Waarom kost het zoveel tijd om een query uit te voeren? Waarom zijn er geen indexen? De kans is groot dat je hebt gehoord over EXPLAIN in PostgreSQL. Er zijn echter nog steeds veel mensen die geen idee hebben hoe ze het moeten gebruiken. Ik hoop dat dit artikel gebruikers zal helpen deze geweldige tool aan te pakken.
Dit artikel is de auteursrevisie van Understanding EXPLAIN door Guillaume Lelarge. Aangezien ik wat informatie heb gemist, raad ik je ten zeerste aan om kennis te maken met het origineel.
De duivel is niet zo zwart als hij is geschilderd
Het is belangrijk om de logica van de PostgreSQL-kernel te begrijpen om query's te optimaliseren. Ik zal het proberen uit te leggen. Het is echt niet zo ingewikkeld.
EXPLAIN toont de nodige informatie die uitlegt wat de kernel doet voor elke specifieke zoekopdracht.
Laten we eens kijken naar wat de EXPLAIN-opdracht weergeeft en begrijpen wat er precies gebeurt in PostgreSQL. U kunt deze informatie toepassen op PostgreSQL 9.2 en hogere versies.
Onze taken:
- Leer hoe u de uitvoer van het EXPLAIN-commando kunt lezen en begrijpen
- Begrijp wat er gebeurt in PostgreSQL wanneer een query wordt uitgevoerd
Eerste stappen
We zullen oefenen op een testtafel met een miljoen rijen.
CREATE TABLE foo (c1 integer, c2 text); INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 1000000) AS i;
Probeer de gegevens te lezen
EXPLAIN SELECT * FROM foo;
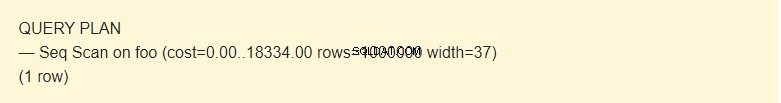
Het is op verschillende manieren mogelijk om gegevens uit een tabel te lezen. In ons geval meldt EXPLAIN dat een Seq Scan wordt gebruikt - een sequentiële, blok-voor-blok, uitgelezen Foo-tabelgegevens.
Wat is kosten ?
Nou, het is geen tijd, maar een concept dat is ontworpen om de kosten van een operatie te schatten. De eerste waarde 0,00 zijn de kosten voor het verkrijgen van de eerste rij. De tweede waarde 18334.00 zijn de kosten voor het verkrijgen van alle rijen.
Rijen zijn het geschatte aantal rijen dat wordt geretourneerd wanneer een Seq Scan-bewerking wordt uitgevoerd. De planner retourneert deze waarde. In mijn geval komt het overeen met het werkelijke aantal rijen in de tabel.
Breedte is een gemiddelde grootte van één rij in bytes.
Laten we proberen 10 rijen toe te voegen.
INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 10) AS i; EXPLAIN SELECT * FROM foo;

De waarde van rijen is niet gewijzigd. De statistieken van de tabel zijn oud. Roep de opdracht ANALYZE op om de statistieken bij te werken.
Nu, rijen het juiste aantal rijen weergeven.
Wat gebeurt er bij het uitvoeren van ANALYSE?
- Willekeurig worden een aantal rijen geselecteerd en uit de tabel gelezen.
- De statistieken van waarden per kolom worden verzameld.
Het aantal rijen dat ANALYZE leest, hangt af van de parameter default_statistics_target.
Werkelijke gegevens
Alles wat we hierboven in de uitvoer van het EXPLAIN-commando zagen, is wat de planner verwacht te krijgen. Laten we proberen ze te vergelijken met de resultaten op werkelijke gegevens. Gebruik hiervoor EXPLAIN (ANALYSE).
EXPLAIN (ANALYZE) SELECT * FROM foo;

Een dergelijke zoekopdracht zal inderdaad worden uitgevoerd. Dus als u EXPLAIN (ANALYZE) uitvoert voor de INSERT-, DELETE- of UPDATE-instructies, worden uw gegevens gewijzigd. Doe voorzichtig! Gebruik in deze gevallen de opdracht ROLLBACK.
De opdracht geeft de volgende aanvullende parameters weer:
- werkelijke tijd is de werkelijke tijd in milliseconden die zijn besteed aan respectievelijk de eerste rij en alle rijen.
- rijen is het werkelijke aantal rijen dat is ontvangen met Seq Scan.
- loops is het aantal keren dat de Seq Scan-bewerking moest worden uitgevoerd.
- Totale runtime is de totale tijd van het uitvoeren van query's.
Verder lezen:
Query-optimalisatie in PostgreSQL. UITLEG Basisprincipes – Deel 2
Query-optimalisatie in PostgreSQL. UITLEG Basisprincipes – Deel 3