Replicatie speelt een cruciale rol bij het handhaven van hoge beschikbaarheid. Servers kunnen uitvallen, het besturingssysteem of de databasesoftware moet mogelijk worden geüpgraded. Dit betekent het herschikken van serverrollen en het verplaatsen van replicatiekoppelingen, terwijl de gegevensconsistentie in alle databases behouden blijft. Topologiewijzigingen zijn vereist en er zijn verschillende manieren om deze uit te voeren.
Een standby-server promoten
Dit is waarschijnlijk de meest voorkomende bewerking die u moet uitvoeren. Er zijn meerdere redenen, bijvoorbeeld database-onderhoud op de primaire server die de werkbelasting op onaanvaardbare wijze zou beïnvloeden. Er kan een geplande downtime zijn vanwege bepaalde hardwarebewerkingen. De crash van de primaire server waardoor deze ontoegankelijk is voor de applicatie. Allemaal redenen om, al dan niet gepland, een failover uit te voeren. In alle gevallen zul je een van de standby-servers moeten promoten om een nieuwe primaire server te worden.
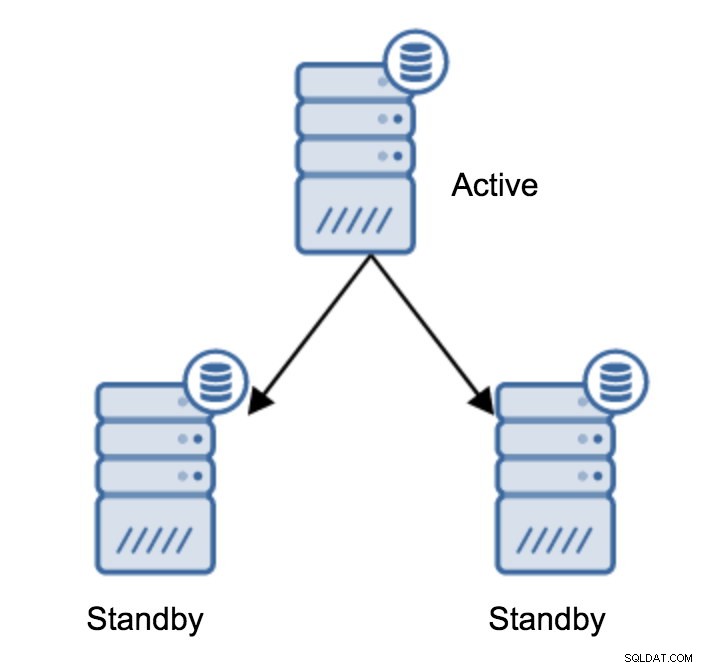
Om een standby-server te promoten, moet je het volgende uitvoeren:
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_ctl promote -D /var/lib/postgresql/10/main/
waiting for server to promote.... done
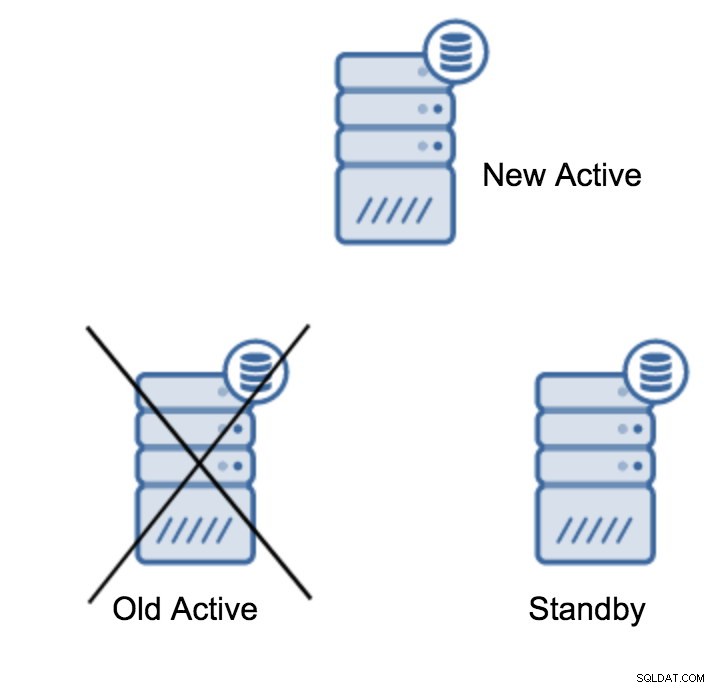
server promotedHet is gemakkelijk om deze opdracht uit te voeren, maar zorg er eerst voor dat u geen gegevens verliest. Als we het hebben over een "primaire server down"-scenario, heb je misschien niet al te veel opties. Als het om een gepland onderhoud gaat, dan is het mogelijk om je hierop voor te bereiden. U moet het verkeer op de primaire server stoppen en vervolgens controleren of de standby-server alle gegevens heeft ontvangen en toegepast. Dit kan worden gedaan op de standby-server, met behulp van de onderstaande query:
postgres=# select pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn();
pg_last_wal_receive_lsn | pg_last_wal_replay_lsn
-------------------------+------------------------
1/AA2D2B08 | 1/AA2D2B08
(1 row)Als alles goed is, kun je de oude primaire server stoppen en de standby-server promoten.
Download de whitepaper vandaag PostgreSQL-beheer en -automatisering met ClusterControlLees wat u moet weten om PostgreSQL te implementeren, bewaken, beheren en schalenDownload de whitepaperEen stand-byserver van een nieuwe primaire server reslaven
Mogelijk hebt u meer dan één standby-server die van uw primaire server afslaat. Standby-servers zijn immers handig om alleen-lezen verkeer te ontlasten. Nadat u een standby-server naar een nieuwe primaire server hebt gepromoveerd, moet u iets doen aan de resterende standby-servers die nog steeds verbonden zijn (of proberen te verbinden) met de oude primaire server. Helaas kunt u recovery.conf niet zomaar wijzigen en verbinden met de nieuwe primaire server. Om ze te verbinden, moet u ze eerst opnieuw opbouwen. Er zijn twee methoden die u hier kunt proberen:standaard basisback-up of pg_rewind.
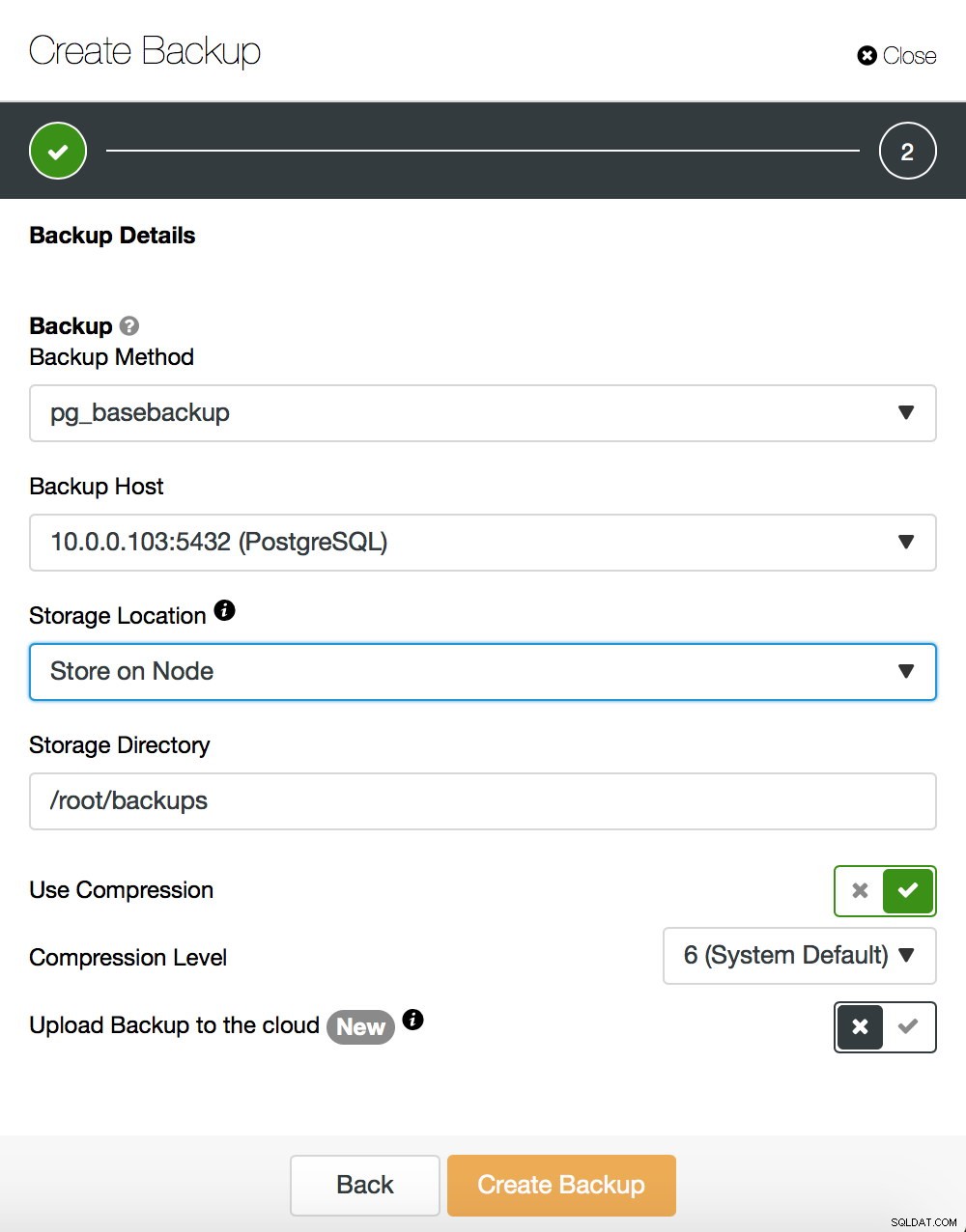
We zullen niet in detail treden over het maken van een basisback-up - we hebben het besproken in onze vorige blogpost, die zich richtte op het maken van back-ups en het terugzetten ervan op PostgreSQL. Als u ClusterControl gebruikt, kunt u het ook gebruiken om een basisback-up te maken:
Aan de andere kant, laten we een paar woorden zeggen over pg_rewind. Het belangrijkste verschil tussen beide methoden is dat basisback-up een volledige kopie van de dataset maakt. Als we het hebben over kleine datasets, kan het goed zijn, maar voor datasets met honderden gigabytes (of zelfs groter) kan het snel een probleem worden. Uiteindelijk wilt u uw standby-servers snel up-and-running hebben - om uw actieve server te ontlasten en een andere stand-by te hebben om naar te failoveren, mocht dat nodig zijn. Pg_rewind werkt anders - het kopieert alleen die blokken die zijn gewijzigd. In plaats van alles te kopiëren, kopieert het alleen wijzigingen, waardoor het proces aanzienlijk wordt versneld. Laten we aannemen dat uw nieuwe master een IP heeft van 10.0.0.103. Dit is hoe je pg_rewind kunt uitvoeren. Houd er rekening mee dat u de doelserver moet laten stoppen - PostgreSQL kan daar niet worden uitgevoerd.
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_rewind --source-server="user=myuser dbname=postgres host=10.0.0.103" --target-pgdata=/var/lib/postgresql/10/main --dry-run
servers diverged at WAL location 1/AA4F1160 on timeline 3
rewinding from last common checkpoint at 1/AA4F10F0 on timeline 3
Done!Dit zorgt voor een droogloop , het proces testen maar geen wijzigingen aanbrengen. Als alles in orde is, hoeft u het alleen maar opnieuw uit te voeren, deze keer zonder de parameter '--dry-run'. Als het klaar is, is de laatst overgebleven stap het maken van een recovery.conf-bestand, dat naar de nieuwe master zal verwijzen. Het kan er zo uitzien:
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.103 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Nu bent u klaar om uw standby-server te starten en deze zal repliceren vanaf de nieuwe actieve server.
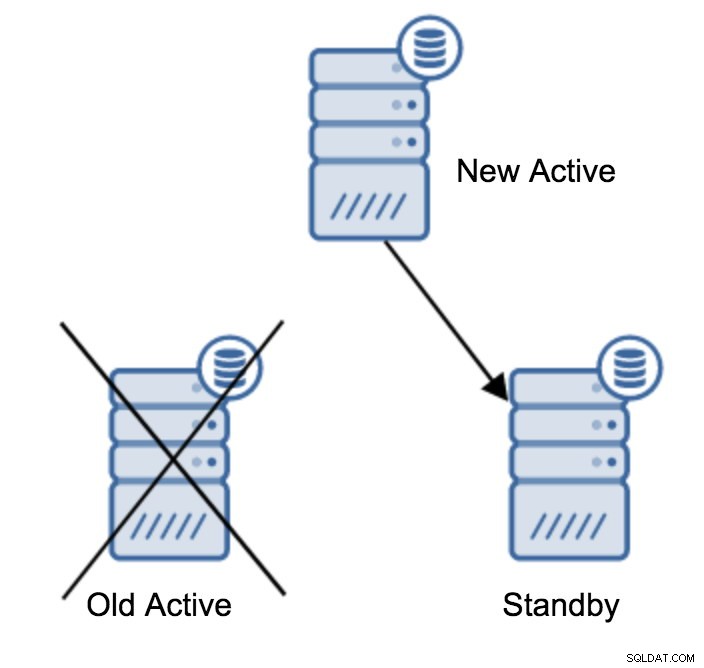
Geketende replicatie
Er zijn tal van redenen waarom u een geketende replicatie zou willen bouwen, hoewel dit meestal wordt gedaan om de belasting van de primaire server te verminderen. Het bedienen van de WAL naar standby-servers voegt wat overhead toe. Het is niet zo'n probleem als je een paar standby-servers hebt, maar als we het hebben over een groot aantal standby-servers, kan dit een probleem worden. We kunnen bijvoorbeeld het aantal standby-servers dat rechtstreeks van de actieve server repliceert, minimaliseren door een topologie te maken zoals hieronder:
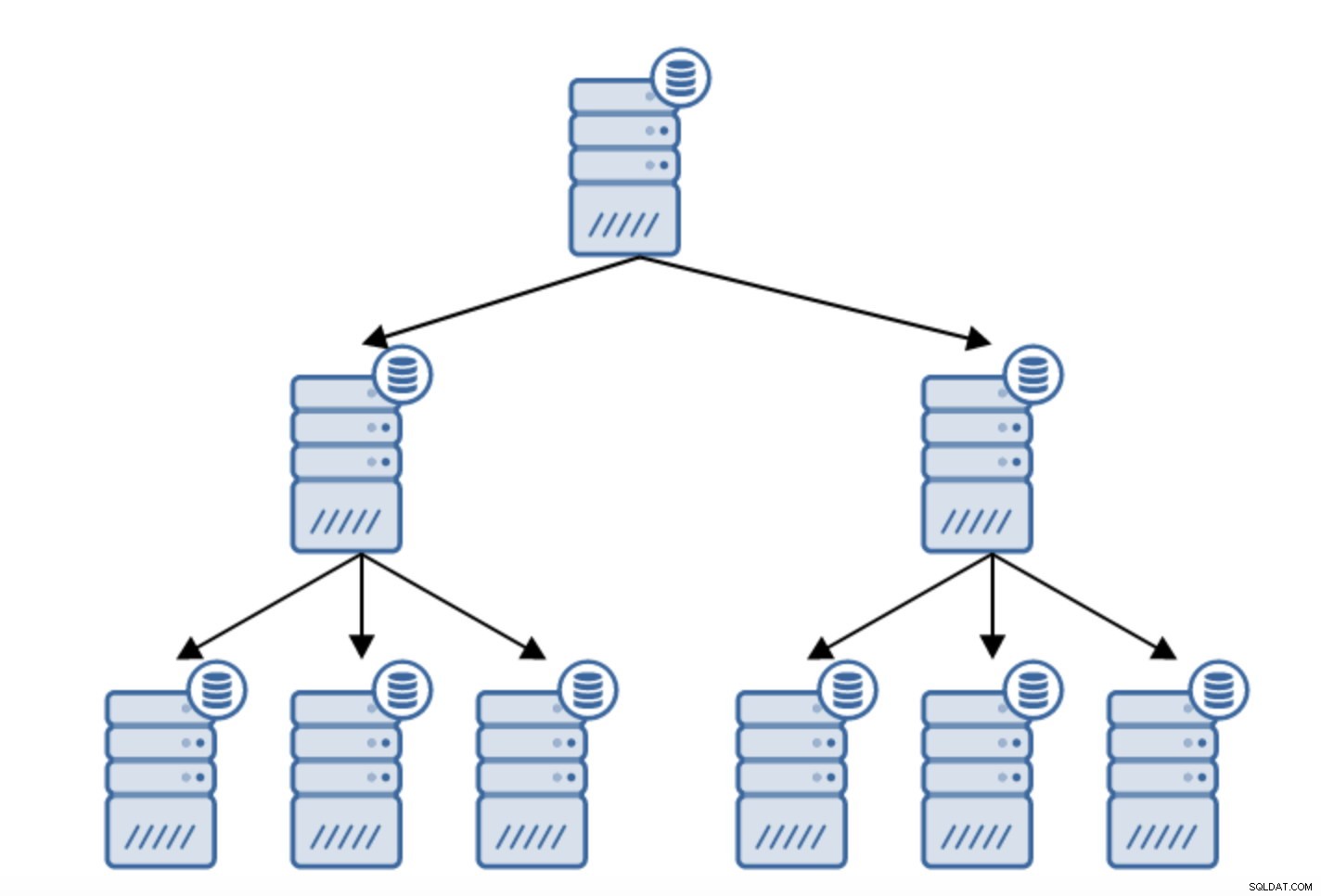
De overstap van een topologie van twee standby-servers naar een geketende replicatie is vrij eenvoudig.
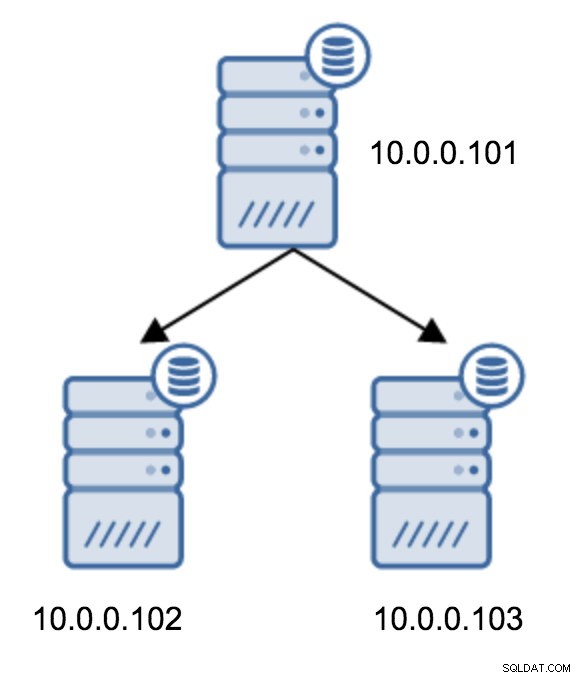
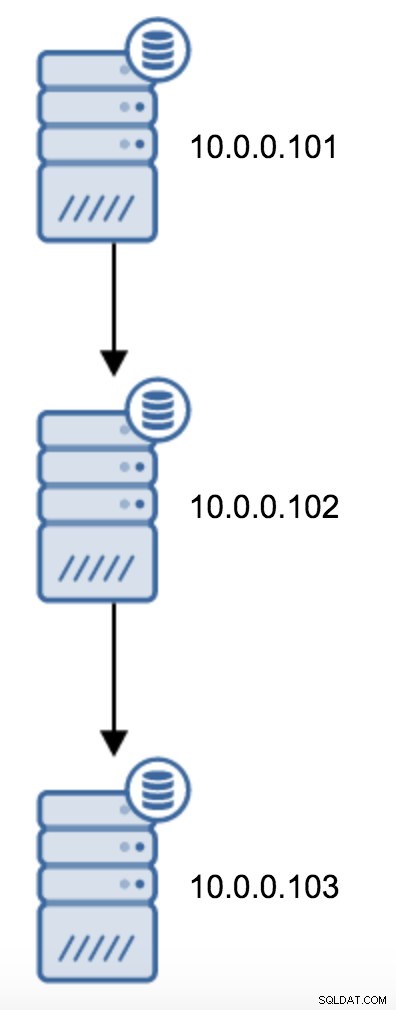
U moet recovery.conf wijzigen op 10.0.0.103, het naar 10.0.0.102 verwijzen en vervolgens PostgreSQL opnieuw starten.
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.102 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Na het opnieuw opstarten zou 10.0.0.103 moeten beginnen met het toepassen van WAL-updates.
Dit zijn enkele veelvoorkomende gevallen van topologiewijzigingen. Een onderwerp dat niet aan de orde is geweest, maar wel belangrijk is, is de impact van deze wijzigingen op de applicaties. We zullen dat in een apart bericht bespreken, evenals hoe u deze topologiewijzigingen transparant kunt maken voor de toepassingen.