-set).
- Als de waarde kan worden weergegeven in 63 bits , schuif alle bits één plaats naar links en zet de LSB op nul. Als we naar de waarde kijken als een geheel getal, betekent dit verdubbeling de waarde. Bijvoorbeeld de
bigintwaarde 1 wordt genormaliseerd naar waarde 2. In binair is dat zeven bytes van allemaal nul gevolgd door00000010. De LSB die nul is, geeft aan dat dit gegevens zijn die inline zijn opgeslagen. Wanneer SQL Server de oorspronkelijke waarde nodig heeft, wordt de 64-bits waarde één positie naar rechts verschoven (waardoor de LSB-vlag wordt weggegooid). - Als de waarde niet kan worden weergegeven in 63 bits, wordt de waarde off-batch opgeslagen als deep data . De in-batch-aanwijzer heeft de LSB ingesteld (waardoor het een oneven getal wordt).
Het proces van testen of een bigint waarde past in 63 bits is:
- Bewaar de onbewerkte*
bigintwaarde in 64-bits processorregisterr8. - Bewaar dubbele waarde van
r8in registerrax. - Verschuif de bits van
raxéén plaats naar rechts. - Test of de waarden in
raxenr8zijn gelijk.
* Merk op dat de onbewerkte waarde niet voor alle gegevenstypen betrouwbaar kan worden bepaald door een T-SQL-conversie naar een binair type. Het T-SQL-resultaat kan een andere bytevolgorde hebben en kan ook metadata bevatten, b.v. time fractionele seconde precisie.
Als de test bij stap 4 slaagt, weten we dat de waarde kan worden verdubbeld en vervolgens binnen 64 bits kan worden gehalveerd - met behoud van de oorspronkelijke waarde.
Een kleiner bereik
Het resultaat van dit alles is dat het bereik van bigint waarden die in batch kunnen worden opgeslagen is verlaagd met één bit (omdat de LSB niet beschikbaar is). De volgende inclusieve bereiken van bigint waarden worden off-batch opgeslagen als deep data :
- -4.611.686.018.427.387.905 tot -9.223.372.036.854.775.808
- +4.611.686.018.427.387.904 tot +9.223.372.036.854.775.807
In ruil voor het accepteren dat deze bigint bereikbeperkingen, normalisatie stelt SQL Server in staat om (de meeste) bigint op te slaan waarden, nulls en diepe gegevensreferenties in batch . Dit is een stuk eenvoudiger en ruimtebesparender dan aparte structuren voor nullabiliteit en diepe gegevensreferenties. Het maakt ook het verwerken van batchgegevens met instructies van de SIMD-processor een stuk eenvoudiger.
Normalisatie van andere datatypes
SQL Server bevat normalisatie code voor elk van de gegevenstypen die worden ondersteund door uitvoering in batchmodus. Elke routine is geoptimaliseerd om de binnenkomende binaire lay-out efficiënt te verwerken en om alleen diepgaande gegevens te creëren wanneer dat nodig is. Normalisatie heeft altijd tot gevolg dat de LSB wordt gereserveerd om nulls of diepe data aan te geven, maar de lay-out van de overige 63 bits verschilt per datatype.
Altijd in-batch
Genormaliseerde gegevens voor de volgende gegevenstypen worden altijd in batch opgeslagen omdat ze nooit meer dan 63 bits nodig hebben:
datetime(n)– intern herschaald naartime(7)datetime2(n)– intern herschaald naardatetime2(7)integersmallinttinyintbit– gebruikt detinyintimplementatie.smalldatetimedatetimerealfloatsmallmoney
Het hangt ervan af
De volgende gegevenstypen kunnen in-batch of diepe gegevens worden opgeslagen afhankelijk van de gegevenswaarde:
bigint– zoals eerder beschreven.money– hetzelfde bereik in batch alsbigintmaar gedeeld door 10.000.numeric/decimal– 18 decimale cijfers of minder in batch ongeacht van verklaarde precisie. Bijvoorbeeld dedecimal(38,9)waarde -999999999.999999999 kan worden weergegeven als het 8-byte gehele getal -999999999999999999 (f21f494c589c0001hex), die kan worden verdubbeld tot -99999999999999998 (e43e9298b1380002hex) omkeerbaar binnen 64 bits. SQL Server weet waar het decimaalteken vandaan komt op de schaal van het gegevenstype.datetimeoffset(n)– in-batch als de runtime-waarde past indatetimeoffset(2)ongeacht van verklaarde fractionele seconden precisie.timestamp– het interne formaat wijkt af van het display. Bijvoorbeeld eentimestampweergegeven vanuit T-SQL als0x000000000099449Awordt intern weergegeven als9a449900 00000000(in zeshoek). Deze waarde wordt opgeslagen als diepe gegevens omdat deze niet in 64-bits past wanneer deze wordt verdubbeld (één bit naar links verschoven).
Altijd diepe gegevens
De volgende worden altijd opgeslagen als diepe data (behalve nulls) :
uniqueidentifiervarbinary(n)– inclusief(max)binarychar/varchar(n)/nchar/nvarchar(n)/sysnameinclusief(max)– deze typen kunnen ook een woordenboek gebruiken (indien beschikbaar).text/ntext/image/xml– gebruikt devarbinary(n)implementatie.
Voor alle duidelijkheid, nulls voor alle batch-modus compatibele datatypes worden in batch opgeslagen als de speciale waarde 'één'.
Laatste gedachten
U mag verwachten dat u het beste haalt uit de beschikbare optimalisaties voor columnstore en batchmodus wanneer u gegevenstypen en -waarden gebruikt die in 64 bits passen. U heeft ook de meeste kans om in de loop van de tijd te profiteren van incrementele productverbeteringen, bijvoorbeeld de nieuwste verbeteringen aan de geaggregeerde pushdown die in de hoofdtekst worden vermeld. Niet alle prestatievoordelen zullen zo zichtbaar zijn in uitvoeringsplannen, of zelfs gedocumenteerd. Desalniettemin kunnen de verschillen extreem groot zijn.
Ik moet ook vermelden dat gegevens worden genormaliseerd wanneer een operator van een uitvoeringsplan in rijmodus gegevens verstrekt aan een ouder in batchmodus, of wanneer een scan zonder kolomopslag batches produceert (batchmodus op rowstore). Er is een onzichtbare rij-naar-batch-adapter die de juiste normalisatieroutine voor elke kolomwaarde aanroept voordat deze aan de batch wordt toegevoegd. Het vermijden van gegevenstypen met gecompliceerde normalisatie en diepe gegevensopslag kan ook hier prestatievoordelen opleveren.